Kafka Architecture
Overview
Kafka's components enable it to achieve a distributed architecture, implement partitioning, and ensure replication. Due to Kafka's high throughput and scalability, it is used widely. Companies ranging from start-ups to large companies use Kafka for data streaming. In this article, we will discuss the architecture of Apache Kafka Architecture in detail.
Introduction to Apache Kafka Architecture
Apache Kafka is an open-source distributed real-time streaming platform. Kafka was made by Linkedin and later on, it became open-source. Kafka was the main project of Apache. Apache then released different versions of Kafka.
Kafka is known for the following:
- High throughput
- Scalability
- Fault tolerance
Most Fortune 500 companies use Kafka for real-time streaming. Some examples of companies using Kafka are Uber, Linkedin, Airbnb, etc.
The Apache Kafka Architecture consists of the following components:
- Kafka Producer
- Kafka Consumer
- Kafka Brokers
- Apache Zookeeper
- Kafka Topics
- Clusters
- Partitions
- Kafka Connect
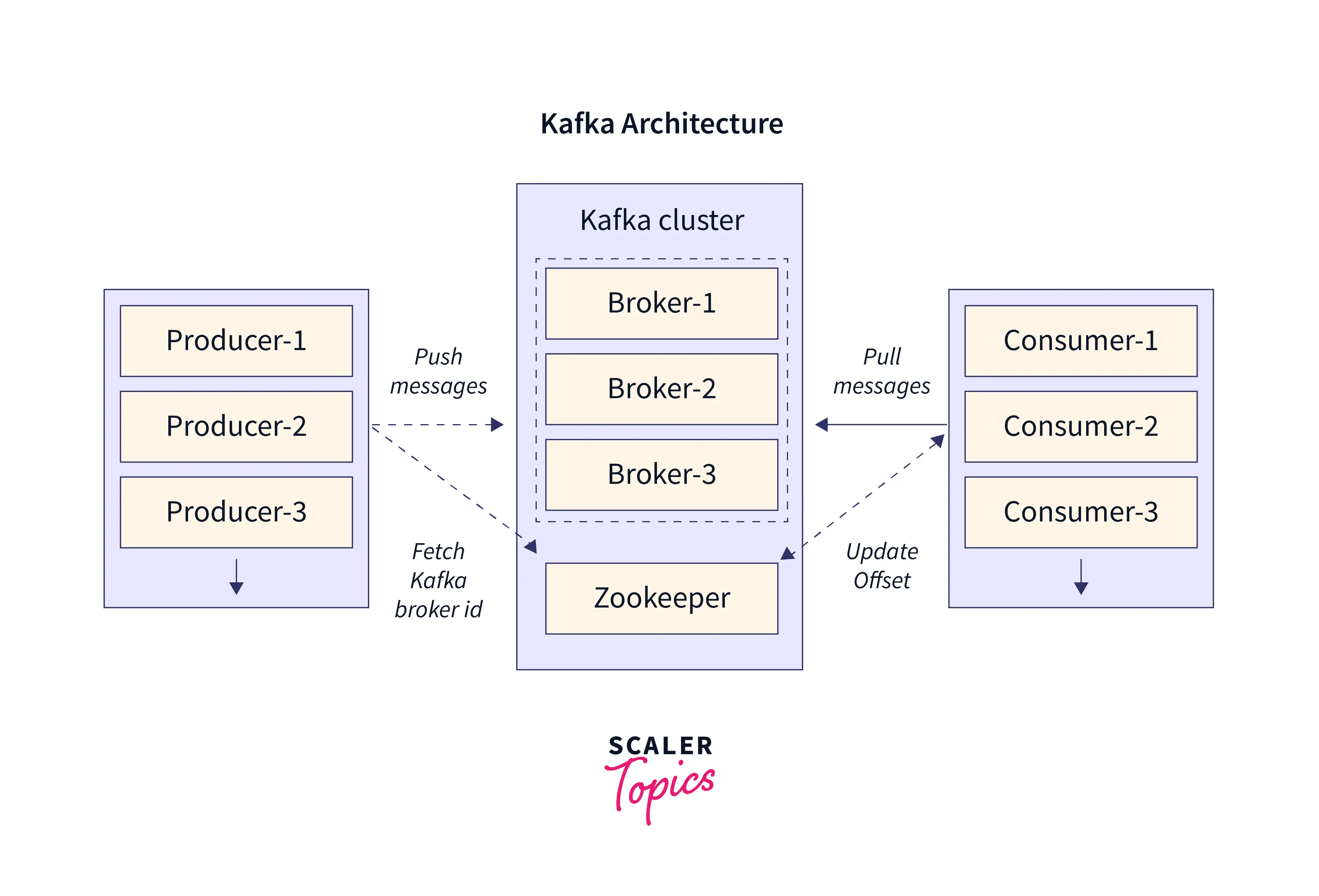
Parts Required to Design Apache Kafka Architecture
The Apache Kafka architecture consists of 4 Apis. Let us discuss each of them:
- Producer APIs:
It allows an application to write messages to Kafka topics. It also allows the application to write in various languages such as Java, Scala, Python, etc. Thus this provides flexibility to developers to write data in Kafka using the APIs. - Consumer APIs:
It allows an application to read messages from Kafka topics. It provides flexibility to developers and allows a developer to consumer messages from Kafka using applications/programs written in Java, Scala, Python and various other languages. - Connector APIs:
It allows third-party applications to connect to Kafka topics. The Connector API provides two types of connectors, SourceConnector and SinkConnector. Source Connector is used for data polling and the sink connector is used for data writing. - Streams APIs:
It allows an application to stream Kafka data.
Let us discuss the components which Apache Kafka architecture is made up of and the parts required to design Apache Kafka architecture.
- Kafka Producer:
Producer writes data to Kafka topics. Apache Kafka guarantees the delivery of messages. - Kafka Consumer:
The consumer consumes data from Kafka topics. - Brokers:
Brokers maintain the metadata of clusters and are responsible for the replication of data among partitions. Replication of data is done by copying data across multiple brokers. Replication of data is done so that the data is not lost when a broker fails. Brokers help us to achieve scalability. By adding more brokers to our Kafka cluster, we can handle more data. - Zookeeper:
Zookeeper manages Brokers and stores information about the Kafka cluster. Whenever there is an addition of a new broker or failure of a broker, the zookeeper notifies both the producer and consumer. - Kafka topics:
Producers produce data from Kafka topics and Consumers consume data from Kafka topics. A Kafka topic is a collection of partitions. - Kafka Clusters
: A cluster is made up of multiple brokers. also handles the distribution of load among brokers and partitions.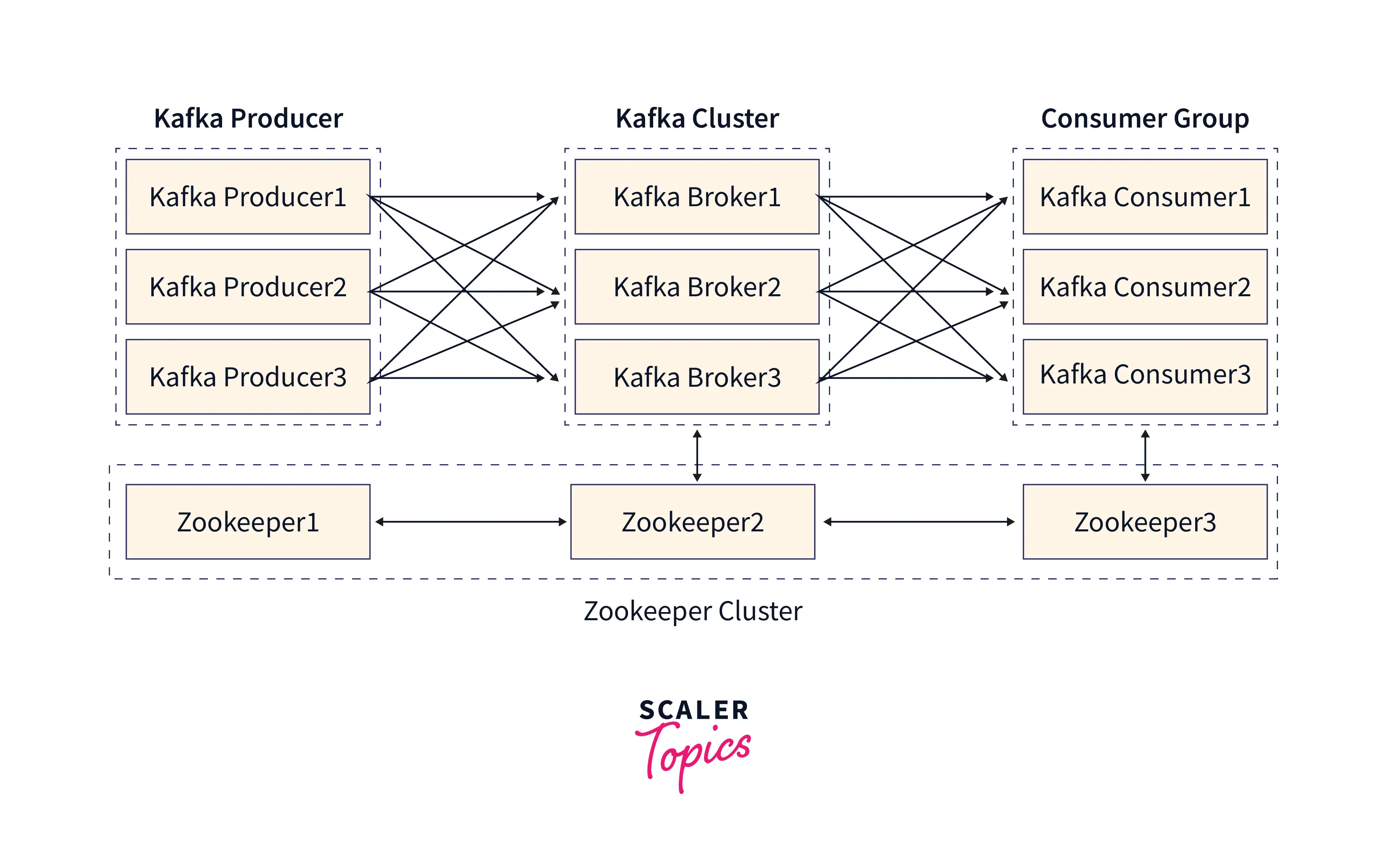
- Partitions:
The records are stored in partitions in an ordered fashion. Partitions help Kafka to achieve high throughput as it helps in the distribution of data. Data is written to multiple partitions and the data is distributed across multiple brokers to achieve high throughput. Due to this, we can stream around 30 thousand messages per second.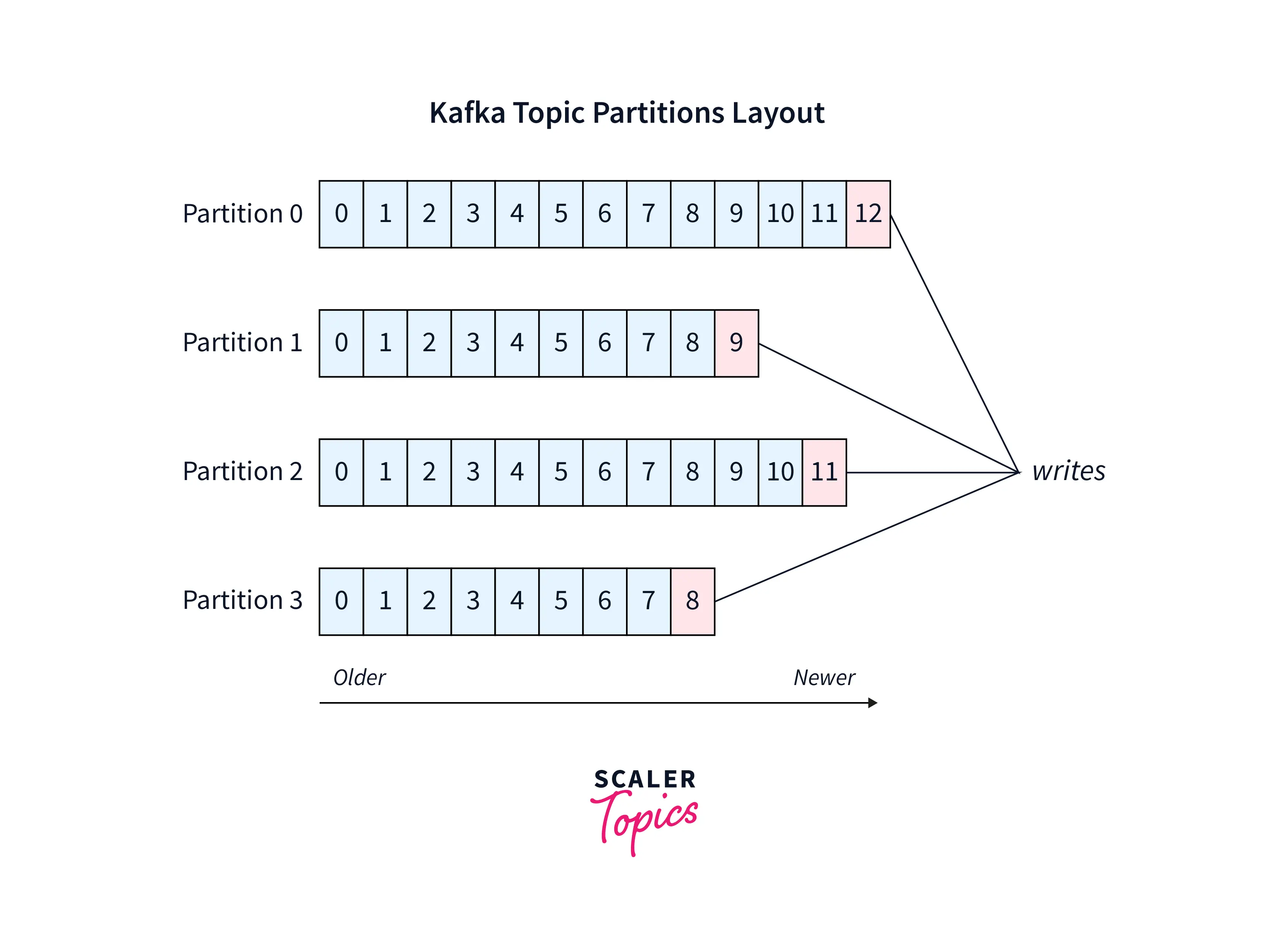 As seen in the above image, we can see different partitions where writing is being done. Also, each record is stored along with its offset. The offset helps us to continue messaging from where we left off. This helps prevention of data during the failure of partition.
As seen in the above image, we can see different partitions where writing is being done. Also, each record is stored along with its offset. The offset helps us to continue messaging from where we left off. This helps prevention of data during the failure of partition. - Kafka Connect:
Kafka Connect helps Kafka to connect with third-party applications such as message queues, databases, etc with high scalability and fault tolerance. It is an open-source system.
The Kafka Connect is made up of the following components:
- Connectors:
Connectors help external applications to read and write data to Kafka. A wide range of third-party applications can connect to Kafka. - Workers: Workers provide high scalability and fault tolerance to the connected applications.
The benefits of using Kafka Connect are:
- Scalability:
Kafka Connect can be scaled horizontally and thus provides scalability. Horizontal scaling can be done by adding more machines to the Kafka cluster. Both the scaling helps us improve the performance of Kafka. - Fault tolerance:
Kafka Connect takes care of failure and recovery. It replicates data into multiple brokers. If any of the brokers fail, we can fetch information from another broker. Thus it prevents any loss of data. - Wide integrations:
Kafka Connect allows a wide range of applications to connect with Kafka. - Throughput:
Kafka can achieve a throughput of around 30k messages/second.
Conclusion
- Apache Kafka is an open-source data streaming platform. It has a large open-source community supporting it. Apache Kafka is free to use.
- The components that make up Kafka Architecture are Consumers, Producers, Brokers, Topics, Partitions, Zookeeper etc.
- The components of Apache Kafka play a key role in achieving scalability, fault tolerance, high throughput, durability, etc.
- Kafka's APIs allow developers to read, write and connect to Kafka easily. It allows integration with a wide range of third-party applications.
- Due to robust architecture, scalability, and high throughput, Kafka is widely used by companies including Fortune 500 companies. Various industries such as e-commerce, finance industries, and software industries use Kafka for real-time processing.