Hive in Big Data
In the realm of Big Data, characterized by its vast volume, high velocity, and diverse variety, tools like Hive are essential. Originally developed by Facebook and integrated into the Hadoop ecosystem, Hive simplifies managing and querying large datasets. It offers a SQL-like interface, eliminating the need for complex languages like MapReduce or Pig. Hive's capacity for handling massive data with user-friendly queries makes it invaluable for data scientists and analysts in processing and deriving insights from Big Data.
What is Hive?
Hive is a popular data warehousing and SQL-like querying tool in the Hadoop ecosystem.
The Hive architecture comprises three parts: a metastore containing metadata about tables and their columns, a query processor that converts SQL-like queries into MapReduce tasks, and a driver software that executes these jobs on a Hadoop cluster.
Hive's support for external tables is one of its important features, allowing users to access data stored in other storage systems such as HBase, Cassandra, and Amazon S3. Hive in Big Data also enables partitioning, allowing users to divide big datasets depending on parameters such as date, location, or user ID. In addition, restricting the quantity of data that must be scanned improves query performance.
How Does Hive Work?
Hive in Big Data lets users run ad hoc searches and analyses on huge datasets stored in Hadoop Distributed File System (HDFS) and other compatible data storage with a familiar SQL-like syntax. When a user enters a query, Hive's query processor converts the SQL-like query into MapReduce jobs, which run on a Hadoop cluster. The query's results are subsequently returned to the user.
Hive's architecture comprises a meta store with metadata about tables and their columns, a query processor that converts SQL-like queries into MapReduce tasks, and driver software that runs these jobs on a Hadoop cluster.
Features of Hive
Hive in Big Data is a popular Hadoop-based data warehouse and SQL-like querying tool. It has various qualities that make it an effective tool for big data analysis, such as:
- SQL-like Interface:
Hive's familiar SQL-like interface makes it simple for users to query and analyze big datasets without the need for programming experience. - Scalability:
Hive in Big Data can handle massive amounts of data stored in HDFS and other data stores compatible with Hadoop. It also offers parallel processing, allowing it to handle sophisticated searches and large data sets. - Flexibility:
Hive supports various data serialization formats, including Avro, Parquet, and ORC, making it a versatile tool capable of handling various use cases and data formats. - Integration:
Hive in Big Data interfaces with other Hadoop ecosystem tools like Pig, Sqoop, and Flume, allowing users to conduct sophisticated data analysis jobs and processes. - External tables:
Hive supports external tables, which allow users to access data stored in other storage systems such as HBase, Cassandra, and Amazon S3. - Partitioning:
Hive offers partitioning, which allows users to separate huge datasets based on parameters such as date, location, or user ID. Restricting the quantity of data that must be scanned improves query performance.
Benefits of Hive
Hive in Big Data provides various advantages for big data analysis, including simplicity, scalability, adaptability, integration, and cost-effectiveness. Let us discuss its advantages in detail.
- Fast
One of Hive's primary advantages is its capacity to quickly process enormous amounts of data. The query optimizer in Hive can optimize queries to reduce the amount of data that must be scanned, thus improving query performance. Hive also offers parallel processing, allowing it to handle sophisticated queries and large data sets. - Familiar
Another significant advantage of Hive is its familiar SQL-like interface. Many developers and data analysts are already familiar with SQL, making it simple to use Hive without any prior knowledge. In addition, Hive's SQL-like syntax allows users to create sophisticated queries and execute data analytic operations easily. This minimizes the learning curve and allows users to begin using Hive to examine massive datasets rapidly. - Scalable
Another key advantage of Hive in Big Data is its scalability. Hive in Big Data can handle massive amounts of data stored in HDFS and other compatible data stores. Hive's support for parallel processing enables it to handle complex queries and Big Data workloads efficiently. Hive also enables partitioning, which allows users to divide big datasets according to certain criteria, minimizing the amount of data that must be scanned.
The Architecture of Hive
Hive's architecture comprises four major components: Hive User Interface, Meta Store, HiveQL Process Engine, and Execution Engine. Let us discuss its architecture in detail.
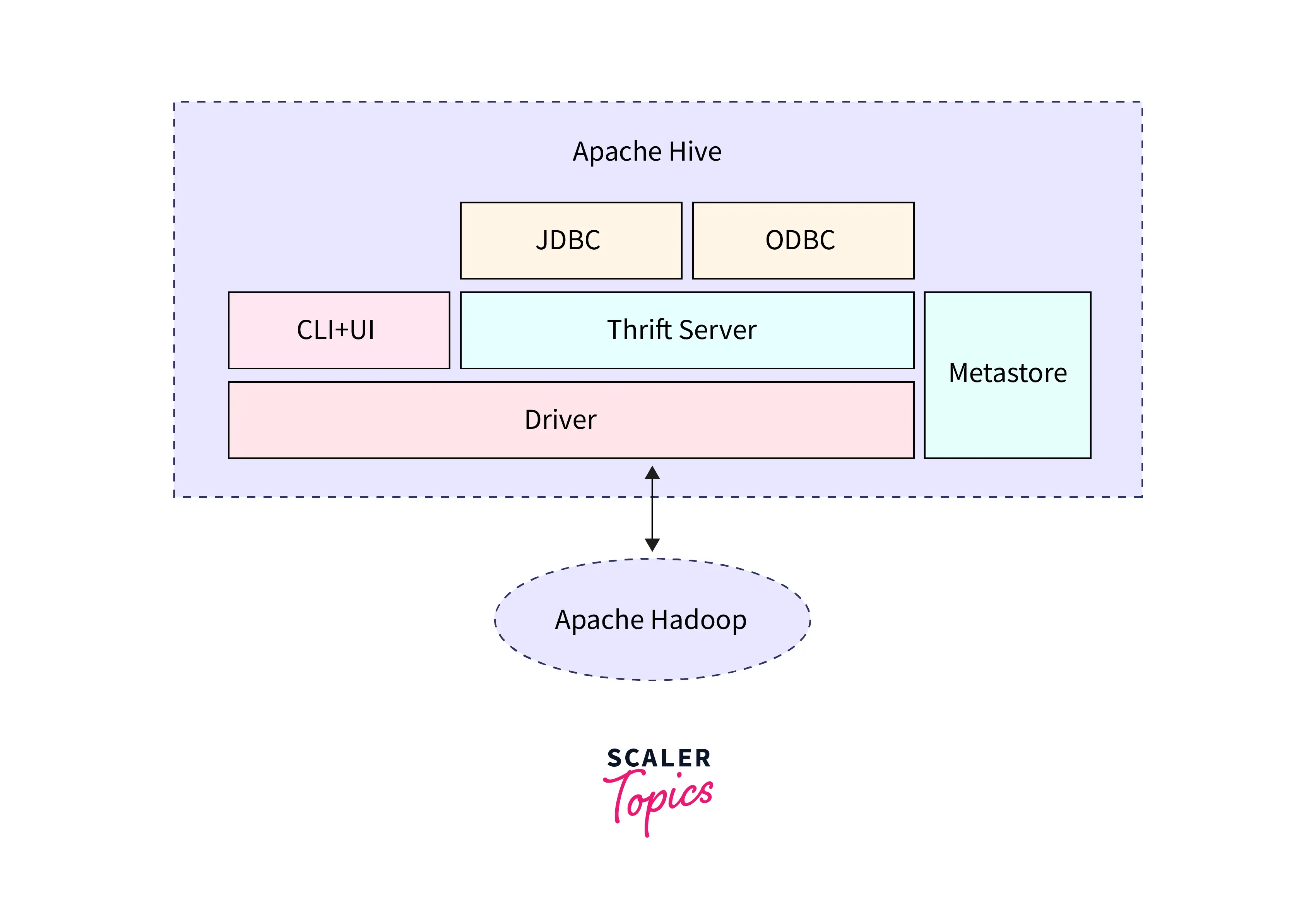
User Interface
Hive's user interface is intended to be straightforward. Users interact with Hive through a SQL-like interface familiar to many developers and data analysts. Users can submit queries and manage Hive sessions through the user interface. Hive in Big Data also has a web-based user interface, the Hive Web Interface, allowing users to enter searches and examine the results in a web browser.
Meta Store
In Hive, the Metastore is a central repository that stores metadata information about the tables, partitions, and databases in Hive such as schema details, table and partition locations, file formats, etc.
The Metastore provides a unified interface for Hive to access metadata information, regardless of where the data is stored. This allows Hive to support multiple storage systems, such as HDFS, S3, and others and provides a layer of abstraction between Hive and the underlying storage systems.
The Metastore is typically implemented using a relational database such as MySQL, Oracle, or PostgreSQL, and is accessed by Hive through a Thrift API. The Metastore can be configured to use different databases, and can also be configured for high availability and scalability.
HiveQL Process Engine
HiveQL is a SQL-like language that Hive uses to interact with data. The HiveQL process engine converts HiveQL queries into MapReduce jobs that the Hadoop environment can execute. The parser, the logical optimizer, the physical optimizer, and the execution engine are the four key components of the process engine. The parser translates the HiveQL code into an abstract syntax tree, which the logical and physical optimizers then optimize. Lastly, the execution engine generates MapReduce jobs that the Hadoop environment may execute.
Execution Engine
The execution engine is a critical component of Hive's architecture. It is in charge of running MapReduce jobs generated by the HiveQL process engine. The execution engine comprises two major parts: the driver and the tasks. The driver is in charge of task coordination and work execution management. The tasks are in charge of carrying out the actual MapReduce jobs. To enable efficient and accurate data processing, the execution engine collaborates closely with the Hadoop environment.
How Does Hive Interact with The Hadoop Framework?
Hive is deeply embedded in the Hadoop environment, interacting with it via the Hadoop Distributed File System (HDFS) and the MapReduce framework. Hive stores data in HDFS and reads and publishes it using Hadoop's InputFormat and OutputFormat APIs. Hive in Big Data also generates MapReduce jobs, which the Hadoop MapReduce framework may perform. Hive's integration with Hadoop allows it to benefit from Hadoop's scalability and fault tolerance, transforming it into an efficient and dependable platform for big data analysis.
- Execute query
Hive turns a query submitted by a user into a directed acyclic network of MapReduce jobs. Hive then sends these jobs for execution to the Hadoop MapReduce framework. The MapReduce framework divides input data into chunks and distributes them among nodes in a cluster for parallel processing. The results of each operation are written back to HDFS and passed on to the next job in the sequence. - Get Plan
Hive communicates with the Hadoop framework in various ways, one of which is retrieving the execution plan for a specific query. When a user sends a query to Hive, the parser parses and analyses the query. Hive then develops an execution plan for the query and delivers it for execution to the Hadoop framework. The execution plan specifies the order in which MapReduce tasks must be performed to complete the query. - Get Metadata
Hive also communicates with the Hadoop framework by acquiring metadata about Hadoop data. Hive maintains a metadata store that contains information about the data structure, such as column names, types, and file formats used to store the data. When a query is sent to Hive, the metadata store is used to determine the data schema and build the execution plan. - Send Metadata
In addition to receiving metadata about the data stored in Hadoop, Hive transmits metadata back to the Hadoop framework during query execution. When a Hive query, for example, is executed, intermediate results are generated and stored in temporary Hadoop files. Hive sends metadata about these files to the Hadoop framework, such as their locations and sizes, to optimize the execution of subsequent jobs. - Send Plan
Hive also connects with the Hadoop framework during query execution by returning the execution plan to Hadoop. The execution plan specifies how the query will be carried out, including the sequence of actions and the resources required for each action. Hadoop then uses this data to schedule and execute activities throughout the cluster efficiently. - Execute Plan
When Hive delivers the execution plan to Hadoop, Hadoop is in charge of carrying out the actions in the plan. For example, Hadoop organizes jobs across the cluster, distributes resources to each task, and runs them all simultaneously. Hive receives updates from Hadoop on the progress and consequences of the activities after they are completed. This allows Hive to provide real-time feedback to the user on the status of the query execution as well as any problems or issues that may arise. - Execute job
Once the execution plan is ready, Hive sends a task to Hadoop to execute the query. Hadoop then separates the task into jobs and assigns them to available nodes in the cluster. The jobs are then executed in parallel by Hadoop, and the results are aggregated and provided to Hive for processing. Hive can then provide the user with real-time feedback on the status of the job execution and any errors or issues that may arise. - Metadata Ops
Hive uses the HDFS to store metadata. Hive first assesses the metadata to extract information about the input files and their locations when a query is executed. Hive then generates a series of MapReduce jobs executed by the Hadoop framework. Throughout the execution, Hive communicates with the JobTracker to track work progress and gather job status. When the job is finished, Hive retrieves the output and puts it in HDFS. - Fetch Result
When the query is completed, Hive communicates with the Hadoop framework to receive the result. The Hadoop framework uses the Hive driver to deliver results to the client. The results are saved in HDFS or other storage systems, from which Hive receives the data. Hive then processes the results before returning them to the user. - Send Results
Hive uses the HDFS to communicate results to the Hadoop framework. The output is saved as files in HDFS, which can be retrieved and processed by other Hadoop applications or tools. Hive has the same MapReduce processing structure as Hadoop, allowing it to process enormous datasets and efficiently distribute work over a cluster of machines. Hive may then take advantage of Hadoop's scalability and fault tolerance features, guaranteeing that even the most complex queries are performed quickly and reliably.
Conclusion
- Hive is a Hadoop-based data warehouse and SQL-style querying tool. It enables users to execute ad-hoc searches and analyses on big datasets without learning languages like MapReduce or Pig.
- Hive allows users to create SQL-like queries that are subsequently converted into MapReduce jobs, making it a powerful and user-friendly data analysis tool.
- Hive supports external tables, partitioning, and data serialization formats such as Avro and Parquet.
- Hive's support for external tables is one of its key features, allowing users to access data from storage systems such as HBase, Cassandra, and Amazon S3.
- Hive's architecture comprises four major components: Hive User Interface, Meta Store, HiveQL Process Engine, and Execution Engine.
- Hive has several benefits for big data analysis, including ease of use, scalability, flexibility, integration, and cost-effectiveness. These characteristics make it a powerful tool frequently used in the Hadoop ecosystem for data warehousing and analysis.