Horizontal Pod AutoScaling in Kubernetes with Examples
Overview
In the world of cloud-native technologies, Kubernetes is a leading orchestration platform for containerized applications. Efficient resource utilization and responsiveness to changing demands are vital for managing container workloads. Kubernetes Horizontal Pod AutoScaler (HPA) automates pod scaling based on metrics, optimizing performance and resource allocation. In this blog, we explore HPA's working principles, algorithms, supported metrics, scaling behavior, and real-world examples.
What is HPA in Kubernetes?
- HPA in Kubernetes automatically adjusts pod replicas based on measured parameters.
- HPA's objective is to ensure applications can handle varying workloads and demands.
- It compares monitored metrics to target values (e.g., CPU utilization) and scales pods accordingly.
- HPA's control loop continuously monitors metrics and makes periodic scaling decisions.
- It optimizes resource and performance utilization, improving efficiency and response to traffic fluctuations.
- HPA Kubernetes is valuable for managing containerized workloads, simplifying application scaling with less user intervention.
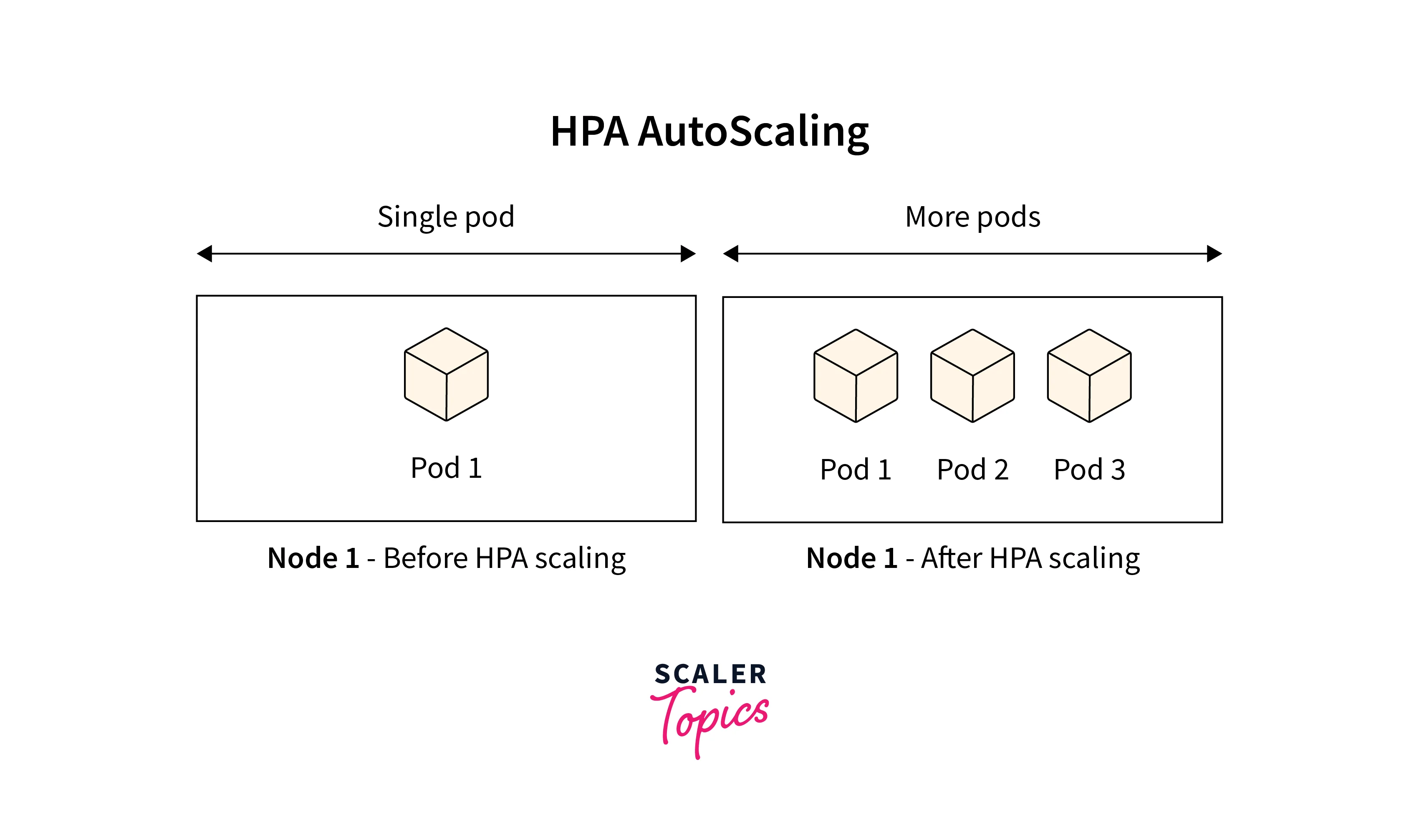
- Through this method, HPA in Kubernetes can automatically adjust the number of pods to fit the actual workload, resulting in the best possible resource and performance utilization.
- It is a useful tool for managing containerized workloads in Kubernetes environments since it makes scaling applications easier and requires less user intervention.
How Does Horizontal Pod AutoScaler Work in Kubernetes?
HPA in Kubernetes works based on the concept of control loops. The HPA Kubernetes controller continuously monitors the specified metrics of the target workload and adjusts the number of replicas (pods) to maintain the desired target metric value. Here's a step-by-step explanation of how HPA Kubernetes works:
- Configuration:
Users set up HPA by defining the metric, target value, and min/max replicas specifying the desired metric to scale on (e.g., CPU utilization, custom application-specific metrics) - Metrics Collection:
HPA collects metrics from specified pods (CPU, custom metrics). The collection of metrics can be based on either resource metrics or custom metrics. - Calculating Desired Replicas:
HPA calculates replicas based on observed metrics and targets. It uses a formula to determine the required number of pods to meet the target metric value - Scaling Actions:
HPA Kubernetes updates replica count via Kubernetes API for scaling.
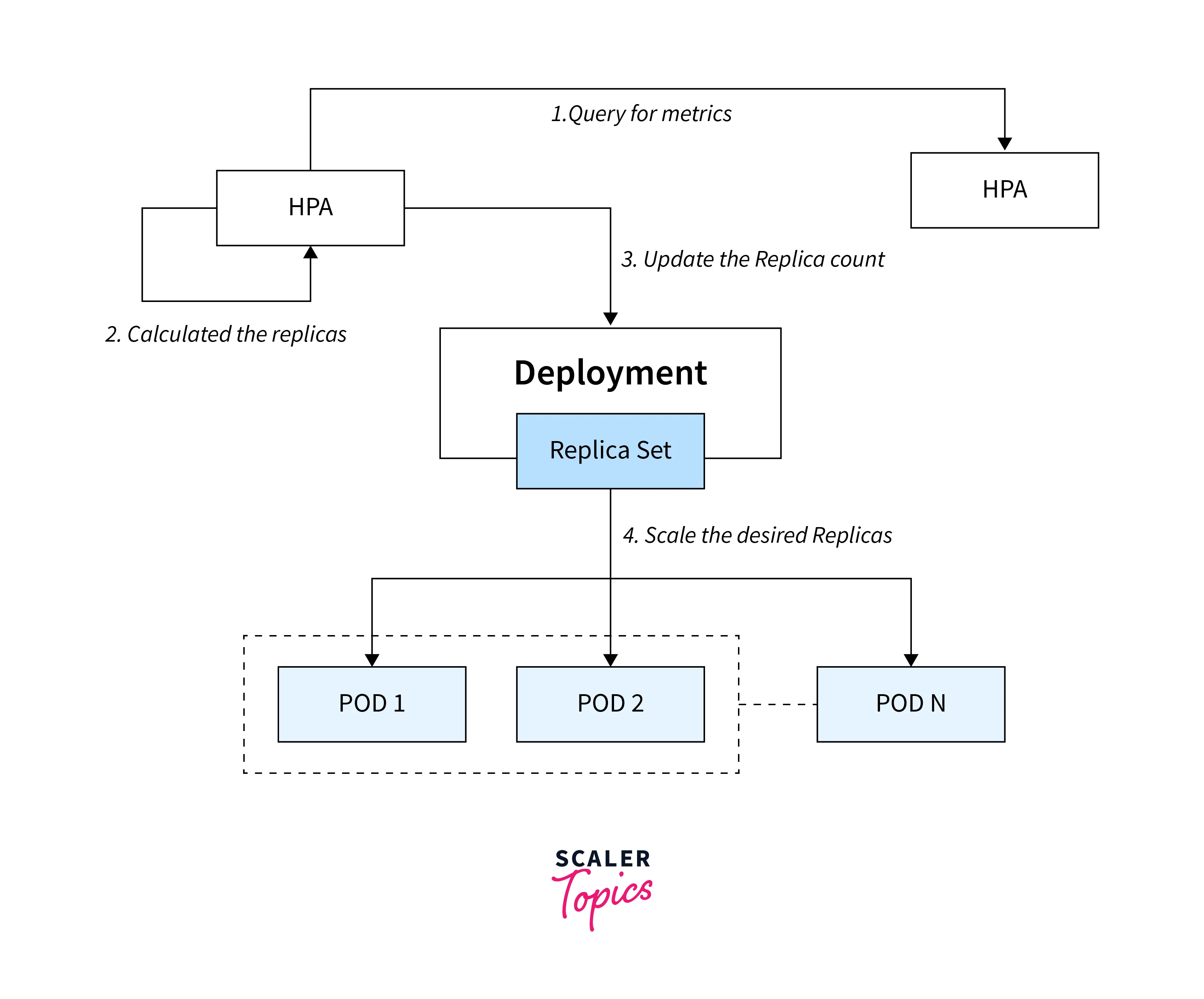
By utilizing HPA Kubernetes, clusters can dynamically adjust the number of pods to efficiently utilize resources and maintain optimal performance in response to varying workloads. HPA in Kubernetes helps ensure that applications can scale up or down as needed, providing a more resilient and responsive infrastructure in Kubernetes environments.
Algorithm Details
The HPA Kubernetes uses an algorithm to determine the desired number of replicas based on observed and target metric values. It considers factors like missing metrics and not-yet-ready pods to calculate the ratio between current and desired metric values such as:
- Metric Ratio Calculation:
The HPA controller calculates the desired replica count using the formula: desiredReplicas = ceil[currentReplicas * (currentMetricValue / desiredMetricValue)]. If currentMetricValue exceeds desiredMetricValue, replicas scale up; if it's lower, replicas scale down. - Tolerance Check:
HPA skips scaling actions if the "currentMetricValue" is close enough to "desiredMetricValue" within a configurable tolerance (default 0.1), preventing unnecessary and rapid scaling. - Handling Missing Metrics:
If some pods have missing metrics, HPA assumes KaTeX parse error: Expected 'EOF', got '%' at position 4: 100%̲ consumption (scale-down) or KaTeX parse error: Expected 'EOF', got '%' at position 2: 0%̲ consumption (scale-up) of the desired metric value. - Not-Yet-Ready Pods:
HPA considers not-yet-ready pods as contributing KaTeX parse error: Expected 'EOF', got '%' at position 2: 0%̲ to the desired metric value. - Recomputing Average:
After considering missing metrics and not-yet-ready pods, HPA recomputes the usage ratio. If the new ratio reverses scale direction or falls within the tolerance range, no scaling occurs; otherwise, it adjusts the number of pods accordingly.
By following this algorithm, the HPA in Kubernetes efficiently and intelligently adjusts the number of replicas to meet the desired metric values, providing automatic and adaptive scaling of applications based on observed workloads.
Object API
The Object API in HPA Kubernetes includes APIs and resources for managing cluster objects, representing the desired state of workloads and applications. Users interact with API resources like pods, services, and deployments declaratively through kubectl. The API Server handles incoming requests and object storage in the etcd database. Custom Resource Definitions (CRDs) allow users to extend HPA in Kubernetes with custom resources. The Object API simplifies workload management, abstracting complexities and letting users focus on application logic while HPA in Kubernetes handles infrastructure and scaling.
Workload Scale Stability
Workload scale stability in HPA Kubernetes makes reliable scaling decisions to maintain application stability. It aims to avoid excessive and frequent scaling actions to prevent instability, resource waste, and performance problems. Key factors for workload scale stability include:
- Metrics and Thresholds:
Choosing suitable metrics and thresholds ensures accurate scaling without overreacting to minor fluctuations. - Scaling Behavior:
Configure HPA Kubernetes scaling behavior to match workload characteristics and requirements. - Cooldown Period:
Implement a cooldown period to prevent rapid scaling actions and stabilize the workload. - Metrics Aggregation:
Properly aggregate multiple metrics for balanced and accurate scaling decisions. - Predictive Scaling:
Advanced HPA in Kubernetes may use predictive algorithms for proactive scaling based on historical data and trends.
By ensuring workload scale stability, the HPA Kubernetes can efficiently manage resources, avoid unnecessary fluctuations in the number of replicas, and provide a stable and reliable experience for both the application and its users in the Kubernetes cluster.
Rolling Update and AutoScaling
Rolling updates and autoscaling are two essential features in HPA Kubernetes that allow for seamless and efficient management of application deployments and resource utilization.
Rolling Update:
Rolling updates in HPA Kubernetes refer to the process of updating a running application by gradually replacing instances of the old version with instances of the new version done in a controlled and non-disruptive manner The rolling update process involves the following steps:
- Creating New Pods:
Kubernetes HPA creates new Pods based on the updated deployment configuration. - Gradual Replacement:
New Pods replace old ones gradually to maintain sufficient healthy instances. - Monitoring and Verification:
Kubernetes HPA monitors Pod health; if issues arise, it rolls back to the previous version for stability. - Rollout Strategy:
Different strategies like "Recreate" and "RollingUpdate" manage updates with or without downtime.
Rolling updates are critical for maintaining application availability and stability during deployments. They allow for seamless updates with minimal disruptions to users.
Autoscaling:
Autoscaling in Kubernetes HPA involves automatically adjusting the number of replicas (Pods) of a deployment based on certain criteria, such as CPU utilization, memory consumption, or custom metrics. Kubernetes supports two types of autoscaling:
- Horizontal Pod Autoscaler (HPA):
As mentioned earlier, HPA automatically scales the number of replicas of a deployment up or down based on predefined metrics. - Vertical Pod Autoscaler (VPA):
VPA, on the other hand, scales the resource requests and limits of individual Pods based on their actual resource usage. It adjusts the resource requests and limits to match the actual resource consumption, optimizing resource allocation for each Pod.
Combining rolling updates with autoscaling allows Kubernetes to automatically adjust the number of replicas based on resource utilization and efficiently update the application without causing disruptions.
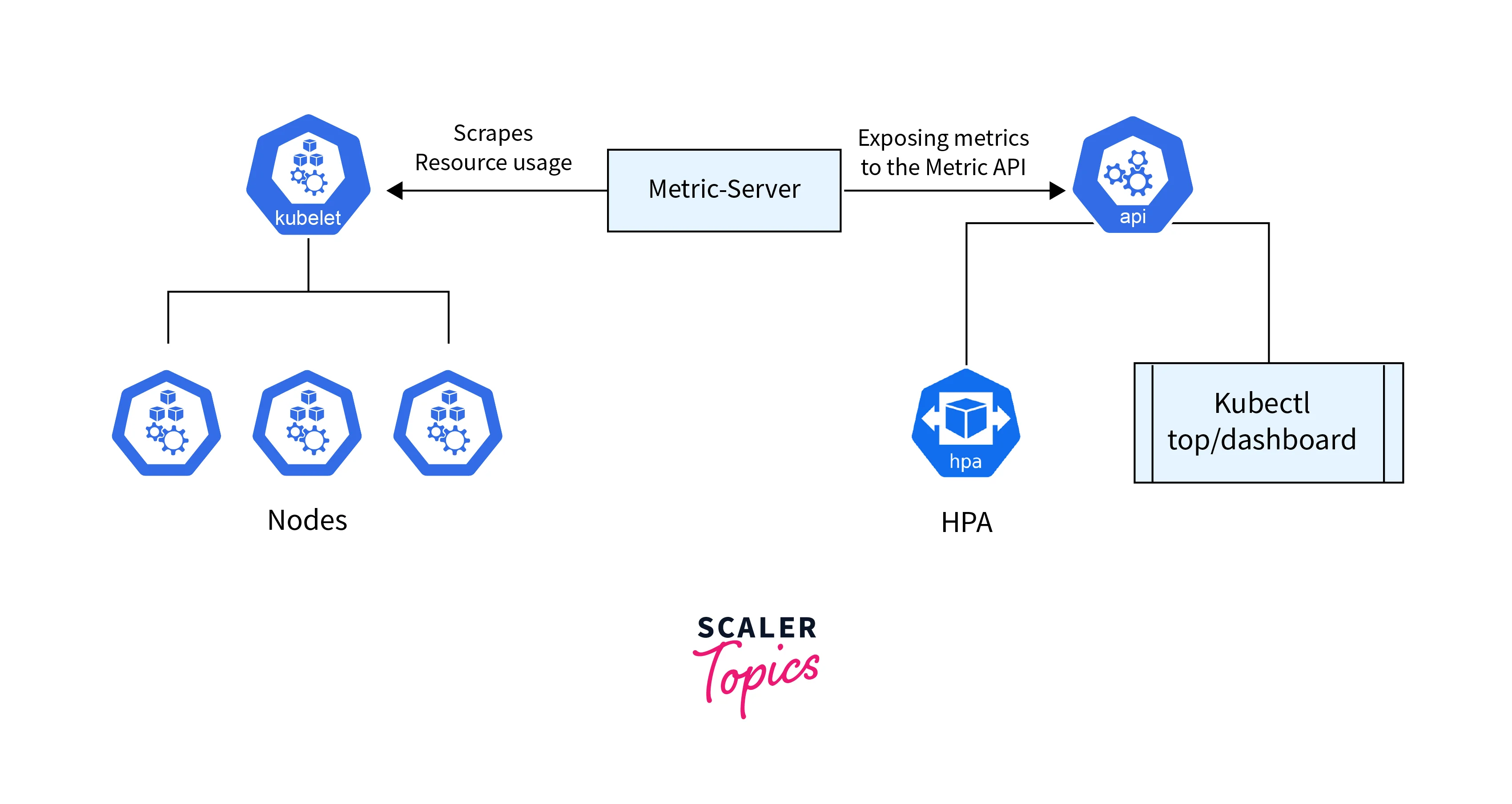
Resource Metrics Support
Resource metrics support in Kubernetes enables the HPA to scale deployment replicas based on resource utilization metrics like CPU and memory usage. Here's how resource metrics support works in Kubernetes HPA:
- Monitoring Resource Utilization:
HPA Kubernetes collects CPU and memory usage data from Kubernetes metrics or custom metrics API. - Calculating Replicas:
HPA Kubernetes calculates desired replicas using the provided formula based on resource utilization data. - Scaling Decision:
HPA Kubernetes decides to scale up or down depending on the calculated desired replicas. - Implementation:
HPA Kubernetes communicates with Kubernetes API to adjust replicas for the deployment. Kubernetes handles creating or terminating Pods accordingly.
The HPA in Kubernetes continuously monitors Pod resource utilization and compares it to the user-defined target value, which can be a percentage or an absolute quantity of CPU/memory.
Custom Metrics Scaling
Custom metrics scaling in Kubernetes allows the Horizontal Pod Autoscaler (HPA in Kubernetes) to scale the number of replicas of a deployment based on custom-defined metrics. These metrics are specific to the application and its requirements. Here's how custom metrics scaling works in Kubernetes HPA:
- Defining Custom Metrics:
Custom metrics are external metrics that are not available by default in HPA Kubernetes. These metrics need to be collected and exposed by external monitoring systems, such as Prometheus, Datadog, or any other monitoring tool capable of exporting custom metrics. - Configuring External Metrics API:
Kubernetes allows custom metrics to be collected and exposed via the External Metrics API. - Defining HPA with Custom Metrics:
Once the custom metrics are available through the External Metrics API, the user can define an HPA resource in Kubernetes, specifying the custom metrics as the scaling target. - Collecting Custom Metrics:
The HPA continuously queries the External Metrics API to collect the custom metrics data. It retrieves the metric values for each Pod in the deployment.
Custom metrics scaling allows developers to define auto-scaling rules based on application-specific performance metrics, enabling more fine-tuned and tailored scaling decisions.
Multiple Metrics Scaling
The Kubernetes in HPA scaling feature enables the HPA to change the deployment's replica count based on a mix of different parameters. By taking into account a variety of factors. Here's how multiple metrics scaling works in Kubernetes HPA:
- Defining Multiple Metrics:
Multiple metrics can be a combination of resource metrics (CPU and memory utilization) and custom metrics. These metrics are collected from the Kubernetes API server for resource metrics or from external monitoring systems via the External Metrics API for custom metrics. - Configuring HPA with Multiple Metrics:
The user defines the resource in HPA Kubernetes and specifies the multiple metrics to be used for scaling. Each metric is associated with a target value and other scaling parameters. - Collecting Metric Data:
The HPA in Kubernetes continuously collects metric data for each Pod in the deployment from the Kubernetes API server or the External Metrics API, depending on the type of metrics used. - Evaluating Metrics and Scaling Decision:
For multiple metrics scaling, the HPA in Kubernetes evaluates the performance of the application based on each metric independently. It calculates the desired number of replicas for each metric using the formula:
Here, currentMetricValue(metric) is the value collected for the specific metric, and desiredMetricValue(metric) is the target value set by the user for that metric.
- Scaling Behavior:
The HPA Kubernetes communicates with the Kubernetes API server to adjust the number of replicas of the deployment. If the final desired number of replicas is greater than the current number, the HPA scales up the deployment. If it is less than the current number, the HPA scales down the deployment.
Multiple metrics scaling provides a more comprehensive approach to auto-scaling, as it takes into account various aspects of the application's performance and resource usage.
API Metrics Support
Kubernetes HPA's API metrics support allows users to scale applications based on custom metrics from the API server. This flexibility lets users define scaling criteria using custom metrics tailored to their application's needs. Here's how API metrics support works in Kubernetes HPA:
- Defining Custom Metrics:
Users can define custom metrics for their application by using Custom Metrics API in Kubernetes. These custom metrics can represent any application-specific performance or resource utilization data that is exposed by the application itself or collected from external sources. - Exposing Custom Metrics:
The application or an external monitoring system exposes the custom metrics to the Kubernetes API server using the Custom Metrics API. - Configuring HPA with API Metrics:
Once the custom metrics are exposed through the Custom Metrics API, users can configure the Horizontal Pod Autoscaler to use these metrics for scaling.
Scaling Behavior Scaling
In Kubernetes, scaling behavior refers to how the Horizontal Pod Autoscaler (HPA) modifies the number of replicas in a deployment based on the metrics and scaling policies detected. The application's responsiveness and resource usage are ensured, and scaling action is decided upon in response to changes in workload needs. The scaling behavior in HPA Kubernetes can be described as follows:
- Upward Scaling:
When the observed metric values exceed the desired target value set by the user, the HPA triggers upward scaling to increase the number of replicas. The formula used for upward scaling is desiredReplicas = ceil[currentReplicas * (currentMetricValue / desiredMetricValue)]. If the current metric value is greater than the desired metric value, the currentMetricValue / desiredMetricValue ratio will be greater than 1, resulting in an increase in the number of replicas. - Downward Scaling:
When the observed metric values are lower than the desired target value set by the user, the HPA triggers downward scaling to decrease the number of replicas. The formula used for downward scaling is the same as for upward scaling: desiredReplicas = ceil[currentReplicas * (currentMetricValue / desiredMetricValue)]. If the current metric value is less than the desired metric value, the currentMetricValue / desiredMetricValue ratio will be less than 1, resulting in a decrease in the number of replicas. - Scaling Tolerance:
To avoid rapid and unnecessary scaling actions due to slight metric fluctuations, HPA uses a scaling tolerance, which is configurable and set to 0.1 by default. If the ratio currentMetricValue / desiredMetricValue is within the scaling tolerance range of 1 (e.g., between 0.9 and 1.1), the HPA does not trigger any scaling action, as it considers the current workload to be stable.
HPA's scaling behavior offers an automated and intelligent solution for managing application scalability according to changing demands. It enables applications to handle varying workloads efficiently while maintaining stability and optimal resource usage. By configuring proper metrics and scaling policies, users ensure their applications automatically scale up or down based on performance requirements.
Examples
To illustrate HPA's capabilities, let's consider a sale, an e-commerce application faces increased traffic. To maintain a smooth shopping experience, the challenge is to configure HPA with suitable CPU utilization metrics and target values for automatic scaling. Here are the steps for setting up the HPA:
- Define the Deployment:
We first define a Kubernetes Deployment that specifies the desired state of the application. This includes information such as the container image, resource requests, and limits. We also ensure that the Pod's CPU requests and limits are appropriately set to enable resource-based scaling. - Create the HorizontalPodAutoscaler:
Next, we create the HorizontalPodAutoscaler resource. We specify the target metric to be CPU utilization, the target value to be 70%, and the desired minimum and maximum number of replicas. For example: - Metrics Collection:
The HPA controller starts collecting CPU utilization metrics from the Pods of the specified Deployment. - Scaling Decision:
As user traffic increases during the sale event, the application experiences higher CPU utilization. Once the observed CPU utilization exceeds 70%, the HPA controller calculates the desired number of replicas using the defined formula. - Scaling Action:
IN HPA Kubernetes communication is done with the Kubernetes API server to update the Deployment with the new replica count. Kubernetes then automatically scales up the number of Pods, adding more instances of the application to handle the increased load.
After the sale event, as user traffic decreases, the HPA recalculates replicas and scales down the application to conserve resources. This dynamic adjustment enables the e-commerce app to efficiently handle varying workloads, ensuring a seamless shopping experience during peak events.
FAQs
Q. Can I use HPA with any Kubernetes deployment?
A. Yes, HPA is compatible with both deployments and replica sets in Kubernetes.
Q. Can I use custom metrics from my application with HPA?
A. Absolutely! HPA allows you to scale based on custom metrics, offering more flexibility and adaptability.
Q. Does HPA replace the need for manual scaling?
A. While HPA automates scaling to a large extent, it's essential to fine-tune and optimize HPA policies to match your application's unique characteristics.
Conclusion
- In conclusion, the Horizontal Pod AutoScaler (HPA) in Kubernetes is a powerful tool that enables automatic and dynamic scaling of containerized workloads. With HPA, Kubernetes users can efficiently manage resource utilization and ensure optimal performance in response to varying workloads.
- By continuously monitoring specified metrics and comparing them to target values, HPA intelligently adjusts the number of replicas (pods) in a deployment or replica set.
- With HPA, applications can seamlessly handle increased traffic or demand by scaling up the number of replicas and automatically scaling down when the workload decreases, optimizing resource usage.
- The scaling tolerance feature prevents unnecessary and rapid scaling actions, ensuring the application remains stable under slight fluctuations in metrics.
- Additionally, HPA can leverage custom metrics exposed through the Kubernetes API or External Metrics API, providing greater flexibility in defining scaling criteria.
- By embracing HPA, Kubernetes users can confidently scale their applications to meet changing demands, making it an indispensable component of any cloud-native environment.