What is Kafka Consumers?
What is Kafka Consumer?
Kafka Consumers are readers of data from Kafka topics. A topic in Apache Kafka is the name of a category or feed to which records are published by producers. Consumers subscribe to one or more topics and pull messages from the topic's partitions to read the information from them.
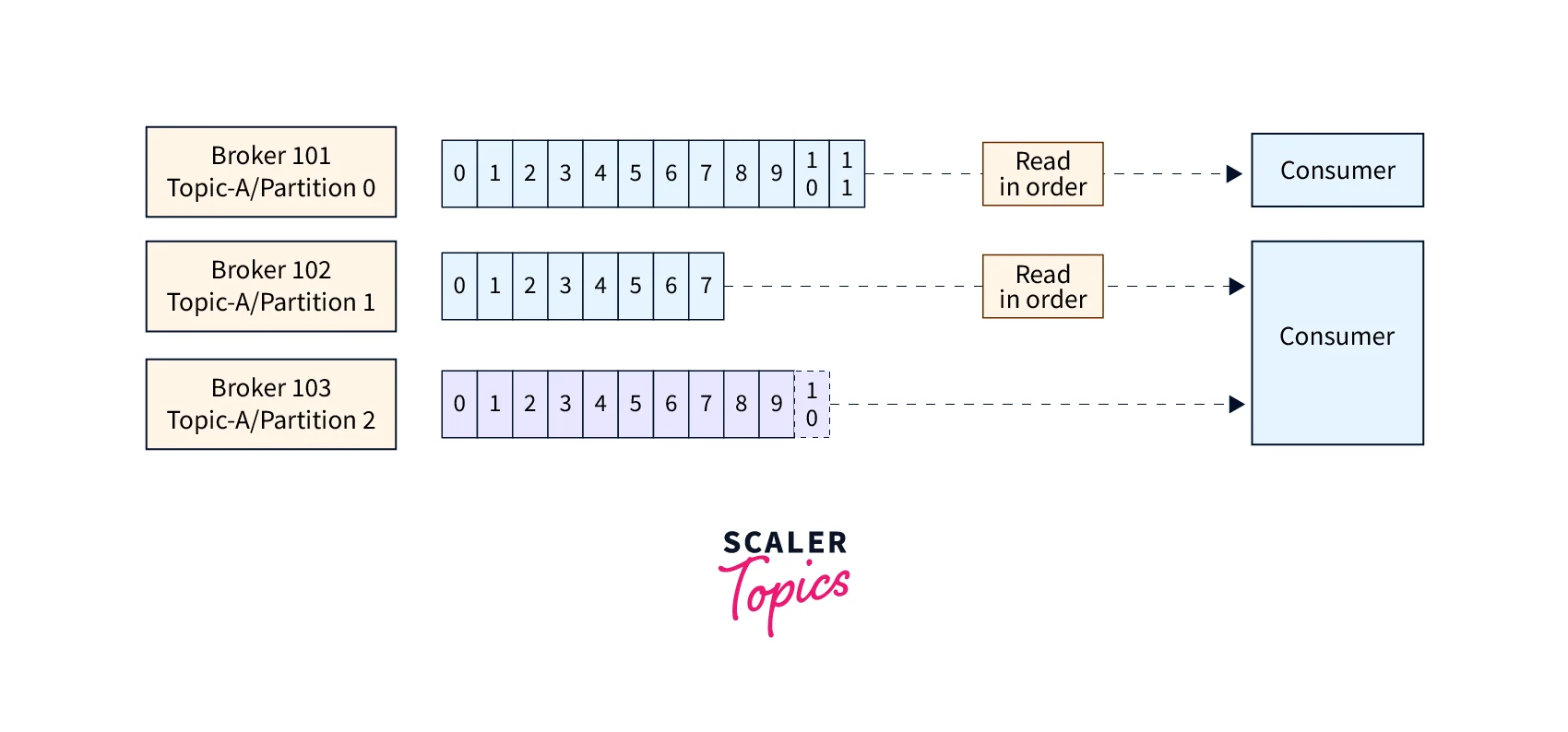
- A consumer group is a collection of consumers who cooperate to consume information on a certain issue, and customers can be a part of consumer groups. To guarantee that the data is evenly distributed among the consumers, each partition of a topic can only be consumed by one consumer within a consumer group.
- An interface for creating Consumers in different programming languages is provided by Kafka client libraries.
- Consumers are often used in streaming analytics, log aggregation, and event-driven systems for real-time data processing.
Kafka Message Deserializers
- The data sent by the Kafka authors is serialized, as we have previously seen. This means that for the data that the Kafka consumers receive to be meaningful in your application, it must be correctly deserialized. The format in which the data was serialized must be used to deserialize the data before consumption. For instance:
- If a String was serialized by the producer using StringSerializer, it must be deserialized by the consumer using StringDeserializer.
- Consumers must use IntegerDeserializer to deserialize an Integer if the producer serialized it using IntegerSerializer.

Throughout a topic lifecycle, the serialization and deserialization format of the topic cannot differ. It is regarded as best practice to build a new topic and migrate your apps to use that new topic if you wish to change the data format of a subject (for instance, from JSON to Avro).
Building Kafka Consumers
Applications can send and receive real-time data streams using the distributed streaming platform Kafka. Applications that read and process data from Kafka topics are known as Kafka Consumers.
Set Up a Kafka Cluster
- You can install Kafka on-premises or use a cloud-based Kafka service. To set up the Kafka cluster for creating the Kafka consumer application, you can utilize either the Confluent Cloud platform or your local machine's default Apache Kafka installation.
- You can utilize the Confluent Cloud platform to build up the Kafka cluster most simply and effectively possible with a great deal less programming work because it is a fully managed service.
A new Kafka cluster has now been successfully set up and launched.A new directory must be set up for Kafka cluster configuration data.
Using the Confluent Cloud Console, go to the Kafka cluster. Under the "Clients" view section, you may get connection details.
The connection settings needed to access the Kafka cluster hosted by Confluent Cloud are contained in the ccloud.properties file.
Creation of Kafka Topic
To create a new topic, run the command below.
Kafka Consumer Application Configuration
- Gradle is a build automation tool that supports you throughout the building, testing, and deployment stages of the end-to-end software development life cycle.
Write a code in Grade as follows :
- Save as the file name with "config. gradle".
- To obtain the Gradle wrapper, which acts as a script file to run all Gradle tasks, enter the following command:
- Adding the following code to the newly formed configuration file and saving it as "dev.properties"
Add the required Confluent Cloud information to the dev.properties files by running the command given below :
- Create a new file called Kafka_Consumer_Application.java in the developer directory you created earlier to write, compile, and run Java code for creating Kafka consumer apps.
- The Kafka Consumer Application function is represented by the code snippet above, which uses the constructor argument to pass consumers and consumer records handlers.
The recordsHandler.process(consumerRecords) function returns polled or fetched consumerRecords to the consumerRecordsHandler interface.
Create a new java file named file_writing_records.java:
Create a Java file by writing the code below and saving it.
- ConsumerRecordsHandler is an interface used to handle and manage consumer records fetched from Kafka servers.
- The File_Writing_Records_Handler class writes records fetched from Kafka servers to a separate file.
- After creating code in file_writing_records.java, use the following command to build and start the Kafka consumer application program.
- By running the command above, you have produced a jar for the Kafka consumer application. To start an end-to-end program, you need a JAR file that includes and archives all the classes, packages, and dependencies.
Compiling and Running the Kafka Consumer Application
Run the Kafka consumer application by using the following command.
- You must send messages into the Kafka topic you previously created after starting the Kafka consumer application for it to start consuming data from this topic.
- Run the following command in a new terminal to produce messages into a Kafka topic.
- From the above running command Kafka producer console publishes messages to the Kafka topic named test_topic.
Consumer Groups
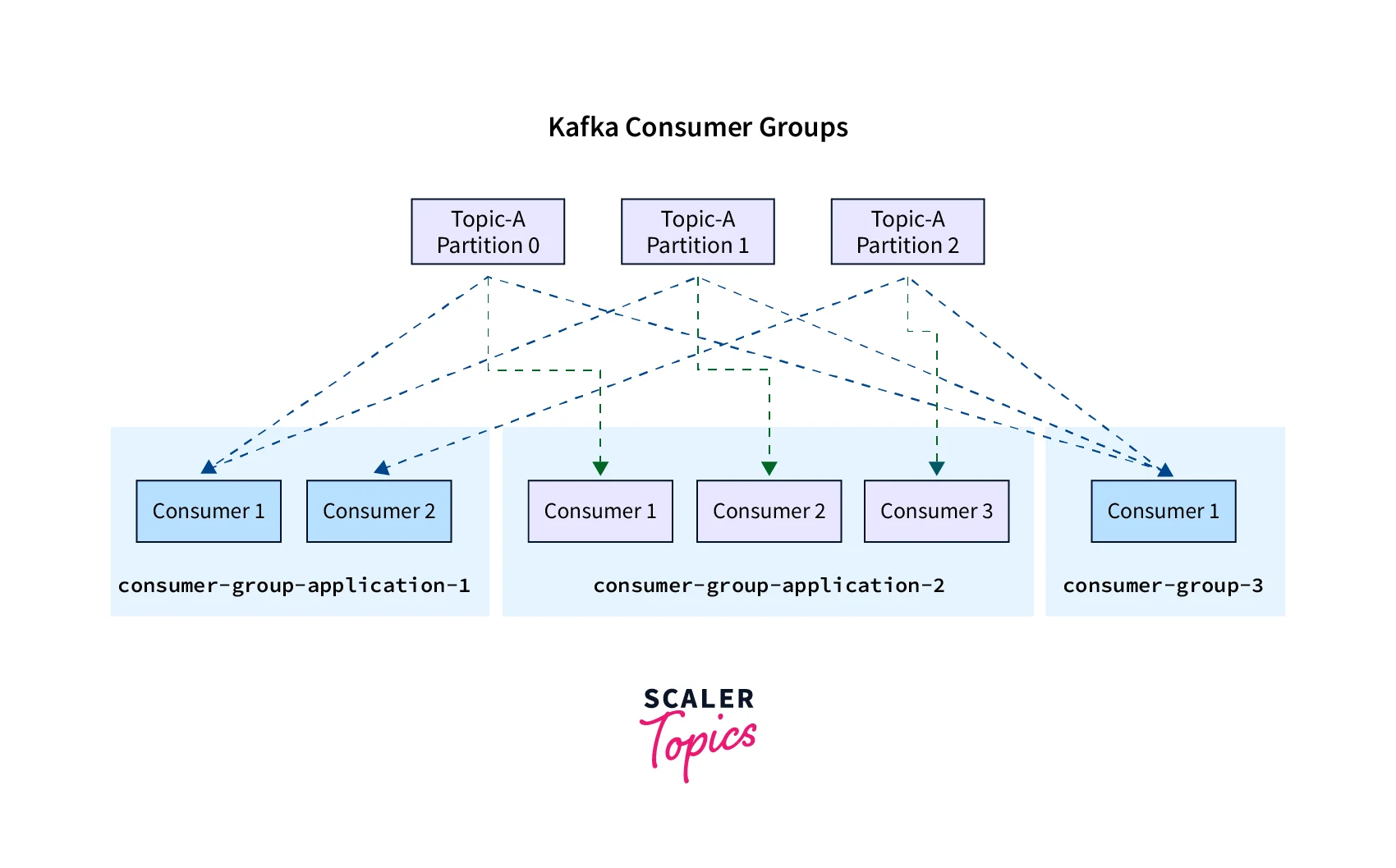
- Kafka Consumer Groups allow numerous Consumers to share the workload of consuming data from a single Kafka topic.
- A group of one or more Consumers who cooperate to consume messages from one or more Kafka topics is known as a Consumer Group.
- Each topic partition is automatically assigned to a single Consumer inside the group by Kafka.
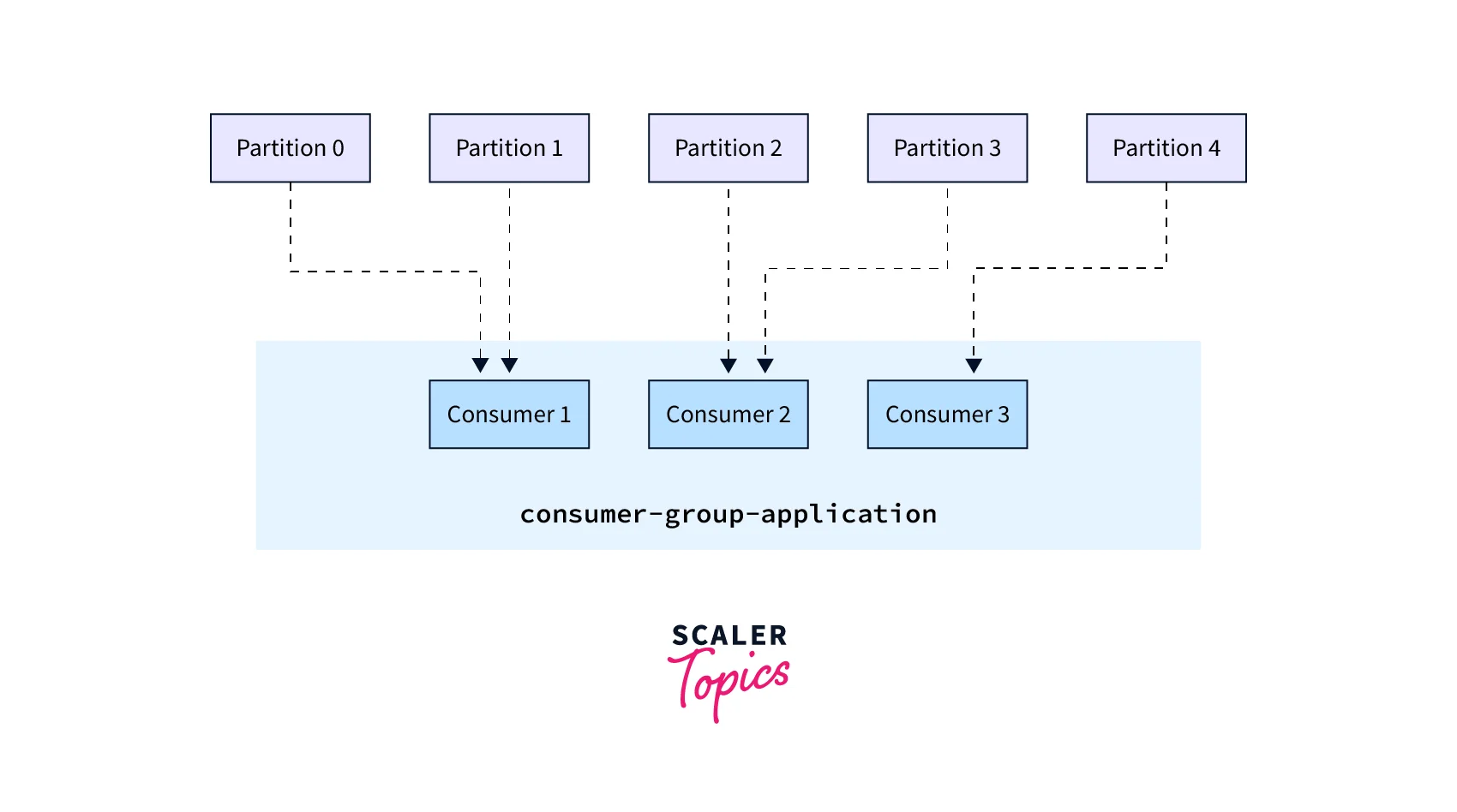
- The Consumers in the Consumer Group are then equally divided into messages from this topic.
- By adding new consumers to the group, consumer groups let you extend your application horizontally while Kafka takes care of load balancing for you.
Kafka Consumer Group ID
- The load balancing of all consumers in the same group is performed automatically by Kafka Consumers using a GroupCoordinator and a ConsumerCoordinator to allocate consumers to a partition.
- A consumer from a consumer group can be allocated many subject partitions, but it's vital to remember that each topic partition is only assigned to one consumer inside a consumer group.
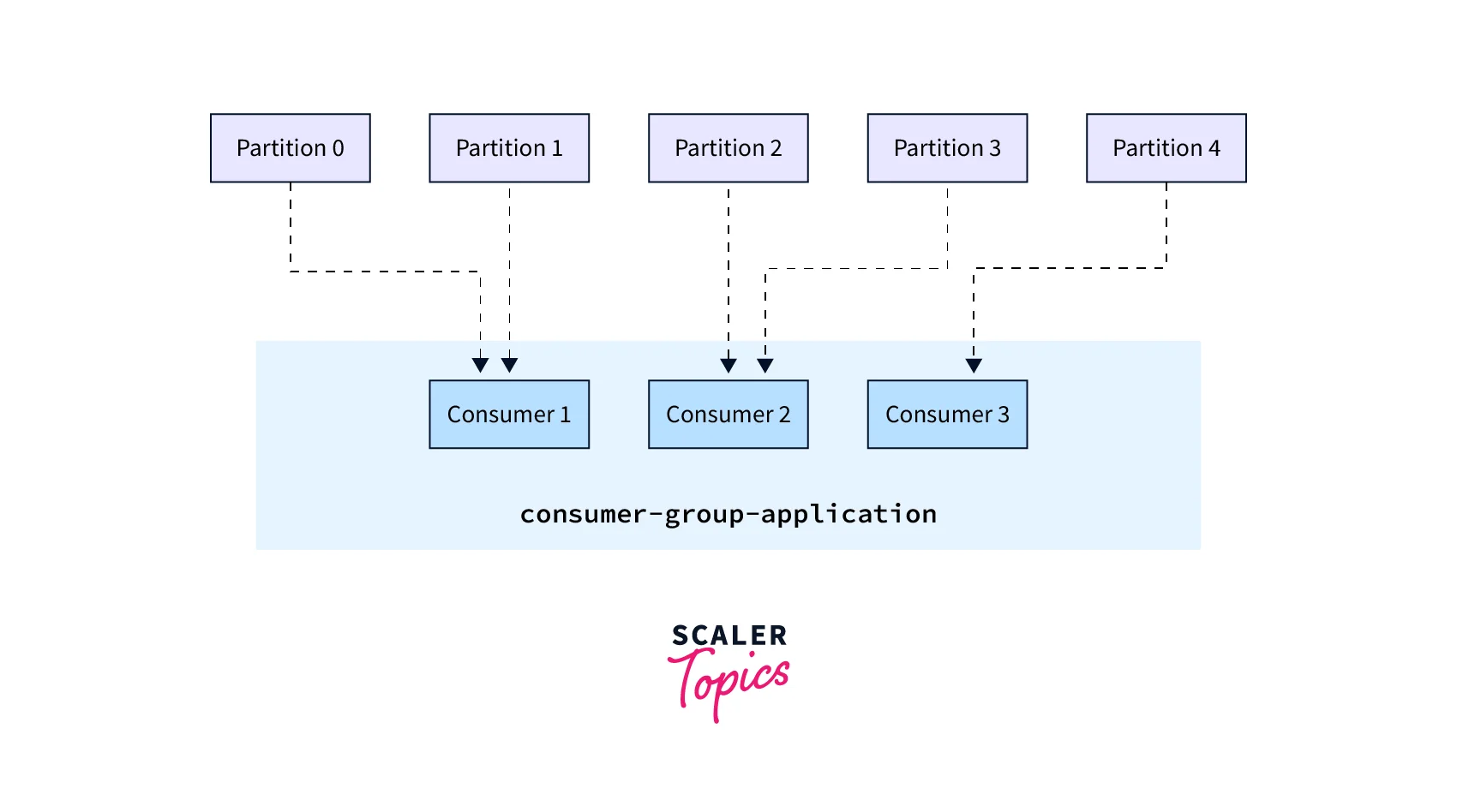
In the above example, Partitions 0 and 1 have been allocated to Consumer 1 of the consumer group consumer-group-application-1, while Partitions 2 and 3 have been given to Consumer 2, and Partition 4 has been given to Consumer 3. Messages from Partitions 0 and 1 are only received by Consumer 1, those from Partitions 2 and 3 are only received by Consumer 2, while messages from Partition 4 are only received by Consumer 3.
- The group must be separate for each of your apps that read from Kafka topics (which may include several consumers).id.
Consumer Offsets
- Kafka Consumer Offsets are crucial for maintaining a Consumer's state and preventing message processing duplication. By enabling consumers to continue reading from the most recently committed offset following a failure, they also offer fault tolerance.
- The messages that a certain consumer group last successfully processed are tracked by Kafka brokers using an internal topic called __consumer_offsets.
- Each message in a Kafka topic has an offset ID and a partition ID linked to it, as is common knowledge.
- So, the consumer will periodically commit the most recently processed message, also known as consumer offset, to "checkpoint" how far they have been reading into a topic partition.
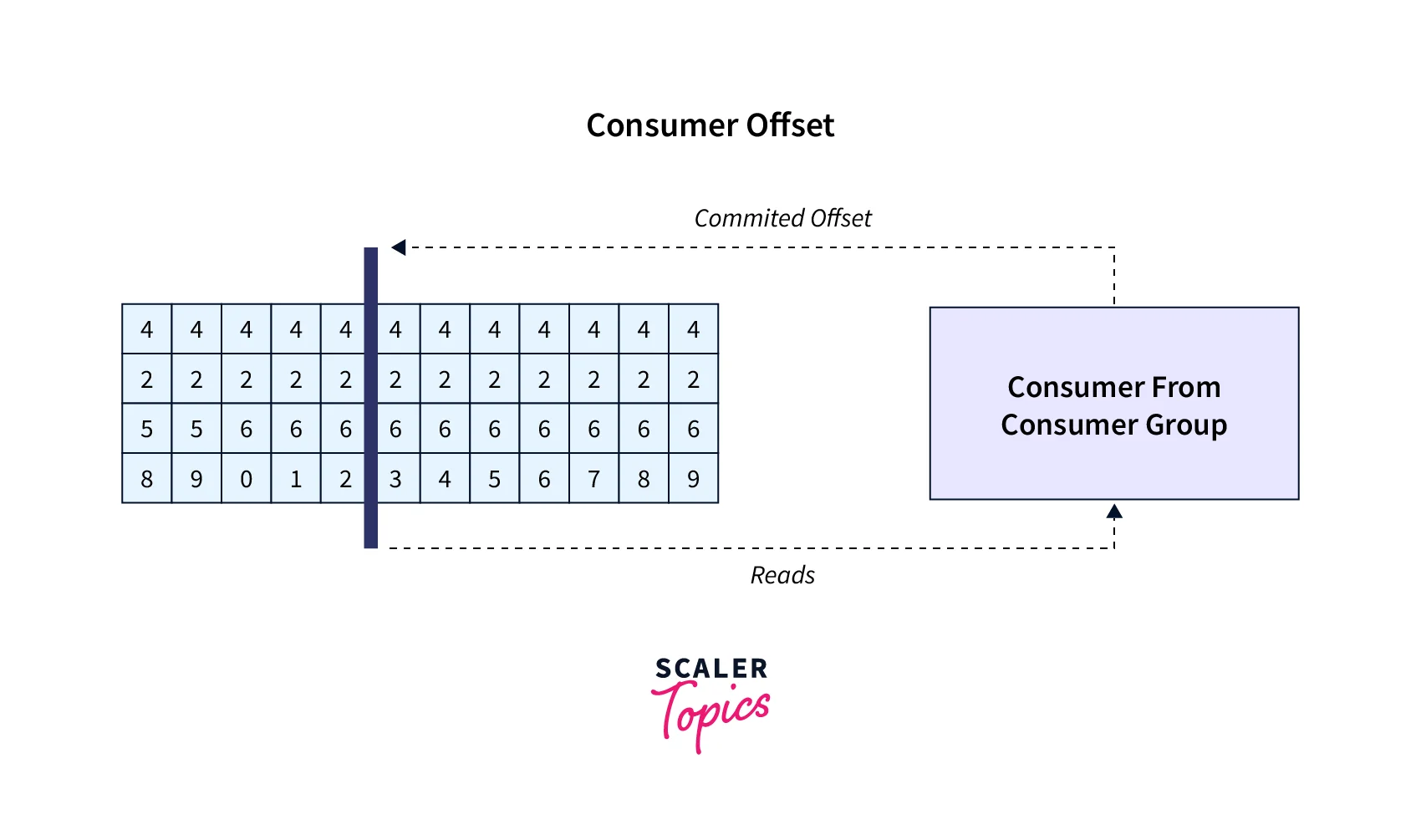
- The majority of client libraries will periodically commit offsets for you to Kafka, and the accountable Kafka broker will assure publishing to the __consumer_offsets topic (consumers do not directly write to that topic).
- Committing offsets is a periodic procedure rather than being done for every message ingested (since it would be inefficient).
- For many applications, offsets are essential. The most recent committed offset aids the remaining Kafka consumers in determining where to begin reading and processing messages if a Kafka client fails.
- Consumer offsets are once again used to inform consumers where to start reading data from if a new consumer is added to a group, resulting in another consumer group rebalancing.
Benefits of Kafka Consumer
- Scalability: Because Kafka Consumers are built to handle massive amounts of data, they are very scalable. They can manage a huge number of concurrent connections and can be distributed over numerous nodes.
- Flexibility: Kafka Consumers may be set to read data from one or more partitions of a Kafka topic, providing additional data processing flexibility.
- Kafka's fault-tolerance Consumers are built to be fault-tolerant, which means they can keep processing data even if there occurs a breakdown or outage.
- Kafka Consumers are built for real-time data processing, which means they can process data as it is created, making them perfect for use cases requiring near-real-time data processing.
- Kafka Consumers are available for a variety of programming languages, including Java, Python, and Scala, making it simple to incorporate them into existing systems and processes.
- Low latency: Because Kafka Consumers are built for low-latency data processing, data may be handled rapidly and effectively, lowering total processing time.
Conclusion
- Clients in the Apache Kafka ecosystem known as "Kafka Consumers" consume data from Kafka topics.
- Data may be read from one or more partitions of a Kafka topic by consumers, who collaborate in consumer groups to process data effectively.
- A topic's commencement or the most recent messages can be selected for consumers to read data from.
- Specifying batch sizes, offsets, and polling frequency are just a few of the choices available with Kafka Consumers to manage how data is retrieved from topics.
- Data may be processed in many different ways by consumers, including uploading information to a database, sending out alerts, or doing complicated analyses.
- Modern data pipelines can process real-time data with the help of Kafka Consumers because they are extremely scalable, fault-tolerant, and able to handle massive volumes of data.