Hashmap in Java

Overview
HashMap in Java is a part of the collections framework, which is found in java.util package. It provides the basic implementation of Map interface of Java. It stores the data in a key-value mapping in which every key is mapped to exactly one value of any data type.
Keys should be unique as the key is used to retrieve the corresponding value from the map. Since Java 5, it is denoted as HashMap<K,V>, where K stands for Key and V for Value. In this article, we will see the uses of HashMap in Java, its internal working and examples.
Introduction to Java HashMap
HashMap in Java is a collection that implements Map interface. HashMap<K, V> stores the data in (Key, Value) pairs. Here, keys are unique identifiers used to associate each value on a map.
HashMap is unsynchronised, therefore it's faster and uses less memory than HashTable. Being unsynchronized means HashMap doesn’t guarantee any specific order of the elements.
Also, HashMap in Java allows to add null keys but there should be only one entry with null as key. However, there can be any number of entries with null as value.
We should choose HashMap over HashTable for an unsynchronized or single-threaded application. Although, since JDK 1.8 HashTable has been deprecated.
Syntax:
The declaration for java.util.HashMap class is as follows:
The HashMap in Java implements Serializable, Cloneable, Map<K,V> interfaces and it extends AbstractMap<K,V> class.
Parameters:
The HashMap in Java takes two parameters which are as follows:
- K: It is the data type of keys maintained by the map. Keys should be unique.
- V: It is the data type of values maintained. Values need not be unique. It can be duplicate.
Basic Usage of HashMap in Java
HashMap in Java is the implementation of map, which is a key-value mapping. Now, one might question that if we simply want to add values, then why can't we use a list? Why do we need HashMap? The simple reason is performance.
To find a specific element in a list, the time complexity is for insertion and lookup and if the list is sorted, it will be on using binary search.
The advantage of HashMap is that the time complexity to insert and retrieve a value is on average, and space complexity is . We will look at the performance of HashMap in Java later in the article.
Example: Create HashMap in Java
First, the java.util.HashMap package needs to be imported to create a HashMap in Java. After the import is done, we can create HashMap in Java as below:
In the above code, a hashmap named languages is created. Here, K represents the key type and V represents the type of values such as below:
Here, the type of key is String, and the type of value is Integer.
Example:
Output:
In the above example, we have created a HashMap named languages. Here, we have used the put() method to add elements to the hashmap. We will learn more about the put() method later in this article.
Hierarchy of HashMap in Java
The hierarchy of HashMap is as follows:
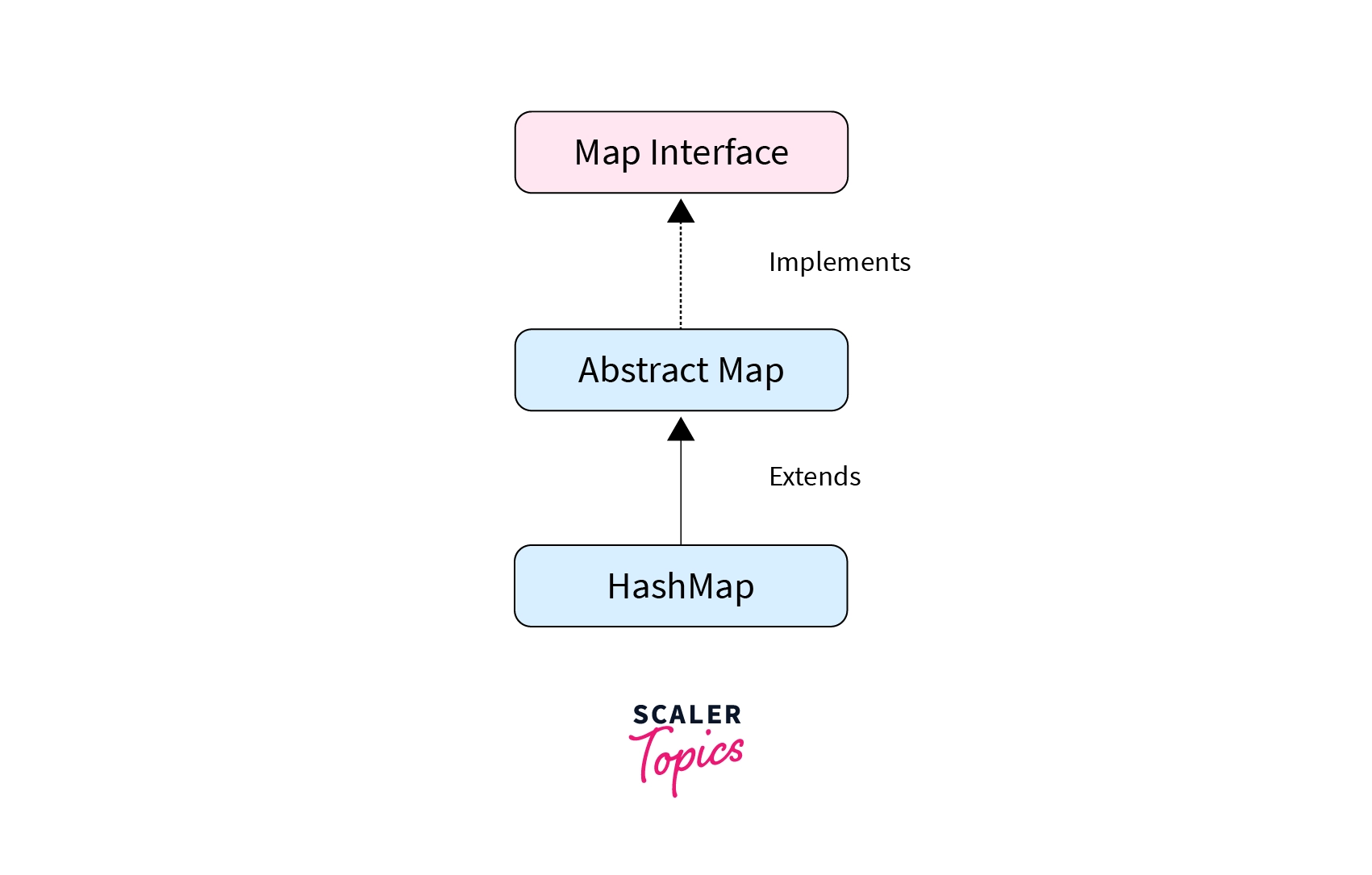
The HashMap in Java implements Serializable, Cloneable, Map interfaces. It extends AbstractMap class.
Constructors in HashMap Java
HashMap in Java has 4 constructors, and each one has public access modifier. The constructors are as follows:
- HashMap()
- HashMap(int initialCapacity)
- HashMap(int initialCapacity, float loadFactor)
- HashMap(Map map)
Before discussing the constructors in detail, let's take a deep dive into a few other terms for better understanding:
- Hashing: HashMap in Java works on the principle of hashing — an algorithm to map object data to some representative integer values.
Hashing is a process of converting an object into integer form by using the method hashCode(). hashCode() method of object class returns the memory reference of object in integer form. So the Hash function is applied to the key object to calculate the index of the bucket in order to store and retrieve any key-value pair.
HashMap<K,V> manages an array of Node<K,V> objects that will be replaced by another larger array if all of its elements has been assigned value. Node<K,V> class consists of 4 fields. The next field is a reference to the next Node object.
It may not be the next element in the array. HashMap ensures those Node(s) having the same hashcode will have consecutive references. This helps it quickly find all Node(s) with the same specified hashcode.
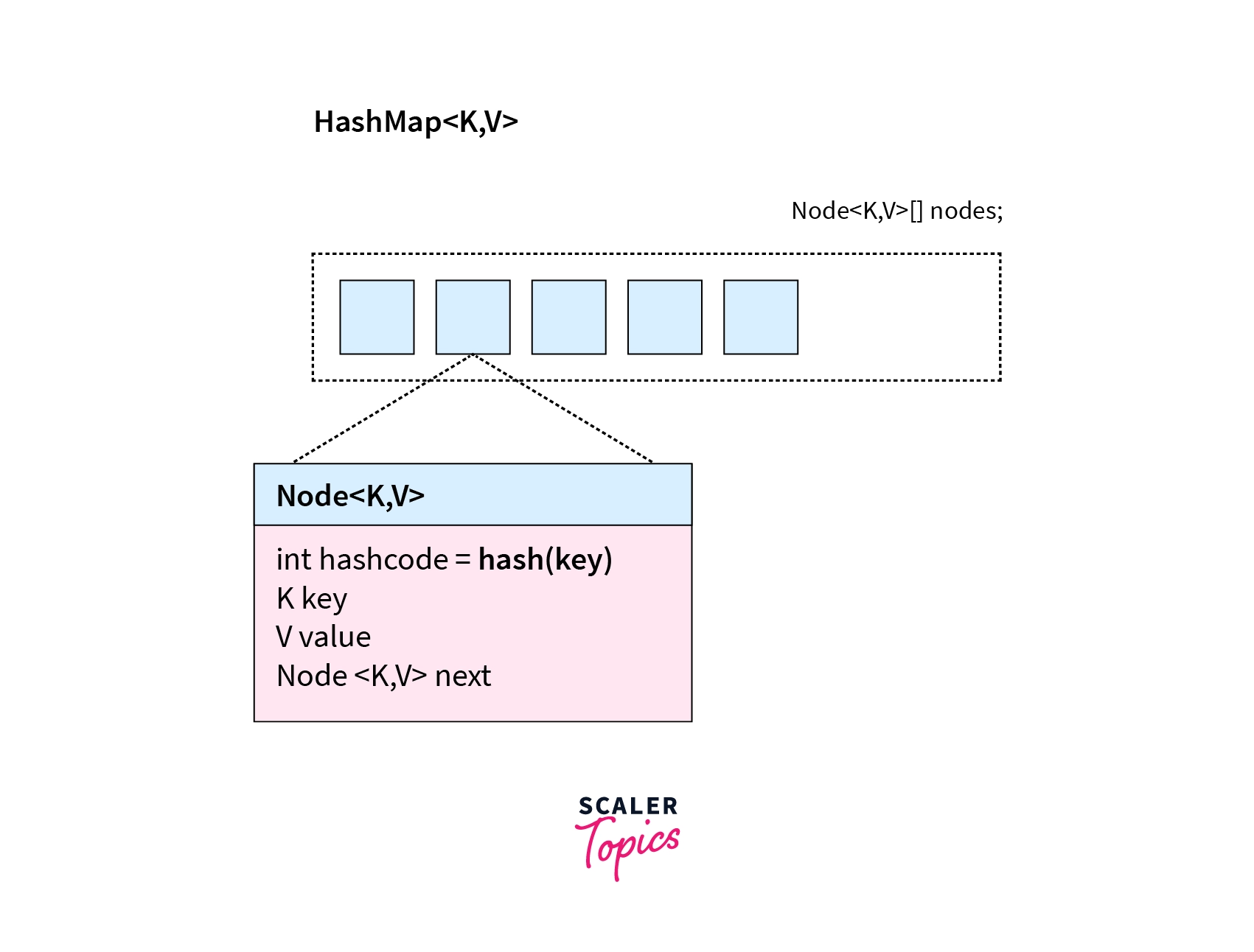
- Capacity: Capacity is the number of buckets in the HashMap. The initial capacity is the capacity at which the Map is created. The initial default capacity of the HashMap is 16`.
- Load Factor: The capacity is expanded as the number of elements in the HashMap increases. The load factor is the measure that decides when to increase the capacity of the Map. The default load factor is 75% of the capacity.
- Threshold: The threshold of a HashMap in Java is approximately the product of the current capacity and load factor.
- Rehashing: Rehashing is the process of re-calculating the hash code of already stored entries. When the number of entries in the hash table exceeds the threshold value, the Map is rehashed so that it has approximately twice the number of buckets as before.
- Collision: A collision occurs when a hash function returns the same bucket location for two different keys.
Let's suppose a HashMap is created with the initial default capacity of 16 and the default load factor of 0.75. So, the threshold is 16 * 0.75 = 12, which means that it will increase the capacity from 16 to 32 after the 12th entry (key-value pair) is added. This will be done by rehashing.
Constructor 1: HashMap()
This is the default constructor, which creates a HashMap instance with a default initial capacity of 16 and a load factor of 0.75.
- Syntax:
- Example:
Output:
In the above example, we have created two HashMaps hMap1 and hMap2, using the default HashMap() constructor and adding 3 values in each HashMap using put() method. Then we have printed both the HashMaps.
Constructor 2: HashMap(int initialCapacity)
This constructor creates an instance of HashMap with a specified initial capacity and a load factor of 0.75.
- Syntax:
- Example:
Output:
In the above example, we have created two HashMaps with different intial capacities. hMap1 with 10 and hMap2 with 5 capacity. If the threshold value is exceeded then the capacity of hMap1 and hMap2 will increase to 20 and 10, respectively (approx. twice).
Constructor 3: HashMap(int initialCapacity, float loadFactor)
This constructor creates an instance of HashMap with a specified initial capacity and specified load factor.
- Syntax:
- Example:
Output:
In the above example we have created two HashMaps with different initial capacity and load factors. hMap1 with a capacity of 10 and load factor of 0.75, whereas hMap2 with a capacity of 5 and a load factor of 0.5.
The default load factor is 0.75 but here we are giving values as required. So the threshold value for both maps would be:
For hMap1:
For hMap2:
So if the respected threshold values exceed the capacity will be increased for the particular HashMap.
Constructor 4: HashMap(Map map)
This creates a HashMap instance with the same mappings as the specified map.
- Syntax:
- Example:
Output:
In the above example, we have created a HashMap hMap1 and then hMap2 by initializing the values of hMap1 to hMap2. So the hMap1 and hMap2 will have the same values, capacity and load factor.
How to Perform Various Operations on HashMap in Java?
1. Adding Elements
We can add an element to the HashMap in Java by using the put() method. However, the insertion order will not be carried out sequentially. Internally, a separate hash is generated for every element. Based on that hash the elements are indexed for more efficiency.
Output:
2. Changing Elements
To change the element after adding, we can again use put() method by adding the element with the updated value for the key for which we want to change the value. This will replace the existing value as the elements in the map are indexed using the keys.
Output:
3. Removing Element
The remove() method is used to remove the elements from the map. We need to pass the key in the method and then the particular key-value pair will be removed if it's present in the map.
Output:
4. Traversal of HashMap
To traverse over any structure of the Collection Framework (like HashMap in Java), we can use the iterator interface. Using Java for-each loop, we can iterate through each entry of the HashMap. Iterators work with one type of data but in Map, we have two types- Key and Value. So we use Entry<K,V> to resolve this into a compatible format.
Output:
In the above example, we have used HashMap.Entry(). Entry is an inner class in whatever Map implementation we are using (here, in this case it's HashMap). HashMap.Entry is a key and its value combined into one class. This allows us to iterate over HashMap.entrySet() instead of having to iterate over HashMap.keySet(), then getting the value for each key. So, the HashMap.entrySet() method returns a collection-view (elements) of the HashMap.
Features of HashMap in Java
- HashMap in Java uses the technique of Hashing. That's why it is called HashMap. Hashing function maps a big number or string to a small integer that can be used as an index. A shorter value helps in indexing and faster searches.
- HashMap in Java is found in the java.util package.
- In HashMap, the keys should be unique but values can be duplicated. It means that an X key can't contain more than one value that is X mapped to only one value. But other Y, Z keys can contain duplicate or the same values already mapped to X key.
- HashMap in Java can also have null key and values. But there could be only one null key. However, there could be any number of null values corresponding to different keys.
- Unlike HashTable, HashMap is not synchronized. It is an unordered collection that doesn't guarantee any specific order of the elements.
- To retrieve any value from the HashMap, one should know the associated key.
- HashMap extends an abstract class AbstractMap and implements Cloneable and Serializable interfaces.
How does HashMap Work Internally?
As we have discussed, HashMap in Java stores the elements using key-value mapping where we can retrieve an element from the HashMap by its key. The key-value pairs are stored as instances of inner class HashMap. The entry which has key-value mapping stored as attributes where the key has been marked as final (immutable).
Internally, the HashMap is an array of nodes. HashMap makes use of array and LinkedList for storing key-value pairs.
Given below is a structure of a node of HashMap that is programmatically represented as a class.
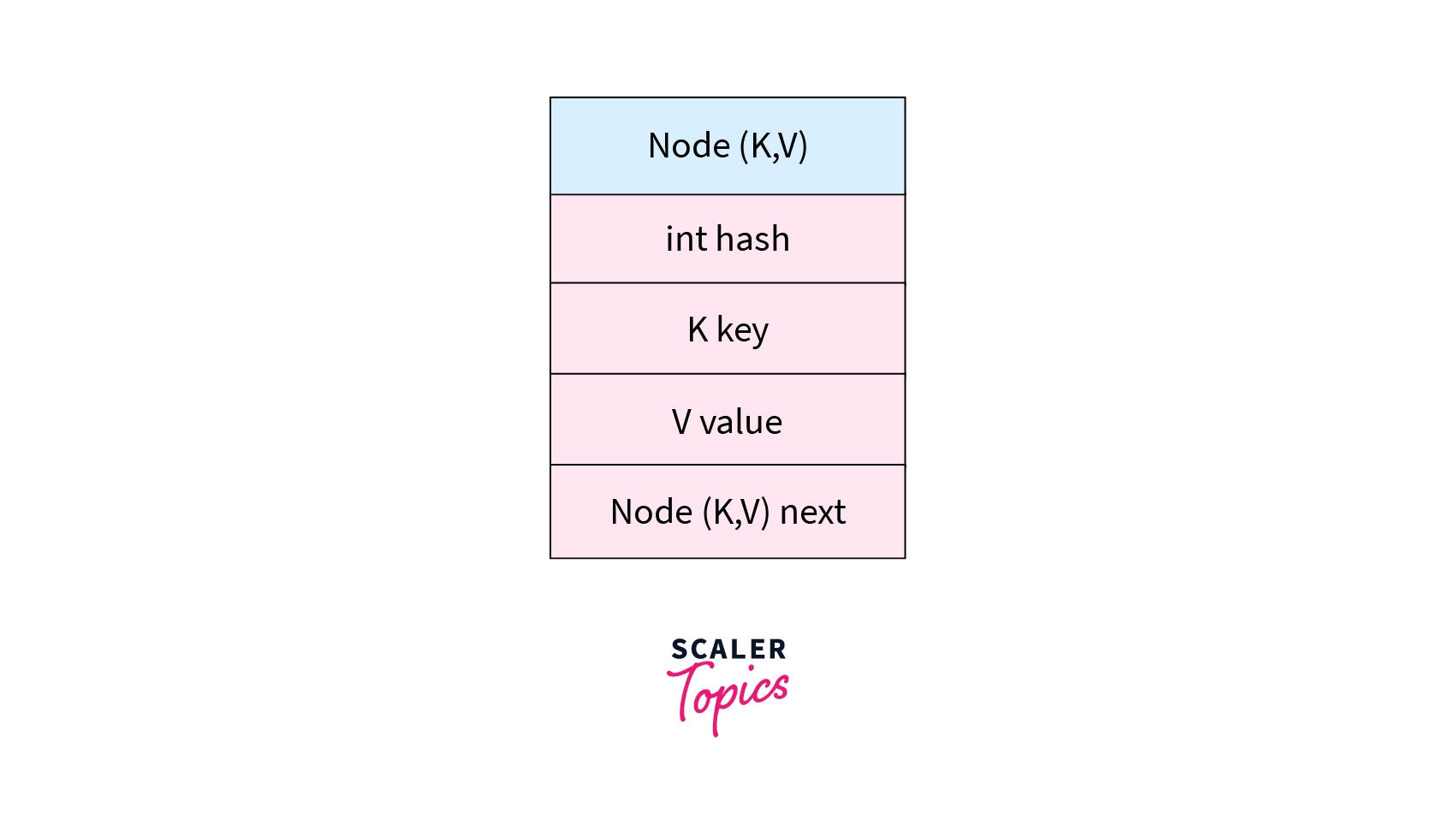
As seen from the node representation above, a node has a structure similar to a linked list node. An array of these nodes is called Bucket. HashMap stores elements in buckets and the number of buckets is called capacity.
When we add a value to the map, the bucket in which the value will be stored is determined by the key's hashCode() method. Basically, a hash value is calculated using the key’s hash code. This hash value is used to calculate the index in the array for storing Entry object.
When we try to retrieve the value, the bucket is calculated by the HashMap in the same way – using hashCode(), which actually calculates the first index location. Then in that bucket, it iterates through the objects found and uses the key's equals() method to find the exact match.
To avoid having many buckets with multiple values, the capacity is doubled if 75% (the load factor) of the buckets become non-empty. The default value for the load factor is 75%, and the default initial capacity is 16. Both can be set in the constructor as discussed above.
Performance of HashMap
The performance of a HashMap is affected by two parameters:
- Initial Capacity: The initial capacity is simply the capacity (number of buckets) during creation.
- Load Factor: The load factor or LF, is a measure of how full the hash map should be after adding some values before it is resized.
The initial default capacity is 16 and the default load factor is 0.75. We can create a HashMap with custom values as well.
However, for custom values, we should understand the performance implications. When the number of hash map entries exceeds the product of LF and capacity, then rehashing occurs i.e. another `internal array is created with twice the size of the initial one, and all entries are moved over to new bucket locations in the new array.
A low initial capacity reduces space cost but increases the frequency of rehashing. Rehashing is obviously a very expensive process. So if we have many entries, we should set a considerably high initial capacity.
But if we set the initial capacity too high, we will pay the cost in iteration time. So a high initial capacity is good for a large number of entries coupled with little to no iteration. A low initial capacity is good for a few entries with a lot of iteration.
Inserting a value into a HashMap takes, on the average case, time. The hash function is computed, the bucket is chosen, and then the item is inserted.
In the worst-case scenario, all of the elements will have hashed to the same value, which means either the entire bucket list must be traversed or, in the case of open addressing, the entire map must be probed until an empty spot is found. Therefore, in the worst case, insertion takes O(n) time.
Note: From Java 8 onward, Java has started using Self-Balancing BST instead of a linked list for chaining. The advantage of self-balancing BST is, in the worst case (when every key maps to the same slot) search time is O(Log n).
Methods in Java HashMap
Here, K is the type of the keys, and V is the type of the values in the map.
| Function Name | Syntax | Description |
|---|---|---|
| clear() | void clear() | Removes all of the mappings from this map. |
| clone() | Object clone() | Returns a shallow copy of this HashMap instance: the keys and values themselves are not cloned. |
| compute() | V compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction) | Attempts to compute a mapping for the specified key and its current mapped value (or null if there is no current mapping). |
| computeIfAbsent() | V computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction) | If the specified key is not already associated with a value (or is mapped to null), attempts to compute its value using the given mapping function and enters it into this map unless null. |
| computeIfPresent() | V computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction) | If the value for the specified key is present and non-null, attempts to compute a new mapping given the key and its current mapped value. |
| containsKey() | boolean containsKey(Object key) | Returns true if this map contains a mapping for the specified key. |
| containsValue() | boolean containsValue(Object value) | Returns true if this map maps one or more keys to the specified value. |
| entrySet() | Set entrySet() | Returns a Set view of the mappings contained in this map. |
| forEach() | void forEach(BiConsumer<? super K,? super V> action) | Performs the given action for each entry in this map until all entries have been processed or the action throws an exception. |
| get() | V get(Object key) | Returns the value to which the specified key is mapped, or null if this map contains no mapping for the key. |
| getOrDefault() | V getOrDefault(Object key, V defaultValue) | Returns the value to which the specified key is mapped, or defaultValue if this map contains no mapping for the key. |
| isEmpty() | boolean isEmpty() | Returns true if this map contains no key-value mappings. |
| keySet() | Set keySet() | Returns a Set view of the keys contained in this map. |
| merge() | V merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction) | If the specified key is not already associated with a value or is associated with null, associates it with the given non-null value. |
| put() | V put(K key, V value) | Associates the specified value with the specified key in this map. |
| putAll() | void putAll(Map<? extends K,? extends V> m) | Copies all of the mappings from the specified map to this map. |
| putIfAbsent() | V putIfAbsent(K key, V value) | If the specified key is not already associated with a value (or is mapped to null), associates it with the given value and returns null, else returns the current value. |
| remove() | V remove(Object key) | Removes the mapping for the specified key from this map if present. |
| remove() | boolean remove(Object key, Object value) | Removes the entry for the specified key only if it is currently mapped to the specified value. |
| replace() | V replace(K key, V value) | Replaces the entry for the specified key only if it is currently mapped to some value. |
| replace | boolean replace(K key, V oldValue, V newValue) | Replaces the entry for the specified key only if currently mapped to the specified value. |
| replaceAll() | void replaceAll(BiFunction<? super K,? super V,? extends V> function) | Replaces each entry's value with the result of invoking the given function on that entry until all entries have been processed or the function throws an exception. |
| size() | int size() | Returns the number of key-value mappings in this map. |
| values() | Collection | Returns a Collection view of the values contained in this map. |
Methods inherited from class java.util.AbstractMap
| Method | Description |
|---|---|
| equals() | Compares the specified object with this map for equality. |
| hashCode() | Returns the hash code value for this map. |
| toString() | Returns a string representation of this map. |
Methods inherited from interface java.util.Map
| Method | Description |
|---|---|
| equals() | Compares the specified object with this map for equality. |
| hashCode() | Returns the hash code value for this map. |
Use cases of HashMap
- We can use HashMap for the implementation of Phonebook by using key-value pair of Name - Number.
- For Dictionary Application HashMap can be used. As Dictionary will be having a lot of words so words can be used as key which are mapped to values - Meaning, Description of word.
- Wherever you are putting a list of objects in an array or list and then retrieving the value based on some attributes of an object, you can use hashmap. This is used extensively as in-memory cache for static/near static values. All your system properties, static business data - country codes, zip codes, cities, etc. - can be stored in a hashmap and retrieved.
- Even distributed caching systems like Couchbase, membase, redis are sort of hashmaps extended to handle high concurrency and large scale data through replication and distribution.
Conclusion
- HashMap in Java is an implementation of the Map interface. It is a part of the collections framework which is found in java.util package.
- HashMap stores the data in key-value mapping where every key is mapped to a value. Keys can not be duplicated but values can be duplicated.
- HashMap is unsynchronised, and it doesn't store the elements in a particular order.
- HashMap allows storing multiple null values and only one null key.
- HashMap in Java has 4 constructors, and each one has public access modifier.
- For traversal over any structure of the Collection Framework (like HashMap), we can use the iterator interface.
- Real-world application of HashMap example: In storing the records of the employees of a company where employee ID is stored as a key and employee data is stored as a value in the HashMap. It helps for faster retrieval of employee data corresponding to an employee ID.