Kafka Connect
Apache Kafka is a distributed streaming platform, and Kafka Connect is a framework for connecting Kafka to other systems such as databases, key-value stores, search indexes, and file systems through the use of Connectors. Because Kafka Connect is only used to replicate streaming data, its reach is limited. It functions as an independent testing procedure as well as a distributed, scalable service support for an organization.
A framework in Apache Kafka called afka Connect makes it possible to integrate Kafka with other systems in a scalable and reliable method. For data streaming between Kafka topics and external systems like databases, file systems, message queues, and S3 storage, it offers a simple-to-use and extensible architecture.
Data pipelines may be created and managed without the need for additional programming thanks to Kafka Connect. Connectors are used to indicate the transformations to be made to the data as it passes between the source and sink systems and to define the source and sink systems. Several connections are pre-installed in Kafka Connect, and the Kafka community can also create and distribute new connectors.
How Kafka Connect Works?
A feature of Apache Kafka called Kafka Connect makes it simple to import data from other systems into Kafka or to export Kafka data into other systems. Built on top of Kafka's distributed architecture, Kafka Connect makes use of Kafka's fault-tolerance and scalability features.
Connectors are used by Kafka Connect to transfer data between Kafka and other systems. Connectors are modular parts that specify how data should be exported from Kafka to an outside system. Connectors may be set up to function either independently or as a unit in a distributed Kafka Connect cluster.
One or more tasks are created when a connection is launched. The actual data transfer between Kafka and the external system is carried out through tasks. Each job uses a different client library to interface with Kafka and the external system while running in its thread.
Additionally, Kafka Connect comes with a REST API that lets users control connections, tasks, and configurations. Users can add new connectors, change existing connectors, or delete connectors completely using the API.
For data integration, Kafka Connect supports several data types, including:
- JSON:
A simple to read and write, lightweight data exchange format. - Avro:
A compact binary data format that offers detailed data structures and a versioning schema registry. - Plain text is a straightforward text-based format that is simple to parse and work with.
- Binary:
A general-purpose binary data format that may be used for any sort of data.
Architecture of Kafka Connect
To make the data readily available for low-latency stream processing, Kafka Connect may ingest whole databases or gather metrics from all of your application servers into Kafka topics.
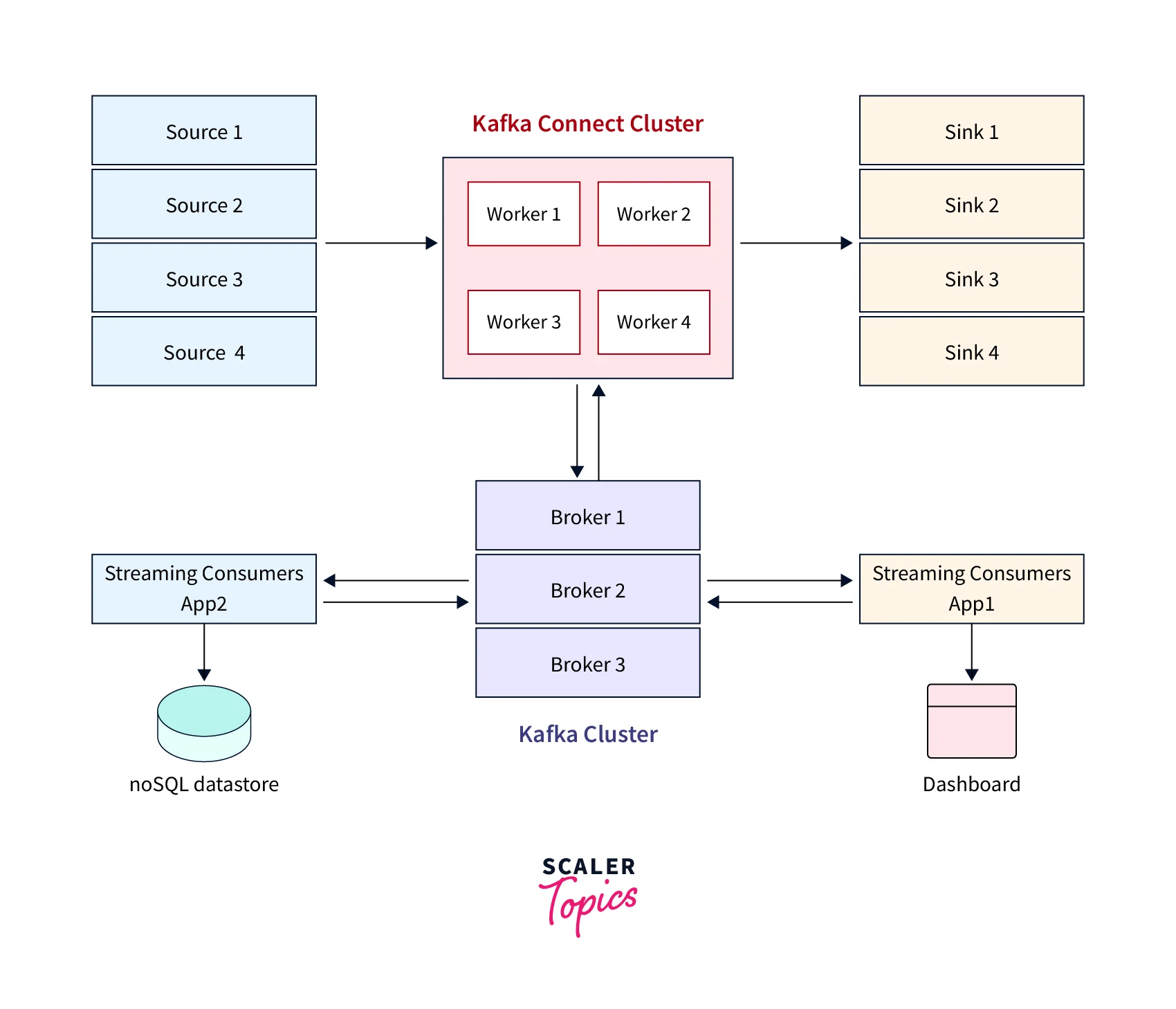
The data flow can be explained as follows:
- Various sources are connected to Kafka Connect Cluster. Kafka Connect Cluster pulls data from the sources.
- Kafka Connect Cluster consists of a set of worker processes that are containers that execute connectors, and tasks automatically coordinate with each other to distribute work and provide scalability and fault tolerance.
- Kafka Connect Cluster pushes data to Kafka Cluster.
- Kafka Cluster persists the data on the broker's local disk or Hadoop.
Data from Kafka topics may be exported into batch systems for offline analysis, secondary storage, and query systems.
Apache Kafka can be made scalable, dependable, and readily linked with other heterogeneous systems (like Cassandra, Spark, and Elassandra) without the need for further coding thanks to Kafka Connect, an API and ecosystem of third-party connectors.
Connectors and Tasks
The Kafka Connect API has three main components: connectors, tasks, and workers.
Connectors:
- Connectors are responsible for defining how data is read from or written to external systems. There are two types of connectors: source connectors and sink connectors.
- Source connectors are responsible for reading data from external systems and writing it to Kafka, while sink connectors are responsible for reading data from Kafka and writing it to external systems.
- Connectors in Kafka Connect can be managed using the Kafka Connect REST API or command-line tools.
- Connectors are responsible for managing tasks, which are responsible for the actual data movement, but connectors do not perform data movement themselves.
Tasks:
- A source task employs a Kafka producer to distribute data to Kafka topics and contains custom code to retrieve data from the source system (in the pull() function).
- The put() method of a Sink Task employs custom code to publish data to the Sink system while a Kafka consumer polls Kafka topics and reads data.
- Tasks are responsible for the actual movement of data between Kafka and external systems. Each task corresponds to a subset of the data, and multiple tasks can be run in parallel.
- Tasks are responsible for creating the appropriate data source or sink connectors, mapping the data to the appropriate format, and reading or writing data as necessary.
Source and Sink Connectors
- A Source Connector specifies the data systems from which data should be collected, which might be a database, real-time data streams, message brokers, or application metrics.
- The Source Connector, once defined, connects to the source data platform and makes the data available to Kafka topics for stream processing.
- A Sink Connector, on the other hand, specifies the destination data platform or the endpoint of the data.
- These endpoints might be any variety of data systems, including index engines, other databases, or file storage.
- While sink connections take data from Kafka topics and send it to external systems, source connectors draw data from external systems and write it to Kafka topics.
- Accordingly, sink connections are also unidirectional and can only receive data from Kafka, whereas source connectors are unidirectional and can only send data to Kafka.
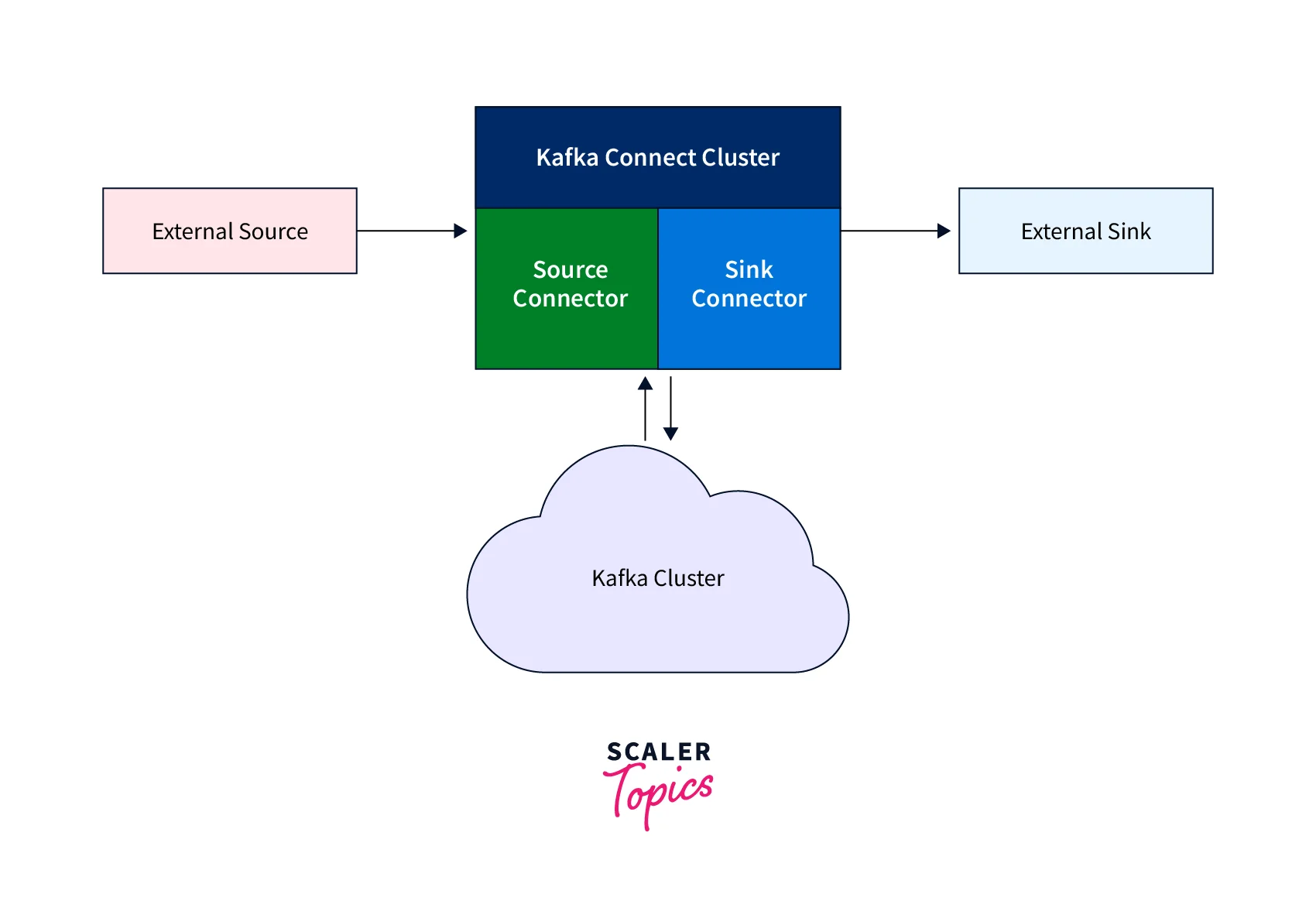
Source and Sink Flows in the High Level Kafka Connect Architecture
Workers
- Workers are responsible for coordinating the execution of connectors and their associated tasks.
- Workers receive tasks from the Kafka Connect cluster and assign them to worker threads for execution. Workers can run on separate machines for horizontal scaling, and each worker instance is responsible for coordinating the execution of one or more connectors and their tasks.
- Workers communicate with one another automatically to distribute work and offer scalability and fault tolerance.
- Workers will distribute work among any available processes but are not responsible for process management; any process management strategy (e.g. cluster management tools like YARN or Mesos, configuration management tools like Chef or Puppet, or direct management of process lifecycles) can be used for Workers.
Kafka Connect Clusters
- There may be one standalone worker or several distributed workers operating on one or more servers in a Kafka Connect cluster.
- The workers divide the work among the available worker processes and are in charge of managing connectors and tasks.
- On a single server, there is only one worker process operating in standalone mode, which is responsible for managing all connections and tasks.
- The connections and tasks are divided across the worker processes in the distributed mode, which consists of several worker processes running on numerous servers. This enables fault tolerance and horizontal scaling.
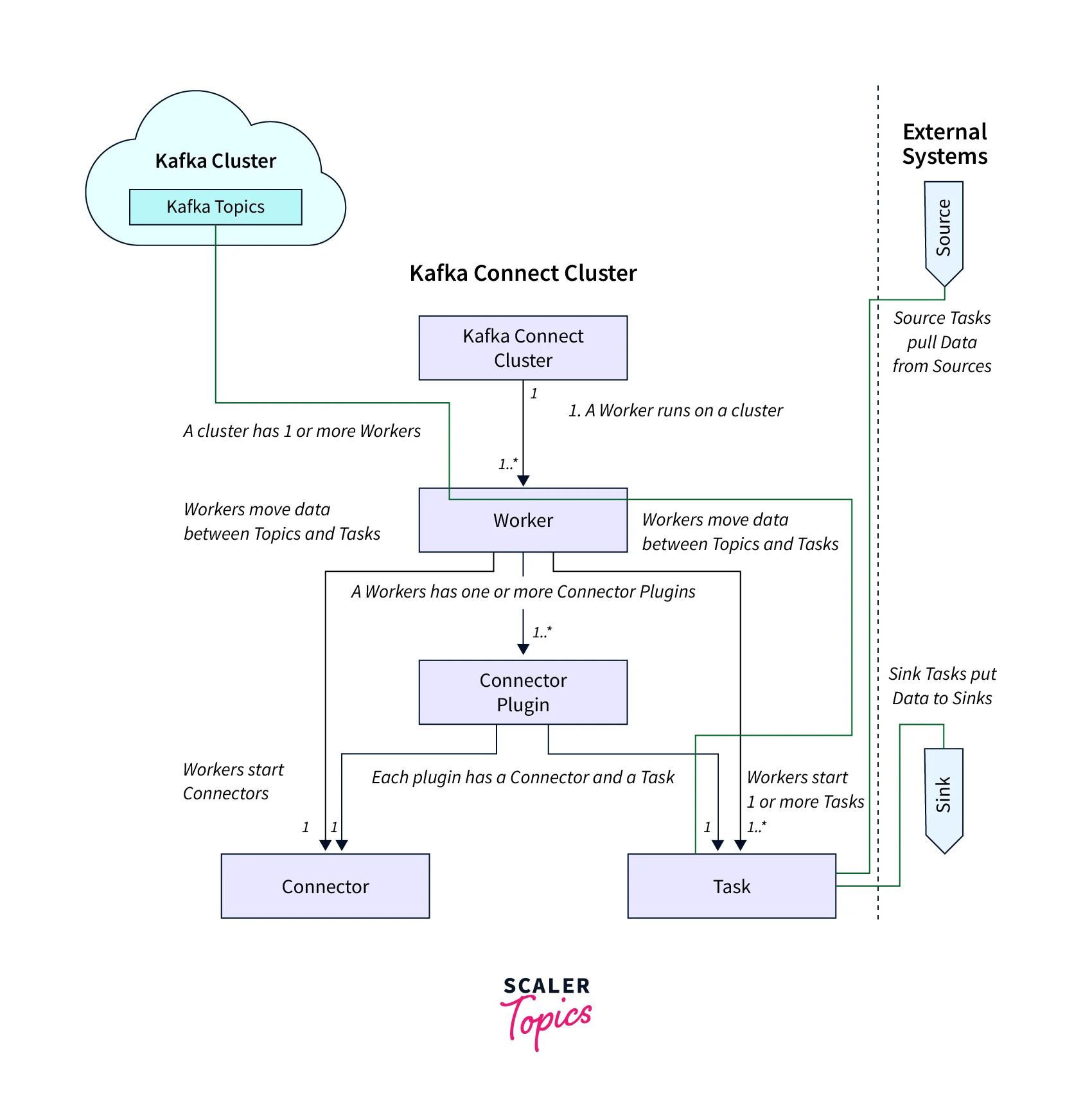
Green lines represent the movement of the data.
The primary connections and purposes of each component in a connected cluster are depicted in the diagram below:
- A Kafka Connect cluster can run on one or more servers (for production, these will be separate from the servers serving the Kafka Brokers), with one (but potentially more) worker on each server.
- Worker:
Workers move the data between Topics and Tasks. A Worker has one or more connector Plugins. Worker start connectors and also one or more Tasks. - Connector Plugins:
Each plugin has a Connector and a Task. - External Systems:
- Source:
A Source Task uses custom code to pull data from the Source system and send it to Kafka topics. - Sink:
A Sink Task uses a Kafka consumer to poll Kafka topics and reads data, and custom code to push data to the Sink system using the put method.
- Source:
Standalone vs Distributed Mode
| Standalone Mode | Distributed Mode |
|---|---|
| Number of Workers are single run in this mode | Multiple number of Workers run in this mode |
| Fault Tolerant is low | Fault Tolerant is high |
| Reliability is low and Scalability is limited | Reliability is high and Scalability is also high |
| Deployment and testing is very easy | Deployment and testing is complex, useful for production environment |
| Configuration is included in the procedure. | A REST API is used to submit configuration. |
Kafka Connect Features
An Apache Kafka framework called Kafka Connect makes it simple and reliable to transfer data between Kafka and other systems. It offers a fault-tolerant and scalable means to stream data into and out of Kafka.
Kafka Connect's features include:
- Connectors that are ready to use right out of the box: Kafka Connect includes a variety of pre-built connectors for popular data sources including databases, file systems, and messaging systems. Without having to create proprietary code, you can quickly combine Kafka with other systems using these connectors.
- Simple configuration:
Kafka Connect connections are set up and configured with ease using straightforward properties files. - Kafka Connect is built with a distributed architecture in mind, enabling you to extend your data pipeline horizontally as your needs change.
- Kafka Connect is built with automated failure detection and recovery, making it fault-tolerant.
- Integration with the Kafka ecosystem:
Kafka Connect combines well with other Kafka ecosystem parts like KSQL and Kafka Streams.
Conclusion
- A mechanism in Apache Kafka called Kafka Connect enables scalable and trustworthy interaction between Kafka and other systems.
- The usage of connectors makes it possible to create and maintain data pipelines without writing original code.
- The source and sink systems, as well as the data transformations that can be used as the data transfers between them, are defined by connectors.
- Additional connections can be created and published in the Kafka community in addition to the built-in connectors that come with Kafka Connect.
- Scalable, fault-tolerant, and highly available are features of Kafka Connect, which may also be used in distributed mode.
- The Kafka Connect REST API, command-line tools, and built-in monitoring and logging may all be used to deploy, manage, and monitor connectors.