Introduction to Neural Networks and Deep Learning

Neural networks, combining artificial intelligence and brain-inspired design, reshape computing by emulating the human brain's intricate functions. These networks, with diverse types like feedforward and recurrent, excel in machine learning tasks such as image recognition and natural language processing. The article delves into real-world applications across industries, offering insights into the architecture and workings of neural networks in machine learning.
Neural Networks and the Brain
Introduction to Neural Networks: A neural network is a machine learning algorithm inspired by the brain's structure and function. It consists of interconnected "neurons" that process and transmit information. We can train neural networks to perform various tasks by adjusting the weights of the connections between neurons. Despite their inspiration from the brain, neural networks are not a direct model of it and are designed to perform specific tasks. They have been successful in a variety of applications. They are particularly effective for tasks involving pattern recognition, such as image and speech recognition.
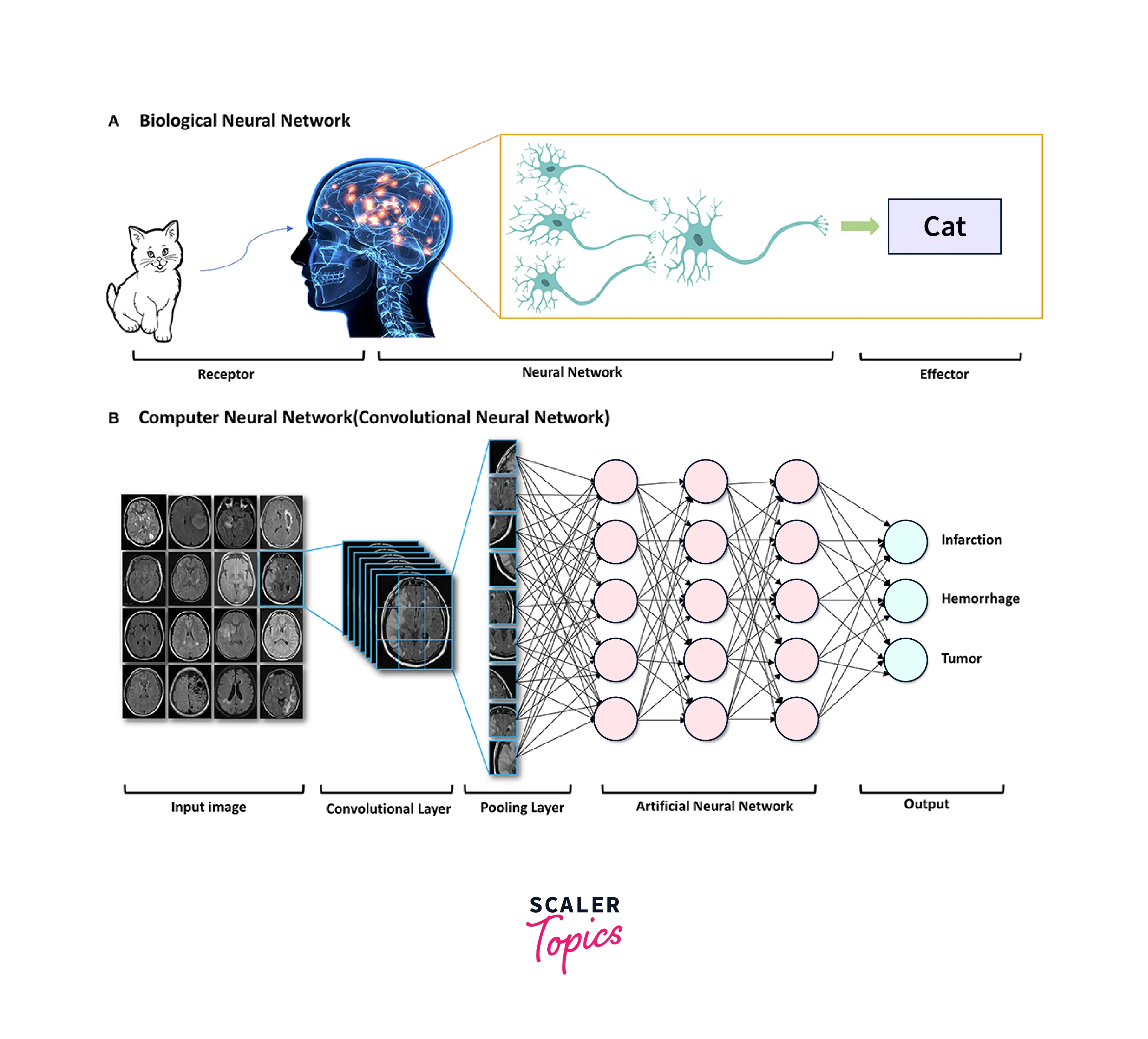
Neural Networks Architecture
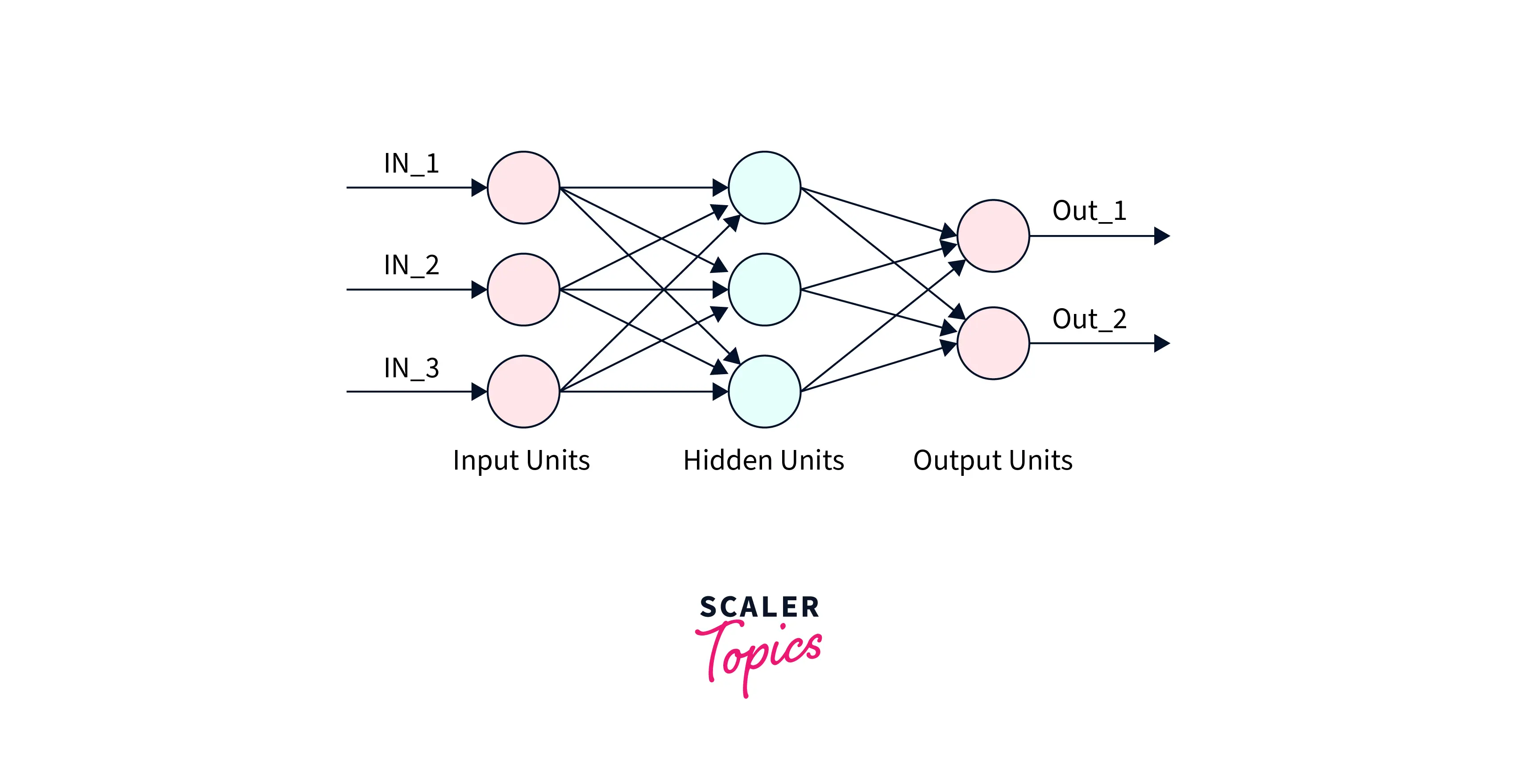
Introduction to Neural Network Architecture: The architecture of a neural network refers to the layout and organization of its layers and the connections between them. A neural network typically consists of an input layer, one or more hidden layers, and an output layer`.
The input layer receives and passes the input data through the network to the hidden layers. The hidden layers process and transform the data, extracting features and patterns used to make a prediction or decision. Finally, the output layer produces the network's final output based on the processing and transformation of the input data by the hidden layers.
The number of layers and units in each layer can vary depending on the complexity of the task and the amount of data available. In general, deeper networks with more hidden layers can learn and represent more complex patterns, but they also require more computational resources and can be more difficult to train.
The weights of the connections between units are adjusted during the training process to optimize the neural network's performance. This process is known as "learning," allowing the network to improve its accuracy and generalize to new data.
Input layers: It Receives and processes the input data. Hidden layers: It Uses weights to transform the data and pass it through to the output layer. Output Layer: It produces the final output or prediction. Weights: They are adjustable parameters of the network that are learned during training to optimize the network's performance on a given task.
Types of Neural Networks
There are several types of neural networks, each with its characteristics and suitable for different tasks.
Feedforward Neural Networks
Introduction to feedforward neural networks: A feedforward neural network is a type in which the information flows in only one direction, from the input to the output layer, without looping back. The input is passed through the network layers, with each layer applying weights and a non-linear activation function to the input, resulting in an output prediction. The weights are learned during training by adjusting them to minimize the error between the predicted output and the actual output. This type of neural network is commonly used for supervised learning tasks such as image and speech recognition. In addition, it is the foundation for more complex architectures, such as convolutional and recurrent neural networks.

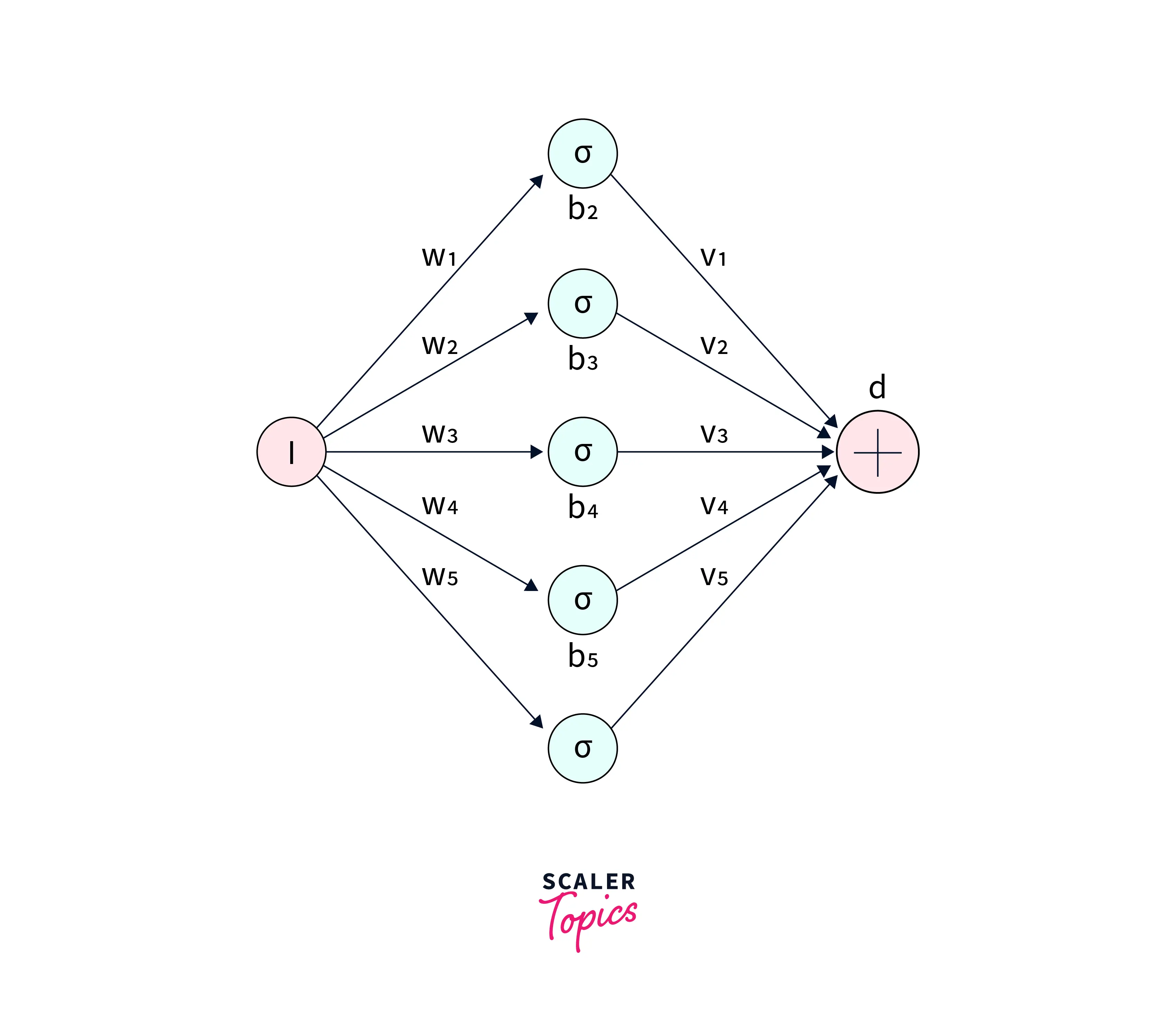
Single-layer Perceptron
Introduction to Neural Networks: A single-layer perceptron is a type of neural network that consists of a single layer of artificial neurons. The input is passed through this single layer of neurons, which apply a set of weights and a linear activation function (such as a threshold function) to the input, resulting in an output prediction. The weights are learned during training by adjusting them to minimize the error between the predicted output and the actual output. The single-layer perceptron is a simple algorithm that only performs binary classification tasks (i.e., separating two classes) and cannot solve complex problems like multi-class or non-linear separable problems. It is considered a basic model of neural networks, but it has yet to be widely used in modern deep-learning applications.
Multi-layer Perceptron (MLP)
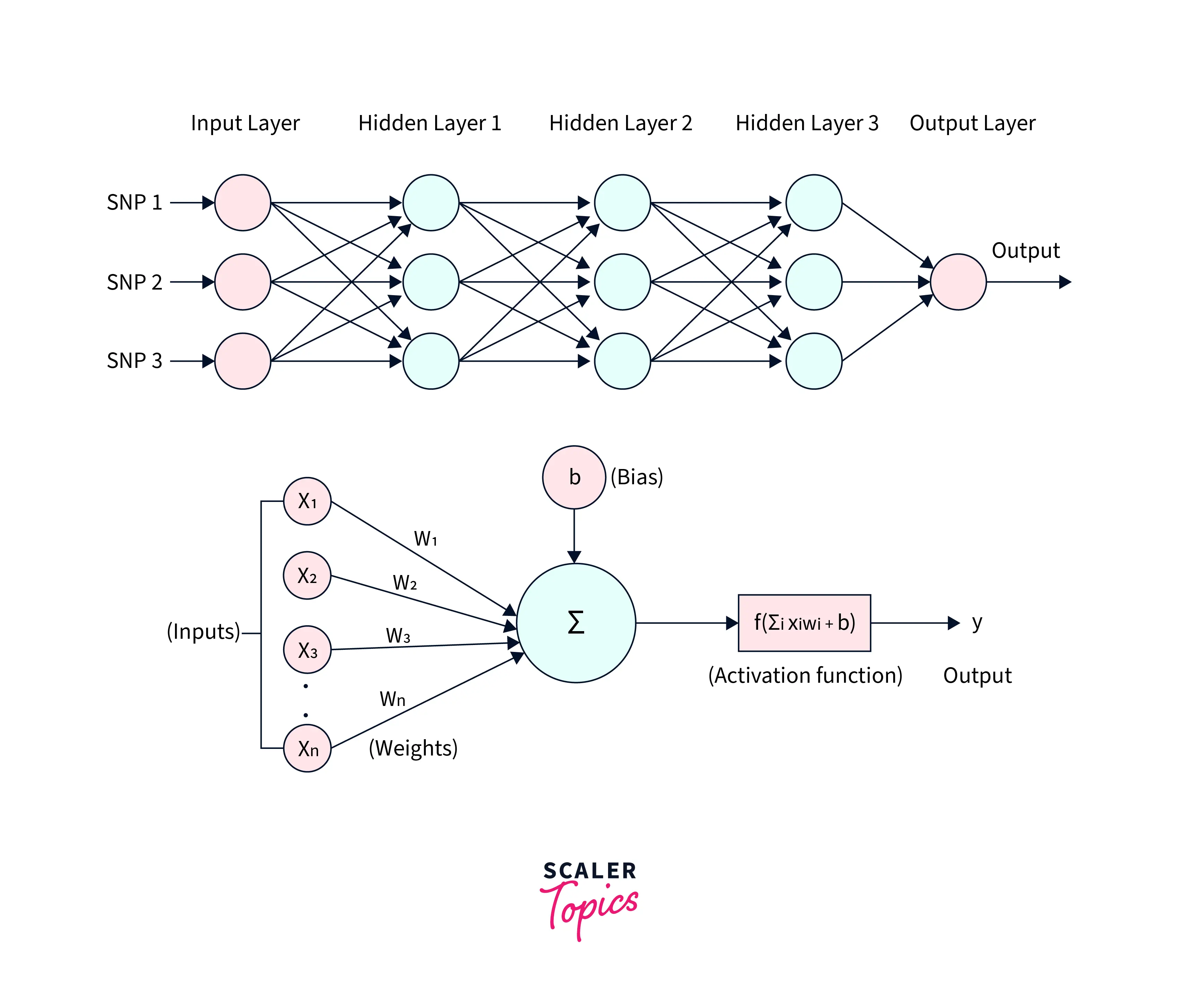
Introduction to Neural Networks: A multi-layer perceptron (MLP) is a type of neural network comprising multiple layers of artificial neurons, typically consisting of an input layer, one or more hidden layers, and an output layer. The input is passed through the network layers, with each layer applying weights and a non-linear activation function to the input, resulting in an output prediction. The weights are learned during training by adjusting them to minimize the error between the predicted output and the actual output. In addition, the non-linear activation functions introduce non-linearity to the model, allowing the MLP to solve more complex problems than single-layer perceptron. As a result, the MLP is a powerful algorithm widely used in many modern deep learning applications, such as image and speech recognition, natural language processing, and more.
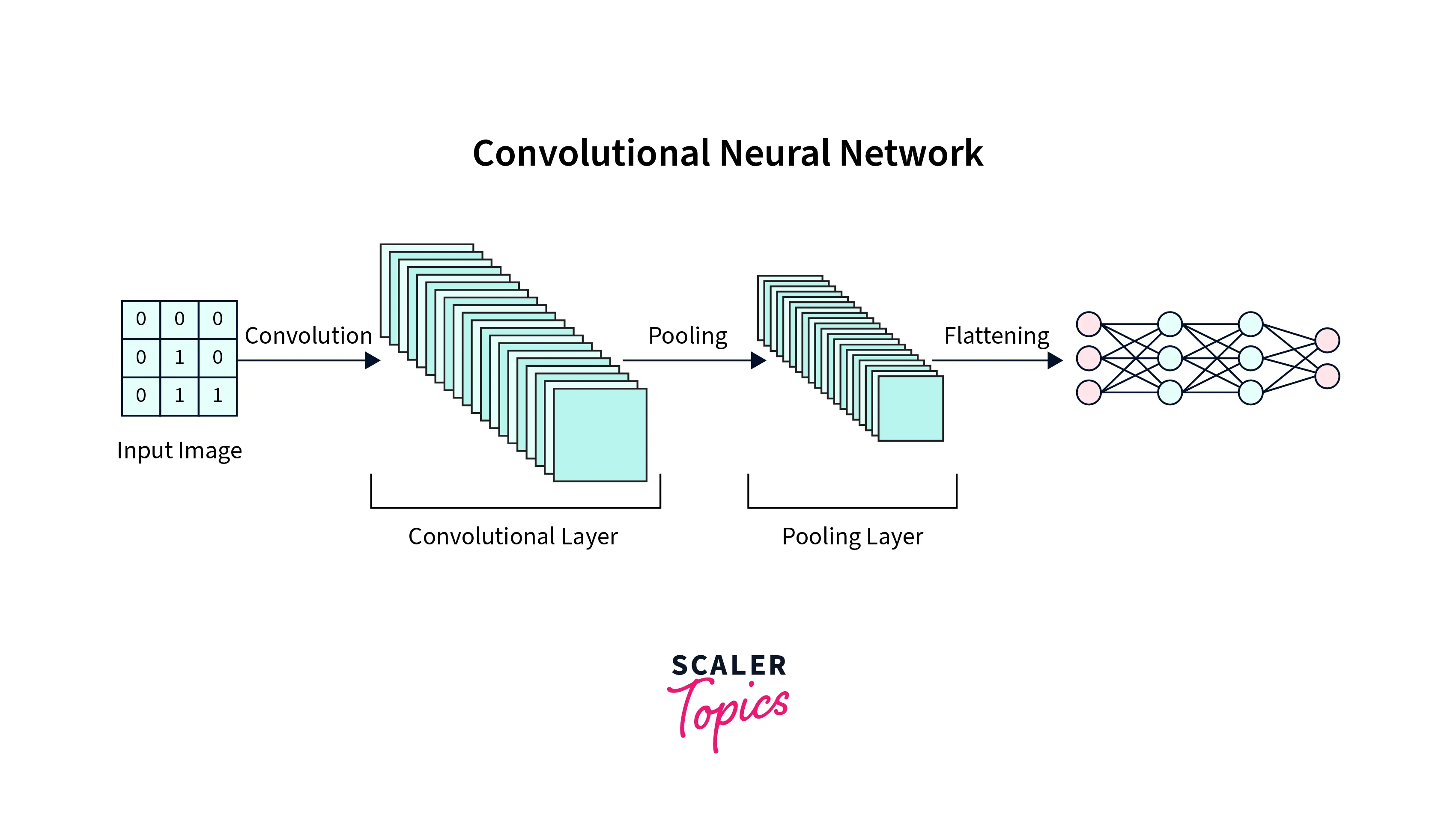
Convolutional Neural Network (CNN)
A Convolutional Neural Network (CNN) is a neural network that processes data with a grid-like topology, such as images. A CNN comprises multiple layers, each performing a specific function to extract features from the input image. The layers in a CNN can be broadly categorized into the following types:
-
Convolutional layer: performs a mathematical operation called convolution on the input data, which helps to extract features from the image.
-
Pooling Layer: reduces the spatial dimensions of the data, which helps to reduce computational complexity and improve the ability of the network to generalize to new images.
-
Fully Connected Layer: connects every neuron in the previous layer to the next layer, which helps to combine the features extracted by the convolutional and pooling layers to make a final prediction.
-
Normalization Layer: helps to improve the stability of the network during training by normalizing the inputs.
-
Activation Layer: applies a non-linear activation function to the inputs, which helps to introduce non-linearity to the model and improve its ability to learn complex patterns.
These layers are stacked together to create a deep neural network to learn complex features and classify images accurately.
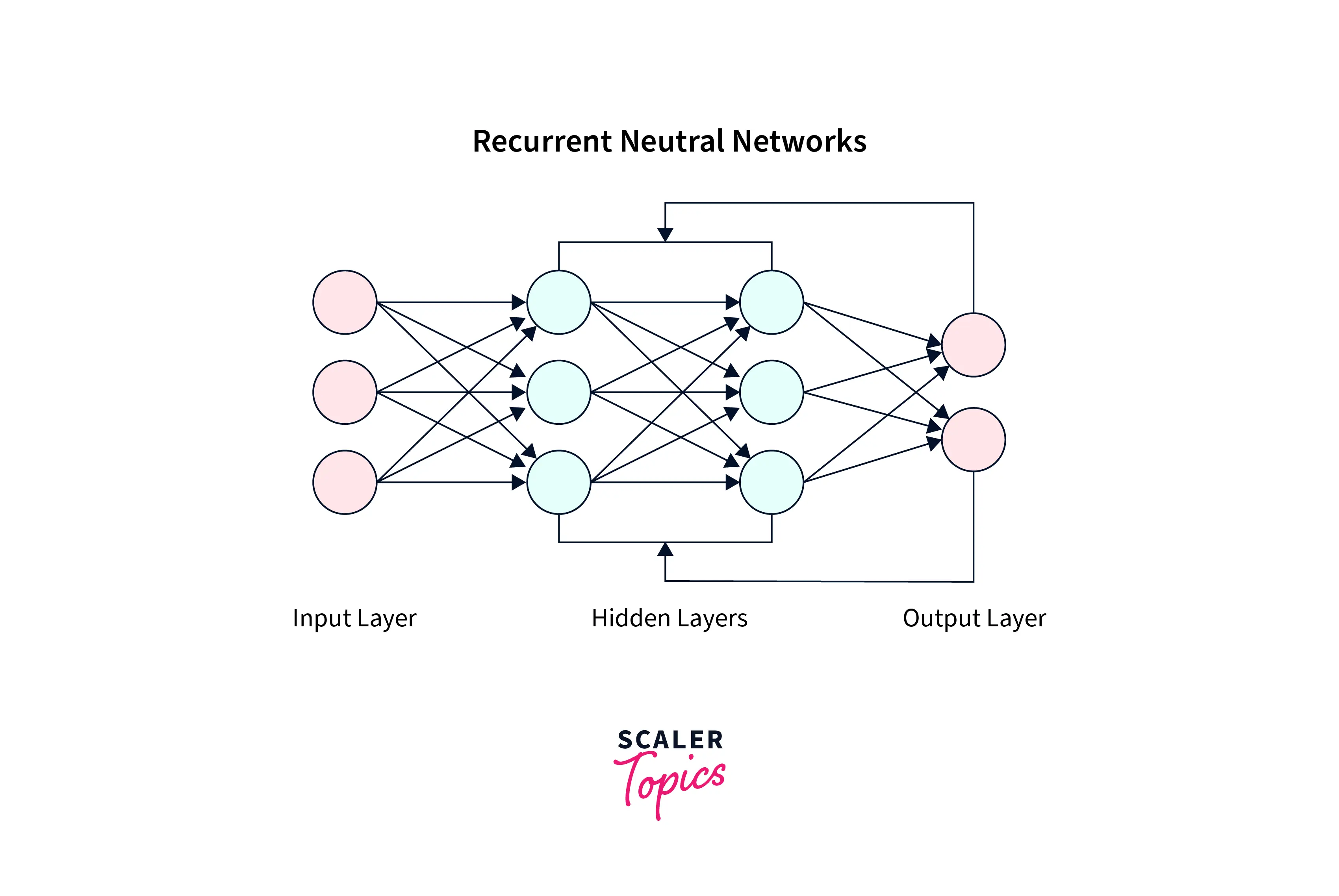
Recurrent neural networks
Recurrent neural networks (RNNs) are a type of neural network that can process sequential data, such as time series, natural language, and speech. RNNs have an internal memory that allows them to remember and use information from previous time steps when processing the current time step. This makes them effective for tasks that require modeling temporal dependencies or processing data with long-term dependencies. RNNs come in several variations, including LSTMs and GRUs, which have additional mechanisms to preserve long-term dependencies better and prevent the internal state from vanishing or exploding during training. RNNs are used in various applications, including language translation, modeling, speech recognition, and music generation.
What is Artificial Neuron?
An artificial neuron is a mathematical function that models a biological neuron's behavior. It takes one or more inputs, performs some computation, and produces a single output. The inputs and output are numbers, and the computation is a simple mathematical operation, such as a dot product followed by a non-linear function called an " activation function".
In a neural network, artificial neurons are organized into layers. Each neuron in a layer receives inputs from the neurons in the previous layer. The weights of these connections between neurons are adjusted during the training process to improve the accuracy of the network's predictions. The inputs are passed through the network layer by layer until they reach the output layer, producing the final result.
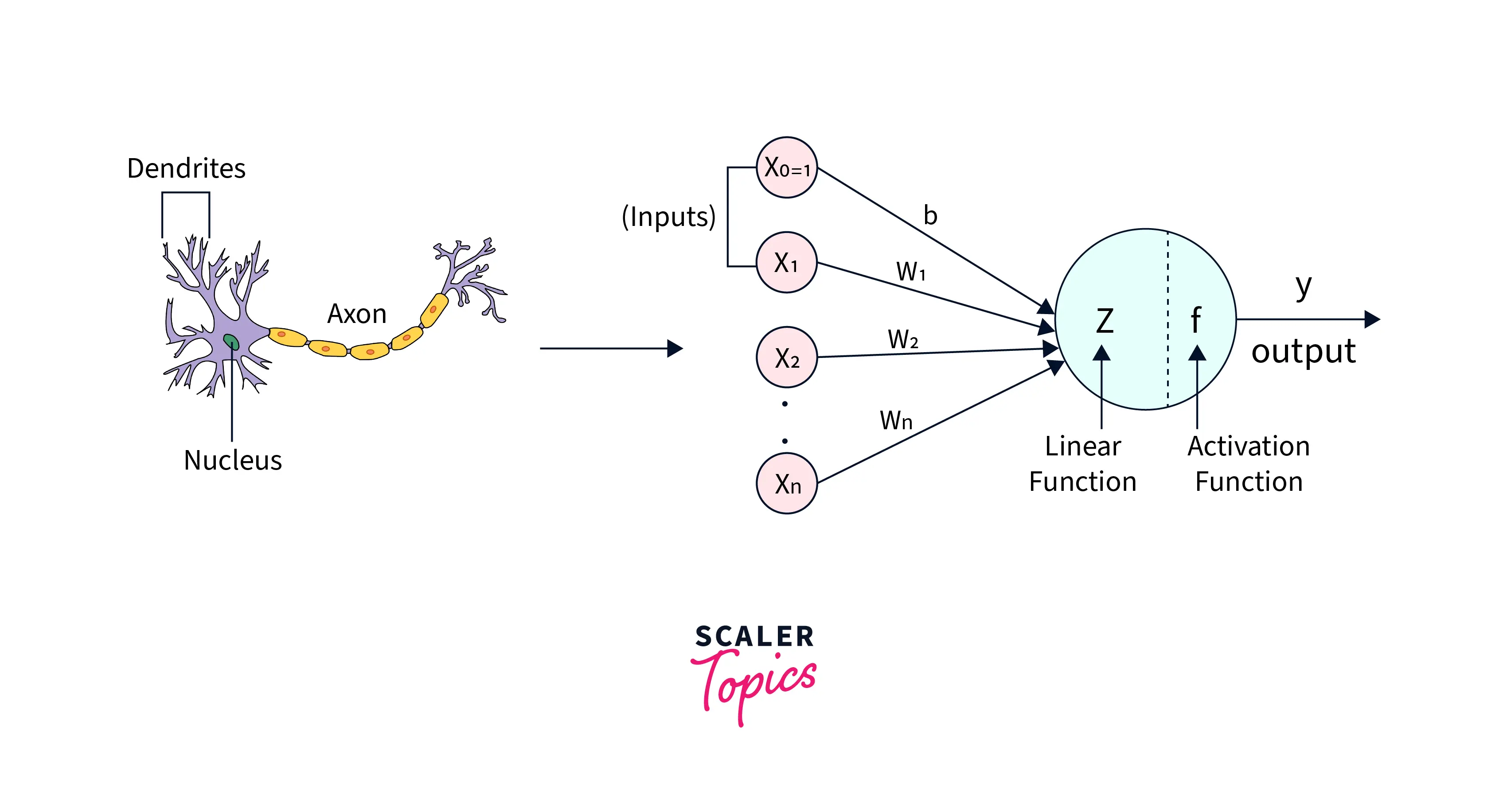
- A biological neuron receives input signals through dendrites, and a perceptron receives data through input neurons
- The connections between dendrites and biological neurons are called synapses, and the connections between inputs and perceptrons are called weights
- The nucleus in a biological neuron produces an output signal based on the input signals, and the nucleus in a perceptron performs calculations to produce an output
- In a biological neuron, the output signal is carried away by the axon, and in a perceptron, the output value is used as input for the next perceptron.
Biological Neuron vs. Artificial Neuron
| Biological Neuron | Artificial Neuron |
|---|---|
| Biological neurons are cells in living organisms that process and transmit information. | Artificial neurons are computer programs that mimic the behavior of biological neurons and are the building blocks of artificial neural networks (ANNs). |
| Biological neurons use electrochemical signals. | Artificial neurons use digital signals. |
| Biological neurons take longer to process information compared to artificial neurons. | Artificial neural networks can process information more quickly than biological neurons. |
| Larger in size. | Smaller in size. |
| All the processing is centrally controlled. | Control unit monitors all computing-related activities. |
What is the Loss function?
A loss function, also known as a cost function or objective function, is a mathematical function that measures the difference between the predicted output and the actual output of a model. The purpose of the loss function is to measure how well the model can make predictions on a given dataset. The goal of training a machine learning model is to minimize the value of the loss function, which means that the model's predictions are as close as possible to the actual output. Many types of loss functions, such as mean squared error, cross-entropy, and hinge loss, are used depending on the specific problem and model.
Activation Functions in Neural Networks
Activation functions are an important part of artificial neural networks. They are used to determine the output of a neuron given an input or set of inputs. Activation functions allow neural networks to learn and adapt to new data, and they help make the network more powerful by introducing non-linearity into the model.
Many different types of activation functions can be used in neural networks, including:
-
Sigmoid function: This function maps any input value to a value between 0 and 1, which makes it useful for classification tasks where the output is a probability.
-
Tanh function: This function maps any input value to a value between -1 and 1. It is similar to the sigmoid function but is centered at zero and has a stronger gradient.
-
ReLU (Rectified Linear Unit) function: This function maps any input value to either 0 or the input value itself, depending on whether the input is positive or negative. It is widely used because it is simple and efficient.
-
Leaky ReLU function: This function is similar to the ReLU function but has a small slope for negative input values, which helps address the "dying ReLU" problem.
-
Softmax function: This function is used in classification tasks with multiple classes. It maps the input values to a probability distribution over the classes, such that the sum of the probabilities is one.
Conclusion
- Neural networks are machine learning algorithms inspired by the structure and function of the human brain. They consist of layers of interconnected "neurons" that process and transmit information.
- Deep learning is a subfield of machine learning that uses deep neural networks with multiple layers to analyze and learn from data.
- Common applications include image and speech recognition, natural language processing, and self-driving cars.
- Training a deep neural network involves using a large dataset and an optimization algorithm to adjust the network's parameters to minimize a loss function that measures the difference between the predicted and actual output.
- Advancements in computational power and large data sets have made it possible to train deep neural networks that can achieve state-of-the-art performance in various fields
- The field is still actively evolving, with new techniques and architectures being developed to improve the performance and capabilities of neural networks and deep learning models.