What is Apache Kafka Producer?
Kafka Broker, Consumer, Producer, and Zookeeper are the core components of the Kafka cluster architecture. While the producer shall be pushing the message into the Kafka cluster, it is the Kafka broker that helps to transfer the message from the producer to the consumer. The zookeeper works as the centralized controller, which manages the entire metadata information for the Kafka producers, brokers, and consumers. Finally, the message reaches the end of the Kafka cluster, where it can be easily read by the consumers.
The Kafka Producers can be defined as the one from where the users can publish, push messages, or writes the data records to the topics within various partitions. It is automatically detected by the producers about what data must be written at which of the partition and broker. The user doesn't need to define the broker and the partition.
The source where the data stream starts is what is termed a Kafka producer. It is the Kafka Producer, where users shall generate tokens, data records, or messages that can be published to more than one Kafka topic in the Kafka cluster. For this process, Apache Kafka Producer is utilized. With the Kafka Producer API, users can pack the data records and send them to the central Kafka Server.
Below is the depiction of how the Kafka producer works with the Kafka cluster.
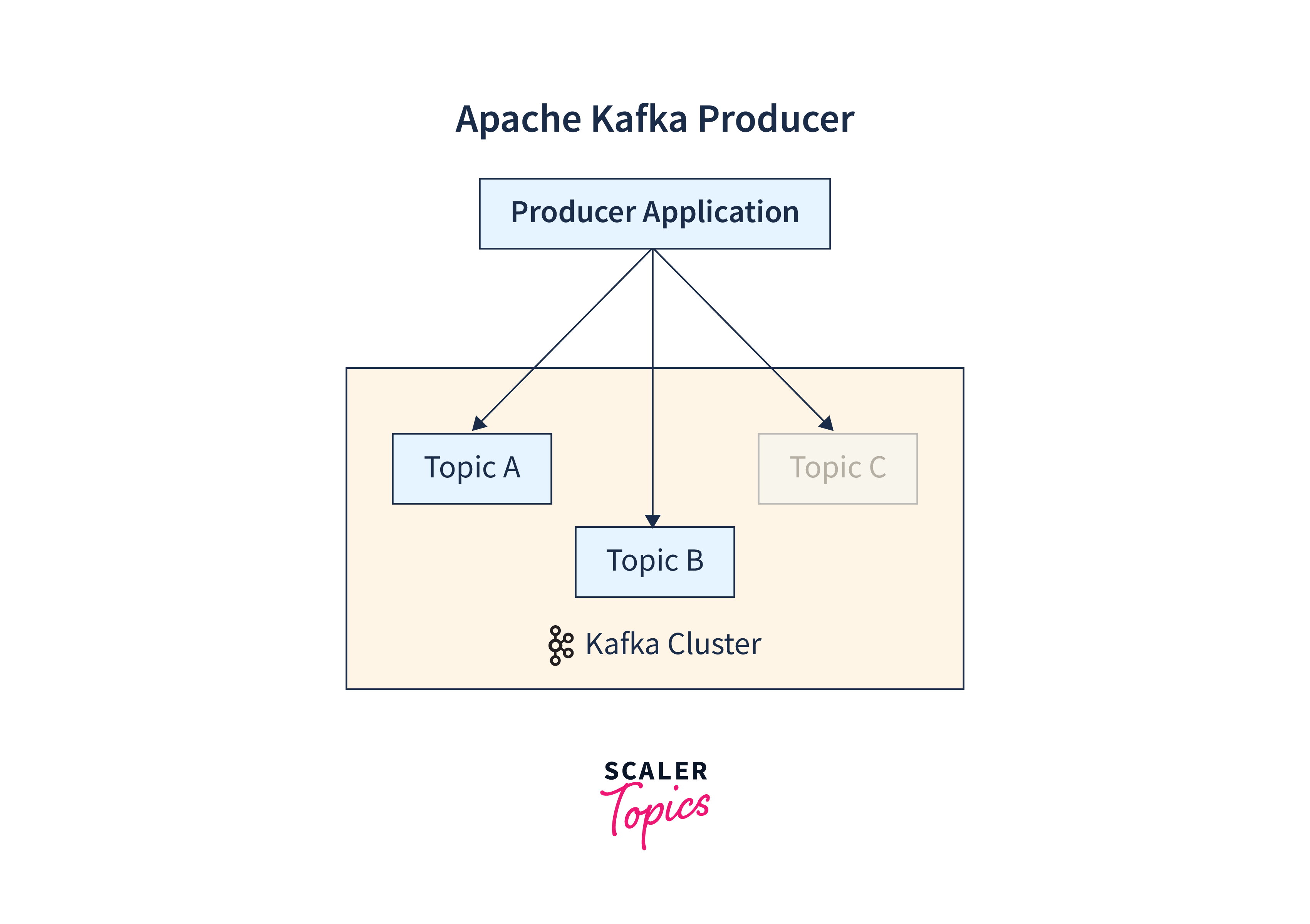
Kafka Producer Configuration
In this section of the article, we will be discussing the Kafka producer configurations and how it is affecting the Kafka producer's behavior.
The Core Configuration:
In this set of configurations, users need to bootstrap.servers property. The bootstrap.servers help the users understand the bootstraps list of defined Kafka brokers. This way, the producer is able to navigate to the Kafka cluster. An optional configuration that is part of the core configuration is the client.id. The client.id helps to identify the Kafka producer application, which allows the users to simply correlate the requests that are something for the broker having the client instance that created it. These above-mentioned settings are for Python, Go, Java, C/C++, and .NET clients.
Durability of the Message/Data records:
With the acks configuration, one can control how durable the data records would be when these messages are being written to Kafka. The acks configuration controls the criteria that state if the Kafa producer requests are defined to be complete. Its ranges as 0, 1, or all. The value of acks, when set as 1, also its default value, requires an explicit acknowledgment showcasing that the write succeeded from the partition leader. If your use case requires you to have the maximum possible throughput, then the acks value must be set as 0. This also does not guarantee the successful writes of the messages written to the Kafka broker's log, as the Kafka broker restricts even sending a response. The offset value is also not determined in this case.
When the value of acks is set as acks=all, it depicts a guarantee of the write being accepted by the partition leader along with the write being successfully replicated to every in-sync replica. For the Python, Go, C/C++, and .NET clients, this durability of messages configuration is set as per-topic configuration, which can also be extended globally via the default_topic_conf sub-configuration in C/C++ as well as default.topic.config sub-configuration in Go, Python, and .NET.
Ordering of the Message:
The messages received in the Kafka producer are written in a similar order to the broker as they were received by the Kafka producer client. Whereas when the message retries setting is enabled to the value greater than 0 ( 0 is the default value ), then the data records are reordered as now the message is retried after the following write is succeeded. For enabling the retries without reordering the message, users can set the max.in.flight.requests.per.connection setting as 1. This makes sure that only one request is sent to the broker at a given point in time. When the retries is not enabled, the Kafak broker starts to preserve the order of the message that is to be written, but this still can see certain gaps due to the individual send failures.
Batching and Compression:
To improve the throughput, Kafka producers make an attempt the collection of the sent data records into batches. However, it is only with the Java client that the user can utilize the 'batch.size' configuration for controlling the maximum size (in bytes) for each data record batch. For the batches to fill, which shall rere more time, users can make use of the linger.ms indicating the Kafak producer to delay the pushing of messages. This is how Batchng can be done in Kafka producer.
With the help of the compression.type setting, one can introduce compression in Kafka producer. Compression covers all the data record batches, enabling the larger batches to have a higher compression ratio. Users can implement the batch.num.messages configuration to define the limit over the number of data records that is, being contained in every batch. for the Go, Python, C/C++, and .NET clients.
With snappy compression, the user has to grant access to the write for the /tmp directory. But even if the users don't have the write access for the /tmp directory, when the value is set to noexec, a user could still pass the directory path for snappy as stated below:
-Dorg.serial.snappy.tempdir=/path/to/newtmp
Queuing Limits:
With the help of the buffer.memory configuration, users can limit the total memory that shall be used for collecting the unsent messages available for the Java client. Once the limit is struck, the Kafka producer starts to block the additional message that is being sent for a given time. This time period is determined by max.block.ms before an exception is raised.
To limit the total number of messages that are queued, users can utilize the queue.buffering.max.messages for transmission, messages retries, or generating the delivery reports at any defined time. Also, to limit the time that a client shall wait, users can implement the queue.buffering.max.ms configuration to fill up a batch before it is sent to the Kafka broker for further processes.
In addition, to avoid the messages being queued indefinitely, users can set a timeout via the request.timeout.ms. Before the data record can be sent, if the timeout duration expires, it gets removed from the queue, and this also throws an exception. Similar settings are observed in the Go, Python, C/C++, and .NET clients.
Let us discuss the main configuration settings offered by Kafka Producer API:
| Kafka Producer Configuration | Description |
|---|---|
| producer.type | This tells the users the Kafka producer is of which type. The two possible Kafka producer types are sync or async. |
| buffer.memory | This configuration helps to control the total amount of memory that is available to the Kafak producer for use cases like buffering. |
| value.serializer | This configuration helps the users know what value could be expected for the serializer interface. |
| client.id | Helps to identify the Kafka producer application. |
| linger.ms | If users want to reduce the number of requests coming to the Kafa log, it can utilize this configuration to set the value of linger.ms as something greater than a certain defined value. |
| key.serializer | This configuration helps users understand what the key is at the serializer interface. |
| acks | This configuration controls the criteria that state if the Kafa producer requests are defined to be complete. Its ranges as 0, 1, or all. |
| batch.size | This configuration helps to simply know the size of the buffer established. |
| bootstrap.servers | Helps to bootstrap the list of defined Kafka brokers. |
| retries | This configuration tells the producer to run again (specify with the defined value) when the Kafak producer fails. |
How Does the Producer Write Data to the Cluster?
To write the message or the data record to the topic across various partitions, Kafka Producer implements the following strategies:
- Message Keys
- Acknowledgment
Message Keys To send the message that is being pushed to the Kafka cluster via the producer, it utilizes the understanding around the key for pushing the data records in a defined order. The key ensures the Kafka Producer with two wide points, i.e., either to automatically push the data record to every partition or push data records to a defined partition only. It is only with the message or the partition keys that a defined message could be sent into the Kafka cluster in the defined manner. When the key is applied over the data record, that message shall always be pushed to the same partition every time.
But, when the partition or message key is not applied while writing the message, it could be sent in a roundtable manner. This is widely known as the process of load balancing. Across Kafka, the load balancing is implemented when the message is pushed to the Kafka topic without the keys being defined; then, it is Kafka that distributes smaller bits of the records to every partition. A message key could be anything from a string, number, or anything which helps the users to determine the message.
Below illustration shows how the Kafka Producer send the data to a topic partition via the help of message keys:
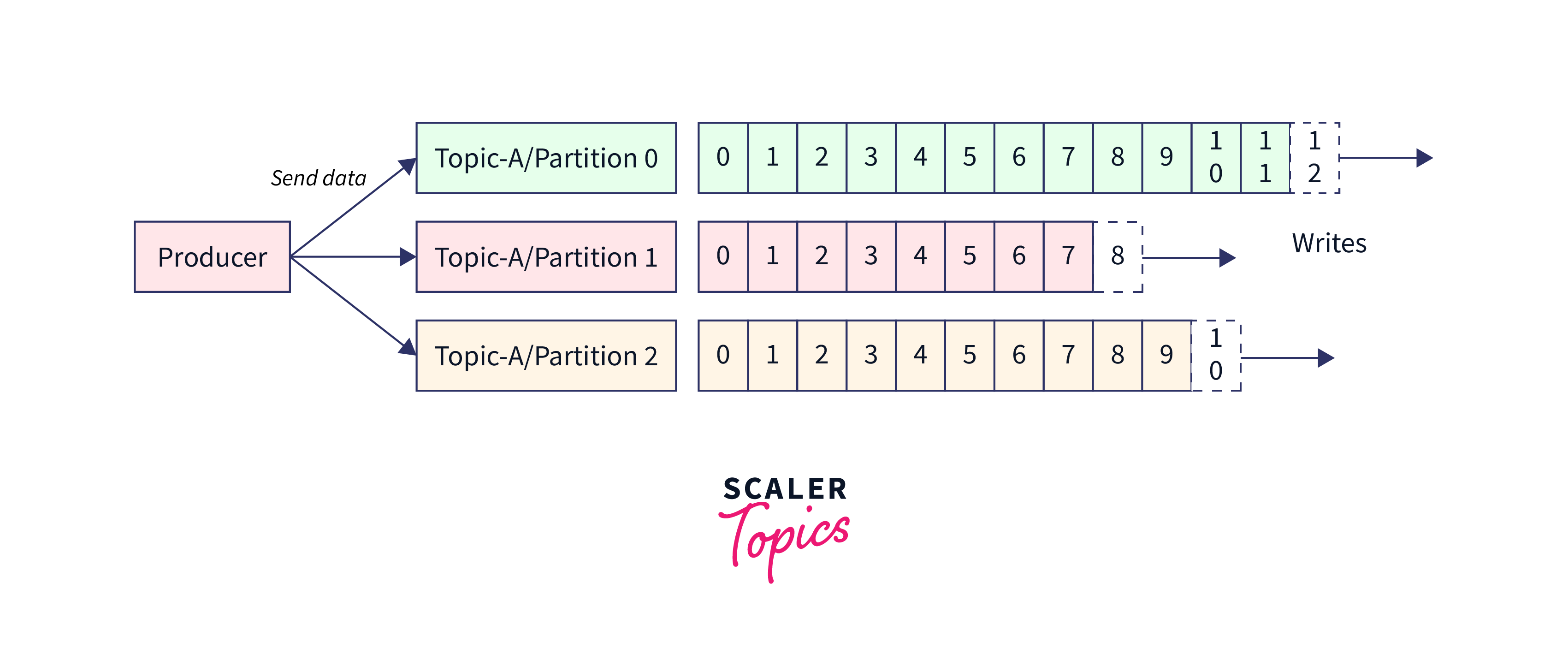
To help the users understand if a message was pushed with or without a key, the following criteria could be validated:
- When the value in the key is seen as 'key=NULL', it reflects that the message is sent without the potential value of key. Hence, it is subjected to be distributed in a roundtable manner.
- When the value in the key is seen as 'key!=NULL', it reflects that the key is reflecting with the message, and hence all data records will always be pushed and received to the same partition in the same manner.
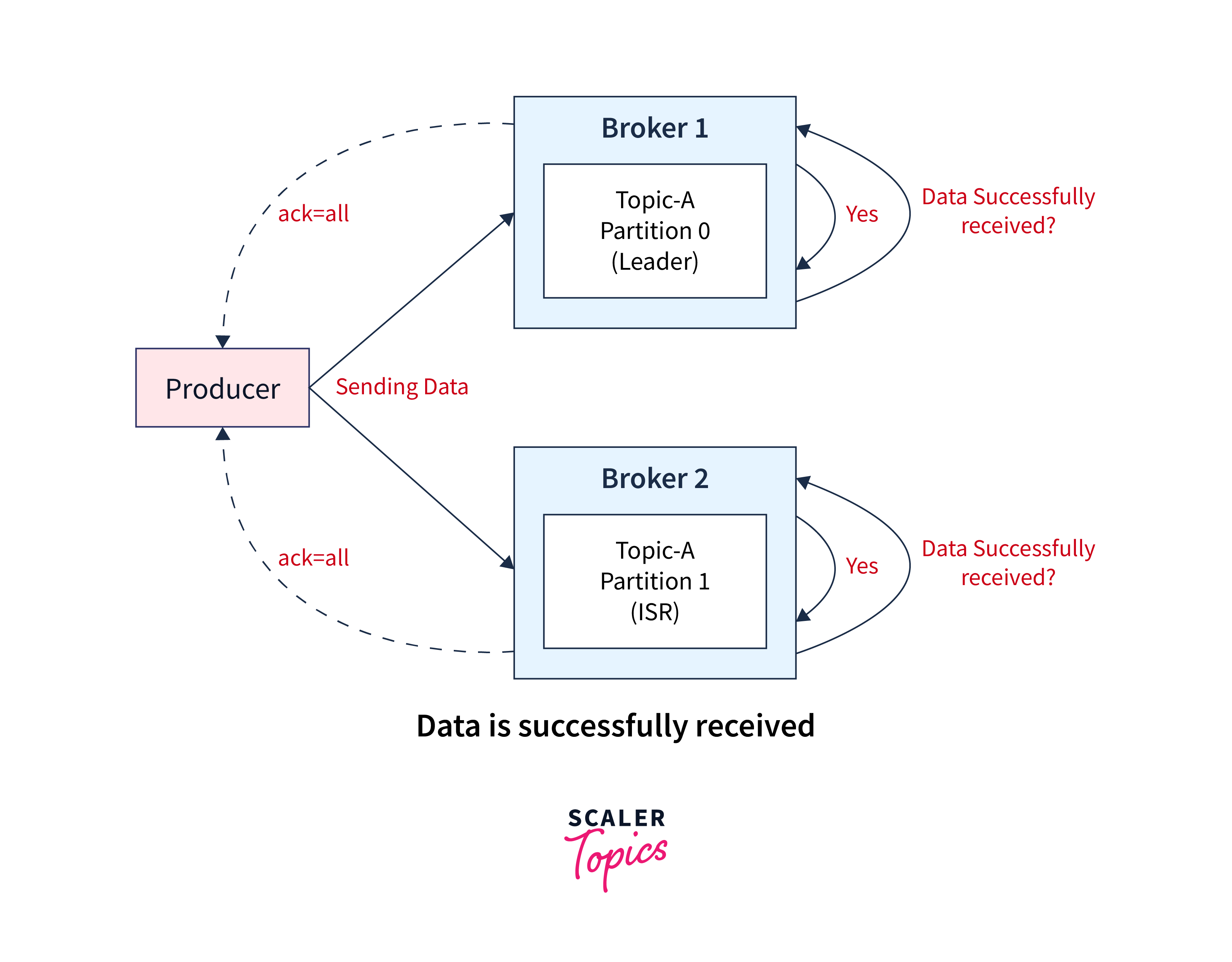
Acknowledgment When data is write to the Kafka cluster, the Kafka producer can opt for the configuration of acknowledgment for message durability. With this configuration, Kafka producer will be able to get a confirmation of the data that is being via receiving the below stated acknowledgments codes:
acks=0: When the configuration of acknowledgment is set to 0, Kafka producer can sends the data to the Kafka broker but will not wait for the acknowledgment response. This leads to potential data loss as without the confirmation response which shall let the user know that the data sent successfully to the broker or maybe the broker is down, it will then only send another one. acks=1: When the configuration of acknowledgment is set to 1, Kafka producer can sends the data to the Kafka broker and shall wait for the partition leader's acknowledgment too. Herem the partition leader shall ask the Kafka broker if the message was successfully received and then only returns feedback to the Kafka producer. In this case, there is limited data loss only. acks=all: When the configuration of acknowledgment is set to 1, Kafka producer can sends the data to the Kafka broker and the acknowledgment is received from both partition leader and their followers. When the data is successfully acknowledged, it means that the data is received successfully. In this case, no data loss is observed.
Below illustration shows how data is successfully received:
Conclusion
- The Kafka Producers as the one from where the users can publish, push messages, or writes the data records to the topics within various partitions.
- The client.id helps to identify the Kafka producer application, which allows the users to simply correlate the requests that are something for the broker having the client instance that created it.
- The key enables the Kafka Producer with two wide points, i.e., either to automatically push the data record to each partition or push data records to a defined partition only.
- key.serialize: This configuration helps users understand what the key is at the serializer interface.
- acks: This configuration controls the criteria that state if the Kafka producer requests are defined to be complete. Its ranges as 0, 1, or all.
- To avoid the messages being queued indefinitely, users can set a timeout via the request.timeout.ms.