Integrating Kafka with databases and message queues
Overview
Kafka as a Queue can be considered as the process of creating the application and subscribing to the data records from Apache Kafka. Once done, you can now write a subscriber, point it to the topic or more than the topic also (as per your requirements), and eventually start subscribing to the data records. The working of Kafka as a queue is possible, when every subscriber instance in the group processes the data records from non-overlapping partitions which let the Consumer Groups ensure that Kafka acts as Queue for each Kafka topic.
What are Apache Kafka Queues?
Let us quickly understand Apache Kafka as a Queue. The messages in the Kafka are saved and stored in the queue format making Apache Kafka act as a Queueing system. This way the messages can be ingested by more than one consumer at the same time. But it is to be noted that only one consumer is allowed to subscribe to each message at a particular time. Once the message is read by the consumer, it is removed from the Apache Kafka Queue.
We know that the above method of the messages getting evaporated once consumed is the opposite characteristic as seen in the publish-subscribe model. In this model, the data records are retained in the topic as defined by the retention period. Hence, the subscribers can consume more than one topic while consuming all the messages that are present in the defined topic. With the help of the application logic, implementing the publish-subscribe model for converting the topic into a message queue can be done easily. And once the message is read by the consumer groups, it gets deleted as per the application logic from the topic.
The advantage of having the Apache Kafka Queue is that it helps with the segregation of work so that every consumer is receiving a distinct set of data for processing. This way, there is no overlap seen, offering the tasks to be horizontally scalable and distributed. When a new consumer is added to a queue, Kafka shall then switch to the sharing mode where it starts splitting the data between the two consumers. When the number of consumers is similar to the number of partitions defined in a Kafka topic, this sharing will stop.
Also, when the number of subscribers exceeds the pre-specified number of partitions, a new subscriber shall not receive any new or additional messages. Scenarios like this arise as a result of the specific need where every consumer is having at least one partition, and new subscribers must wait until the partitions are free or when no new partition is available.
For scenarios with imperative programming, Kafka queueing is suited as data records are similar for the subscriber in the same domain. While, event-driven programming, the scenarios are slightly different. Here, the single event results in various actions from the subscriber's end, which also differs from domain to domain. Hence, as already studied, the limitation holds for non-multi-consumers as once the data is read by the consumer, it evaporates.
Creating Apache Kafka Queue
Let us deep dive into understanding how we can create Kafka as a queue. To do so, one must have the following two crucial elements:
- Queue topic
- Markers topic
When we say, the Queue topic for creating the Kafka Queue, it means that only the messages that must be processed are contained. On the other hand, the Markers topic is implemented for creating the Kafka Queue, including start and finish markers specie for each data record. With the help of the markers, the message could be easily traced back if any message has to be redelivered.
In the step-by-step process for creating Kafka as a queue, users need to create a standard subscriber which can then start reading the data records from the recently committed offset:
- To process start by reading the data record from the queue topic.
- Then once the start marker is sent with the data record offset to the marker’s topic, you should wait until Apache Kafka acknowledges the transmission.
- Now, you can easily commit the offset for the data record that has been read from the queue to Apache Kafka.
- Once the marker is sent, these messages could be processed and eventually you can also commit the offset.
- When the processing completes, the end marker can now be sent to the markers topic. This is the same message which contains the data record offset once more. You don't need to wait for any sent acknowledgment.
- The Redelivery Tracker components can also be started, which will consume the markers topic and when seen will also redeliver the data records.
- To define the Redelivery Tracker as per Apache Kafka is the application where the data records are read directly from the markers queue. Along with, keeping a list of data records that have not been processed.
Kafka as a Queue
Let us explore more on Kafka as a Queue. To start with, for creating any application, that subscribes the data records from Apache Kafka. Once done, you can now write a subscriber, point it to the topic or more than the topic also ( as per your requirements), and eventually start subscribing to the data records.
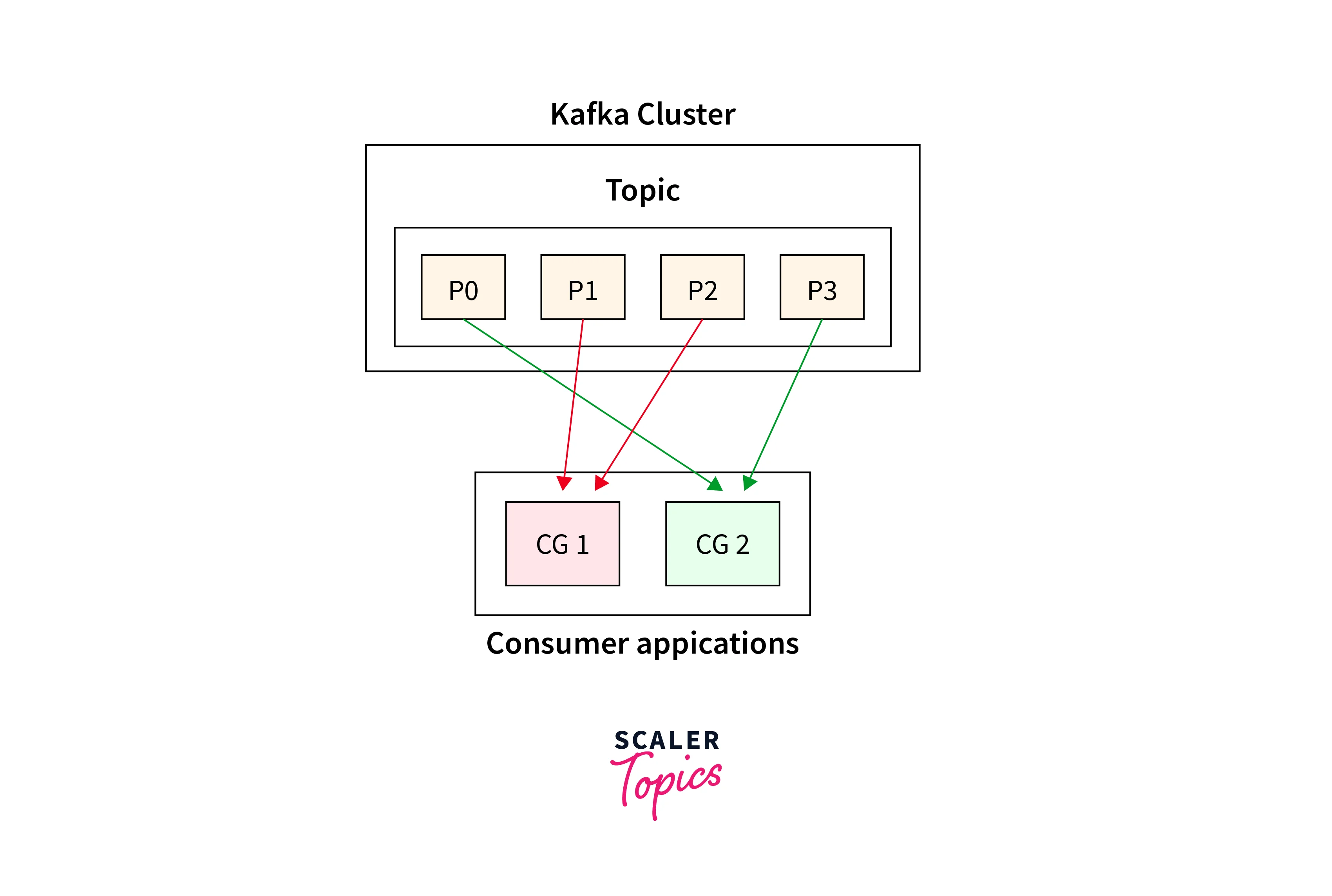
Users can start building and group the various consumers into what is known as the Consumer Group. When you see that the one subscriber is not good enough to keep up with the production rate, you can then easily start more instances of your subscriber and horizontally scale out. This helps to distribute the workload among them and it is these instances that could be grouped as the Consumer Group.
A Kafka topic is usually divided into the Kafak partitions offering fault-tolerance and scalability. The working of Kafka as a queue is possible, when every subscriber instance in the group processes the data records from non-overlapping partitions which let the Consumer Groups ensure that Kafka acts as Queue for each Kafka topic.
Below is the representation of how two Consumer Groups 1 and 2 are consuming from a single Kafka topic having four partitions (that is, P0 to P4).
How to Integrate Your Databases with Apache Kafka and CDC
Let us highlight and understand how we can Integrate Your Databases with Apache Kafka and CDC.
Kafka Connect
We know that to transfer the data from the data source to Kafka to the data sink we have various components from Kafka that help us support this process. To name such, the Kafka Connect API is defined as the core component offered by Apache Kafka with its 0.9 version. This not only offers scalability as well as resilient integration between Apache Kafka and other applications.
Below is the representation of how where the Kafka connect is integrated in the entire data processing:
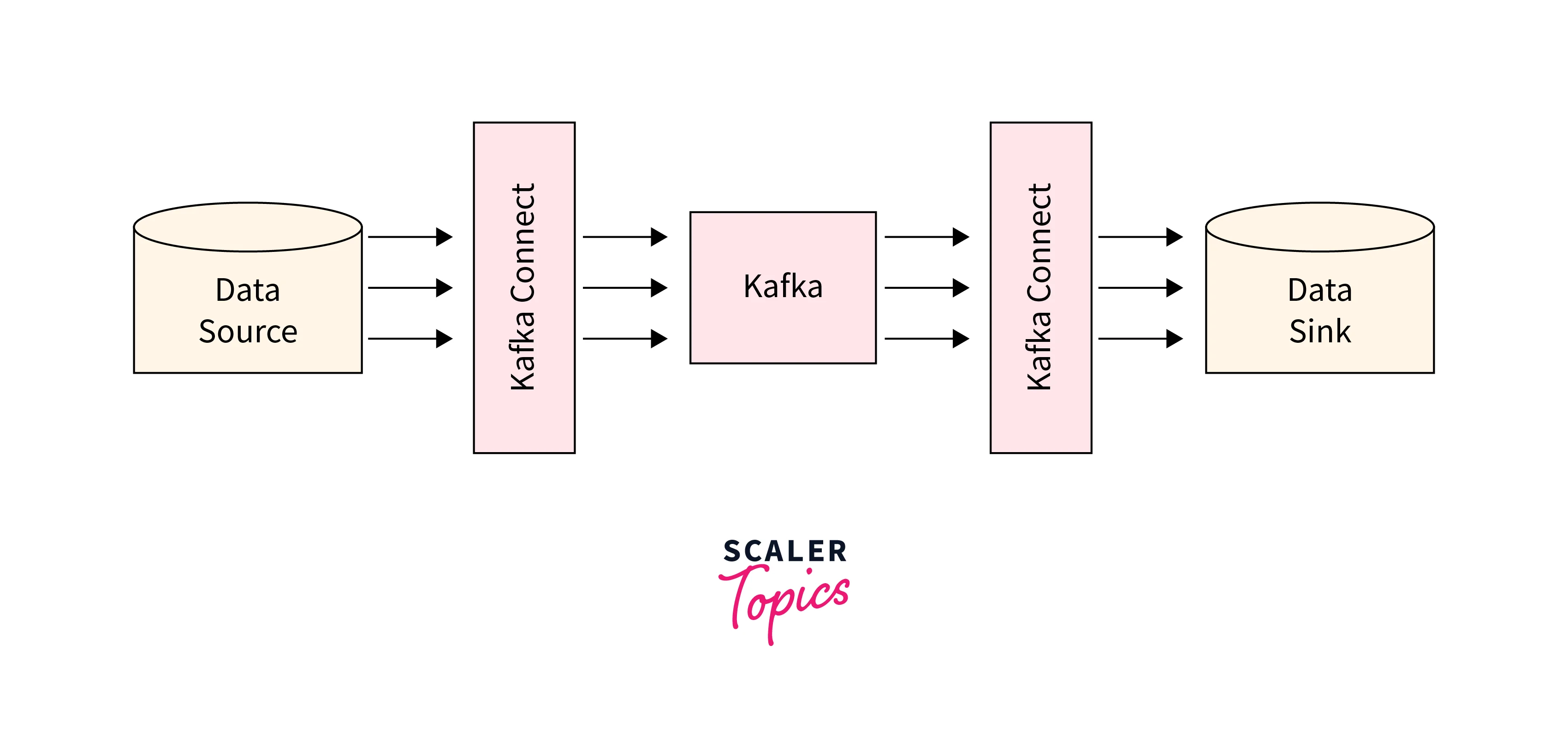
The following are configuration files that you could implement for providing a simple integration point for the developers.
Various scenarios where the use of Kafka Connect could be an advantage throughout the entire clustered process across various nodes are discussed below:
- Offer greater throughput for scaleout of ingest and egress across the various nodes.
- In the event of failure of nodes, Kafka connects to automatic restart as well as failover of tasks.
- Offset management is automatic.
- Preservation of data schema at the source gets automated.
- For the creation of data objects to utilize the data’s schema.
- Compatibility support and schema evolution
- Serialisation and deserialization of data get automated.
- Single Message Transformations
- Exactly once processing semantics
Log-based Change-Data-Capture (CDC) Tools and Kafka
If you looking for integrating the databases and message queues you can opt-in for the Log-based Change-Data-Capture (CDC) tools and Kafka. CDC offers the user to seamlessly stream each event or data record from the database into the Apache Kafka queue. Traditionally, relational databases implemented the transaction log-based model for writing each event in the database. Be it inserting, updating, or even deleting a row, all of it happened via the transaction log.
While with CDC, the transaction logs are utilized for extracting the events that are hapening inthe database at low latency and low impact. We do have various CDC tools already existing and offering a broad range of sources to serve from. The defining characteristic offered by CDC is the schema preservation via the Schema Registry. The data could be streamed from a database into Kafka seamlessly.
CDC widely popular as Change data capture offers low latency, and low impact, as well as offering full data fidelity. But still, certain limitations might not be the best-fit use case for your requirements. let us see a few scenarios where CD won't offer that many benefits:
- CDC tools are much more complex than any other DBC connector.
- Although the complexity of the CDC might support your requirements, it's good to be aware of adding more moving parts to the overall solution.
- CD might be a skill for robust prototyping while DBC connector is the go-to option.
- The nature of integration with low-level log files adds to the complexity offered by CDC.
- Requires a considerable amount of administration access for initial setup with the database.
- The costing offered by CDC is meant for commercial offerings.
Example Project: Real-time Database Replication Using Kafka
With this section, we shall brief you on how to create your real-time database replication via implementing Apache Kafka. Though it is not as tough as it sounds, let us see the process starting from the database replication setup. We shall be setting it up from one SQL database server acting as the source to various destination SQL database servers as the sink via implementing the Apache Kafka and the Kafka Connect framework.
It would help if you kept in mind that while implementing the database replication using Kafka, users are assumed to have the following:
- Proper understanding of fundamental concepts around Kafka and Kafka Connect.
- Strong grasp of the SQL Server Change Data Capture methodology.
Similar implementation could be done if you are approaching a use case where there is a need for replicating the tables from one database to various other databases while keeping the replication in real time.
The architecture must be well-designed so that it can effectively handle the following:
Replication for many updates to the specific in the source database. Seamlessly scale to effectively handle the sink or target databases as per traffic in the future. To implement such a design, Apache Kafka, along with Kafka Connect, works excellently. Users can easily enable the CDC (widely popular as change data capture) over the source tables/SQL database where the replication must happen.
Set connectors like debezium to enable the reading of the CDC updates coming from the SQL server. Eventually, push these updates to the Kafka topics. Also, remember to set the DBC sink connector from the Kafka topics to pull data and push the data ( the updates ) into the target databases.