Introduction to Image Segmentation
Overview
Image segmentation is a fundamental task in computer vision that involves partitioning an image into multiple segments or regions based on the similarity of the pixels within those regions. The goal of image segmentation is to simplify and/or change the representation of an image into something more meaningful and easier to analyze.
Introduction
In simpler terms, image segmentation is a process of dividing an image into multiple parts or segments, where each segment represents a unique object or region within the image. This process can be used in a variety of applications, including medical imaging, autonomous driving, surveillance, and image editing.
Image segmentation is a challenging task due to the variability of objects and scenes in real-world images. Some common methods used for image segmentation include thresholding, clustering, edge detection, and deep learning-based approaches such as convolutional neural networks (CNNs).
What is Image Segmentation?

Image segmentation is the process of dividing an image into multiple segments or regions, each of which represents a meaningful object or part of the image. The primary goal of image segmentation is to extract useful information from images, simplify image representation, and enable higher-level computer vision tasks.
-
Extracting Useful Information: Image segmentation allows us to identify and extract useful information from an image that may be difficult or impossible to obtain without segmenting the image. For example, in medical imaging, image segmentation can be used to identify and isolate specific organs or tissues for further analysis or diagnosis.
-
Simplifying Image Representation: Images can be complex and contain a lot of information. By segmenting an image into meaningful regions or objects, we can simplify the image representation and make it easier to analyze. This can be particularly useful for computer vision tasks such as object recognition or tracking, where the focus is on specific regions of an image rather than the entire image.
-
Enabling Higher-level Computer Vision Tasks: Image segmentation is a critical step in many higher-level computer vision tasks, such as object detection, semantic segmentation, and instance segmentation. By segmenting an image into regions or objects, we can better understand the spatial relationships between different parts of the image, which can be used to classify and identify objects, track their movements, or generate 3D models.

Need for Image Segmentation
Image segmentation is needed in computer vision for object recognition, image editing, and medical imaging. It is essential to train machine learning algorithms to recognize and classify different objects. Image segmentation is also used to isolate specific regions of an image for editing and identifying different tissues or organs in medical images.
-
Object Recognition: Image segmentation is essential for object recognition in computer vision. By segmenting an image into meaningful objects or regions, we can train machine learning algorithms to recognize and classify different objects. This is useful in many applications, such as autonomous vehicles, surveillance systems, and robotics.
-
Image Editing: Image segmentation is also used in image editing software to isolate specific regions of an image for editing. For example, in photo editing software, image segmentation can be used to select and enhance a particular object or remove unwanted objects from an image.
-
Medical Imaging: Image segmentation is critical in medical imaging applications, such as identifying tumours or lesions in MRI or CT scans. By segmenting an image into different regions or objects, doctors can identify and diagnose medical conditions more accurately and efficiently.
-
Augmented Reality: Image segmentation is also necessary for augmented reality applications, where virtual objects are overlaid onto the real-world environment. By segmenting an image into different objects or regions, AR systems can identify and track real-world objects to enhance the user's experience.
-
Video Analysis: Image segmentation is used in video analysis to track and monitor objects over time. By segmenting an image into different objects or regions, we can track the movements of these objects, which is useful in applications such as traffic monitoring or surveillance.

Image Segmentation Techniques
There are several methods for image segmentation, each with its strengths and weaknesses. Here are some of the most common techniques:
Thresholding
Thresholding is the simplest image segmentation method, which involves dividing an image into foreground and background by selecting a threshold value. Pixels with intensity values above the threshold are classified as foreground, while pixels with intensity values below the threshold are classified as background. Thresholding is suitable for images with high contrast, but it may not work well with images with low contrast.

- Simple Thresholding Simple thresholding is a basic technique used in image segmentation to separate pixels in an image into two categories based on their intensity values: foreground and background. It involves setting a threshold value, such that all pixels with intensity values above the threshold are classified as foreground, while those with values below the threshold are classified as background. This technique is commonly used in tasks such as object detection and segmentation, where the objects of interest have a distinct intensity or colour compared to the background.

-
Adaptive Thresholding Adaptive thresholding is an image segmentation technique used to binarize an image by dynamically adjusting the threshold value based on the local pixel intensity. Unlike simple thresholding, where a global threshold value is used for the entire image, adaptive thresholding calculates a threshold value for each pixel based on a small neighbourhood around that pixel.
This technique is useful in images with uneven illumination or varying contrast, as it can adjust to local variations in lighting conditions. The most commonly used adaptive thresholding method is the "Adaptive Gaussian Thresholding," which calculates the threshold value as the weighted average of the pixel intensities in the local neighbourhood, where the weights are determined by a Gaussian kernel.
Adaptive thresholding is commonly used in applications such as document scanning, image segmentation, and object detection, where accurate binarization of the image is necessary for further processing.

Edge Detection
Edge detection involves identifying the boundaries between regions based on changes in intensity values. Edges can be detected using techniques such as Sobel, Canny, or Laplacian of Gaussian (LoG). Edge detection is useful for image segmentation for images with sharp boundaries, but it may not work well with images that contain gradual transitions.

-
Sobel Edge Detection Sobel Edge Detection is a simple and computationally efficient method in image segmentation that applies a series of convolution operations on an image to highlight regions of high gradient or change in intensity. This technique uses two filters to compute the gradient magnitude and direction of the image, which are then combined to identify edges. The Sobel operator can be applied in both the x and y directions, allowing for the detection of edges in both vertical and horizontal directions.
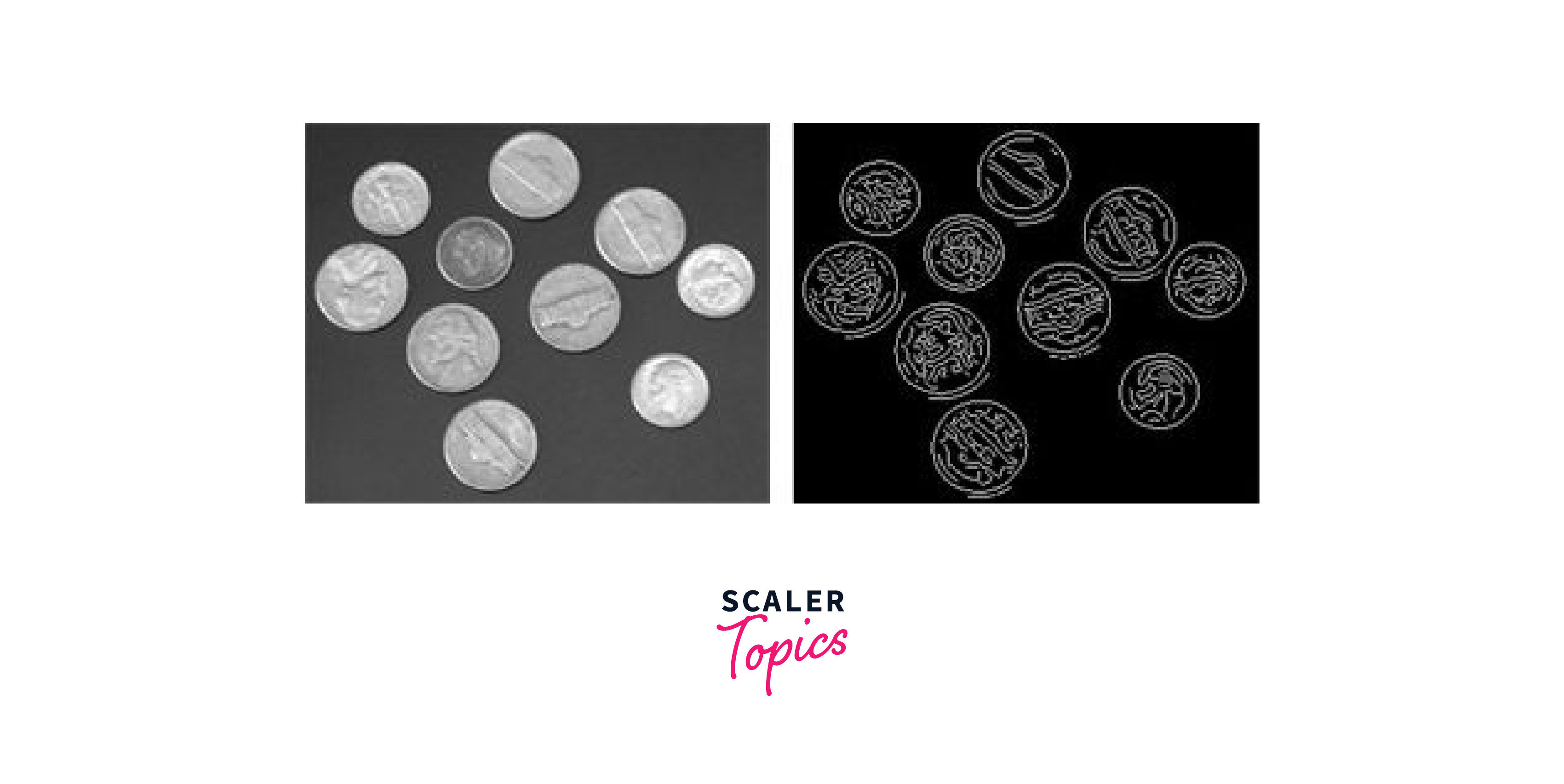
-
Canny Edge Detection Canny Edge Detection is a more advanced and accurate method for image segmentation that involves several steps. Firstly, it applies a Gaussian filter to smooth the image and reduce noise. Then, it calculates the gradient magnitude and direction using Sobel or another gradient-based operator.
Next, it applies non-maximum suppression to thin the edges and preserve only the most prominent ones. Finally, it applies hysteresis thresholding to determine the final edge map, which involves setting two threshold values, a high threshold to detect strong edges and a low threshold to detect weaker edges that are connected to the strong edges.
Compared to Sobel Edge Detection, Canny Edge Detection produces more accurate and reliable results but is computationally more expensive. Both techniques are widely used in applications such as object detection, image segmentation, and feature extraction.

Clustering
Clustering involves dividing an image into groups based on their similarity. The most common clustering algorithms used for image segmentation are K-means and Mean-shift. Clustering is useful for image segmentation and images with multiple regions, but it may not work well with images that contain noise or outliers.
-
K-Means Clustering K-means clustering and Mean Shift Clustering are two common unsupervised machine learning algorithms used for clustering and grouping data points based on their similarity.
K-means clustering is a simple and widely used clustering algorithm for image segmentation that aims to partition data points into k clusters based on their similarity in feature space. It works by first randomly initializing k cluster centroids and then iteratively assigning each data point to the closest centroid based on a distance metric, such as Euclidean distance. After all data points have been assigned to their closest centroids, the centroids are updated to the mean of all data points assigned to that cluster. This process is repeated until the centroids converge or a maximum number of iterations is reached.
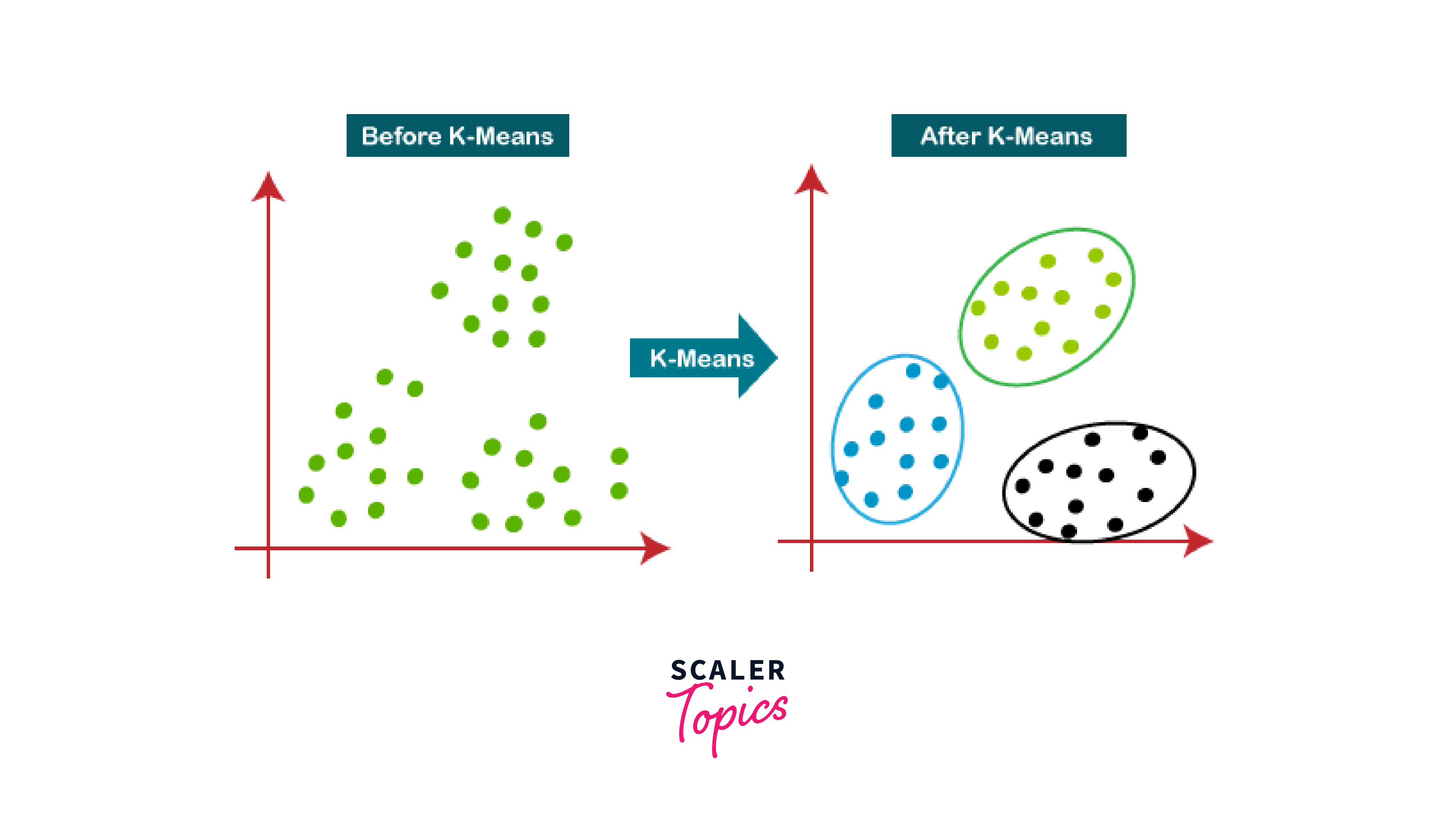
-
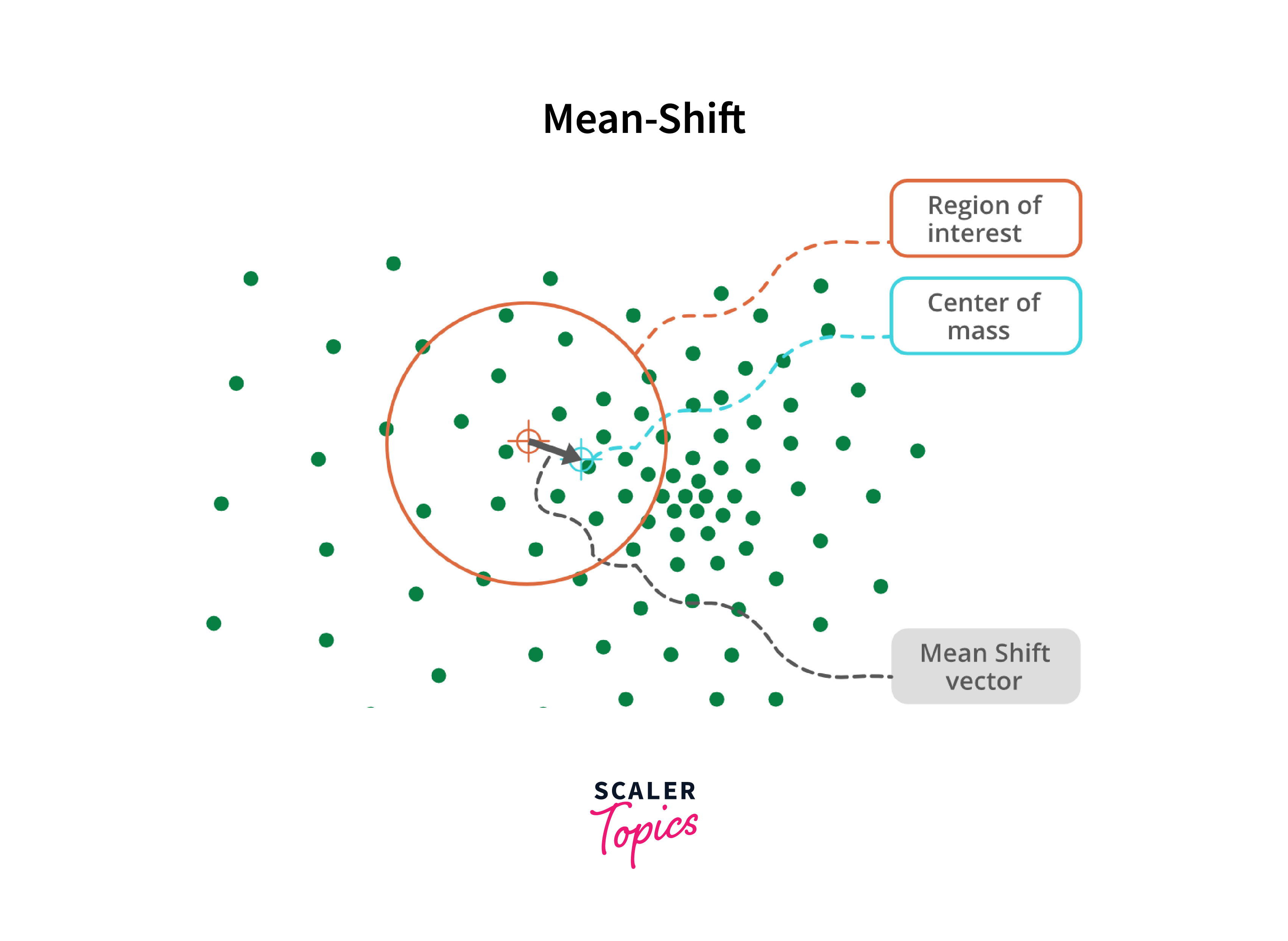
Mean Shift Clustering Mean Shift Clustering is a more advanced clustering algorithm in image segmentation that does not require a pre-specified number of clusters like k-means. Instead, it works by iteratively shifting each data point towards a higher density region in feature space until it converges to a mode or local maxima of the probability density function. This is achieved by applying a kernel function to each data point to estimate its density and then shifting it towards the weighted mean of all nearby data points within a certain radius or bandwidth.
Compared to k-means, Mean Shift Clustering is more robust to noise and can identify non-linearly separated clusters. However, it is computationally more expensive and may not be suitable for large datasets. Both algorithms are widely used in applications such as image segmentation, pattern recognition, and data analysis.
Region-Based Segmentation
Region-Based Image Segmentation and Watershed Algorithm are two common techniques used in image processing for segmentation, where the goal is to partition an image into regions or objects of interest.
Region-Based Image Segmentation is a technique that involves grouping pixels in an image based on their similarity in colour, texture, or other features. This technique uses a clustering algorithm, such as k-means or Mean Shift, to group pixels into regions or superpixels based on their similarity. Then, these regions can be merged or split based on certain criteria, such as colour or intensity homogeneity, to obtain the final segmentation map.
-
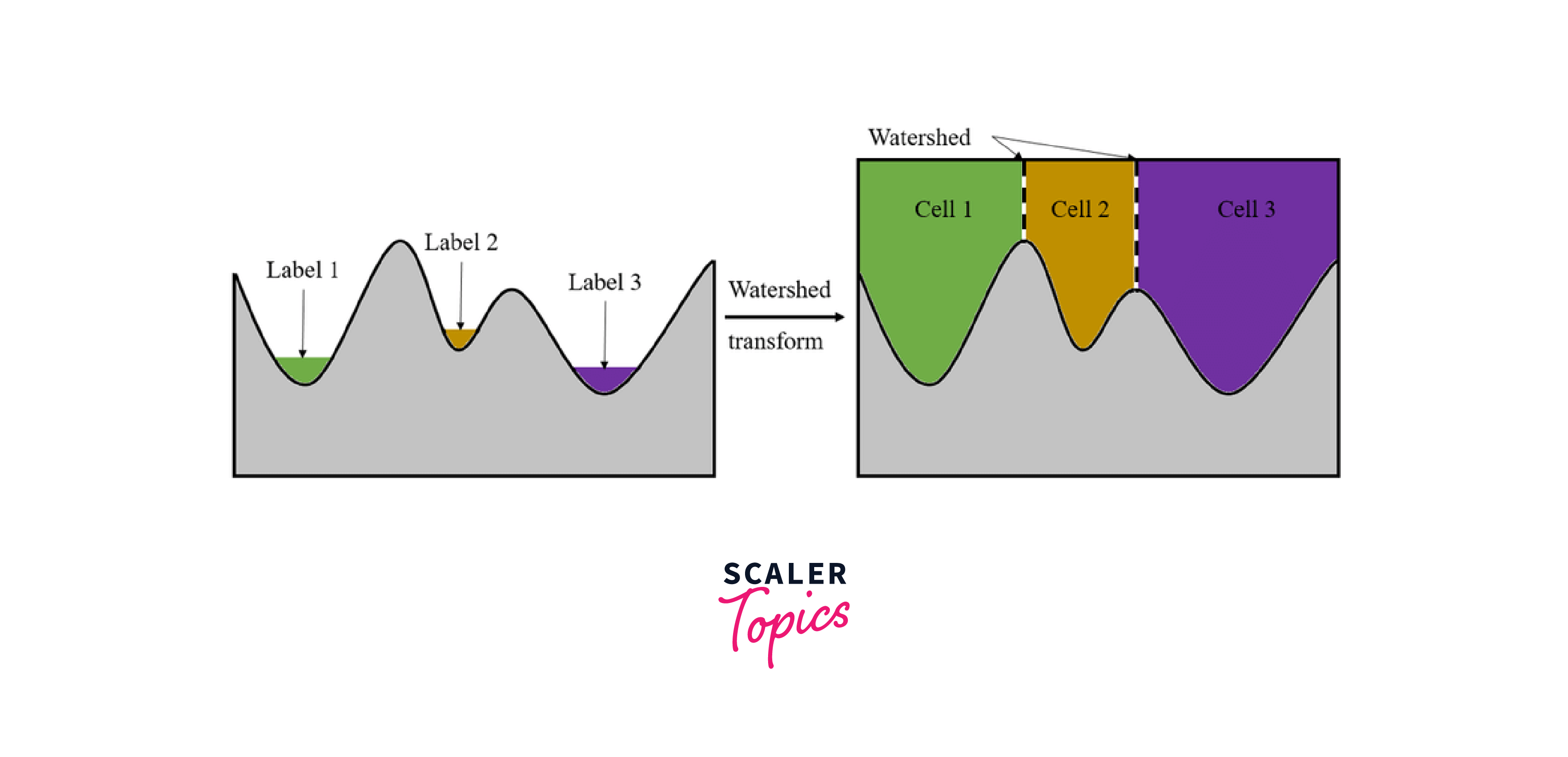
Watershed Algorithm The Watershed Algorithm is a region-based image segmentation technique that is particularly useful in cases where the boundaries between objects are not well-defined or where there are many objects of interest. This algorithm works by treating the intensity values of an image as the height of a topographic map and flooding the map from its minima, where each regional minimum is considered as a seed point for a different region.
The algorithm then partitions the image into catchment basins, where each basin represents a different region. The boundaries between regions are defined by the watershed lines, which are formed by the ridges or peaks of the topographic map.
Implementation of Image Segmentation in OpenCV
OpenCV provides a wide range of image segmentation techniques that can be used to extract useful information from images and simplify image representation. These techniques can be applied to a variety of computer vision tasks such as object detection, tracking, and recognition.
1. Installing OpenCV
To begin, we first need to install OpenCV. OpenCV can be installed via pip using the following command:
2. Reading and Displaying an Image in OpenCV
Once we have installed OpenCV, we can read and display an image using the following code:
In this code, we use the cv2.imread() function to read an image from a file and store it in a variable img. Then, we use the cv2.imshow() function to display the image in a window titled 'image'. Finally, we use the cv2.waitKey() function to wait for a keyboard event and the cv2.destroyAllWindows() function to destroy all windows.
3. Applying Image Segmentation Techniques in OpenCV
Image segmentation is a fundamental task in computer vision that involves dividing an image into meaningful regions. OpenCV provides several techniques for image segmentation, including thresholding, edge detection, clustering, and region-based segmentation. These techniques can be used for a wide range of applications, such as object detection, medical imaging, and video analysis.
3.1: Thresholding One of the simplest and most widely used image segmentation techniques is thresholding, which involves converting an image into a binary image by setting all pixels with intensities above a certain threshold to white and all other pixels to black. In OpenCV, we can apply thresholding using the cv2.threshold() function as follows:
In this code, we first convert the image to grayscale using the cv2.cvtColor() function. Then, we apply thresholding using the cv2.threshold() function, where grey is the input image, 127 is the threshold value, 255 is the maximum pixel value, and cv2.THRESH_BINARY is the thresholding type. Finally, we display the thresholded image using the cv2.imshow() function.
Output:

3.2: Edge Detection Another popular image segmentation technique is edge detection, which involves detecting the boundaries between regions in an image. One of the most commonly used edge detection algorithms is the Canny edge detector, which is implemented in OpenCV as follows:
Output:

3.3: Clustering Clustering is another image segmentation technique that involves grouping pixels in an image based on their similarity in color, texture, or other features. One common clustering algorithm used in image segmentation is k-means clustering, which we discussed earlier.
We can apply k-means clustering to an image in OpenCV as follows:
Step 1: Import the necessary libraries
Here, we import the necessary libraries and read in the input image 'image.jpg' using the cv2.imread() function of OpenCV.
Step 2: Reshape image to a 2D array of pixels
We reshape the 3D input image into a 2D array of pixels using the reshape() function of NumPy.
Here, we specify the shape of the new array as (-1,3), where -1 is inferred automatically based on the size of the original array and 3 represents the number of channels in the image (BGR).
Step 3: Convert pixel values to float32 for image segmentation
We convert the pixel values to float32 using the np.float32() function of NumPy. This is required for applying the k-means clustering algorithm.
Step 4: Apply k-means clustering for image segmentation We apply k-means clustering to the pixel values using the cv2.kmeans() function of OpenCV.
-
Here, we specify the number of clusters k as 5, and the termination criteria for the algorithm as 10 iterations or a change in compactness value of less than 1.0.
-
We also specify the flag for selecting random initial centres as cv2.KMEANS_RANDOM_CENTERS.
-
The function returns the compactness value, the labels assigned to each pixel, and the centre values of each cluster.
Step 5: Reshape labels and centres to the original image shape for image segmentation
We reshape the labels assigned to each pixel and the centre values of each cluster to the original image shape using the reshape() function and the img.shape attribute of the input image. We also convert the centre values to the uint8 data type using the np.uint8() function of NumPy. We assign the cluster centre values to the corresponding pixel labels to obtain a segmented image.
Step 6: Display the clustered images
Finally, we display the output of the image segmentation using the cv2.imshow() function of OpenCV and wait for a key press before closing the window using the cv2.waitKey() and cv2.destroyAllWindows() functions.
Input Image

Output Image
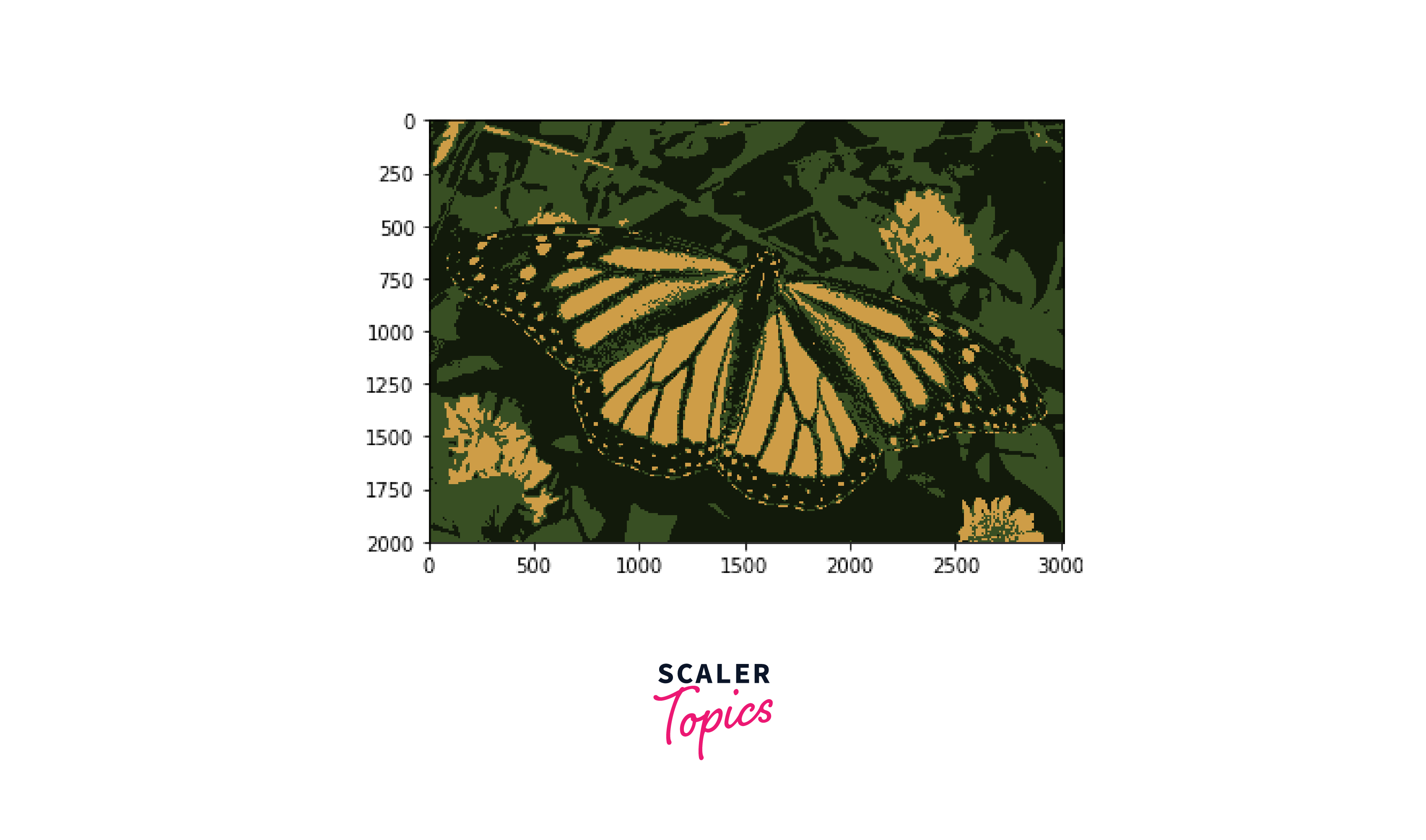
3.4: Region-Based Image Segmentation
Region-based Image segmentation is a widely used technique in image processing that involves partitioning an image into regions or objects of interest based on their similarity in colour, texture, or other features. In this tutorial, we will explore how to implement region-based segmentation using OpenCV, a popular computer vision library.
Step 1: Read the input image The first step is to read the input image using the cv2.imread() function of OpenCV. Make sure that the image is in the same directory as your Python file.
Step 2: Preprocessing Before applying the Watershed Algorithm, we need to perform some preprocessing steps to improve the image segmentation result. The preprocessing steps include noise reduction and image smoothing.
-
Noise Reduction Noise reduction is essential to improve segmentation accuracy. In this tutorial, we will use the cv2.fastNlMeansDenoisingColored() function of OpenCV to reduce noise from the input image.
-
Image Smoothing Image smoothing helps to remove small variations in intensity that can cause over-image segmentation. In this tutorial, we will use the cv2.medianBlur() function of OpenCV to smooth the input image.
Step 3: Thresholding The next step is to apply thresholding to the preprocessed image. Thresholding is the process of converting an image into a binary image by selecting a threshold value. In this tutorial, we will use the cv2.threshold() function of OpenCV to apply thresholding.
Step 4: Morphological Operations Morphological operations are used to remove noise and fill holes in the segmented regions. In this tutorial, we will use the cv2.morphologyEx() function of OpenCV to perform morphological operations for image segmentation.
Step 5: Distance Transform and Marker-Based Watershed Algorithm for image segmentation The next step is to apply the distance transform to the thresholded image to obtain the foreground regions. In this tutorial, we will use the cv2.distanceTransform() function of OpenCV to calculate the distance transform.
After applying the distance transform, we can perform the marker-based Watershed Algorithm to segment the image into multiple regions. In this tutorial, we will use the cv2.connectedComponents() function of OpenCV to obtain the markers and then apply the Watershed Algorithm.
Step 6: Display the results: Finally, we can display the segmented image and the contours found in the previous step using the following code:
The cv2.imshow() function is used to display the output of the image segmentation process and the contours separately. The cv2.drawContours() function is used to draw the contours on the original image. The last command cv2.destroyAllWindows() is used to close all the windows.
Output:

Examples of Image Segmentation using OpenCV
This section let us know some real-time examples of Image segmentation such as Object segmentation, Skin tone detection and Medical Image segmentation using OpenCV.
Segmenting Objects from Background
In this example, we will segment objects from the background of an image using thresholding.
Step 1: Importing Required Libraries First, we need to import the required libraries - cv2 and numpy.
Step 2: Reading and Preprocessing the Image
Next, we will read the image and convert it to grayscale. We will also apply Gaussian blur to remove any noise from the image.
Step 3: Thresholding the Image
Now, we will perform thresholding to segment the objects from the background. We will use Otsu's thresholding method, which automatically determines the threshold value based on the image histogram.
Step 4: Cleaning up the Segmented Image
After thresholding, we may still have some noise or small objects in the segmented image. To clean up the image, we will perform some morphological operations like opening and closing.
Step 5: Displaying the Segmented Image Finally, we will display the output of the image segmentation process.
Output:

Segmentation of Skin Tones in an Image
Skin tone segmentation is a commonly used application of image segmentation, which involves separating pixels corresponding to skin regions from the background. This can be useful in various computer vision applications such as face detection, hand gesture recognition, and skin disease diagnosis. In this section, we will implement skin tone segmentation using OpenCV.
Step 1: Load the Image
First, we need to load the image that we want to segment. We will use the imread() function of OpenCV to load the image. Here is the code for loading the image:
Step 2: Convert the Image to YCrCb Color Space
Skin tone image segmentation is usually performed in the YCrCb colour space, as it separates the luminance and chrominance components of the image. We can use the cvtColor() function of OpenCV to convert the image to the YCrCb colour space.
Here is the code for converting the image to YCrCb colour space:
Step 3: Apply Skin Tone Detection Algorithm
Next, a binary mask is created using the cv2.inRange() function. The input is the image in the YCrCb color space, and the lower and upper bounds for skin tones. The output is a binary mask where white pixels represent skin tones that fall within the specified range, and black pixels represent everything else. The binary mask can be used to perform image segmentation and segment out skin tones from the original image.
After creating a binary mask representing the skin tones in the image, the next step is to apply morphological operations to remove any noise in the mask and fill in any holes. This is done using the cv2.erode() and cv2.dilate() functions.
The cv2.getStructuringElement() function is used to create a kernel, which is a matrix used as a structuring element for the morphological operations. In this case, an elliptical kernel of size 7x7 is created.
The cv2.erode() function is used to erode away the boundaries of the skin mask, while the cv2.dilate() function is used to dilate the remaining areas. These operations help to smooth the edges of the skin mask and remove any isolated pixels.
Finally, the skin mask is applied to the original image using the cv2.bitwise_and() function, which extracts the skin tones from the image. The resulting image after the image segmentation is the mage with only the skin tones remaining.
Step 4: Display the Results
Finally, we can display the original image, the binary mask, and the segmented skin image using the imshow() function of OpenCV.
The waitKey() function waits for a keyboard event for a specified amount of milliseconds. Here, we have passed 0 as an argument which means the function waits indefinitely until we press a key. The destroyAllWindows() function closes all the OpenCV windows that are currently open.
Output:
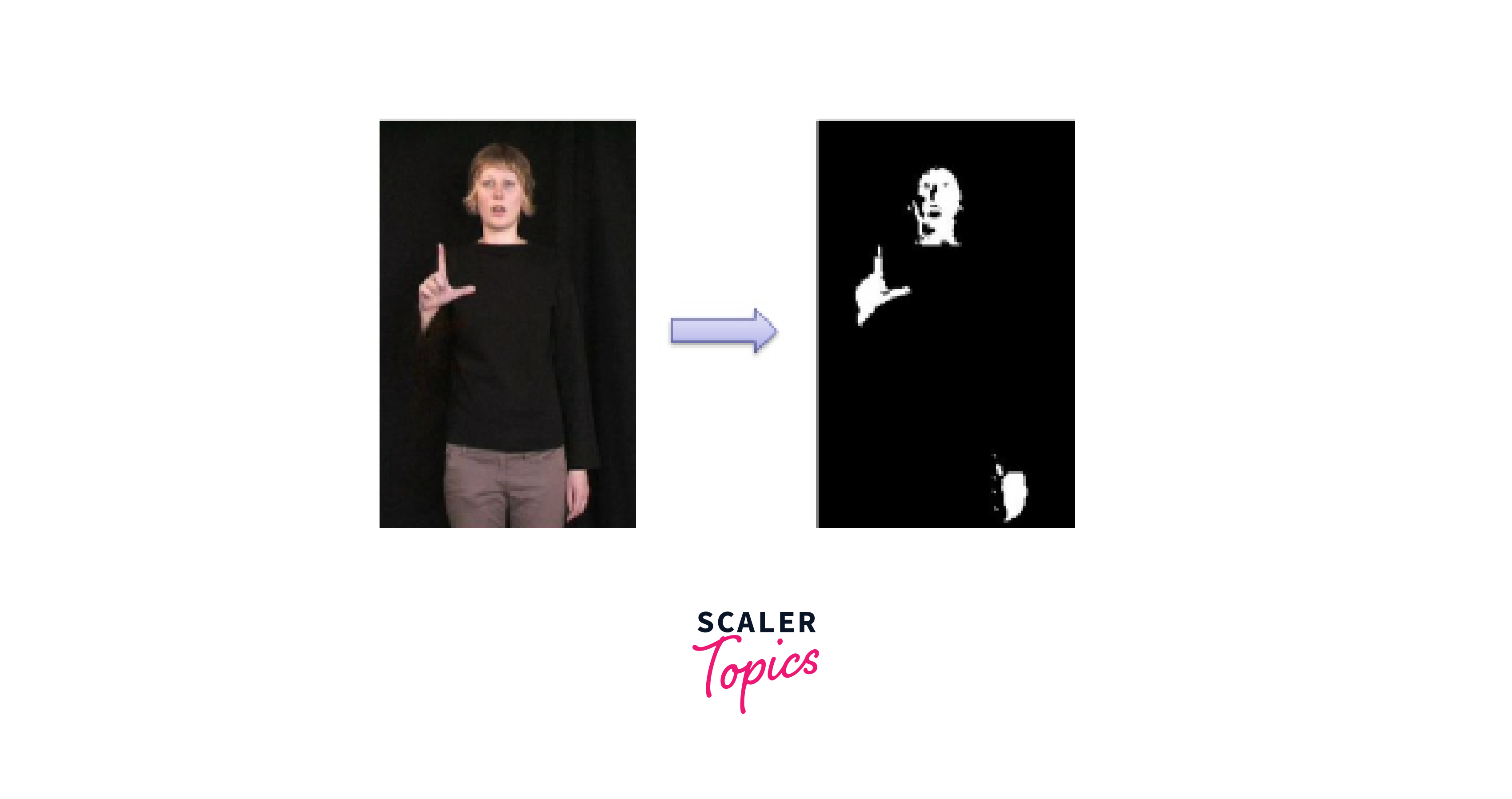
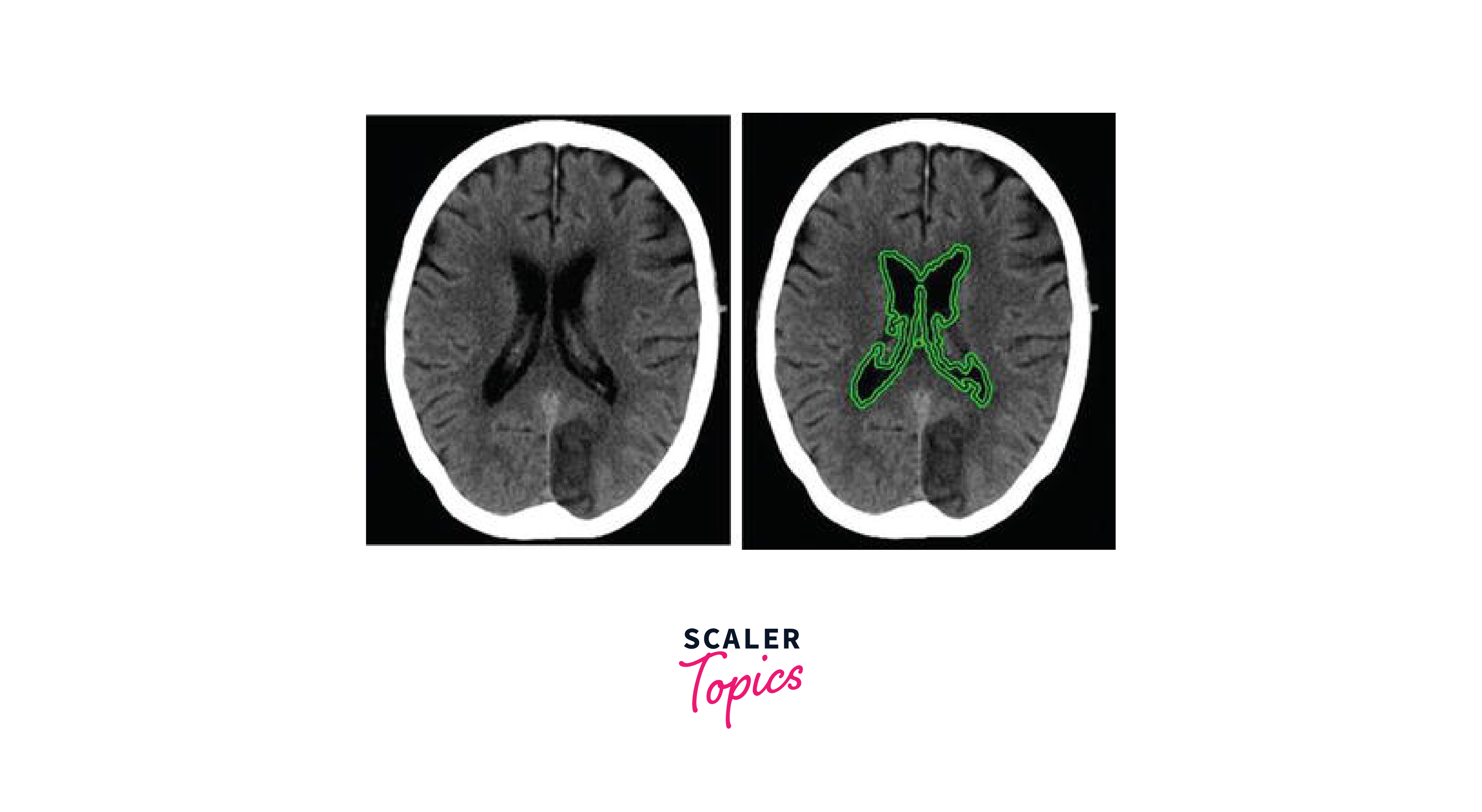
Image Segmentation of Medical Images
Medical image segmentation is a crucial step in many medical imaging applications, such as tumour detection, image-guided surgery, and radiation therapy planning. In this section, we will discuss how to perform the segmentation of medical images using OpenCV in Python. Specifically, we will use thresholding and morphological operations to segment the image and extract the region of interest.
Step 1: Import necessary libraries
We begin by importing the necessary libraries, including OpenCV and NumPy.
Step 2: Read the image
Next, we read in the medical image that we want to segment. In this example, we will use an MRI brain image.
Step 3: Apply thresholding for medical image segmentation
The next step is to apply thresholding to the image. Thresholding is a technique used to convert a grayscale image into a binary image, where the pixels are either black or white. This is done by setting a threshold value, and any pixel with a value above the threshold is set to white, while any pixel with a value below the threshold is set to black. This allows us to separate the foreground (the object we want to extract) from the background.
In this code, we use Otsu's thresholding method, which automatically calculates the threshold value based on the image histogram. We also use the THRESH_BINARY_INV flag to invert the binary image, so that the object we want to extract is white on a black background.
Step 4: Apply morphological operations
Next, we apply morphological operations to the thresholded image. Morphological operations are used to remove noise and fill in gaps or holes in the image. In this example, we will use erosion and dilation operations to remove small objects and fill in small gaps.
In this code, we first create a 5x5 kernel using NumPy. We then apply the erode function to remove small objects and the dilate function to fill in small gaps. We use the iterations parameter to control the amount of erosion and dilation.
Step 5: Find Contours for image segmentation
Finally, we find contours on the segmented image. Contours are the boundaries of objects in an image. In this case, we are interested in finding the contours of the tumours in the medical image.
Step 6: Draw Contours on Original Image
After finding the contours, we can draw them on the original medical image using the cv2.drawContours function. We can also calculate the area and perimeter of each tumour by using the cv2.contourArea and cv2.arcLength functions.
Step 7: Display the image segmentation output
Finally, we display the output using cv2.imshow() method.
Output:
Conclusion
- In conclusion, image segmentation is a fundamental task in computer vision that plays a crucial role in various applications.
- The various methods discussed in this article can be applied to different types of images, including medical images, skin tone segmentation, and object/background segmentation.
- By understanding and applying these techniques, it is possible to extract useful information from images, enabling us to perform various tasks such as object detection, recognition, tracking, and more.
- With its ease of use and wide range of features, OpenCV is an excellent tool for anyone interested in image segmentation and computer vision.