What is a Kafka Broker?
What is a Kafka Broker?
The Kafka broker can be defined as one of the core components of the Kafka architecture. It is also widely known as the Kafka server and a Kafka node.
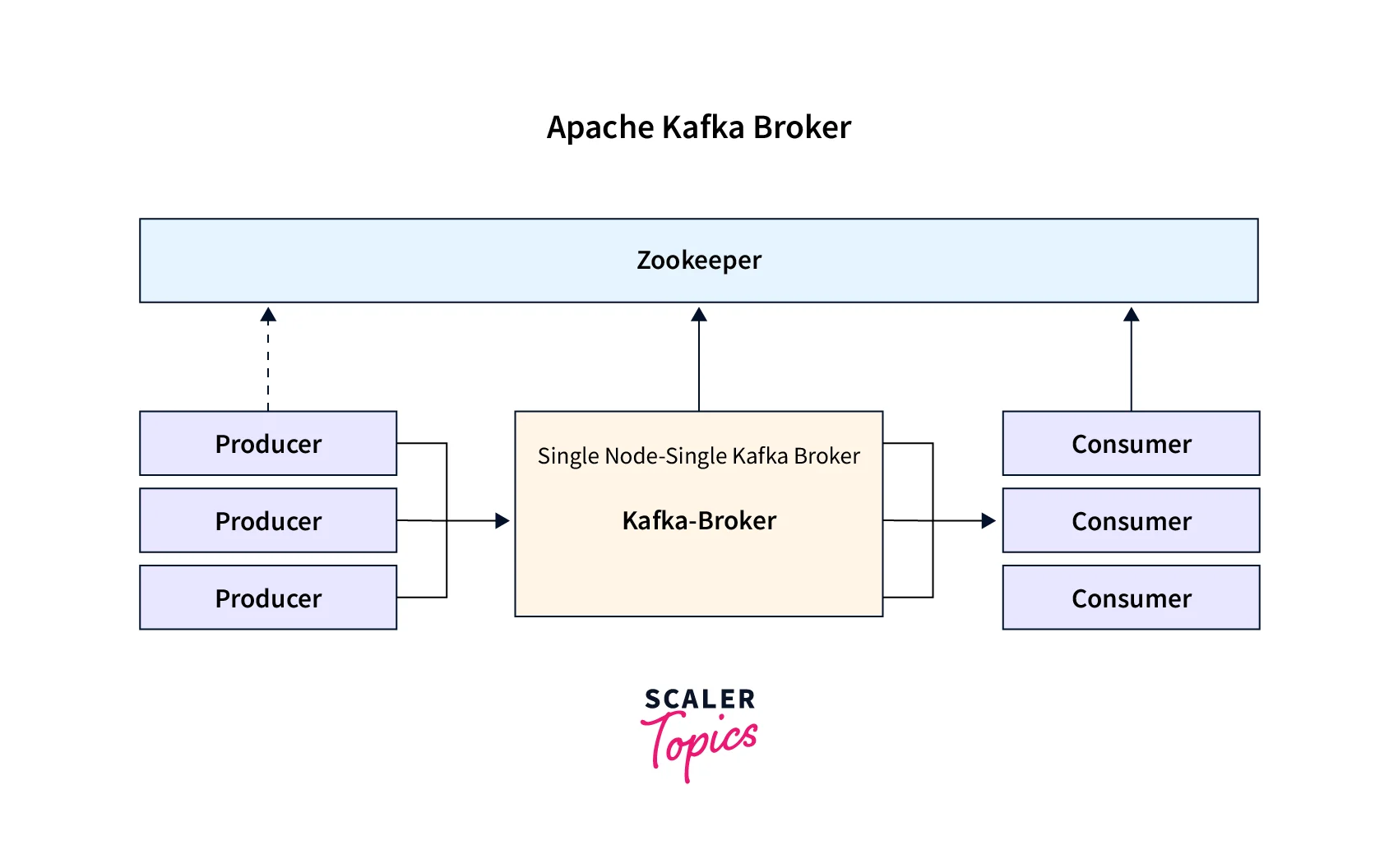 As seen in the illustration above, the Kafka broker is used for managing the storage of the data records/messages in the topic. It can be simply understood as the mediator between the two. We define a Kafka cluster when there is more than one broker present. The Kafka broker is responsible for transferring the conversation that the publisher is pushing in the Kafka log commit and the subscriber shall be consuming these messages. The conversation is mediated between the multiple systems, enabling the delivery of the data records/ message to process to the right consumer.
As seen in the illustration above, the Kafka broker is used for managing the storage of the data records/messages in the topic. It can be simply understood as the mediator between the two. We define a Kafka cluster when there is more than one broker present. The Kafka broker is responsible for transferring the conversation that the publisher is pushing in the Kafka log commit and the subscriber shall be consuming these messages. The conversation is mediated between the multiple systems, enabling the delivery of the data records/ message to process to the right consumer.
While the Kafka cluster consists of various brokers. Kafka cluster implements the Zookeeper for maintaining the state of the cluster. It has also been seen that an individual broker can handle thousands of requests for reads and writes per second. When no performance impact is seen then every broker in the Kafka cluster can handle terabytes of messages. ZooKeeper also performs the broker leader election.
Kafka Broker is structured as a KafkaServer, that is hosting various topics. The stated topics must be partitioned across the various brokers spread in a Kafka cluster. The single broker is hosting the topic partitions for more than one topic, while a topic is partitioned for a single partition. Also, the Kafka producers push a message to a broker. Then the broker receives the data record and stores it. This stored data remains over the disk defined by a distinct offset. However, the partition, topic, and offset of a broker allow consumers to fetch messages.
Hence, the brokers could create the Kafka cluster by exchanging information with each other either directly or indirectly via the Zookeeper. It is one broker among all the brokers in a Kafka cluster that acts as the controller.
How to Start Kafka Broker?
It is with the Kafka-server-start.sh script, which can help the users to kick start the Kafka broker.
Steps:
- Start the Zookeeper via the below command:
- Once the Zookeeper is up and running, users are ready to start a Kafka server via the below command:
- The kafka-server-start.sh starts the Kafka broker.
It is recommended that the Zookeeper is checked and validated as up and running before triggering the kafka-server-start.sh script. Utilize the zookeeper-server-start shell script.
The kafka-server-start.sh implements the config/log4j.properties for logging the configuration that could be overridden via the KAFKA_LOG4J_OPTS environment variable.
Kafka Command-line Options
Some of the Kafka Command-line Options are mentioned below:
| Command-line Options | Descriptions |
|---|---|
| –override property=value | Represents the value that must be overridden for the value set of the property in the server properties file. |
| -daemon | Enables the daemon mode. |
| -logic | Automatically enabled when Kafka is in daemon mode. |
| -name | Used as defaults for representing the kafkaServer when it is in the daemon mode. |
What is Kafka Cluster?
As we already studied the Kafka broker acts as a mediator between the systems to smoothly transfer the message from the source to the destination.
When there is a band containing more than one broker working together that is termed the Kafka Cluster. The number of brokers in a Kafka Cluster contain can range from one to three or can even potentially contain hundreds of brokers. Organizations dealing with streaming data such as Netflix, Hotstar+, Ola, and Uber contain thousands of Kafka brokers for effectively managing and handling the data.
Now, you must be thinking about how can you identify a specific broker out of the range of brokers that a Kafka Cluster might contain. Well, any specific Kafka broker residing in a Kafka cluster could be recognized via its unique numeric ID.
Below is a crisp illustration of how a Kafka Cluster is made by five Kafka brokers.
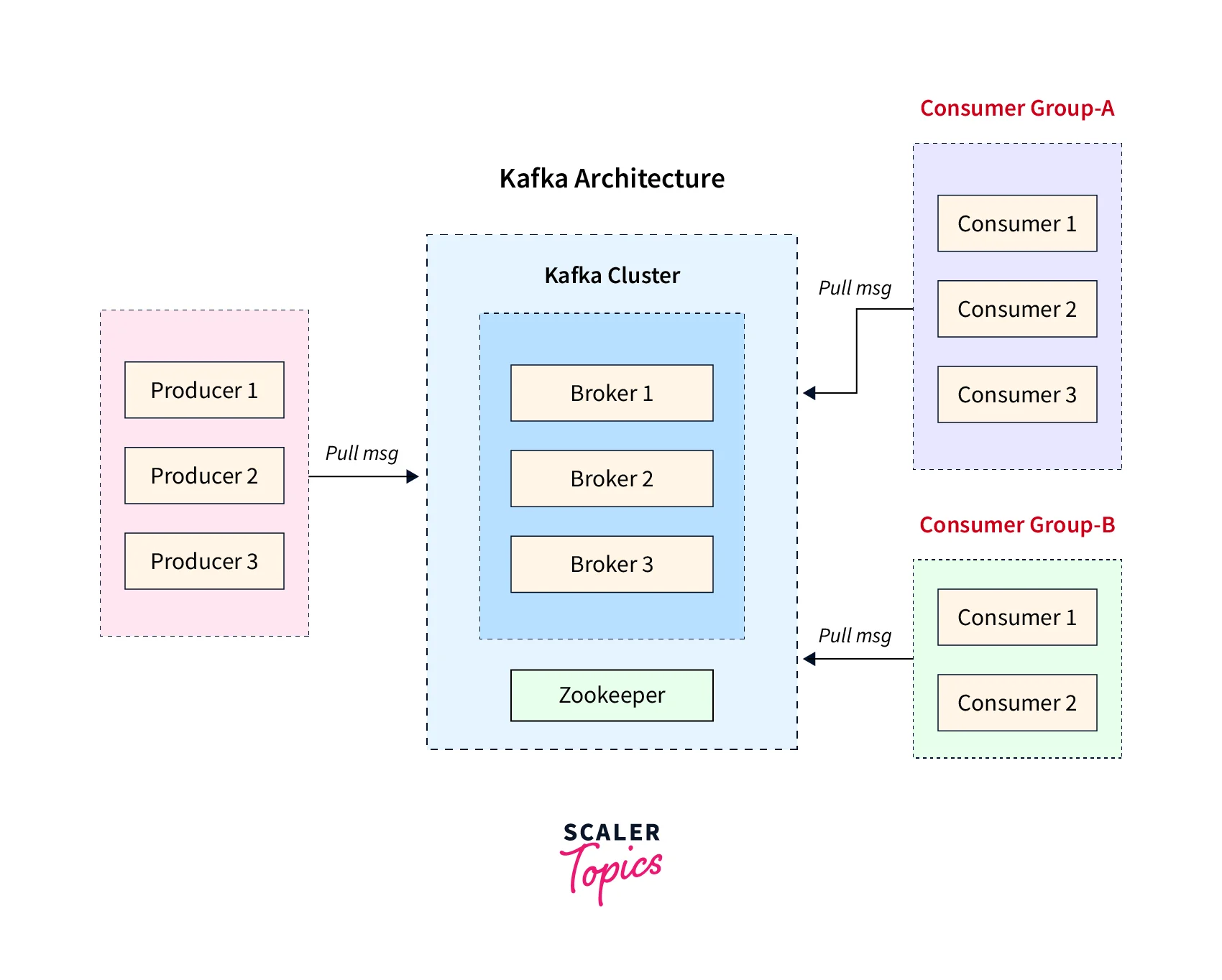
The Kafka cluster consists of multiple components, widely known as nodes, that together comprise the Kafka cluster. Various Kafka services such as Kafka Broker, Kafka Consumer, Kafka Producer, Zookeeper, etc are widely deployed to form a complete Kafka Cluster. Multiple functionalities like a failure, replication, data high availability, multiple partition support, etc are supported by it.
With these various brokers in a Kafka Cluster, the message is distributed over various instances. The Zookeeper plays a crucial role as a part of the Kafka cluster. It helps to synchronize, manage as well as handle the entire distributed configuration. Zookeeper also acts as the coordinator interface for the multiple Kafka brokers and consumers.
While the Kafka producer shall be pushing the message into the Kafka cluster, from where the message reaches the end of the Kafka cluster, where it could be easily read or consumed by the Kafka consumers.
You can understand more about it in the Kafka Cluster link, where we shall deep dive into the Kafka Cluster architecture as well.
How do Clients Connect to a Kafka Cluster (Bootstrap Server)?
Let us explore how a client connects with a Kafka Cluster. First, the client needs to connect with any Kafka broker to start sending or receiving the data records from the Kafka cluster. It is well known that each Kafka Broker residing in the Kafka cluster contains the metadata. This metadata contains information about the other Kafka brokers, which would eventually be utilized by the client to connect with the Kafka broker. Hence, any Kafka broker residing in the Kafka cluster is also widely known as a bootstrap server.
The metadata is returned via this bootstrap server to the specified client where the metadata includes the list of all the Kafka brokers in the Kafka cluster. With the help of this information, a client knows about each Kafka broker to connect to, send, or even receive data from. This list of information helps the client know the accurate data to find the specific Kafka brokers that serve their relevant topic-partition information.
Below is the pictorial representation of how a client connects with a Kafka Cluster:
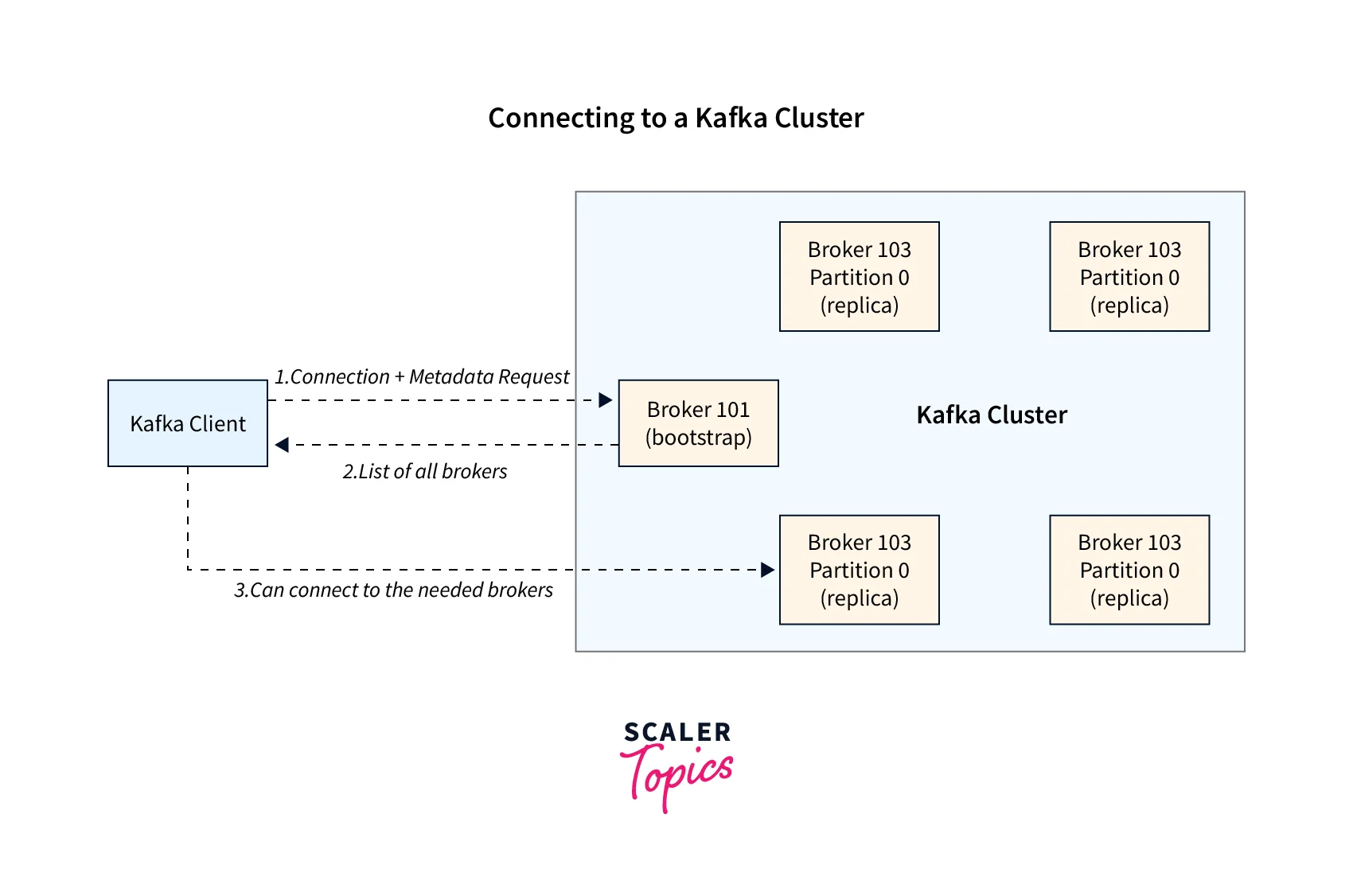 As a fault tolerance or security practice, the Kafka client always has the reference to at least two bootstrap servers as part of its connection URL. If any issue occurs, the Kafka client need not worry and can safely rely on the other Kafka broker to respond with the defined details. This also states that no Kafka client say, Developers, businesses, or even DevOps need to be aware of every single hostname for each of the Kafka broker residing in the Kafka Cluster. They only need to make sure that they are aware along with serves with two or three references in the connection string for the Kafka Clients.
As a fault tolerance or security practice, the Kafka client always has the reference to at least two bootstrap servers as part of its connection URL. If any issue occurs, the Kafka client need not worry and can safely rely on the other Kafka broker to respond with the defined details. This also states that no Kafka client say, Developers, businesses, or even DevOps need to be aware of every single hostname for each of the Kafka broker residing in the Kafka Cluster. They only need to make sure that they are aware along with serves with two or three references in the connection string for the Kafka Clients.
Conclusion
- Kafka Broker is structured as a KafkaServer, that is hosting various topics. The stated topics must be partitioned across the various brokers spread in a Kafka cluster.
- "–override property=value" is a widely used CLI to represent the value that must be overridden for the value set of the property in the server properties file.
- Kafka broker which acts as a mediator between the systems to smoothly transfer the message from the source to the destination.
- The Kafka brokers could create the Kafka cluster by exchanging information with each other either directly or indirectly via the Zookeeper.
- Any specific Kafka broker residing in a Kafka cluster could be recognized via its unique numeric ID.
- It is recommended that the Zookeeper is checked if it is up and running.