Image Classification in Deep Learning
Overview
This article offers an extensive examination of image classification in deep learning, focusing on the advanced techniques that contribute to exceptional performance. We delve into the fundamentals of image classification, deep learning models, and their implementation and evaluation methodologies. Additionally, we explore real-world applications spanning numerous industries, emphasizing the transformative influence of image classification in deep learning and contemplating the potential future developments within the domain.
Introduction
Image classification is an essential component of computer vision, entailing the organization of images into separate classes according to their content. The swift expansion of digital images has resulted in an increasing need for automated and precise image classification systems. These systems are employed across various sectors, such as healthcare, finance, retail, and beyond. In recent years, machine learning approaches, especially image classification in deep learning techniques, have garnered substantial interest due to advancements in computing power and the accessibility of large-scale datasets. Image classification in deep learning has become a popular choice for tackling complex classification tasks.
Basics of Image Classification
Image classification is a core concept in computer vision that assigns images to predefined categories based on their content. Its applications span various fields, such as facial recognition, object detection, medical diagnosis, and self-driving cars. The primary types of image classification are binary, multi-class, and multi-label, which involve classifying images into two categories, multiple categories, or assigning multiple labels to a single image, respectively. Machine learning-based image classification techniques have gained prominence in recent years, leveraging algorithms to learn from labeled datasets and accurately classify new, unseen images into their corresponding categories.
Deep Learning for Image Classification
Deep learning is a subset of machine learning that employs artificial neural networks with multiple layers to learn complex patterns and representations from data. In image classification, deep learning techniques have been transformative, enabling models to achieve unprecedented accuracy levels. Image classification in deep learning has become more popular by the introduction of Convolutional Neural Networks (CNNs). These specialized neural networks use convolutional layers to process images, capturing local and global patterns effectively.
Popular deep learning models for image classification in deep learning include:
- ResNet (Residual Networks):
These networks leverage skip connections to address the vanishing gradient problem, allowing for deeper architectures and improved performance in image classification in deep learning. - VGG (Visual Geometry Group) networks:
These deep CNNs utilize small convolutional filters and multiple layers to achieve high accuracy in image classification in deep learning. - Inception (e.g., GoogleNet, Inception-v3, Inception-v4):
These networks use a combination of convolutional layers with different filter sizes and pooling layers in parallel to capture diverse spatial information, resulting in more efficient and accurate models for image classification in deep learning. - DenseNet (Densely Connected Convolutional Networks):
These models incorporate dense connections between layers, improving gradient flow, encouraging feature reuse, and reducing the number of parameters, making them more efficient and robust. - MobileNet:
These networks focus on lightweight architectures suitable for mobile and edge devices, balancing high performance with low computational complexity.
Pre-trained models play a crucial role in deep learning-based image classification. These models, which have already been trained on large-scale datasets like ImageNet, can be fine-tuned for specific tasks. Using pre-trained models can save time, computational resources, and often lead to improved performance by capitalizing on the knowledge acquired from previous training in image classification in deep learning.
Implementing Image Classification using Deep Learning
In this section, we discuss the process of implementing image classification in deep learning, from data collection and preprocessing to model training and evaluation. We also cover data augmentation techniques and the importance of preprocessing in improving model performance.
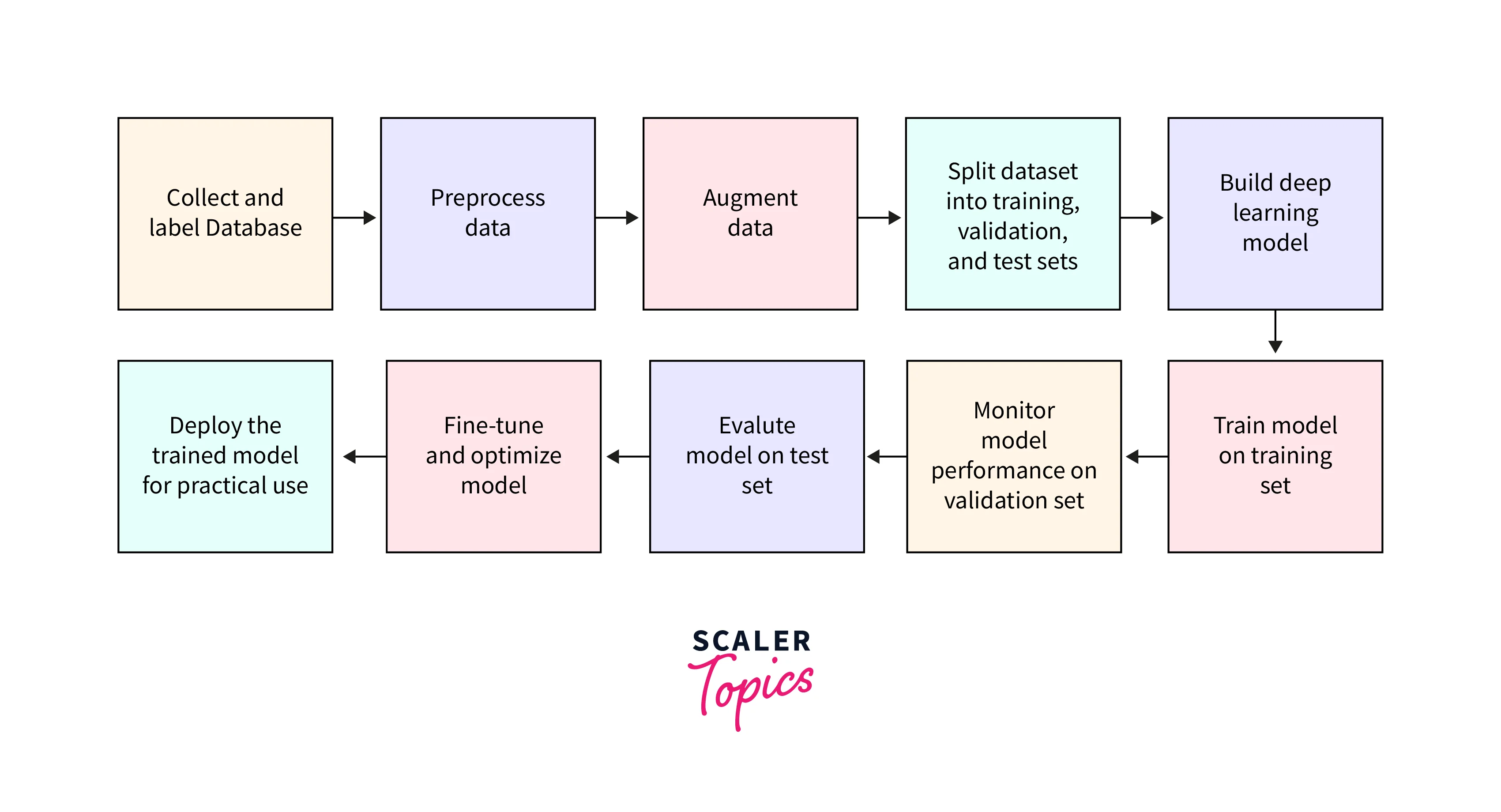
Steps Involved in Implementing Image Classification Using Deep Learning
- Collecting and labeling a dataset of images:
Gather a diverse and representative set of images for the desired classes and label them accordingly. - Preprocessing and augmenting the data:
Process the images to prepare them for the deep learning model, which may include resizing, normalization, and data augmentation techniques. - Building the deep learning model:
Choose an appropriate deep learning architecture, such as a CNN or a pre-trained model, and configure its layers, activation functions, and other hyperparameters. - Training the model:
Split the dataset into training and validation sets, and train the model using the training set while monitoring its performance on the validation set to prevent overfitting. - Evaluating the model:
Assess the model's performance on a test set of unseen images, using relevant evaluation metrics such as accuracy, precision, recall, and F1-score. - Fine-tuning and optimizing:
Improve the model's performance by adjusting hyperparameters, employing regularization techniques, or using techniques such as transfer learning with pre-trained models.
How to Preprocess and Augment Data for Image Classification
- Resizing:
Ensure that all images have the same dimensions, as required by the deep learning model. - Grayscale conversion:
If color information is not necessary for the classification task, convert the images to grayscale to reduce computational complexity. - Normalization:
Normalize pixel values in the images to a consistent range, typically between 0 and 1, to facilitate the learning process. - Data augmentation:
Generate new training examples by applying random transformations to the original images, such as rotation, flipping, scaling, and translation. This process can help improve model generalization and prevent overfitting. - Splitting the dataset:
Divide the dataset into training, validation, and test sets, ensuring that each set has a balanced representation of the different classes. - Data shuffling:
Randomly shuffle the dataset to ensure that the deep learning model does not learn any unintended patterns from the order of the input data.
Building an Image Classification Model Using TensorFlow
First, we need to import the libraries necessary for the implementation of CNN. To start with, we will go with the following libraries.
1. Load the Dataset
Now, we need to import the dataset from the Flowers dataset from TensorFlow Datasets. The dataset can be imported from the URL using the get_file() function keras.utils.
Now we need to generate a dataset from the data directory using image_dataset_from_directory utility. It's good practice to use a validation split when developing your model. You will use 80% of the images for training and 20% for validation.
Now, we'll extract the class names using class_names attribute.
Output:
2. Visualize the data
Here are the first nine images from the training dataset.

3. Configure the Dataset for Performance
Make sure to use buffered prefetching, so you can yield data from the disk without having I/O become blocking. These are two important methods you should use when loading data:
4. Standardize the Data
Making the input values small improves the models performance. Therefore, we need to standardize the data to be in the [0,1] using layers.Rescaling().
5. Build the Model
To create an image classification model we need to create a Sequential model using keras. We are going to build a sequential model with three convolutional layers(Conv2D), followed by a MaxPooling2D layer for each layers respectfully. There's a fully-connected layer (Dense) with 128 units on top of it that is activated by a ReLU activation function ('relu').
Now the model is built, we need to compile the model with proper optimizers and loss functions.
For our model, we are choosing Adam as optimizer and SparseCategoricalCrossentropy as loss function, pass the metrics to model.compile function.
model.fit() is a function that is used to train the model.
Training a CNN involves feeding the training data through the network and adjusting the parameters to minimize the loss function. The loss function measures the difference between the predicted output and the true output.
Now we'll evaluate the performance of the model by plotting the accuracy and loss function of training and validation data.
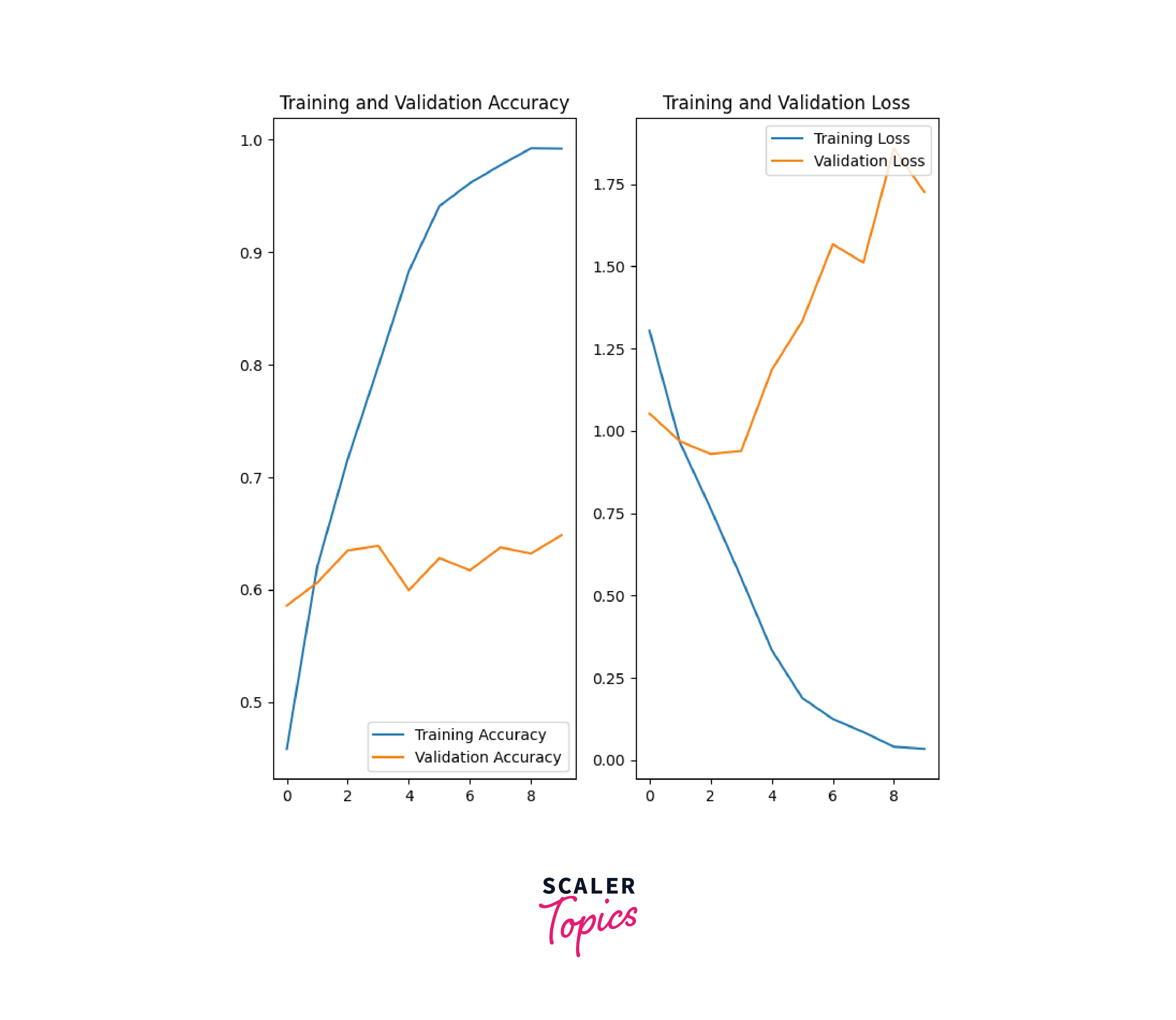
The model's accuracy plot shows a linear increase in training accuracy while validation accuracy plateaus at around 60%, indicating overfitting.
6. Overfitting
Overfitting occurs when a model learns from noises or unwanted details in training examples, which negatively affects its performance on new data. To prevent overfitting, this tutorial proposes using data augmentation and adding dropout to the model.
7. Data Augmentation
Data augmentation generates additional training data by augmenting existing examples with random transformations, exposing the model to more aspects of the data and improving generalization. Keras preprocessing layers such as RandomFlip, RandomRotation, and RandomZoom can be included in the model for data augmentation.
Visualize a few augmented examples by applying data augmentation to the same image several times:

Now we'll apply the augmented data to the model:
Now we'll visualize the accuracy and loss function:
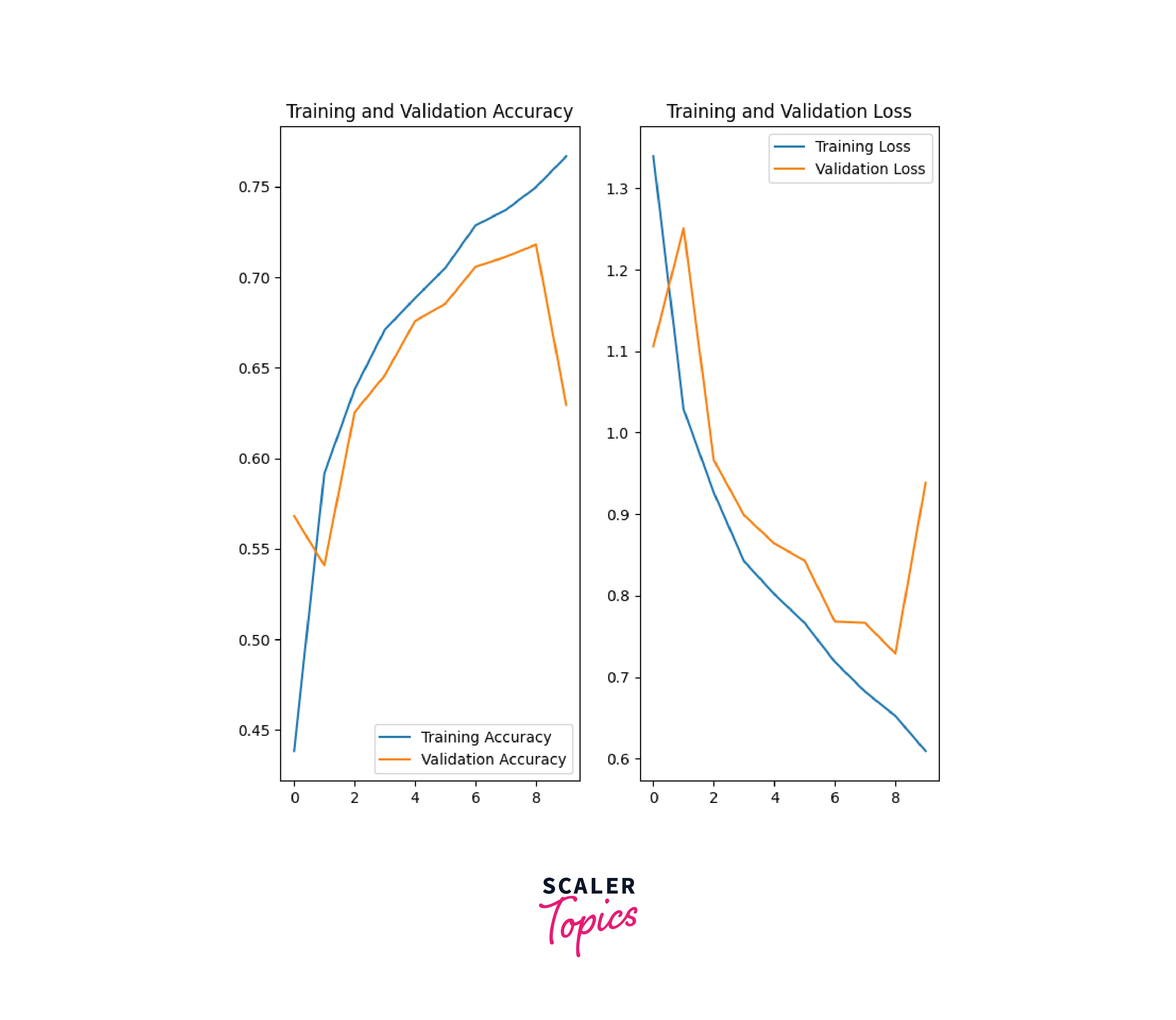
Now, the model's performance has improved. Now, we'll use the trained model to predict new data using model.predict() method.
Advantages and Disadvantages of Deep Learning-Based Image Classification
Advantages of Deep Learning-Based Image Classification:
- High accuracy:
Deep learning models, especially Convolutional Neural Networks (CNNs), have achieved state-of-the-art performance in image classification tasks, outperforming traditional machine learning methods. - Feature learning:
Deep learning models can automatically learn to extract relevant features from raw images, eliminating the need for manual feature engineering, which is often time-consuming and requires domain expertise. - Hierarchical feature representation:
Deep learning models can learn hierarchical representations of the input data, capturing both low-level details (e.g., edges, textures) and high-level abstractions (e.g., objects, scenes) in images. - Scalability:
Deep learning models can handle large-scale datasets and are well-suited for training on parallel computing architectures like GPUs, making them efficient for training on massive amounts of data. - Transfer learning:
Pre-trained deep learning models can be fine-tuned for specific tasks with relatively small amounts of data, allowing for faster training and improved performance.
Disadvantages of Deep Learning-Based Image Classification:
- Computational complexity:
Deep learning models are computationally expensive to train and require powerful hardware resources like GPUs, which might not be accessible to everyone. - Large dataset requirement:
Deep learning models typically require large amounts of labeled data to achieve high performance, which can be difficult to obtain for some applications. - Model interpretability:
Deep learning models are often considered "black boxes" due to their complex internal structure, making it difficult to understand and interpret their decision-making process. - Overfitting:
Deep learning models, with their large number of parameters, are prone to overfitting, especially when trained on small datasets. This can result in poor generalization to new, unseen data. - Longer training times:
The training process for deep learning models can take a long time, particularly for large datasets and complex architectures. This can be a disadvantage when rapid development and deployment of a model are required.
Evaluating Image Classification Models
Popular Metrics
- Accuracy:
The proportion of correctly classified images out of the total number of images. Accuracy is a simple and widely used metric, but it may not be suitable for imbalanced datasets. - Precision:
The proportion of true positive predictions out of the total positive predictions made by the model. Precision is useful when the cost of false positives is high. - Recall:
The proportion of true positive predictions out of the total actual positive instances. Recall is useful when the cost of false negatives is high. - F1-Score:
The harmonic mean of precision and recall, providing a single metric that balances both. F1-score is especially useful when dealing with imbalanced datasets. - Confusion Matrix:
A table that displays the number of correct and incorrect predictions made by the model, grouped by the true and predicted classes. It helps to understand the types of errors made by the model. - Area Under the Receiver Operating Characteristic (ROC) Curve (AUC-ROC):
A plot that shows the relationship between the true positive rate (recall) and the false positive rate. A higher AUC-ROC value indicates better model performance.
Techniques for Improving Model Performance
- Hyperparameter Tuning:
Adjusting the parameters of the model, such as the learning rate, number of layers, and activation functions, to find the best combination for the given task. - Regularization:
Techniques like L1 and L2 regularization can be applied to prevent overfitting by adding a penalty term to the loss function, encouraging the model to learn simpler and more generalizable features. - Data Augmentation:
Applying random transformations like rotation, flipping, or scaling to the training images to increase the diversity of the training dataset, improving the model's ability to generalize. - Transfer Learning:
Using a pre-trained model as a starting point and fine-tuning it on the target task, which can lead to faster training and better performance. - Early Stopping:
Stopping the training process when the model's performance on a validation set starts to degrade, preventing overfitting. - Ensemble Methods:
Combining multiple models to improve the overall performance, such as bagging, boosting, or stacking.
Applications of Image Classification Models in Various Industries
Image Classification models have proven to deliver exceptional performance across diverse industries, including healthcare, automotive, and finance.
- In the healthcare industry, Image Classification models have revolutionized medical image analysis, enabling precise diagnosis of diseases and facilitating breakthroughs in drug discovery. These models contribute to the identification and characterization of medical conditions, aiding healthcare professionals in making informed decisions and improving patient outcomes.
- In the automotive sector, Image Classification models have played a pivotal role in advancing safety and autonomous driving technologies. By accurately detecting and classifying objects, these models enhance object recognition and enable critical functionalities such as object detection, lane detection, and overall scene understanding, fostering the development of self-driving vehicles and enhancing road safety.
- In the realm of finance, Image Classification models have been instrumental in bolstering security and enhancing decision-making processes. These models are utilized for tasks such as fraud detection, where they analyze images and identify suspicious patterns or anomalies, helping to prevent fraudulent activities. Moreover, Image Classification models contribute to credit scoring systems, aiding in the assessment of creditworthiness and risk evaluation. Additionally, these models have been employed in stock price prediction, leveraging visual data to extract insights and support investment strategies.
By harnessing the power of Image Classification models, industries can leverage visual information to gain deeper insights, enhance efficiency, and make informed decisions, leading to significant advancements and improvements across various sectors.
Conclusion
- To conclude, Developing a custom Image Classification model with TensorFlow offers valuable experience in deep learning and can lead to expertise in creating similar models for various applications.
- Image Classification models have widespread applicability across diverse industries, including healthcare, automotive, and finance, demonstrating their potential to revolutionize data analysis and understanding.
- The process of building an Image Classification model involves several key steps, such as data preprocessing, model architecture design, training, and evaluation, which collectively contribute to the development of a robust and accurate classifier.
- Utilizing techniques for improving model performance, such as hyperparameter tuning, data augmentation, and regularization, can lead to better generalization and increased reliability of the model, enhancing its overall impact and usefulness.