Kafka Cluster
What is Kafka Clusters?
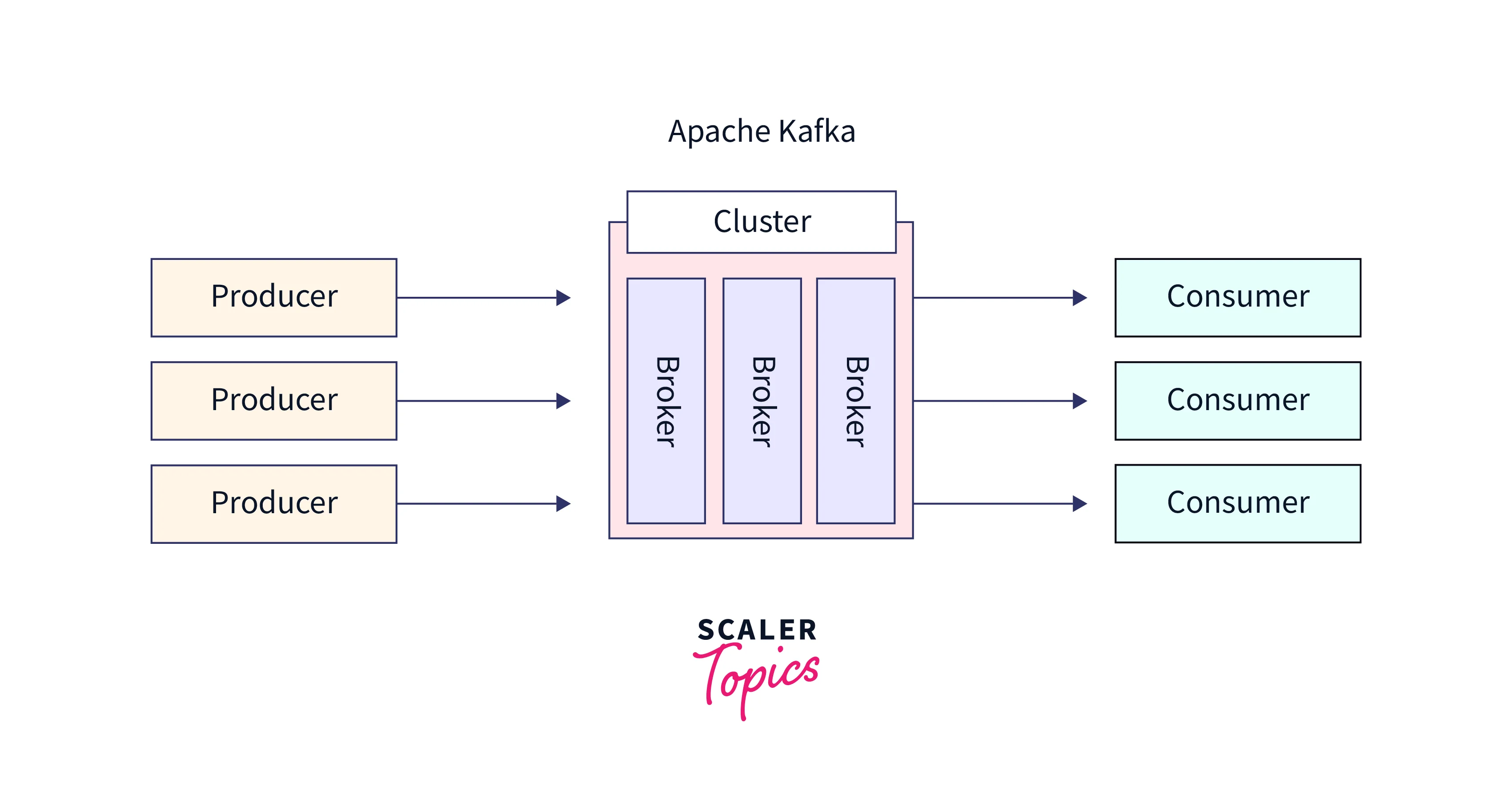
A Kafka cluster is a collection of several brokers, each with its partitions. Connecting two or more clusters to make the task of producers and consumers easier is referred to as a multiple Kafka cluster. A consumer extracts data from a Kafka topic. Operating a single Kafka broker is feasible, but it lacks some of the advantages that a cluster of Kafka brokers may offer, such as data replication.
Several Zookeepers may be present in a cluster; in fact, three to five are advised, with an odd number to ensure that there is always a majority and as few as feasible to save on overhead costs. Kafka clusters are also frequently used in conjunction with other big data technologies like as Apache Spark, Hadoop, and Cassandra to create end-to-end data processing and analytics pipelines.
Syntax
This command enters Kafka Cluster mode.
kafka-cluster name
Parameters
name : specifies the configuration's name.
A single period or two consecutive periods are not permitted in the name. The name can include up to 128 alphanumeric characters and one of the special characters listed below
period(.),hyphen(-) and underscore(_).
To remove connection for the Kafka cluster, use the no kafka-cluster command.
How does Kafka Cluster Work?
Partitioning
- A Kafka topic can be divided into one or more partitions, and each partition can be replicated across multiple brokers to provide fault tolerance and high availability.
- Round-robin partitioning is no longer the default partitioning strategy in Kafka. Producers employ the "sticky" partitioning approach as of Kafka 2.4. (org.apache.kafka.clients.producer.internals.DefaultPartitioner).
Kafka Brokers
- Kafka Brokers are a critical component of a Kafka cluster. They store and process the data, manage the partitions and replicas of the topics, and ensure high availability and fault tolerance. Without Kafka Brokers, the Kafka cluster would not be able to function.
- The min.insync.replicas option defines the number of brokers who must confirm receiving the record before the producer deems it to have been properly provided.
In-sync and out-of-sync replicas
- If a replica hasn't asked for new messages in 30 seconds or hasn't caught up to the most recent message in the last 30 seconds, it is by default out of sync. By using the replica.lag.time.max.ms option, we may regulate the passing of time.
- The partition leader keeps track of the amount of in-sync copies since high dependability requires duplicating all messages across several brokers.
- The above reason partition leader stops any writes to that partition if the number of in-sync replicas is less than the min.insync.replicas option, since it cannot ensure the appropriate durability.
Cluster controller
- Cluster Controller is a core component that is responsible for maintaining and managing the state of the cluster.
- It is elected among the Kafka brokers and acts as a central coordinator for various tasks such as broker registration, leader election, topic partition reassignment, and handling of failed nodes.
Partition leader election
- In a Kafka cluster, each partition of a topic is replicated across multiple brokers to ensure high availability and fault tolerance. One of the replicas is designated as the leader, which is responsible for handling all read and write requests for the partition. If the leader replica fails or goes offline, the Kafka cluster must elect a new leader for the partition. This process is known as Partition Leader Election.
Kafka Clusters Architecture
A system made up of several Brokers, Topics, and Partitions for both is known as a Kafka cluster.Equal workload distribution across replicates and partitions is the main goal.
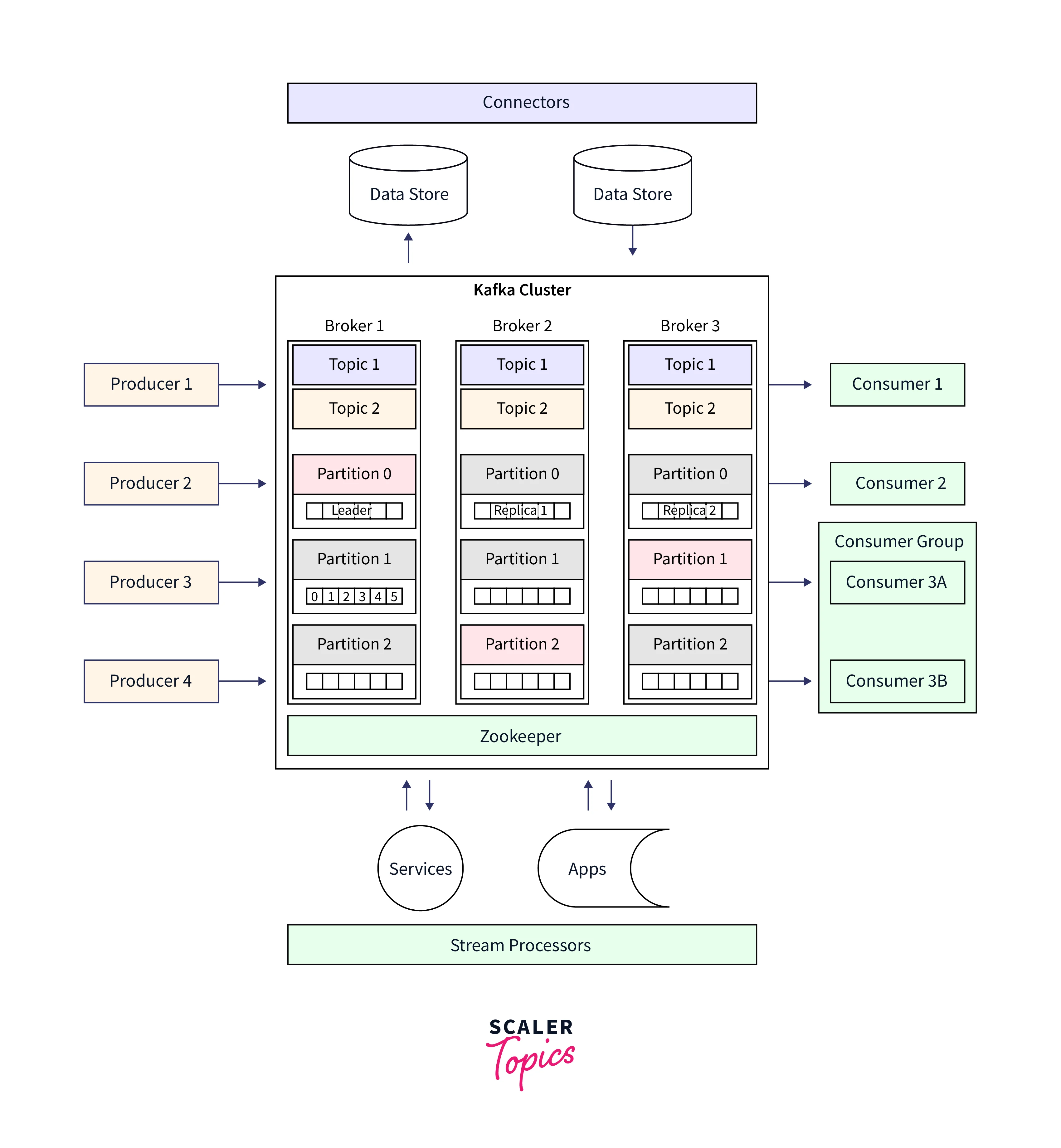
Topic
- Kafka divides topics into partitions, which can be divided into any number of parts. Several users can access data from the same topic at once thanks to Kafka partitions.The number of divisions is specified while configuring a Topic, however, it can be changed afterward.
- The servers of the Kafka Clusters' servers house the partitions that make up a topic.
Broker
- The Kafka Server, sometimes referred to as the Broker, is in charge of managing the Topic's Message Storage. For load balancing purposes, each Kafka Cluster has many Kafka Brokers.
- Also, the replication factor cannot be greater than the total number of available Brokers.
Zookeeper
- The cluster's Kafka brokers, producers, and consumers are managed and coordinated by ZooKeeper, a distributed coordination service.
- It keeps track of details about the Kafka cluster's status, including where each broker is located, what topics and partitions are present, and how each component is configured.
Producers
- Producers in Kafka cluster are applications or processes that generate data and publish it to Kafka topics. They are responsible for partitioning the data and selecting the appropriate broker for each partition. Producers can also compress and serialize the data, authenticate with the Kafka cluster, and receive acknowledgments for each published message.
Consumers
- . They are responsible for fetching and processing data from the Kafka cluster and can be configured to consume data in various ways, such as in batches or continuously. Consumers can also be part of a consumer group, allowing them to scale horizontally and distribute the workload across multiple instances.
Conclusion
- The above article covered the Apache Kafka Clusters architecture, including concepts like Topics, Brokers, Producers, and Consumers.
- Providing highly distributed workloads across replicas and partitions is the goal.
- Kafka cluster architecture in brief:
- Brokers: Brokers take communications from producers, store them on disk, and then make them accessible to consumers.
- Topics: In Kafka, topics serve as the communicational medium. They are separated into one or more divisions and given a name.
- Partitions: In a Kafka cluster, partitions are topic parts that are dispersed among the brokers.
- Producers: These people are in charge of writing the communications, giving them a theme, and delivering them to the right broker.
- Consumers are in charge of subscribing to a topic and retrieving the messages allotted to them.
- Many businesses use Apache Kafka to address their big data issues. You may create data-driven applications more successfully and handle streams of data more effectively by understanding the Kafka Clusters Architecture.