Kafka Queues
What are Apache Kafka Queues?
In the Kafka ecosystem, we can span multiple nodes, expanding or expanding the environment. Again, we have several great systems available. In the same system, we have multiple microservices running.
When we have multiple microservices in our system, communication is very important. Communication refers to how microservices communicate internally. Now doing cross-platform apps, big data, etc.
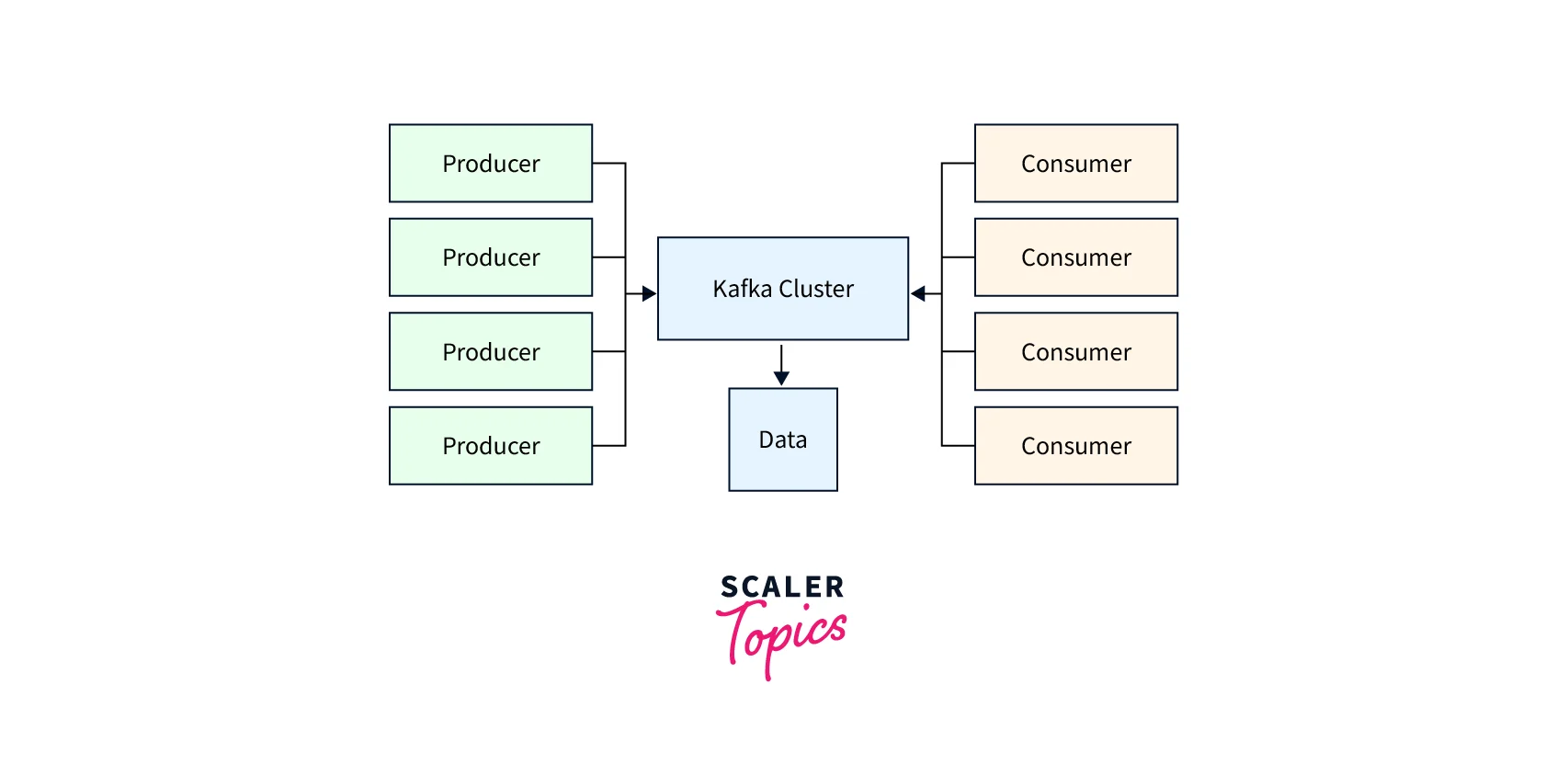
Queues come in handy when we need to communicate with various microservices or communicate with various consumers and producers. In the Kafka environment, the queue is also used as fault tolerance.
Queue
Queue-based systems are often structured such that numerous consumers process data from a queue, and the work is divided so that each consumer receives a unique set of things to process. As a result, there is no overlap, which allows the burden to be divided and allows for horizontally scalable designs.
Syntax of Kafka Queue
- To use Kafka queues, we must first comprehend the entire architecture of the Kafka streaming system. Similarly, we must understand how data moves in the Kafka context.
- We utilize it as a Kafka consumer group with several consumers in Kafka Queue. We must define the queue configuration for the Kafka environment based on the demand or necessity.
- We must specify the configuration of the number queue and configure it by the given schema. It will enable the message queuing and publish-subscribe technique in Kafka (it depends on architecture and requirements).
How does Kafka Queue Works?
In the Kafka environment, we may use the message queue notion as well as the publish and subscribe concept. We may build the queue base system in Kafka so that different Kafka consumers can handle data from the appropriate queue. The work will be distributed in Kafka in such a way that each Kafka consumer will receive a distinct set of process messages.
The following are lists of properties that might be useful for tuning the queue in the Kafka environment:
-
queued.max.requests
- The default value for this attribute is 500.
- Explanation: This attribute influences the number of requests that are queued. The way the I/O threads are handled will impact how this occurs. When network threads cease reading or receiving new requests, this should be taken into account.
-
controller.message.queue.size
- The default value for this parameter is 10.
- Explanation: The buffer size may be specified using the controller.message.queue.size attribute. The controller-to-broker channels get the same buffer size value.
-
queued.max.message.chunks
- This property's default value is 10.
- Explanation: The queued.max.message.chunks property may be used to specify how many messages, or chunks, can be buffered for consumption at one time. We can specify the value of this by the requirements. The data can be fetched by a single chunk up to the fetch.message.max.bytes limit.
-
queue.buffering.max.ms
- This property's default value is 5000.
- The time value we are specifying for the queue.buffering.max.ms attribute is as follows. While using the async mode, it would specify how long the buffered data should be held. Let's look at an example: if we set the value to 200, it will attempt to transfer the data or messages in a batch at a time of 200 Ms. It will be able to increase throughput as a result. Yet when the throughput rises, the buffering will cause the delay of the extra messages to rise as well.
-
queue.buffering.max.messages
- This property's default value is 10000
- Explanation: The number of unsent messages can be defined to help. It will be placed in the producer's queue. When we use async mode, it will take place. It is possible that the data may be lost or that the Kafka producer will be stopped.
-
queue.enqueue.timeout.ms
- The default value for this property is -1.
- Explanation: It will specify the number of messages that will be kept before they are erased. The buffer will reach the queue when we are in async mode. If we set the value to 0, it will join the queue instantly. In other words, if the queue is full, it will be dismissed. The producer will request that no blocks be placed. If the value is -1, the producer will be blocked and unable to reverse the request.
Creating Apache Kafka Queue
You require these two topics to set up an Apache Kafka queue, namely,
The messages to be processed will be contained in the Queue subject in the Apache Kafka Queue. Each message's start and end marks are stored in the Markers topic of the Apache Kafka Queue. These markers make it easier to monitor communications that require redelivery.
You must first create a standard consumer before you can start receiving messages from the most recent offset kept in Apache Kafka Queues:
- Read a message from the queue that is being processed.
- Send a start marker to the topic of the marker before Apache Kafka can detect a transmission.
- Upload the message received from the queue's position to Apache Kafka.
- The message can be processed when the identity and offset have been supplied.
- Once (and only once) the processing is complete, send an end marker to the "markers topic" along with the message offset. It is not essential to wait for a reception acknowledgment.
It is not essential to wait for a reception acknowledgment when sending an end marker to a "markers topic" because the end marker is typically just a lightweight signal that indicates the completion of processing for a batch of messages. The main purpose of the end marker is to help downstream systems determine which messages have been processed and can be safely consumed.
In this scenario, Redelivery Tracker is an Apache Kafka application that reads data from the marks queue. It also preserves a list of messages that have yet to be handled.
Kafka as a Queue
Kafka may be used as a queue by considering Kafka topics as message queues. Producers provide messages to a Kafka topic, and consumers read the messages in the order they were sent.
Kafka keeps messages in topics for a configurable duration of time or until they are explicitly destroyed. Messages can be queued in the subject until they are eaten by consumers or they expire.
It supports parallel processing, which means that several consumers can read messages from the same topic at the same time. This enables message parallel processing, which can enhance throughput and decrease processing time.
It offers message ordering guarantees, which ensure that messages are delivered to users in the order in which they were created. This is accomplished by assigning each message a unique offset that indicates its position in the queue.
Create a consumer (client), point it to a topic (or more than one, but for simplicity, let's just assume one), and then consume data from it to create a Kafka-aware application.
If one is unable to keep up with the rate of production, just start more consumers (i.e., scale out horizontally), and the workload will be spread among them. These instances may all be grouped to form the Consumer Group, a single (logical) object.
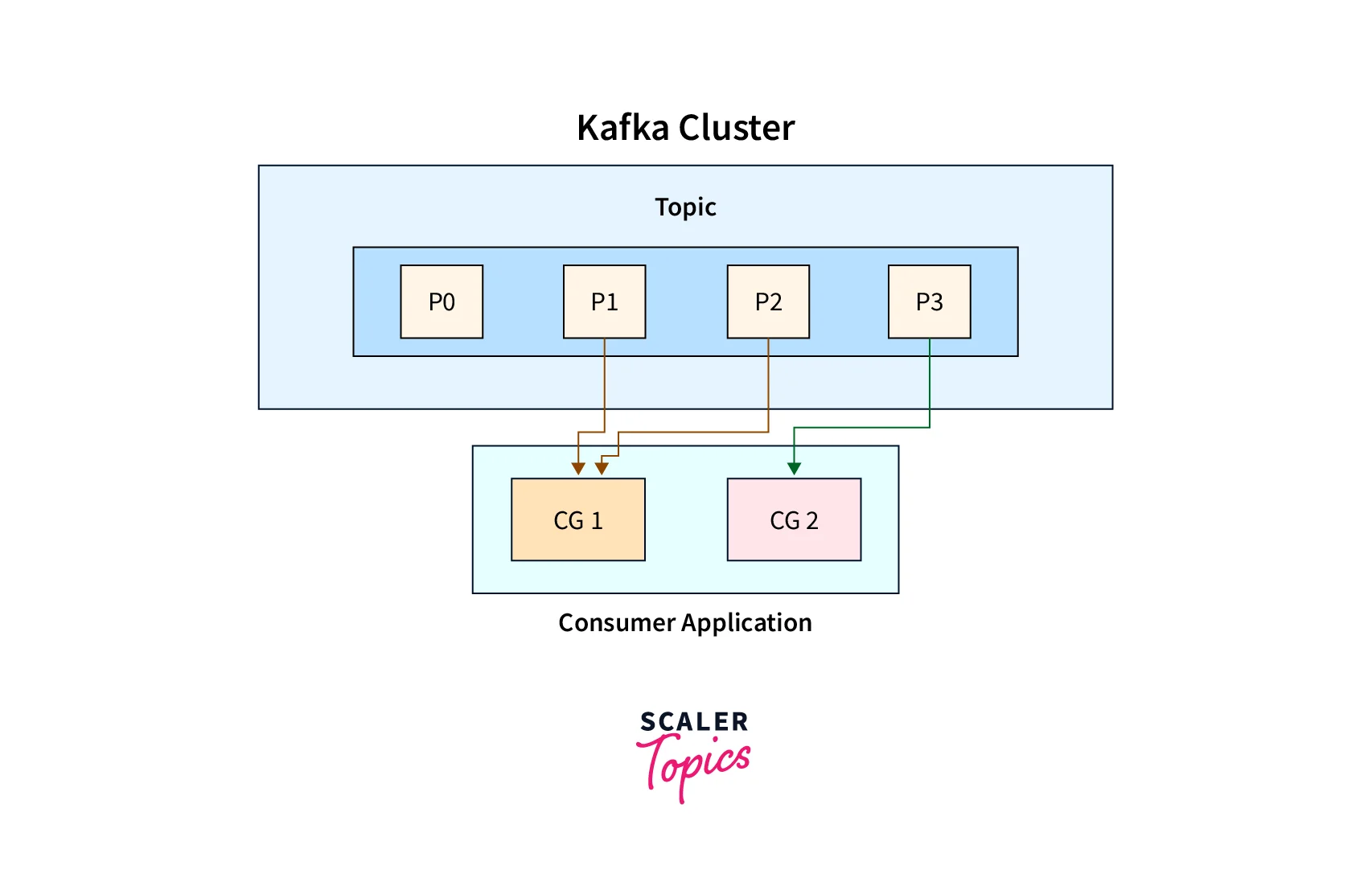
Scalability and fault tolerance are enhanced by partitioning a Kafka topic. Consumer groups enable Kafka to work as a queue since each consumer instance in a group processes data from a non-overlapping set of partitions. (within a Kafka topic).
Consumer Groups 1 and 2 (CG1 and CG2) are depicted in the graphic above as consuming from a single Kafka topic with four partitions. (P0 to P4)
Conclusion
- Queues come in handy when we need to communicate with various microservices or communicate with various consumers and producers. In the Kafka environment, the queue is also used as fault tolerance.
- Kafka duplicates data and can handle numerous subscribers. Multiple consumers can read messages from the same subject at the same time, allowing for message parallel processing.
- Kafka ensures message ordering by providing each message a unique offset that represents its position in the queue. Furthermore, in the case of a breakdown, it immediately balances customers. That is, it is more dependable than comparable texting services.
- We can use the message queue idea and publish-subscribe concept in the Kafka environment. We can create a basic queue system in Kafka so that multiple Kafka consumers can be accessed to process data from the appropriate queues.
- Tasks will be distributed across Kafka so that each Kafka consumer receives a unique set of process messages.