Introduction to InceptionNet
Overview
InceptionNet is a convolutional neural network (CNN) architecture that Google developed to improve upon the performance of previous CNNs on the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) benchmark. It uses "inception modules" that apply a combination of 1x1, 3x3, and 5x5 convolutions on the input data and utilizes auxiliary classifiers to improve performance. InceptionNet won the 2014 ILSVRC competition and has been used in various applications, including image classification, object detection, and image segmentation.
Introduction
InceptionNet is a convolutional neural network architecture developed by Google in 2014. It is known for using inception modules, blocks of layers that learn a combination of local and global features from the input data. InceptionNet was designed to be more efficient and faster to train than other deep convolutional neural networks. It has been used in image classification, object detection, and face recognition and has been the basis for popular neural network architectures such as Inception-v4 and Inception-ResNet.
What is InceptionNet
InceptionNet is a convolutional neural network (CNN) designed for image classification tasks and developed for the ImageNet Large Scale Visual Recognition Challenge. InceptionNet is known for using inception modules, blocks of layers designed to learn a combination of local and global features from the input data. These modules are composed of smaller convolutional and pooling layers, which are combined to allow the network to learn spatial and temporal features from the input data. InceptionNet was designed to train more efficiently and faster than other deep CNNs. It has been widely used in various applications, including image classification, object detection, and face recognition.
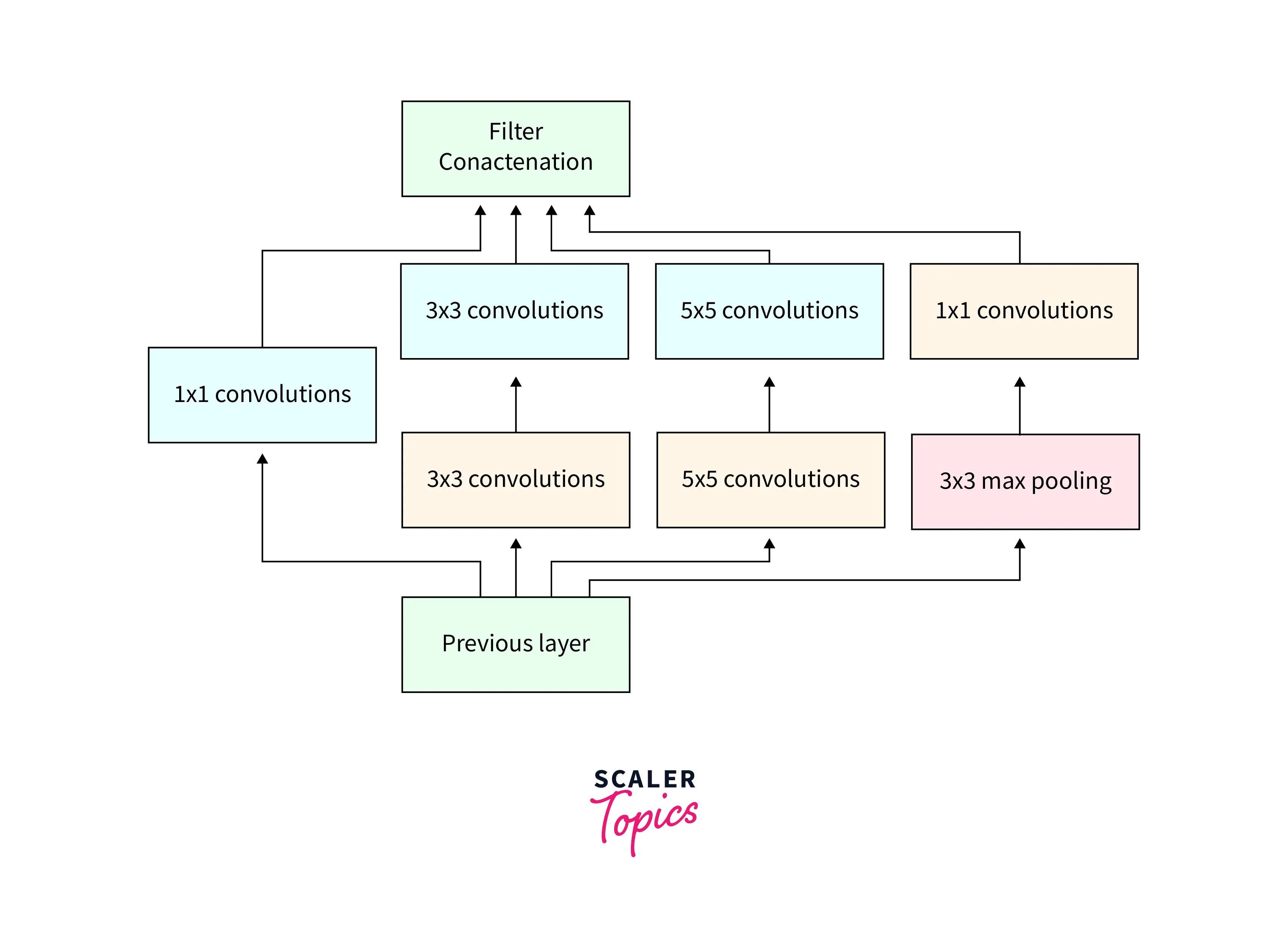
Inception Blocks
Conventional convolutional neural networks typically use convolutional and pooling layers to extract features from the input data. However, these networks are limited in capturing local and global features, as they typically focus on either one or the other. The inception blocks in the InceptionNet architecture are intended to solve the problem of learning a combination of local and global features from the input data.
Inception blocks address this problem using a modular design that allows the network to learn a variety of feature maps at different scales. These feature maps are then concatenated together to form a more comprehensive representation of the input data. This allows the network to capture a wide range of features, including both low-level and high-level features, which can be useful for tasks such as image classification.
By using inception blocks, the InceptionNet architecture can learn a more comprehensive set of features from the input data, which can improve the network's performance on tasks such as image classification.
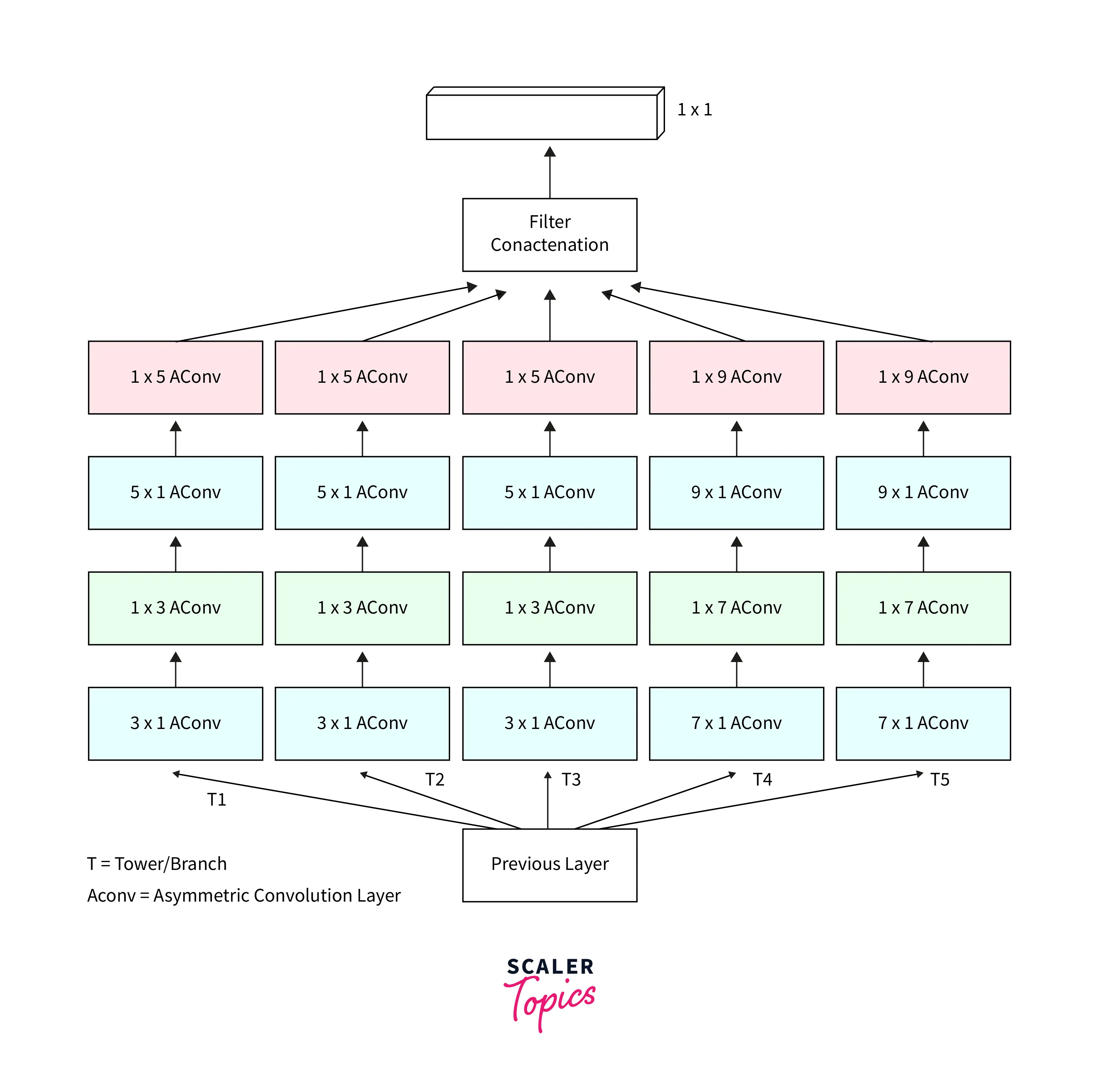
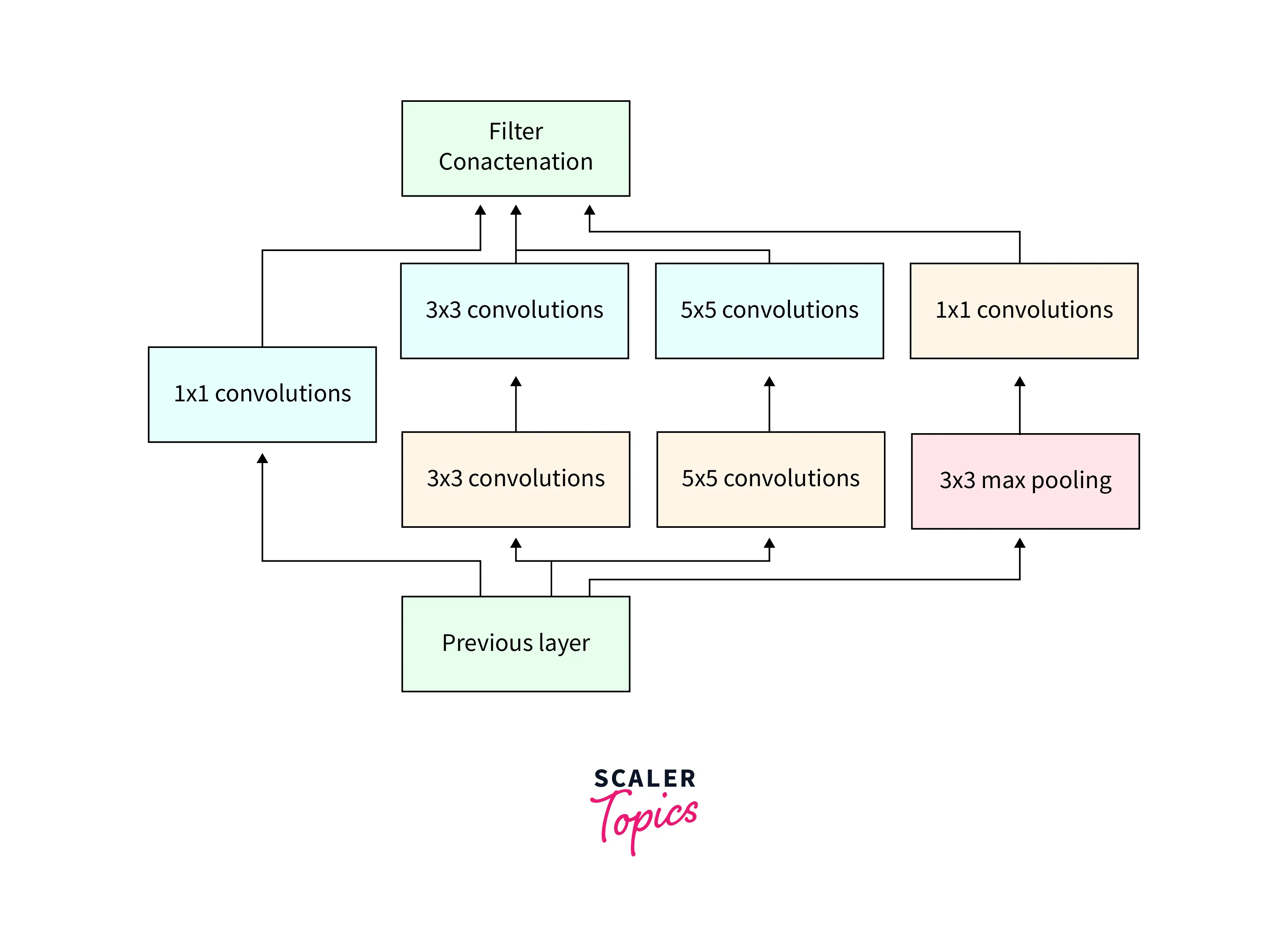
Inception Modules
Inception modules are a key feature of the InceptionNet convolutional neural network architecture. They are blocks of layers designed to learn a combination of local and global features from the input data. Inception modules comprise a series of smaller convolutional and pooling layers, which are combined to allow the network to learn spatial and temporal features from the input data.
The idea behind the inception module is to learn a variety of feature maps at different scales and then concatenate them together to form a more comprehensive representation of the input data. This allows the network to capture a wide range of low-level and high-level features, which can be useful for tasks such as image classification.
Inception modules can be added to the network at various points, depending on the desired complexity level and the input data size. We can also modify them by changing the number and size of the convolutional and pooling layers and the type of nonlinear activation function used.
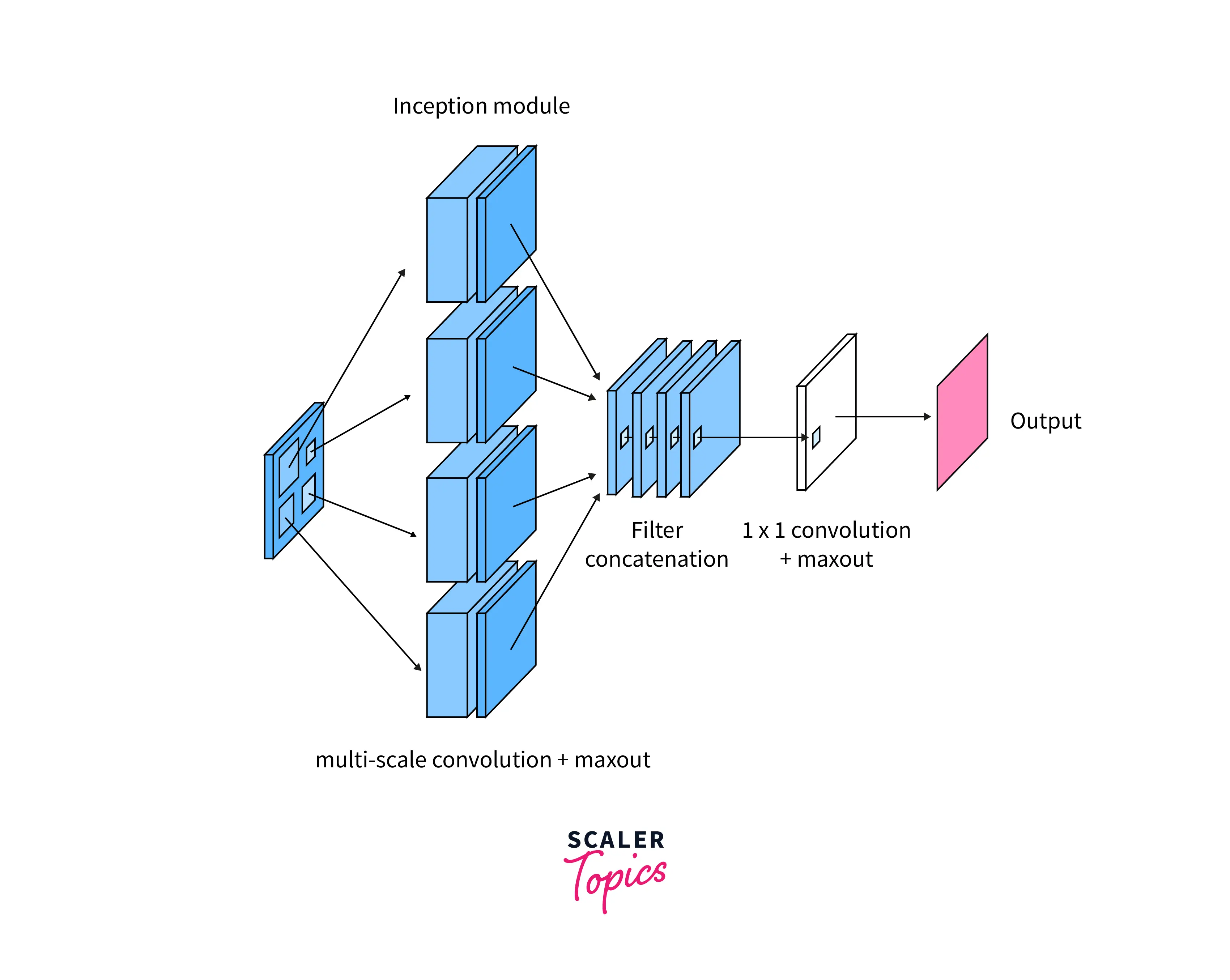
How does an Inception Module Function Work?
- An Inception Module is a building block used in the Inception network architecture for CNNs.
- It improves performance by allowing multiple parallel convolutional filters to be applied to the input data.
- The basic structure of an Inception Module is a combination of multiple convolutional filters of different sizes applied in parallel to the input data.
- The filters may have different kernel sizes (e.g. 3x3, 5x5) and/or different strides (e.g. 1x1, 2x2).
- Output of each filter is concatenated together to form a single output feature map.
- Inception Module also includes a max pooling layer, which takes the maximum value from a set of non-overlapping regions of the input data.
- This reduces the spatial dimensionality of the data and allows for translation invariance.
- The use of multiple parallel filters and max pooling layers allows the Inception Module to extract features at different scales and resolutions, improving the network's ability to recognize patterns in the input data.
- In summary, the Inception module improves feature extraction, improving the network's performance.
Why 1 X 1 Convolutions are Less Expensive?
- 1x1 convolutions are less computationally expensive than larger convolutional filters because they involve fewer parameters.
- Since the kernel size is 1x1, it only has one set of weights, much less than the number required for larger convolutional filters.
- 1x1 convolutions also require less memory to store the weights and less computation to perform the convolution.
- These smaller kernels are more efficient as they are applied to lower-dimensional feature maps, which reduces the number of operations and memory required.
- Using 1x1 convolutions also allows for dimensionality reduction, which can help to reduce the number of parameters in the network and improve performance.
- In summary, 1x1 convolutions are less computationally expensive due to fewer parameters, fewer memory requirements, and less computation required for convolution, making them more efficient and suitable for dimensionality reduction.
Different Inception Versions
Inception v1
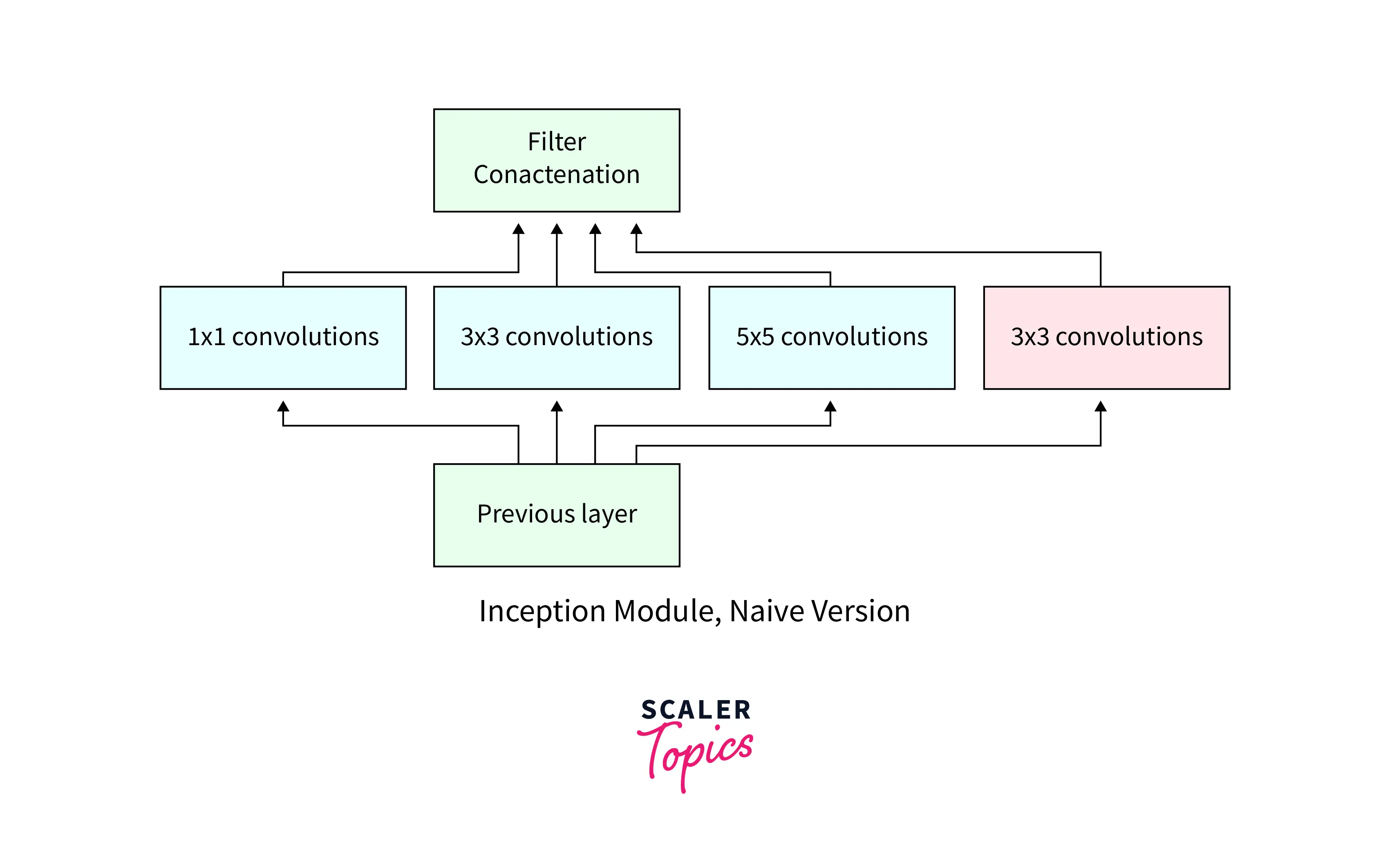
- Inception v1, also known as GoogLeNet, was the first version of the Inception network architecture.
- It was introduced in 2014 by Google and designed to improve the performance of CNNs on the ImageNet dataset.
- It uses a modular architecture, where the network comprises multiple Inception Modules stacked together.
- Each module contains multiple parallel convolutional filters of different sizes, which are applied to the input data and concatenated to form a single output feature map.
- Inception v1 includes a total of 9 Inception Modules, with max-pooling layers at different scales.
- It includes a global average pooling layer and a fully connected layer for classification.
- It achieved state-of-the-art performance on the ImageNet dataset at the time of its release.
- It was a very deep and complex network. It introduced the idea of using multiple parallel convolutional filters and showed how to reduce the computational cost using 1x1 convolution.
Inception v2
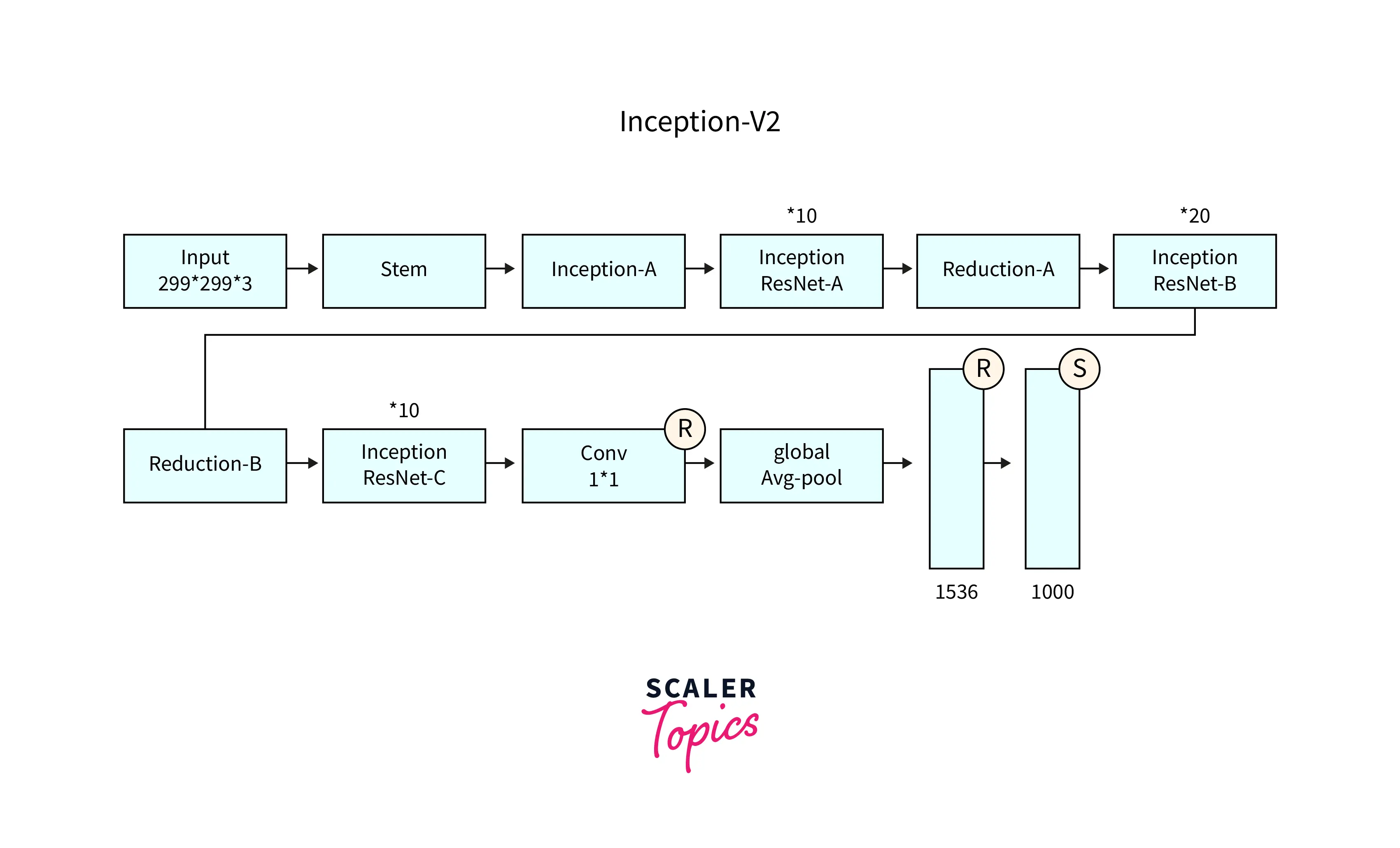
- Inception v2 is an improved version of the Inception network architecture introduced in 2015 by Google.
- It builds upon the original Inception v1 architecture and aims to improve the performance of CNNs further.
- Inception v2 uses a similar modular architecture, where the network comprises multiple Inception Modules stacked together.
- It uses a new Inception Module, called the Inception-ResNet Module, which combines the benefits of both Inception and Residual networks.
- These Inception-ResNet Modules allow for a deeper network with fewer parameters and better performance.
- Inception v2 also uses a batch normalization layer after each convolutional layer, which helps improve the network's stability and performance.
- Inception v2 achieved state-of-the-art performance on several image classification benchmarks, and its architecture has been used as a basis for many subsequent CNNs.
- Inception v2 improved the Inception architecture by introducing Inception-ResNet modules, which allow for deeper networks with fewer parameters, and batch normalization layers which improved the stability and performance of the network.
Inception v3
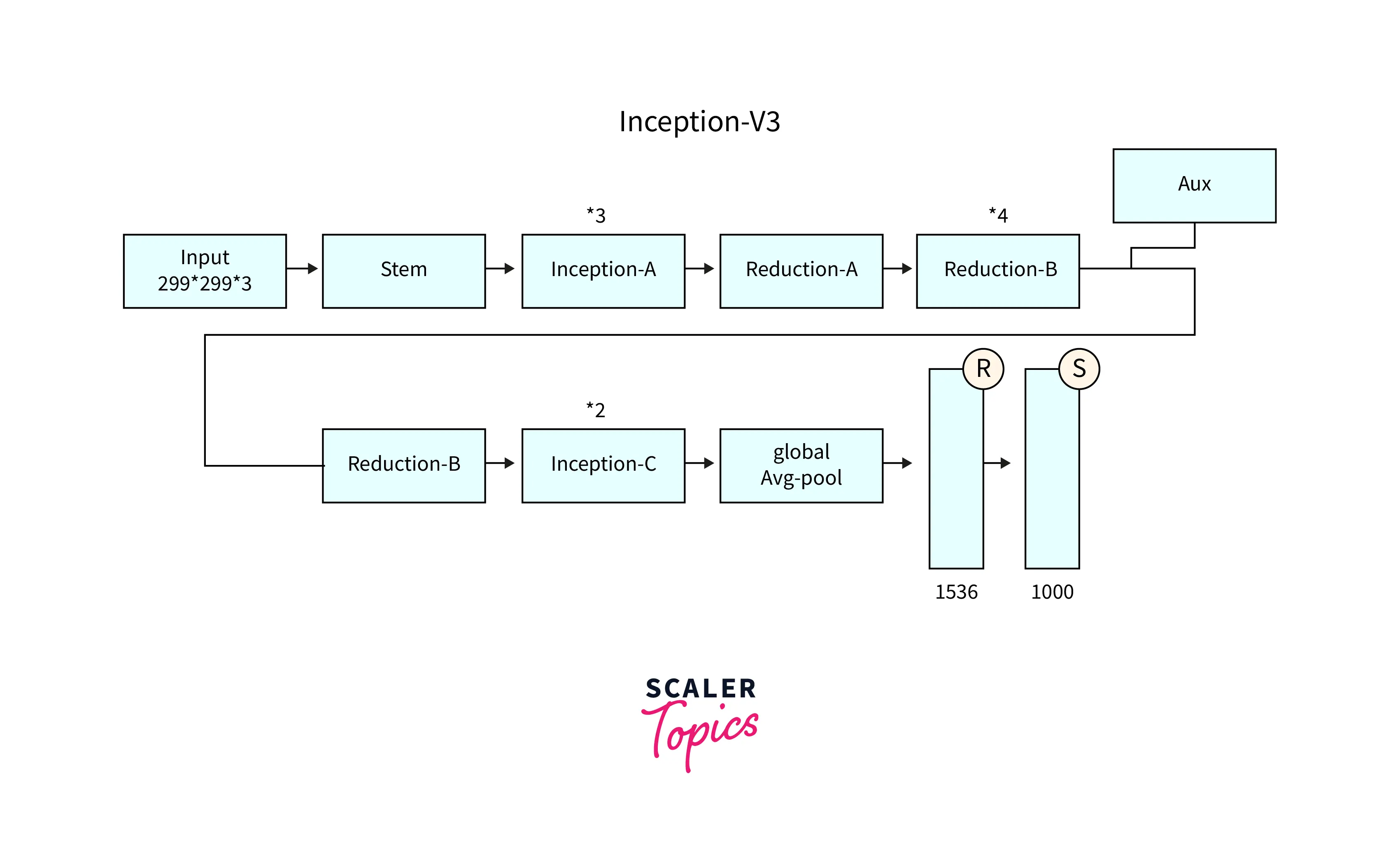
- Inception v3 is the third version of the Inception network architecture, which was introduced in 2015 by Google.
- It builds upon the original Inception v1 and v2 architectures and aims to improve the performance of CNNs further.
- Inception v3 uses a similar modular architecture, where the network comprises multiple Inception Modules stacked together.
- It uses a new type of Inception Module, called the Factorization-Based Inception Module, which uses factorization techniques to reduce the number of parameters in the network and improve performance.
- Inception v3 also introduces batch normalization layers after each convolutional layer, which helps improve the network's stability and performance.
- Inception v3 achieved state-of-the-art performance on the ImageNet dataset, and its architecture has been used as a basis for many subsequent CNNs.
- Inception v3 improved the Inception architecture by introducing Factorization-Based Inception Modules, which allows for a deeper network with fewer parameters, and batch normalization layers which improved the stability and performance of the network.
Inception v4
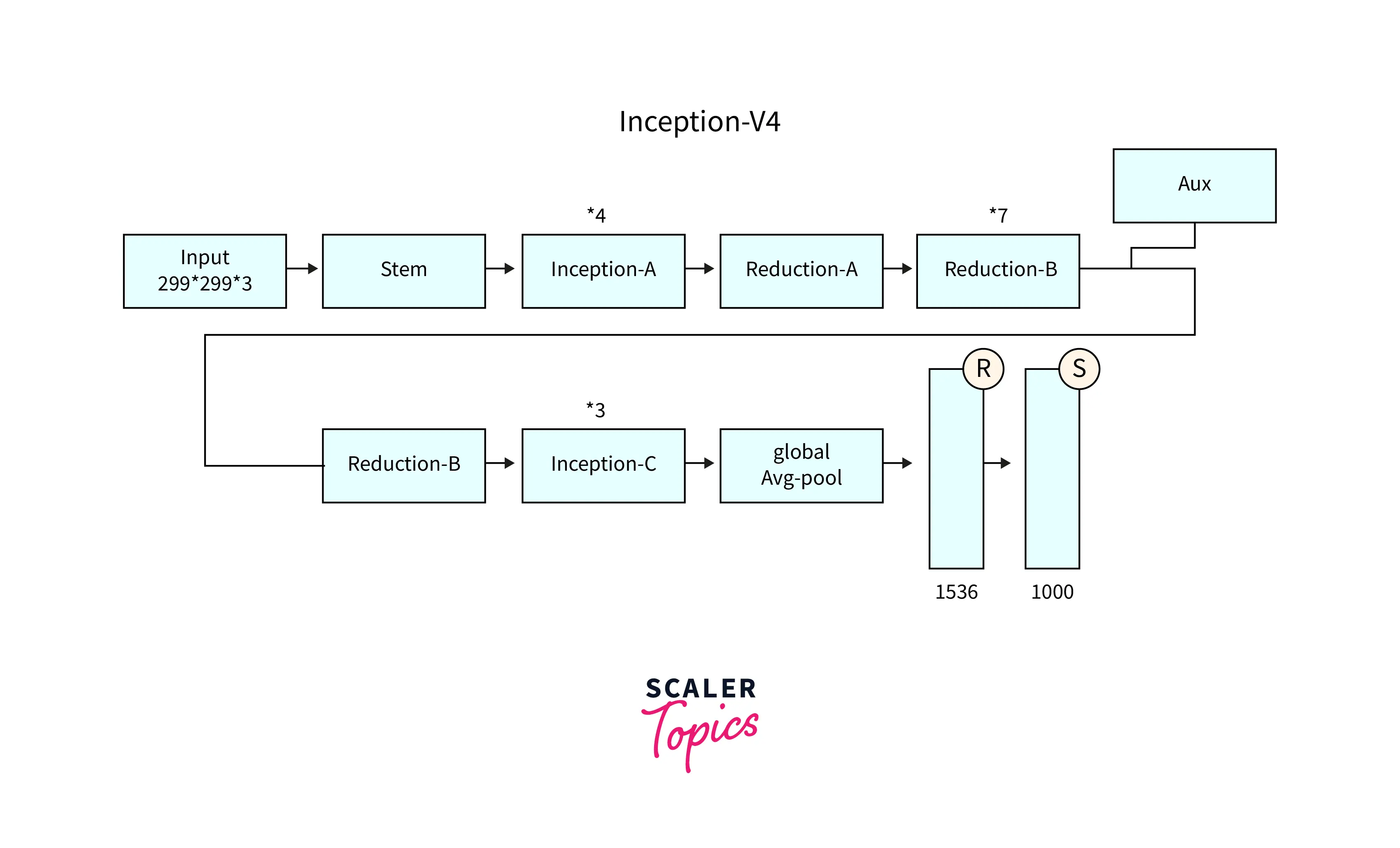
- Inception v4 is the fourth version of the Inception network architecture, which was introduced in 2016 by Google.
- It builds upon the original Inception v1, v2, and v3 architectures and aims to improve the performance of CNNs further.
- Inception v4 uses a similar modular architecture, where the network comprises multiple Inception Modules stacked together.
- It uses a new type of Inception Module, called the Inception-Auxiliary Module, which provides auxiliary classifiers to improve the network's performance.
- Inception v4 also introduces the use of Stem layers, which reduce the spatial resolution of the input data before it is passed to the Inception Modules.
- Inception v4 achieved state-of-the-art performance on several image classification benchmarks, and its architecture has been used as a basis for many subsequent CNNs.
- Inception v4 improved the Inception architecture by introducing Inception-Auxiliary Modules, which provide auxiliary classifiers to improve the network's performance, and Stem layers, which reduce the spatial resolution of the input data before it is passed to the Inception Modules.
Each Inception version was developed to improve the previous version, focusing on increasing efficiency, accuracy, and the ability to learn a wider range of features from the input data. The specific design of each version may vary, but all are based on the idea of using inception modules to learn a combination of local and global features from the input data.
Inception-Resnet v1 and v2
Inception-Resnet v1 and v2 are deep convolutional neural network architectures developed by Google. They are based on the Inception architecture and incorporate residual connections, which bypass one or more layers. This allows the network to learn the residual mapping between the input and the output, making it easier to train deeper networks.
- Inception-Resnet v1 was introduced in 2016 in the paper "Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning" by Szegedy et al. It was designed to improve the accuracy of image classification tasks.
- Inception-Resnet v2 was introduced in 2017 in the paper "Inception-ResNet-v2: Improved use of factorized convolutions" by Szegedy et al. It was designed to improve the accuracy of image classification tasks further and reduce the network's computational cost.
| Feature | Inception-ResNet v1 | Inception-Resnet v2 |
|---|---|---|
| Network Depth | Deep | Shallow |
| Complexity | High | Low |
| Residual Connections | No | Yes |
| Feature Map Sizes | Large | Small |
| Training Time | Long | Short |
| Accuracy | Good | Better |
| Resource Requirements | High | Low |
Inception-Resnet v1 and v2 have been widely used for image classification tasks and other computer vision tasks.
Conclusion
- InceptionNet is a convolutional neural network (CNN) architecture developed by Google in 2014. It is known for its use of inception modules, which learn a combination of local and global features from input data
- InceptionNet was designed to be more fficient and faster to train than other deep CNNs
- It has been widely used in image classification, object detection, and face recognition
- InceptionNet has also been the basis for other popular neural network architectures, such as Inception-v4 and Inception-ResNet.