Introduction to Relational Model in DBMS

E.F. Codd introduced the relational model for structuring data into tables. After conceptualizing a database with an ER diagram, the transition to the relational model is essential. In database management systems (DBMS), this model organizes data into interconnected tables, or relations, where each row signifies an entity and each column denotes the entity's properties, facilitating efficient data storage and management.
What is the Relational Model?
The relational model for database management is an approach to logically represent and manage the data stored in a database. In this model, the data is organized into a collection of two-dimensional inter-related tables, also known as relations. Each relation is a collection of columns and rows, where the column represents the attributes of an entity and the rows (or tuples) represents the records.
The use of tables to store the data provided a straightforward, efficient, and flexible way to store and access structured information. Because of this simplicity, this data model provides easy data sorting and data access. Hence, it is used widely around the world for data storage and processing.
Let's look at a scenario to understand the relational model:
Consider a case where you wish to store the name, the CGPA attained, and the roll number of all the students of a particular class. This structured data can be easily stored in a table as described below:
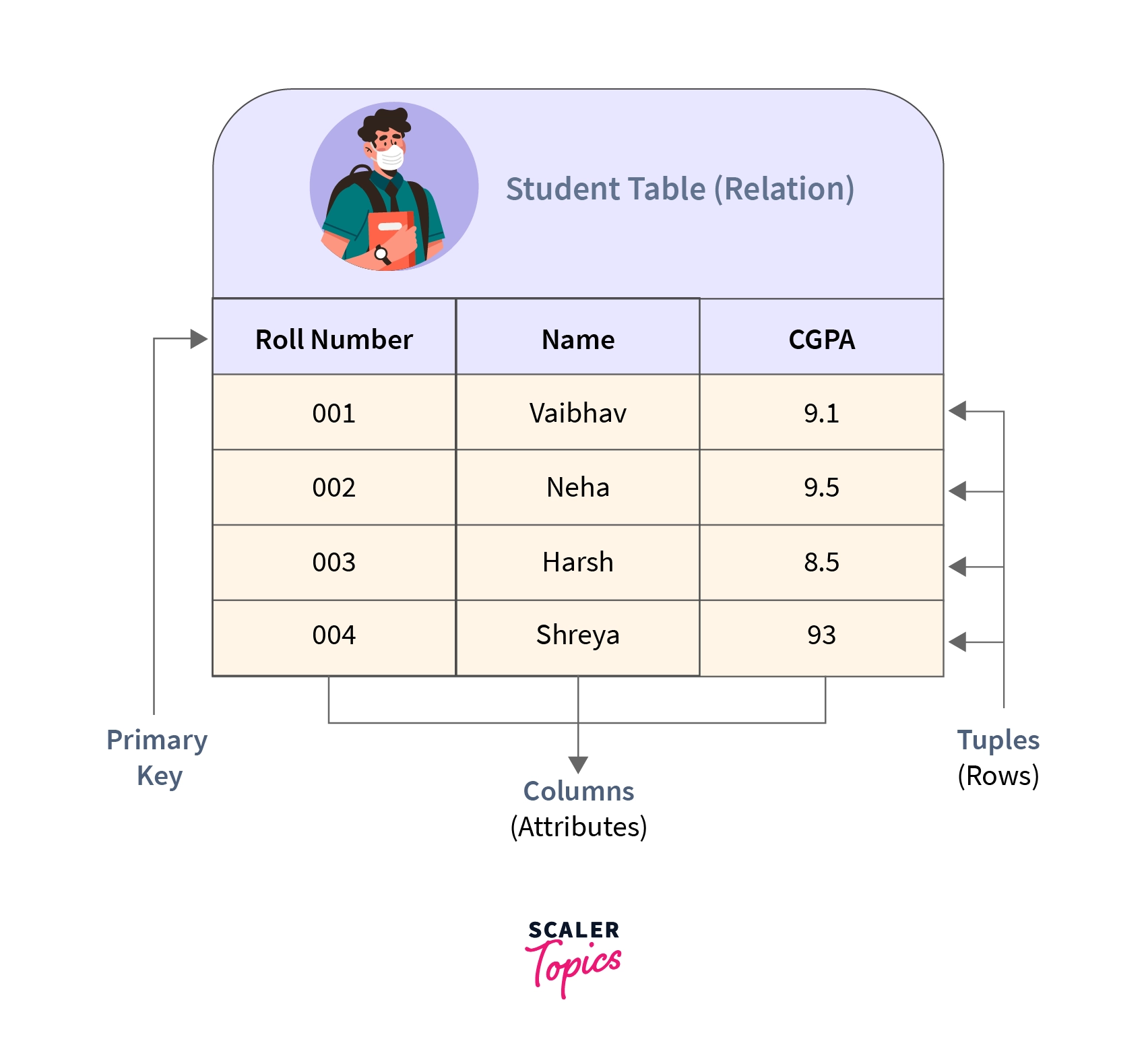
As we can notice from the above relation:
- Any given row of the relation indicates a student, i.e., the row of the table describes a real-world entity.
- The columns of the table indicate the attributes related to the entity. In this case, the roll number, CGPA, and the name of the student.
NOTE: A database implemented and organized in terms of the relational model is known as a relational database management system (RDBMS). Hence, the relational model describes how data is stored in relational databases.
Highlights:
- Relational Model stores the data into tables (relations).
- It makes data sorting and data access easier.
- Provides a standard way to organize data in databases.
:::
Relational Model Concepts
As discussed earlier, a relational database is based on the relational model. This database consists of various components based on the relational model. These include:
- Relation: Two-dimensional table is used to store a collection of data elements.
- Tuple: Row of the relation, depicting a real-world entity.
- Attribute/Field: Column of the relation, depicting properties that define the relation.
- Attribute Domain: Set of pre-defined atomic values that an attribute can take, i.e., it describes the legal values that an attribute can take.
- Degree: It is the total number of attributes present in the relation.
- Cardinality: It specifies the number of entities involved in the relation, i.e., it is the total number of rows present in the relation.
- Relational Schema: It is the logical blueprint of the relation, i.e., it describes the design and the structure of the relation. It contains the table name, its attributes, and their types:
TABLE_NAME(ATTRIBUTE_1 TYPE_1, ATTRIBUTE_2 TYPE_2, ...)
For our Student relation example, the relational schema will be:
STUDENT(ROLL_NUMBER INTEGER, NAME VARCHAR(20), CGPA FLOAT)
- Relational Instance: It is the collection of records present in the relation at a given time.
- Relation Key: It is an attribute or a group of attributes that can be used to uniquely identify an entity in a table or to determine the relationship between two tables. Relation keys can be of 6 different types:
- Candidate Key
- Super Key
- Composite Key
- Primary Key
- Alternate Key
- Foreign Key
Highlights:
- A Relation is a collection of rows (tuples) and columns (attributes).
- In a relation, the tuples depict real-world entities, while the attributes are the properties that define the relation.
- Structure of the relation is described by the relational schema.
- Relational keys are used to uniquely identify a row in a table or to determine the relationship between two tables.
:::
Constraints in Relational Model
Relational models use some rules to ensure the accuracy and accessibility of the data. These rules or constraints are known as Relational Integrity Constraints. These constraints are checked before performing any operation like insertion, deletion, or updation on the data present in a relational database. These constraints include:
- Domain Constraint: It specifies that every attribute is bound to have a value that lies inside a specific range of values. It is implemented with the help of the Attribute Domain concept.
- Key Constraint: It states that every relation must contain an attribute or a set of attributes (Primary Key) that can uniquely identify a tuple in that relation. This key can never be NULL or contain the same value for two different tuples.
- Referential Integrity Constraint: It is defined between two inter-related tables. It states that if a given relation refers to a key attribute of a different or same table, then that key must exist in the given relation.
Highlights:
- To ensure data accuracy and accessibility, Relational Integrity Constraints are implemented.
- It includes domain, key, and referential integrity constraints.
:::
Anomalies in Relational Model
When we notice any unexpected behavior while working with the relational databases, there may be a presence of too much redundancy in the data stored in the database. This can cause anomalies in the DBMS and it can be of various types such as:
-
Insertion Anomalies: It is the inability to insert data in the database due to the absence of other data. For example: Suppose we are dividing the whole class into groups for a project and the GroupNumber attribute is defined so that null values are not allowed. If a new student is admitted to the class but not immediately assigned to a group then this student can't be inserted into the database.
-
Deletion Anomalies - It is the accidental loss of data in the database upon deletion of any other data element. For example: Suppose we have an employee relation that contains the details of the employee along with the department they are working in. Now, if a department has one employee working in it and we remove the information of this employee from the table, there will be the loss of data related to the department also. This can lead to data inconsistency.
-
Modification/Update Anomalies - It is the data inconsistency that arises from data redundancy and partial updation of data in the database. For example: Suppose, while updating the data into the database duplicate entries were entered. Now, if the user does not realize that the data is stored redundantly after updation, there will be data inconsistency in the database.
All these anomalies can lead to unexpected behavior and inconvenience for the user. These anomalies can be removed with the help of a process known as normalization.
Highlights:
- Any unexpected behavior in a relational database can be caused by an anomaly.
- Anomaly occurs mainly due to the presence of data redundancy in the database.
- Anomalies are of 3 types, i.e., Insertion, Updation, and Deletion anomaly.
:::
Codd Rules in DBMS
Edgar F. Codd, the creator of the relational model, proposed 13 rules knowns as Codd Rules that states:
For a database to be considered as a perfect relational database, it must follow the following rules:
- Foundation Rule - The database must be able to manage data in relational form.
- Information Rule - All data stored in the database must exist as a value of some table cell.
- Guaranteed Access Rule - Every unique data element should be accessible by only a combination of the table name, primary key value, and column name.
- Systematic Treatment of NULL values - Database must support NULL values.
- Active Online Catalog - The organization of the database must exist in an online catalog that can be queried by authorized users.
- Comprehensive Data Sub-Language Rule - Database must support at least one language that supports: data definition, view definition, data manipulation, integrity constraints, authorization, and transaction boundaries.
- View Updating Rule - All views should be theoretically and practically updatable by the system.
- Relational Level Operation Rule - The database must support high-level insertion, updation, and deletion operations.
- Physical Data Independence Rule - Data stored in the database must be independent of the applications that can access it, i.e., the data stored in the database must not depend on any other data or an application.
- Logical Data Independence Rule - Any change in the logical representation of the data (structure of the tables) must not affect the user's view.
- Integrity independence - Changing the integrity constraints at the database level should not reflect any change at the application level.
- Distribution independence - The database must work properly even if the data is stored in multiple locations or is being used by multiple end-users.
- Non-subversion Rule - Accessing the data by low-level relational language should not be able to bypass the integrity rules and constraints expressed in the high-level relational language.
Highlights:
- Codd Rules are 13 sets of constraints that a perfect relational database must follow.
- Codd Rules were introduced by Edgar F. Codd to resolve the database standardization problem.
:::
Advantages of using the relational model
The advantages and reasons due to which the relational model in DBMS is widely accepted as a standard are:
- Simple and Easy To Use - Storing data in tables is much easier to understand and implement as compared to other storage techniques.
- Manageability - Because of the independent nature of each relation in a relational database, it is easy to manipulate and manage. This improves the performance of the database.
- Query capability - With the introduction of relational algebra, relational databases provide easy access to data via high-level query language like SQL.
- Data integrity - With the introduction and implementation of relational constraints, the relational model can maintain data integrity in the database.
Highlights:
- Relational databases are simple to use, easy to manage, provide data integrity, and are query capable.
- All the advantages of relational databases are because of the use of tables and constraints.
:::
Disadvantages of using the relational model
The main disadvantages of relational model in DBMS occur while dealing with a huge amount of data as:
- The performance of the relational model depends upon the number of relations present in the database.
- Hence, as the number of tables increases, the requirement of physical memory increases.
- The structure becomes complex and there is a decrease in the response time for the queries.
- Because of all these factors, the cost of implementing a relational database increases.
Highlights:
- Relational databases work perfectly well for a limited number of relations.
- Increasing the amount of data can lead to performance and storage issues with relational databases.
:::
Conclusion
- Relational model in DBMS is an approach to logically represent and manage the data stored in a database by storing data in tables.
- Relations, Attributes and Tuples, Degree and Cardinality, Relational Schema and Relation instance, and Relation Keys are some important components of the Relational Model.
- To maintain data integrity constraints such as domain, key, and referential integrity are implemented in the relational model.
- Presence of redundancy in data can lead to insertion, deletion, and updation anomalies in a relational database.
- A perfect relational database follows and implements all the 13 Codd Rules.
- Because of the use of tables and constraints, relational models are simple to use, easy to manage, provide data integrity, and are query capable.
- Increasing the amount of data can lead to performance and storage issues with relational databases.