Introduction to Image Classification
Overview
Image classification is a computer vision technique that allows machines to categorize images based on their features. This technology has many practical applications, including self-driving cars, face recognition, and content filtering. In this blog, we will provide an introduction to image classification, explaining how it works, and providing examples of code.
What is Image Classification?
Image classification is a type of computer vision task that involves assigning an image to one of several predefined categories or classes. For example, an image of a dog might be classified as a "dog" while an image of a cat might be classified as a "cat". This task can be performed by humans, but it is often more efficient to use machine learning algorithms.
How does Image Classification Work?
The process of image classification involves several steps. First, the algorithm needs to be trained on a dataset of labeled images. This means that each image in the dataset is assigned a label or category that the algorithm will learn to recognize. If the algorithm has been trained once, then it will be used to classify new images later.
When a new image is presented to the algorithm, it is first preprocessed to extract features that will be used to make the classification. These features might include things like the color, texture, and shape of objects in the image. The algorithm then uses these features to predict the class that the image belongs to.
Structure for Performing Image Classification
Let's see how performing image classification typically involves the following steps and structure:
-
Data Preparation:
Gather a labeled dataset of images for training and evaluation. Split the dataset into training, validation, and testing sets. Preprocess the images, which may include resizing, normalization, and augmentation techniques. -
Model Selection:
Choose an appropriate model architecture for image classification. Popular choices include convolutional neural networks (CNNs) such as VGG, ResNet, Inception, or MobileNet. You can also use pre-trained models that have been trained on large-scale image datasets like ImageNet. -
Model Configuration:
Set up the model architecture, including the number of layers, number of filters, activation functions, pooling layers, and other hyperparameters. You can use existing model architectures or design your own based on the requirements of your task. -
Model Training:
Train the model using the labeled training dataset. During training, the model learns to extract meaningful features from the images and predict the corresponding labels. The training process involves feeding the images through the network, calculating the loss, and optimizing the model parameters using backpropagation and gradient descent algorithms. -
Model Evaluation:
Assess the performance of the trained model using the labeled validation dataset. Compute metrics such as accuracy, precision, recall, and F1 score to evaluate the model's performance. Make adjustments to the model architecture or hyperparameters as needed to improve performance. -
Model Testing:
Evaluate the final trained model on the unseen testing dataset to obtain a final assessment of its performance. This step helps to determine how well the model generalizes to new, unseen images. -
Model Deployment:
Once the model has been trained and evaluated, deploy it for real-world use. This may involve integrating the model into an application or system where it can classify new images in real-time.
It's important to note that this is a high-level overview of the structure for performing image classification. Each step may involve additional considerations and techniques depending on the specific requirements of the task.
Image Classification Metrics
When evaluating the performance of an image classification model, several metrics can be used to measure its accuracy and effectiveness. Here are some commonly used metrics for image classification:
-
Accuracy:
Accuracy is the most straightforward metric and measures the overall correctness of the model's predictions. It is calculated as the ratio of correctly classified images to the total number of images in the dataset. -
Confusion Matrix:
A confusion matrix provides a more detailed analysis of the model's performance by showing the counts of true positive, true negative, false positive, and false negative predictions. From the confusion matrix, various other metrics can be derived. -
Precision:
Precision measures the proportion of correctly predicted positive samples out of the total predicted positives. It is calculated as true positives divided by the sum of true positives and false positives. Precision is useful when the cost of false positives is high. -
Recall (Sensitivity or True Positive Rate):
Recall measures the proportion of correctly predicted positive samples out of the actual positive samples in the dataset. It is calculated as true positives divided by the sum of true positives and false negatives. Recall is important when the cost of false negatives is high. -
F1 Score:
The F1 score is the harmonic mean of precision and recall. It provides a balanced measure between the two metrics and is often used when the dataset is imbalanced. It is calculated as 2 _ ((precision _ recall) / (precision + recall)). -
Specificity:
Specificity measures the proportion of correctly predicted negative samples out of the actual negative samples. It is calculated as true negatives divided by the sum of true negatives and false positives. Specificity is useful when the cost of false positives is high. -
Accuracy per Class:
In some cases, it is important to examine the performance of the model in each class. Accuracy per class provides insights into how well the model performs for specific categories within the dataset. -
Receiver Operating Characteristic (ROC) Curve:
The ROC curve is a graphical representation of the true positive rate (sensitivity) against the false positive rate (1 - specificity) at various classification thresholds. It helps evaluate the model's performance across different thresholds and can be used to determine the optimal threshold for decision-making. -
Area Under the Curve (AUC):
The AUC is the area under the ROC curve and provides a single scalar value that represents the overall performance of the model. It is a commonly used metric to compare different models or evaluate the performance of a binary classification model.
These metrics provide a comprehensive assessment of the model's performance in image classification tasks. It's important to consider the specific goals and requirements of the task when selecting the appropriate metrics to evaluate the model.
Image Classification vs. Object Detection
Here's a comparison table highlighting the main differences between image classification and object detection:
| Image Classification | Object Detection | |
|---|---|---|
| Definition | Assigning a single label to an image | Locating and classifying multiple objects within an image |
| Output: | Single class label | Multiple bounding boxes with class labels |
| Task | Categorizing images into classes | Locating and identifying objects in an image |
| Model Input | Entire image | Entire image or regions of interest (ROI) |
| Model Output | Class probability distribution | Bounding boxes and class labels |
| Training Data | Labeled images | Labeled images with bounding box annotations |
| Training Process | Learning feature representations | Learning feature representations and object localization |
| Use Cases | Image tagging, content filtering, scene recognition, disease diagnosis, facial recognition | Object detection, instance segmentation, autonomous driving, object tracking |
It's important to note that while image classification focuses on assigning a single label to an entire image, object detection goes beyond that by identifying and localizing multiple objects within an image. Object detection combines both classification and localization tasks, providing not only the class labels but also the bounding boxes around the detected objects.
Both image classification and object detection have their unique applications and use cases, depending on the requirements of the task at hand.
Different Algorithms for Image Classification
Several algorithms and models have been widely used for image classification. Here are some of the prominent ones:
-
Convolutional Neural Networks (CNNs):
CNNs have revolutionized image classification and are the most popular choice for this task. They are designed to automatically learn hierarchical features from images using convolutional layers, pooling layers, and fully connected layers. Well-known CNN architectures include AlexNet, VGG, GoogLeNet (Inception), ResNet, and DenseNet.
-
Support Vector Machines (SVM):
SVM is a traditional machine learning algorithm that can be used for image classification. SVM finds an optimal hyperplane to separate different classes based on extracted features from the images. Features can be obtained using techniques such as Histogram of Oriented Gradients (HOG) or Scale-Invariant Feature Transform (SIFT).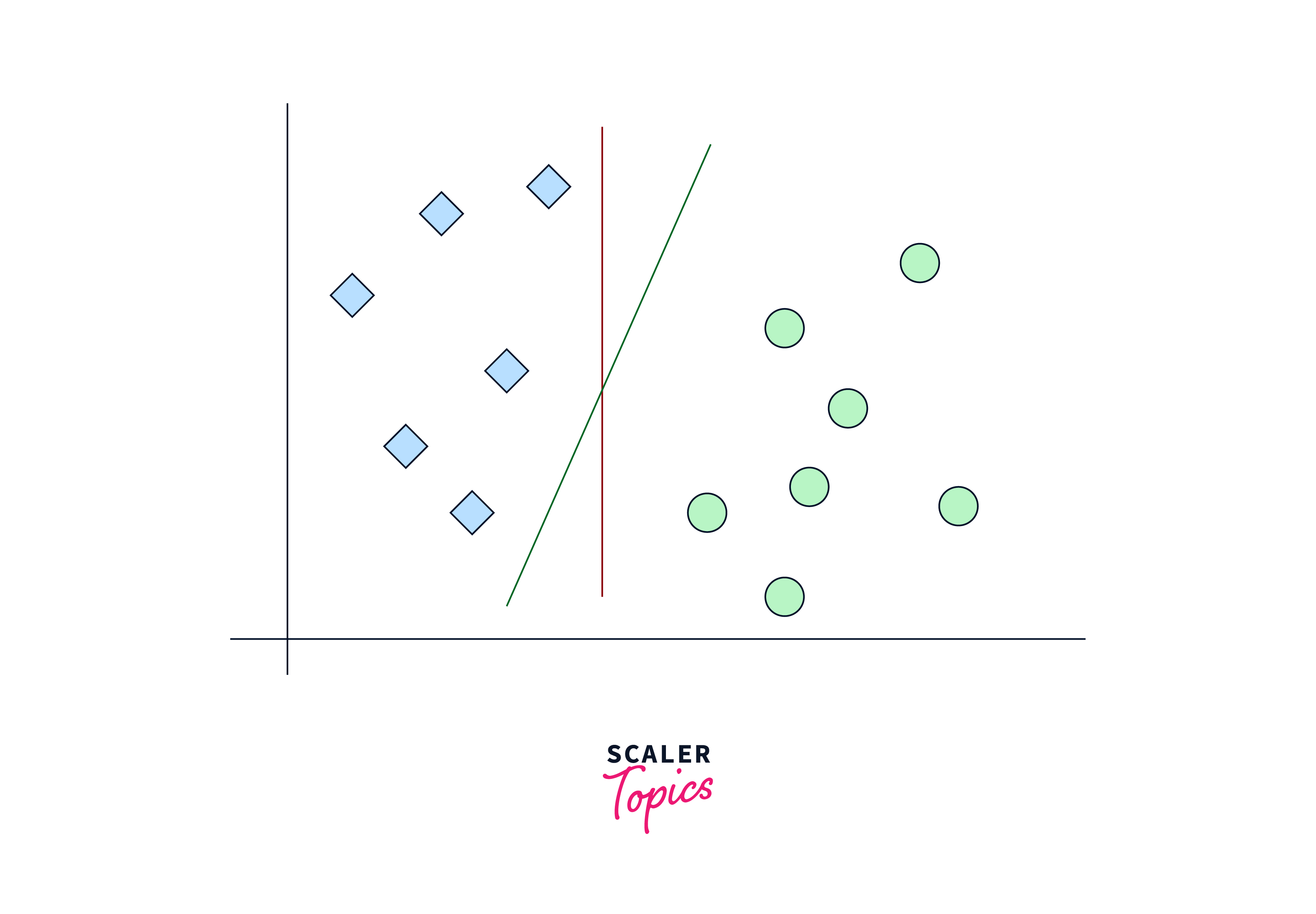
-
Random Forest:
Random Forest is an ensemble learning algorithm that combines multiple decision trees. Each tree is trained on a random subset of features and votes for the final class prediction. Random Forest has been applied to image classification tasks by extracting relevant features from the images.
-
K-Nearest Neighbors (KNN):
KNN is a simple and intuitive algorithm that classifies samples based on the class labels of their nearest neighbors in the feature space. It can be applied to image classification by representing images as feature vectors and finding the nearest neighbors based on distance metrics.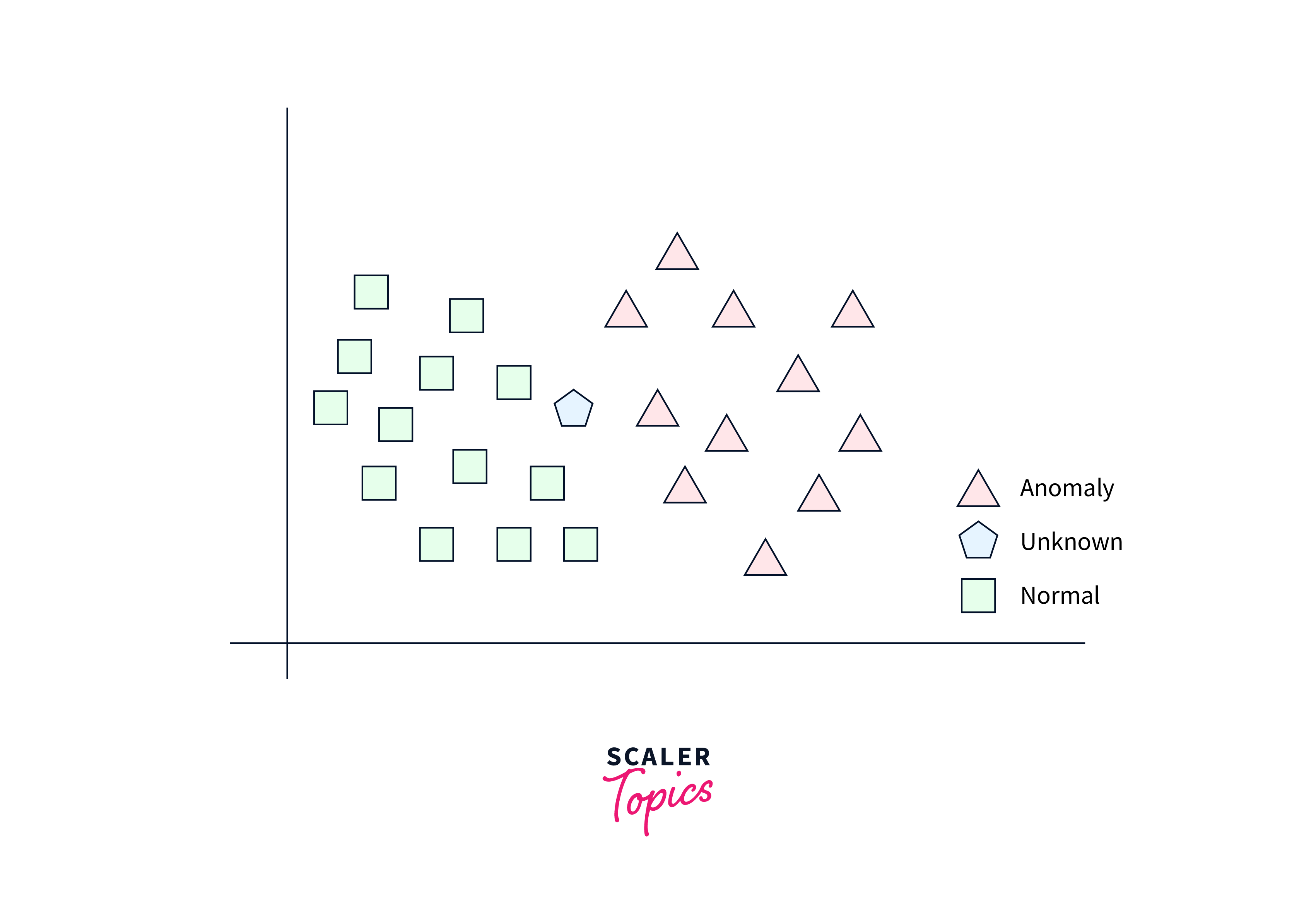
-
Naive Bayes:
Naive Bayes is a probabilistic classifier based on Bayes' theorem. It assumes independence among features and calculates the probability of a sample belonging to each class. Naive Bayes can be used for image classification by extracting relevant features from the images and applying the classifier.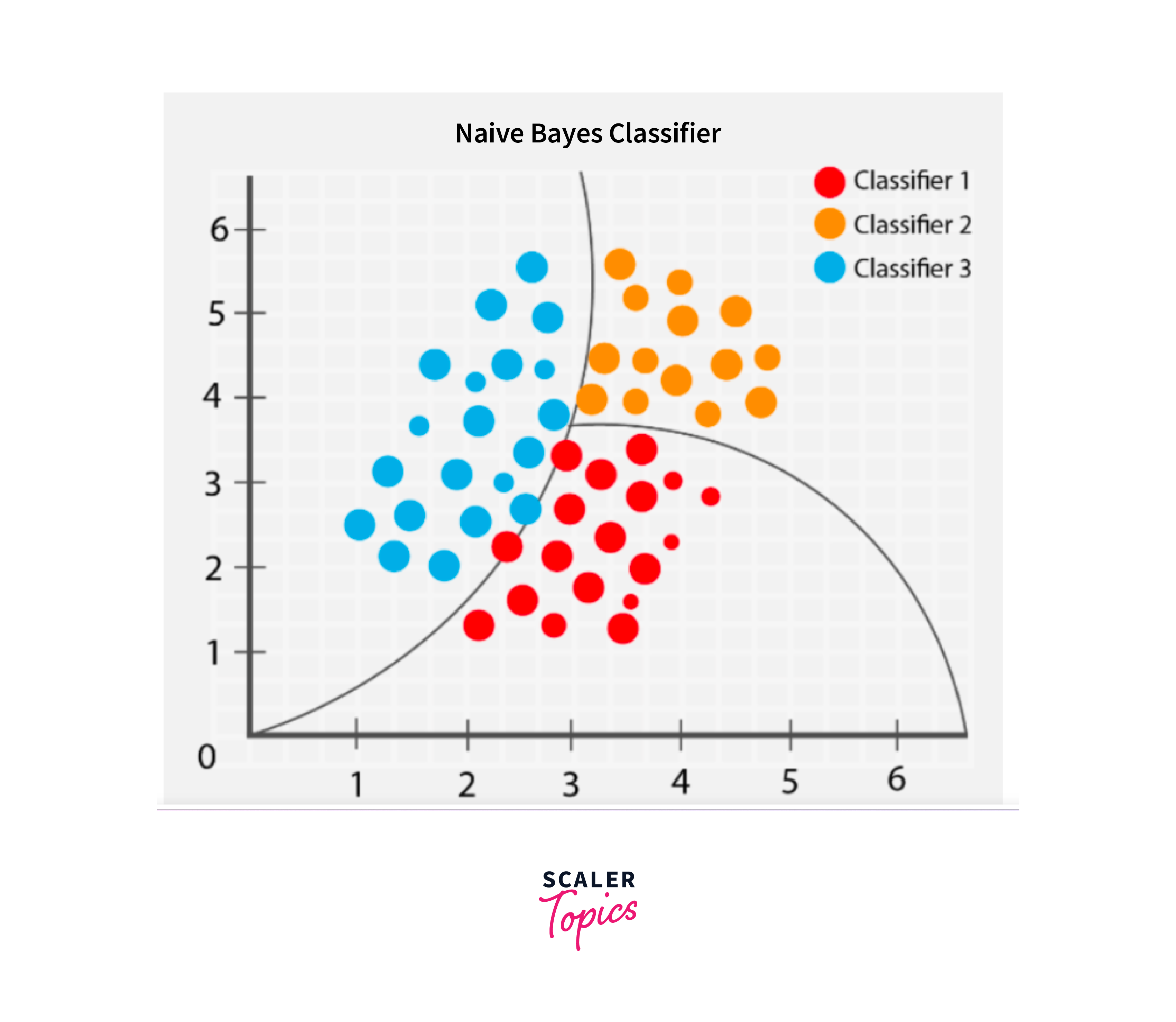
-
Deep Learning Models:
In addition to CNNs, various deep learning models have been used for image classification, such as Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Transformers. These models can capture sequential or spatial dependencies in images and have been successful in certain image classification domains, such as text recognition or scene understanding.
It's important to note that CNNs, particularly with deeper architectures, have shown superior performance in image classification tasks in recent years. However, the choice of algorithm depends on the specific requirements of the task, available data, and computational resources. Additionally, transfer learning, where pre-trained models on large datasets are fine-tuned for specific image classification tasks, has become a common practice for achieving state-of-the-art performance.
Applications of Image Classification
Image classification is a field of computer vision that has many practical applications in various industries, including:
- Object Recognition:
Image classification is used for recognizing and identifying objects in an image, such as cars, pedestrians, animals, or other objects of interest. This can be used in autonomous vehicles, surveillance systems, or in medical imaging. - Medical Diagnosis:
Image classification is widely used in medical diagnosis to identify abnormalities and diagnose diseases. It is used in radiology to identify tumors, fractures, or other medical conditions from medical images such as X-rays, CT scans, or MRI images. - Quality Control:
Image classification is used in manufacturing industries to detect defects in products, such as scratches, dents, or missing components. It can also be used to identify and sort products based on their quality or characteristics. - Agriculture:
Image classification is used in agriculture to monitor crop health and yield. It can identify plant diseases, pests, and nutrient deficiencies, allowing farmers to take corrective actions in real-time. - Security and Surveillance:
Image classification is used in security and surveillance systems to identify people, vehicles, or objects of interest. It can be used to detect suspicious behavior or identify potential threats, such as unattended bags or unauthorized vehicles. - Social Media:
Image classification is used in social media to recognize and tag images automatically, allowing users to easily search and categorize images based on their content. This can also be used for sentiment analysis and understanding user preferences.
Overall, image classification has numerous applications across a wide range of industries, and its importance is only expected to grow in the coming years.
Image Classification with OpenCV and Python
Let's see some code examples that demonstrate how to perform image classification using an OpenCV in Python:
-
Step - 1: Importing the required libraries like TensorFlow and Keras
-
Step - 2: A dataset from the keras library, the cifar10 dataset is loaded
-
Step - 3: Now Data in the dataset is preprocessed for training
-
Step - 4: Defining the CNN architecture
-
Step - 5: Compiling and training the model
Output:

-
Step - 6: Saving the model
Explanation:
- The above code example shows how to perform image classification on the CIFAR-10 dataset using a CNN. The CIFAR-10 dataset consists of 60,000 images as 32x32 color images with 6,000 images per class as total 10 classes.
- The code first loads the dataset using the keras.datasets.cifar10.load_data function. Then the data is preprocessed by normalizing the pixel values to be between 0 and 1.
- Next, the CNN architecture is defined using the Sequential API in Keras. The architecture consists of three convolutional layers followed by two fully connected layers. The output layer has 10 units, which correspond to the 10 different categories in the CIFAR-10 dataset.
- After defining the architecture, the model is compiled using the SparseCategoricalCrossentropy loss function and the Adam optimizer. The model is then trained on the training data for 10 epochs, with the validation data used for evaluating the model's performance.
Object Recognition With OpenCV
Object recognition is the process of identifying and classifying objects within images or video streams. It involves detecting and localizing specific objects of interest and assigning them corresponding labels or categories. Object recognition is essential in various applications such as autonomous vehicles, robotics, surveillance systems, augmented reality, and image retrieval. By enabling machines to understand and interpret their visual environment, object recognition helps automate tasks, provide contextual information, and enhance decision-making capabilities.
Object Recognition With OpenCV
Let's outline the steps involved in performing object recognition using OpenCV and Python:
-
Loading and Preprocessing Images:
- Import the necessary libraries (e.g., OpenCV, NumPy ).
- Load a dataset of images containing the objects of interest.
- Preprocess the images by resizing, normalizing, or applying other desired transformations.
-
Training a Classifier:
- Extract relevant features from the preprocessed images using techniques like HOG or SIFT.
- Split the dataset into training and testing sets.
- Train a classifier, such as SVM or Random Forest, on the training set using the extracted features.
- Evaluate the classifier's performance on the testing set to assess its accuracy.
-
Detecting Objects in New Images:
- Load a new image or capture it from a camera feed.
- Preprocess the new image similar to the training images.
- Apply the trained classifier to detect objects in the image.
- Draw bounding boxes around the detected objects and label them with the corresponding class.
Discussion of the Results and Potential Areas for Improvement:
After performing the object recognition, you can evaluate the results, consider potential improvements, and optimize the code. Here are some sample code snippets to illustrate these steps:
Output:

Potential areas for improvement
- Experimenting with different feature extraction techniques or using deep learning models for feature extraction.
- Fine-tuning hyperparameters of the classifier or exploring other classifiers.
- Augmenting the training data with additional variations to improve generalization.
- Exploring more advanced object detection algorithms like Faster R-CNN or YOLO for improved accuracy and speed.
- Optimizing the code for real-time object recognition by leveraging hardware acceleration or model compression techniques.
Conclusion
- In conclusion, image classification is a powerful technique that has many applications in various fields.
- The ability to categorize images into different classes and recognize patterns is important for many machine learning tasks.
- The image classification is one of the fundamental building blocks for achieving recognizing patterns.