Issues in Machine Learning
Overview
Machine learning is a transformative field in which computers learn from data, improving their performance on tasks without being explicitly programmed. It encompasses a range of techniques that enable computers to recognize patterns and make predictions, enhancing their capabilities over time. On the other hand, machine learning also faces several challenges and issues.
These include concerns about bias and fairness in algorithms, the interpretability of complex models, the need for large amounts of high-quality data, potential security vulnerabilities, and ethical considerations surrounding privacy, accountability, and the potential impact on jobs and society. Addressing these issues is crucial to harness the power of machine learning for positive and responsible outcomes.
With an understanding of the significance of challenges in machine learning, let's delve into the prevalent problems frequently encountered in this field.
Common Issues in Machine Learning
As the field of machine learning continues to advance, it has become increasingly evident that its widespread adoption is not without its share of challenges. These challenges, often referred to as the common issues in machine learning, encompass a range of complex and interconnected problems that researchers, practitioners, and policymakers must grapple with.
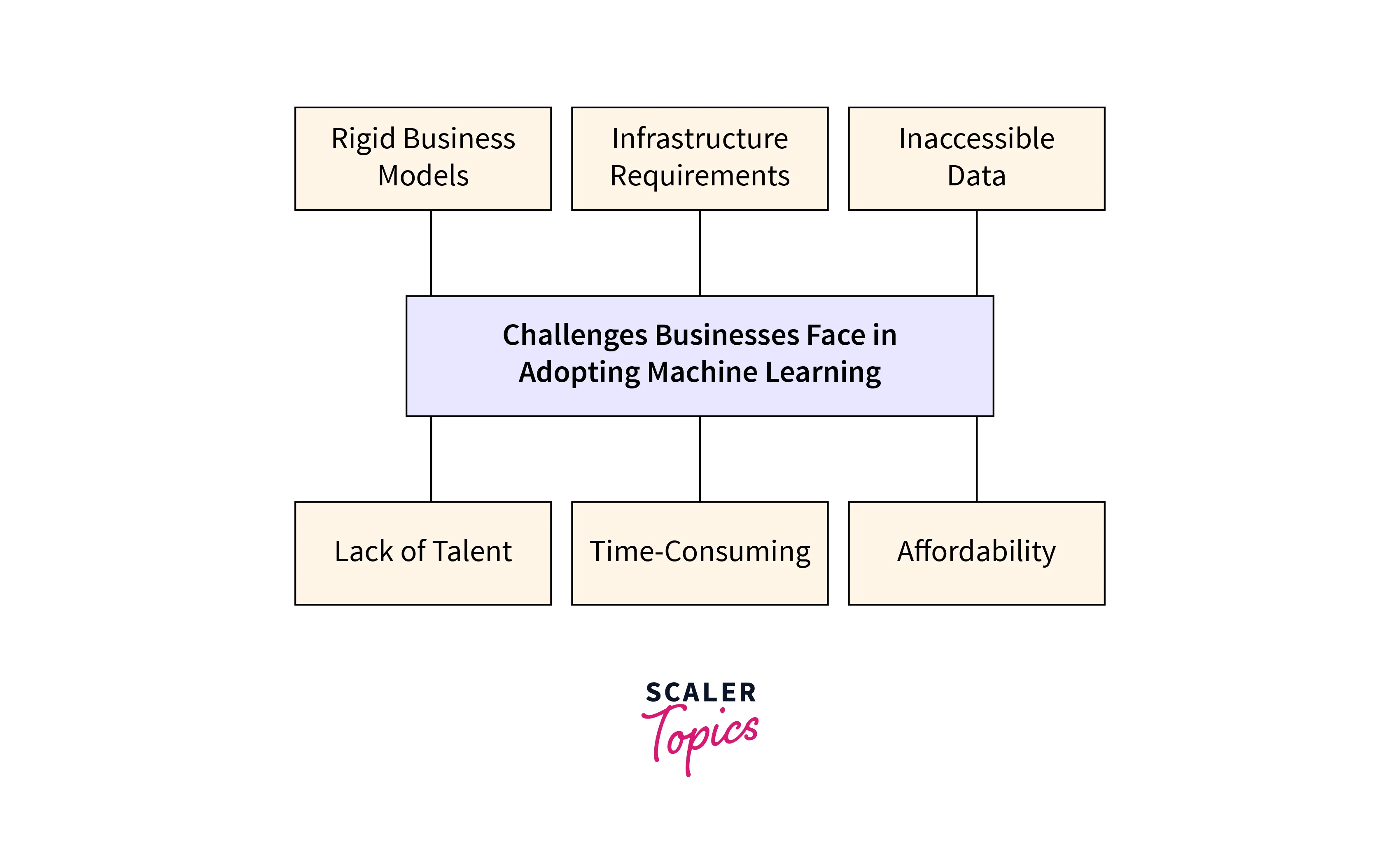
Addressing data bias, model complexity, and ethical implications is crucial for responsible machine learning deployment, emphasizing the need for holistic solutions in this evolving field. This exploration into the common issues in ML will shed light on the multifaceted nature of these challenges and underscore the need for comprehensive solutions in this ever-evolving landscape.
Poor Quality of Data
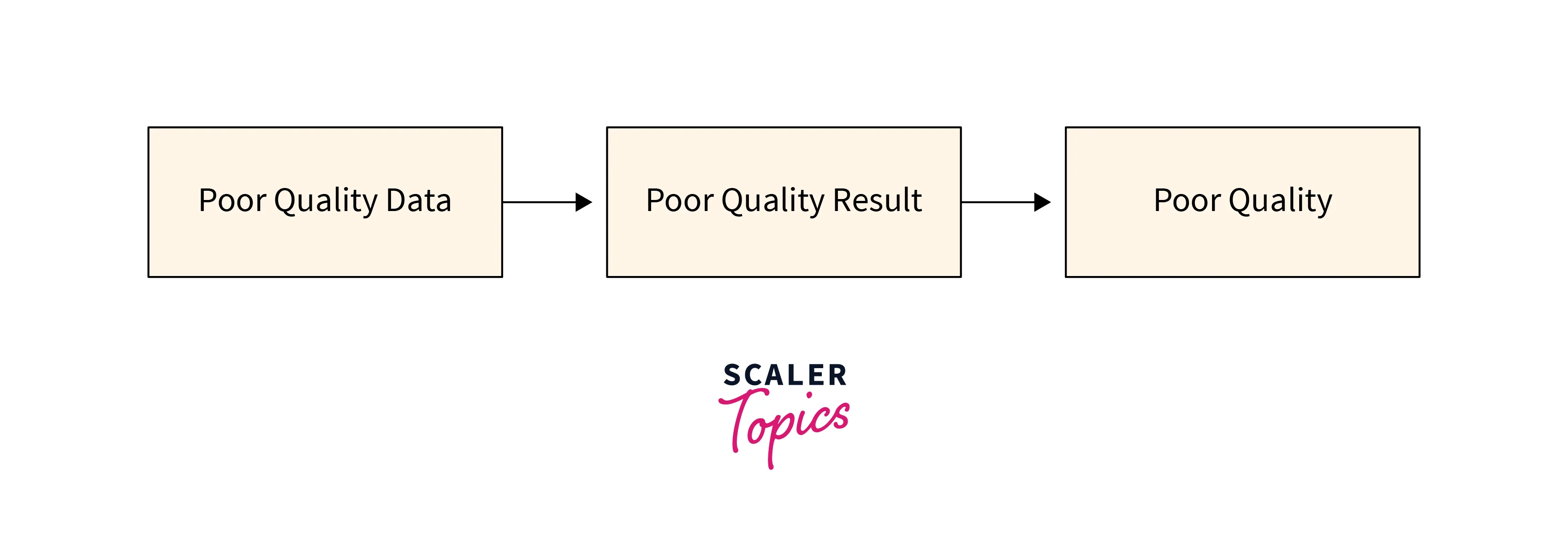
-
Incomplete Data: Poor data quality often stems from incomplete datasets, where crucial information is missing or not collected uniformly. This can hinder the training process and lead to inaccurate models, as the algorithms might struggle to grasp the underlying patterns due to insufficient information.
-
Noisy Data: Noise in data refers to irrelevant or erroneous information that can mislead machine learning algorithms. Noisy data can arise from various sources, such as sensor errors or human input mistakes. Algorithms trained on noisy data might learn from these errors rather than the actual patterns, resulting in suboptimal performance.
Underfitting of Training Data
-
Insufficient Model Complexity: Underfitting occurs when the chosen machine learning model is too simplistic to capture the underlying patterns in the data. If the model is too basic, it might struggle to learn the complexities of the dataset, resulting in poor performance both on the training and validation/test datasets.
-
Limited Training Iterations: Inadequate training iterations or epochs can prevent the model from fully converging to a suitable solution. If the model stops learning too early, it might not have refined its internal parameters enough to make accurate predictions, leading to underfitting.
Overfitting of Training Data
-
Complex Model: Overfitting occurs when a machine learning model is excessively complex, fitting not only the underlying patterns in the data but also the noise and randomness present in the training dataset. This can lead to a model that performs exceptionally well on the training data but fails to generalize to new, unseen data.
-
Limited Data: When the training dataset is small, complex models can effectively memorize the training examples rather than learn the actual patterns. As a result, they struggle to make accurate predictions on new data. This phenomenon is particularly pronounced in situations where the model has more parameters than there are data points to constrain them effectively.
Machine Learning is a Complex Process
-
Algorithm Selection: Choosing the appropriate machine learning algorithm for a specific task is a complex decision. Different algorithms have distinct strengths and weaknesses, and selecting the right one requires a deep understanding of their characteristics and the problem at hand.
-
Hyperparameter Tuning: Each machine learning algorithm has hyperparameters that need to be set before training. Finding the optimal combination of hyperparameters can be challenging and often involves iterative experimentation and validation to achieve the best model performance.
Lack of Training Data
-
Limited Representativeness: Insufficient training data may lead to models that fail to capture the true diversity and complexity of real-world scenarios. A small or unrepresentative dataset can result in biased or inaccurate predictions when the model encounters new, diverse examples.
-
Reduced Generalization: Inadequate training data can hinder a model's ability to generalize well beyond the data it was trained on. Without exposure to a wide range of instances, the model might struggle to identify underlying patterns and make accurate predictions in various contexts.
Slow Implementation
-
Resource Intensive Algorithms: Some machine learning algorithms are computationally demanding, requiring significant processing power and memory. Implementing such algorithms can lead to slow training and inference times, making them less practical for real-time or large-scale applications.
-
Complex Model Architectures: Deep learning models, with their intricate architectures, can be slow to train and deploy due to the vast number of parameters involved. The complexity of these models often necessitates specialized hardware or distributed computing setups, which can contribute to slower implementation times.
Imperfections in the Algorithm When Data Grows
-
Scalability Challenges: As datasets grow larger, algorithms that once worked well might encounter scalability issues. Some algorithms might struggle to process and analyze massive datasets efficiently, leading to slower training times and increased computational demands.
-
Increased Sensitivity: Algorithms that perform well on smaller datasets might become more sensitive to outliers, noise, and variations as the data grows. This can lead to decreased model performance, as the algorithm may overfit the noise present in the larger dataset. Regularization techniques and careful preprocessing become crucial to address this issue.
How to Overcome Issues in Machine Learning
Overcoming issues in machine learning requires a multi-faceted approach. Enhancing data quality involves rigorous data preprocessing, identifying and addressing biases, and collecting additional data if necessary.
-
Enhance Data Quality: Rigorous preprocessing, bias detection, and additional data collection can improve data quality and mitigate biases.
-
Address Underfitting: Employ more complex models, increase training iterations, and include relevant features to overcome underfitting issues.
-
Combat Overfitting: Use model simplification techniques, apply regularization, and validate with cross-validation to counter overfitting challenges.
-
Manage Complexity: Stay updated with evolving techniques, continuously learn, and adopt best practices to navigate the complexities of the field.
-
Tackle Limited Data: Implement data augmentation, leverage transfer learning, and consider synthetic data generation to mitigate limitations posed by insufficient data.
-
Optimize Implementation: Opt for efficient coding practices, utilize parallel processing, and leverage hardware acceleration to overcome slow implementation.
-
Adapt to Data Growth: Adjust algorithms to handle larger datasets and choose models designed to scale effectively as data expands.
By applying these strategies, machine learning challenges can be systematically addressed, enhancing the reliability and performance of models.
Conclusion
In conclusion, the journey through the landscape of machine learning challenges has unveiled the intricate nature of this transformative field. The recognition of issues spanning data quality, model behaviour, implementation efficiency, and scalability highlights the multifaceted aspects that demand careful consideration.
However, this exploration also illuminates the power of strategic solutions that lie within reach. By embracing rigorous data practices, leveraging diverse model strategies, optimizing implementation processes, and adapting algorithms to evolving data dynamics, the realm of machine learning can be navigated more effectively.
Through these concerted efforts, the path toward responsible and impactful deployment of machine learning technologies becomes clearer, fostering advancements that contribute positively to industries, societies, and the broader technological horizon.