K Fold Cross Validation in Machine Learning
Machine learning models often face the challenge of overfitting or underfitting, which hampers their generalization of new data. To tackle this issue, cross-validation techniques are employed. One such powerful method is K Fold Cross Validation, which divides the dataset into 'K' folds, ensuring a robust evaluation of model performance.
Cross-Validation in Machine Learning
Cross-validation is a pivotal technique in the field of machine learning, playing a crucial role in both the development and evaluation phases of building models. Its primary purpose is to provide a robust assessment of a model's performance by minimizing dependency on a particular subset of the data. This ensures that the model's generalization capabilities are thoroughly tested, making it more reliable when applied to new, unseen data.
The need for cross-validation arises due to the inherent risk of overfitting or underfitting when training a machine learning model on a single split of the data. Overfitting occurs when the model learns the training data too well, capturing noise and patterns that might not generalize to new data. On the other hand, underfitting happens when the model is too simplistic to capture the underlying patterns in the data.
Cross-validation helps address these issues by providing a more comprehensive evaluation of the model's performance across different subsets of the dataset.
K Fold Cross Validation in Machine Learning
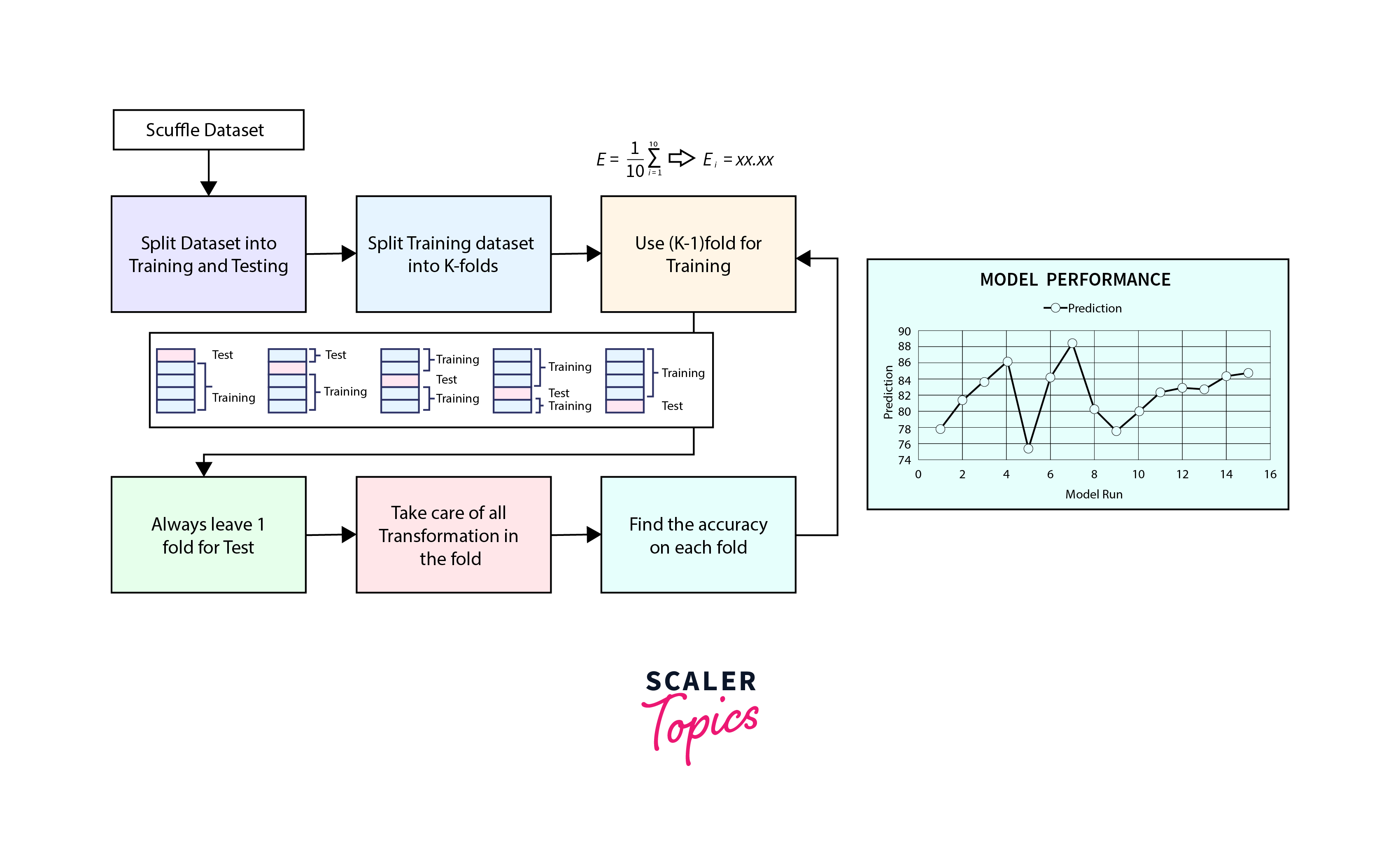
K Fold Cross Validation is a sophisticated extension of traditional cross-validation techniques, designed to provide a more robust evaluation of machine learning models. It addresses the limitations of simple train-test splits by systematically partitioning the dataset into 'K' subsets or folds. The model is then trained and tested multiple times, each time using a different fold as the testing set. This iterative process of training and testing the model yields a more comprehensive understanding of the model's performance, contributing to enhanced reliability and generalization.
Benefits of K Fold Cross Validation
-
Reduced Variance: By averaging the performance over multiple folds, K Fold Cross Validation reduces the impact of variability in the evaluation metrics. This is particularly beneficial when the dataset is limited.
-
More Robust Performance Estimate: The use of multiple folds ensures that the model's performance is assessed across different subsets of the data, leading to a more robust estimate of how well the model generalizes.
-
Optimal Resource Utilization: K Fold Cross Validation allows for the maximum utilization of available data for both training and testing. Each data point contributes to the evaluation process, enhancing the model's understanding of the underlying patterns.
-
Model Sensitivity Analysis: The iterative nature of K Fold Cross Validation allows practitioners to observe how sensitive the model is to different subsets of the data. This sensitivity analysis aids in identifying potential weaknesses and strengths of the model.
Lifecycle of K Fold Cross Validation
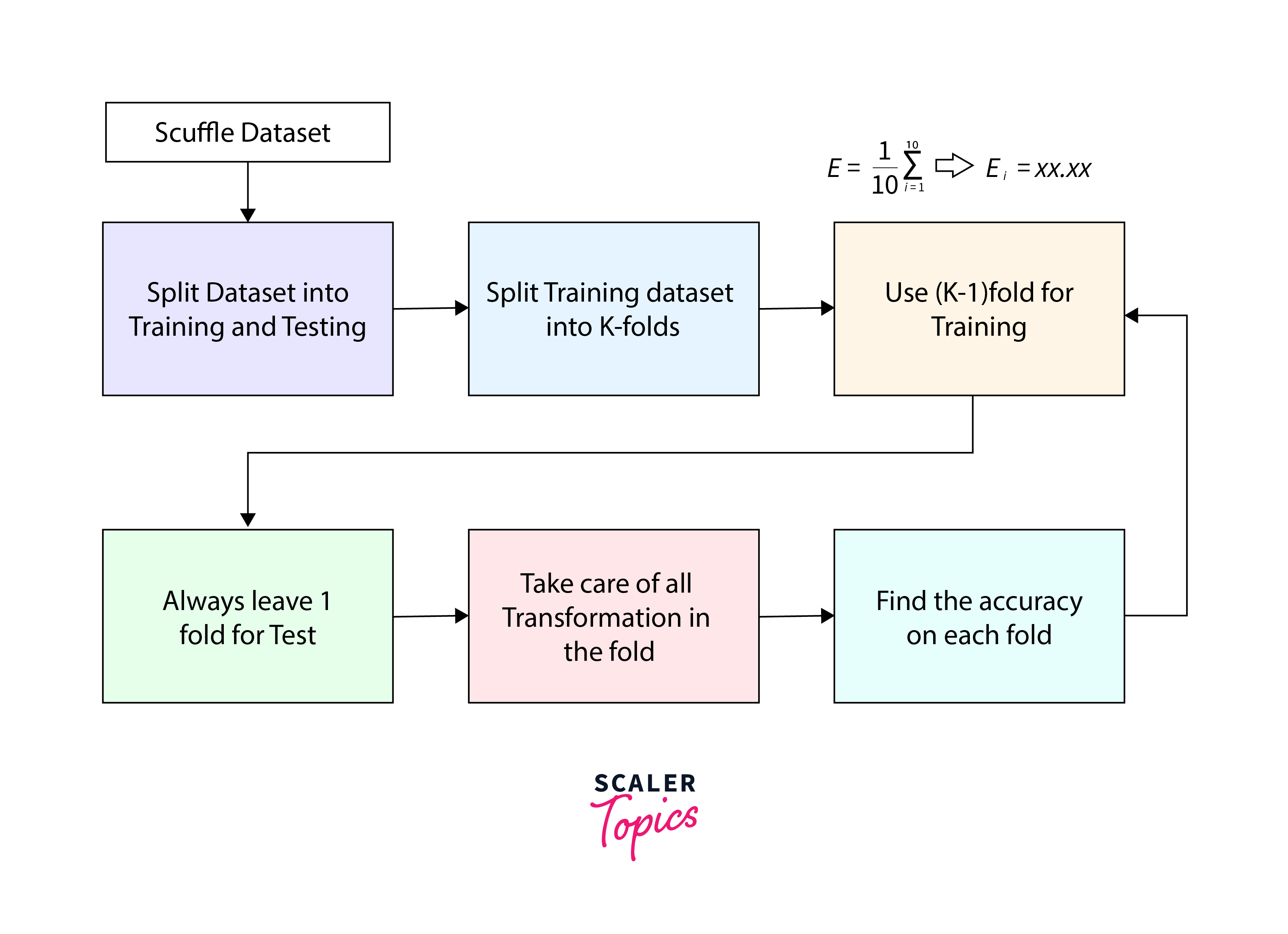
K Fold Cross Validation follows a systematic lifecycle to ensure a robust evaluation of machine learning models. The process involves multiple steps, from initial data splitting to the creation of a final model. Let's delve into each stage of the lifecycle:
-
Data Splitting: The first step in K Fold Cross Validation is to divide the dataset into 'K' non-overlapping folds. Each fold ideally contains a representative distribution of the data, maintaining the balance of classes or target variables. This step is crucial for ensuring that the model is exposed to diverse subsets of the data during the training and testing phases.
-
Model Training and Testing: In the subsequent stages, the model undergoes 'K' iterations. In each iteration, 'K-1' folds are used for training, and the remaining fold is reserved for testing. This means that during each iteration, the model learns from a majority of the data and is then evaluated on a different subset, ensuring that each fold serves as the testing set exactly once.
-
Performance Metrics: Following the training and testing of the model in each iteration, performance metrics are recorded. These metrics could include accuracy, precision, recall, F1 score, or any other relevant evaluation metric depending on the nature of the machine learning task (classification, regression, etc.). Recording these metrics for each iteration provides insights into how well the model performs across different subsets of the data.
-
Average Performance: To obtain a more stable and reliable estimate of the model's performance, the recorded metrics from all 'K' iterations are averaged. This average performance metric serves as a consolidated measure, smoothing out potential fluctuations that may arise from a single train-test split. Averaging helps mitigate the impact of outliers and randomness, providing a more representative evaluation of the model's capabilities.
-
Final Model: Once the K Fold Cross Validation process is complete, and the average performance is calculated, the final model is trained on the entire dataset. This final training step utilizes the optimal parameters identified during the cross-validation process. By training the model on the entire dataset, it ensures that the model can leverage the maximum amount of information available for making predictions on new, unseen data.
K Fold Thumb Rules
-
Choose an Appropriate K Value:
- Selecting an appropriate 'K' value, such as 5 or 10, is vital in K Fold Cross Validation. The choice depends on factors like dataset size and characteristics. Smaller 'K' values may suffice for larger datasets, while larger values can enhance evaluation on smaller datasets.
-
Randomize Data:
- Before employing K Fold Cross Validation, it is crucial to shuffle the dataset. Randomizing the data helps prevent bias and ensures a more representative distribution across folds. This step is particularly important when dealing with ordered or time-sensitive datasets.
-
Consistent Evaluation:
- Maintain reproducibility by using the same random seed for consistent evaluation in K Fold cross-validation. This ensures that the data-splitting process remains uniform across different runs, allowing for reliable comparisons between models or experimental conditions.
Examples
Consider a binary classification problem with a dataset of 1000 samples. Applying 5-fold cross-validation involves dividing the data into 5 subsets, training the model on 4 subsets, and testing the remaining subset in each iteration. The process yields 5 sets of evaluation metrics, helping assess the model's consistency.
Let us see an example of coping below.
Model Selection in K Fold
Let's see the model selection in K fold with an example:
Let's try K-fold on different algorithms.
Logistic Regression
We will employing the liblinear solver for Logistic Regression, specifically falling under the category of "Large Linear Classification." This solver utilizes a Coordinate-Descent Algorithm, which systematically minimizes a multivariate function by addressing the optimization problems of individual variables in a loop.
Output:
SVM
The gamma parameter is adjusted to fit the training dataset, and its value is determined by using the reciprocal of the number of features (1/n_features). In this context, it is set to auto.
Output:
Random Forest Classifier
Assigning the estimators as 40 for now.
Output:
We can see that currently Logistic regression and Random forest models are performing better than SVM.
We will employ the cross_val_score function to obtain performance scores by applying various algorithms to a dataset and using cross-validation.
For logistic regression, cv=3:
Output:
For SVM, cv=3:
Output:
For Random Forest, cv=3:
Output:
Average results of Random forest is best hence we will select this model.
Parameter Tuning in K Fold
Parameter tuning is the process of finding the best combination of hyperparameters for a machine learning algorithm to achieve optimal performance on a given dataset. Hyperparameters are settings that are not learned from the data but rather set before the learning process begins. They can significantly impact the performance of the model.
Let us take an example to understand this. We will use Random forest on the same data and start with n_estimators as 10. In the context of the Random Forest algorithm, one of the hyperparameters is n_estimators, which determines the number of decision trees in the forest. Each tree in the forest contributes to the final decision by a voting mechanism or averaging the predictions.
Output
Estimators = 20
Output
Estimators = 30
Output
Estimators = 40
Output
Comparing all the scores:
We can see that the best results are seen when n_estimators are 30.
K Fold In Visual Form
Visualizing data is crucial for understanding patterns and making informed decisions.
Output
Let's see the variation by differing the values of k from 1-25 and plotting it for a KNN model.
Output:

FAQs
Q. Why is K Fold Cross Validation preferred over simple train-test splitting?
A. K Fold Cross Validation provides a more robust estimate of model performance by evaluating it on multiple subsets of the data, reducing dependency on a specific split.
Q. What is the impact of choosing a higher 'K' value?
A. Higher 'K' values lead to smaller validation sets, potentially increasing variance. It can be computationally expensive but is beneficial for smaller datasets.
Q. Can K Fold Cross Validation be applied to any machine learning algorithm?
A. Yes, K Fold Cross Validation is a general technique and can be applied to various machine learning algorithms for performance evaluation.
Q. How does K Fold Cross Validation handle imbalanced datasets?
A. It ensures that each fold maintains the original class distribution, minimizing the risk of biased evaluation on imbalanced datasets.
Conclusion
- K Fold Cross Validation is fundamental in developing and evaluating machine learning models, providing a systematic and reliable approach to performance assessment.
- The technique's strength lies in its systematic dataset partitioning, ensuring comprehensive model evaluation by iterating through various subsets.
- K Fold Cross Validation proves versatile in tasks such as model selection and hyperparameter tuning, enhancing the overall efficacy of the model development process.