Configuring Zookeeper for a Kafka Cluster
Overview
ZooKeeper is a distributed coordination service that assists in the management and synchronization of distributed systems. Kafka is a framework for constructing distributed event streaming pipelines and streaming applications. Setting up a separate ZooKeeper ensemble with an odd number of nodes, specifying the ZooKeeper connection in the Kafka broker's setup, and ensuring adequate memory allocation and JVM settings are all critical when configuring ZooKeeper for a Kafka cluster. Monitoring ZooKeeper's health and performance indicators, as well as applying security measures such as ACLs, are also critical. ZooKeeper configuration and monitoring are critical for a robust and reliable Kafka cluster.
Introduction
What is Apache Kafka?
Apache Kafka is an open-source event-streaming software platform. It is a distributed, fault-tolerant, and scalable architecture for dealing with real-time data streams.
Kafka combines three critical event streaming capabilities:
- Publish and Subscribe: Producers can publish (write) streams of events to specified topics, and consumers can subscribe to (read) those topics to get the events. This publish-subscribe approach provides real-time data streaming and allows data producers and consumers to be separated.
- Storage: Kafka provides a long-term and dependable solution for storing event streams. It distributes the storage of event streams over a cluster of Kafka brokers. The events are saved to disc and repeated for fault tolerance, assuring longevity and dependability even in the face of failure.
- Stream Processing: Kafka offers real-time event stream processing, allowing developers to create apps that handle and analyze event streams in real-time or in the past. It enables filtering, transformation, aggregation, combining, and other operations, allowing real-time analytics, event-driven architectures, and reactive applications.
What is Zookeeper?
ZooKeeper is an important component of a Kafka cluster that acts as a distributed coordination service. ZooKeeper is in charge of monitoring and preserving the cluster's metadata, coordinating the operations of many nodes, and assuring the general stability and consistency of the Kafka cluster.
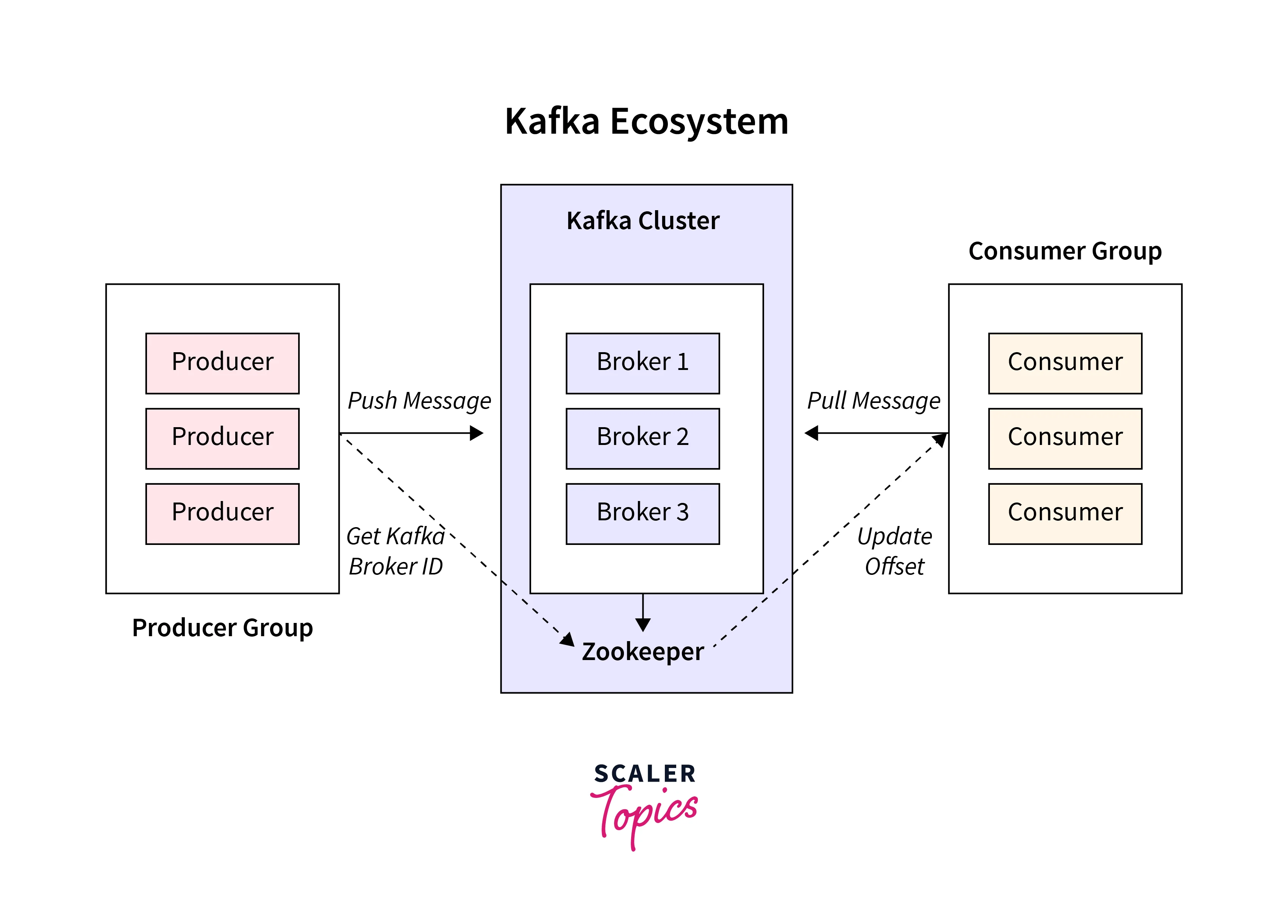
In a Kafka cluster, ZooKeeper performs the following tasks:
Cluster Coordination: ZooKeeper keeps track of the active brokers in the cluster, as well as their connectivity and state. Each broker registers with ZooKeeper, making it possible for other brokers and clients to find and connect with them.
Controller Election: ZooKeeper is utilized in the Kafka cluster to elect a controller node. The controller is in charge of partition leader election, partition reassignment, and cluster-wide metadata management.
Metadata management: ZooKeeper maintains and handles important metadata about topics, partitions, and their related leader/follower information. Brokers use ZooKeeper to receive up-to-date information and understand the condition of the cluster.
Consumer Group Management: ZooKeeper assists in the management of consumer groups in Kafka. It contains consumer group information, including offsets for each consumer group's subscribed topics. ZooKeeper is used by consumers to coordinate and track their progress in consuming messages from Kafka topics.
Notifications and Watchers: ZooKeeper has a feature called Watchers that allows Kafka clients to register for alerts when certain events occur.
Installation and Setup
Downloading and Installing ZooKeeper
Open a terminal and Launch a terminal application on your system. Navigate to the location where you want ZooKeeper to be downloaded and installed.
Using the wget or curl commands, download the ZooKeeper package. Replace version> with the actual version number to choose the appropriate version.
Using the tar command, extract the downloaded package. Version> should be replaced with the actual version number.
To make things easier, rename the extracted directory. The version should be replaced with the actual version number.
Proceed to the installation location for ZooKeeper.
Configure ZooKeeper: Copy the example configuration file and replace it required configuration changes.
To change the ZooKeeper configuration settings, open the zoo.cfg file in a text editor.
Customize the properties in the zoo. cfg file to meet your needs. Set the dataDir property to define the directory in which ZooKeeper will save its data.
Launch ZooKeeper: To start ZooKeeper, use the following command:
Check the ZooKeeper server status to confirm the installation:
Execute this command:
Configuring ZooKeeper Nodes
Before beginning the configuration, ensure that Java is installed on your machine.
Local Zookeeper Cluster configuration:
Need to set up additional ZooKeeper nodes to configure a local ZooKeeper cluster. Here are the instructions to configure a local ZooKeeper cluster:
Make a copy of the ZooKeeper configuration file: Navigate to the ZooKeeper installation directory and save zoo_sample.cfg as zoo.cfg. As an example:
Configure each ZooKeeper node as follows:
In a text editor, open the zoo.cfg file. As an example:
Specify a unique ID for each node by setting the server.<id> property.The <id> should be a number beginning with 1. As an example:
Each line in the format represents a ZooKeeper node. For example in the format: server.<id>=<hostname>:<port1>:<port2>.
Set the dataDir property to configure the data directory for each node. As an example:
Every node should have its data directory.
Make separate data directories: As indicated in the dataDir settings, create separate data folders for each ZooKeeper node. As an example:
Begin each ZooKeeper node as follows:
- For each ZooKeeper node, launch a terminal.
- Navigate to the installation location for ZooKeeper.
- Use the following command to start the ZooKeeper server:
Check the cluster's configuration:
- Navigate to the ZooKeeper installation location in a terminal.
- To check the status of each node in the cluster, use the following command:
Each node will run on its port and have its data directory.
Creating a ZooKeeper Cluster
Setting Up Multiple ZooKeeper Nodes
To construct a ZooKeeper cluster, you must install numerous ZooKeeper nodes. The following are the steps for establishing a ZooKeeper cluster:
-
Download and install ZooKeeper on each machine that will act as a ZooKeeper node. Make sure to use the same version of ZooKeeper on all nodes.
-
Configure ZooKeeper properties:
- Navigate to the installation location of ZooKeeper on each node.
- Make a copy of the zoo_sample.cfg file and rename it zoo.cfg. This will be the configuration file for each node.
- Open the zoo.cfg file with a text editor.
- Set the dataDir attribute to a unique path where each ZooKeeper node will keep its data. As an example:
- Other characteristics, such as clientPort, which determines the port for client connections, and advanced settings such as tickTime, initLimit, and syncLimit, can be configured as needed. Make sure that each node has its own clientPort.
-
Provide separate IDs to each node:
- Each node in the cluster must be allocated a unique ID.
- Develop a file called myid in each node's data directory.
- The content of the myid file should contain the node's unique ID. Node 1 will, for example, have ID 1, node 2 will have ID 2, and so on. Check that the IDs correspond to the server IDs supplied in the zoo.cfg file.
-
Start ZooKeeper on each node as follows: Start the ZooKeeper server on each system by running the relevant command based on your platform.
-
Check the cluster's configuration: To verify the status of each node in the cluster, use the following command on any node:
Setting up a ZooKeeper Ensemble
An ensemble is a collection of 2n + 1 ZooKeeper servers, where n is any positive integer bigger than zero. Because there are an odd number of servers, ZooKeeper may conduct majority elections for leadership.
When using an external ZooKeeper ensemble, you must be a little more careful than in the Getting Started example.
The difference is that instead of just setting up the servers, one must first configure them to recognize and communicate with one another. As a result, the first zoo.cfg file might appear like this:
initLimit
Time in ticks it takes for followers to connect and sync with a leader. In this case, there are 5 ticks, each of which is 2000 milliseconds long, so the server may have to wait up to 10 seconds to connect and sync with the leader.
syncLimit
Time in ticks it takes for followers to sync with ZooKeeper. Followers who fall too far behind a leader will be discarded.
server.X
These are the IDs and locations of all servers in the ensemble, as well as the ports via which they interact. The server ID must also be saved in the dataDir>/myid file, which must be placed in the dataDir of each ZooKeeper instance. Because the ID identifies each server, in this situation, you would create the file /var/lib/zookeeperdata/1/myid with the content "1".
Integration with Kafka
Configuring Kafka to Use ZooKeeper
Download the Apache Kafka distribution package and unpack it to a specific location on your machine.
Set up Kafka to utilize ZooKeeper:
- Navigate to the installation location for Kafka.
- In a text editor, open the config/server.properties file.
- Locate and set the zookeeper.connect the property to the ZooKeeper connection string. The connection string should have the following format: zookeeper_host>:zookeeper_port>.As in example:
- If your ZooKeeper ensemble is operating on many nodes, use commas to separate all host: port combinations. As an example:
- Begin with the following Kafka brokers: Start the Kafka brokers using the following command:
Check the Kafka-ZooKeeper integration:
- Examine the Kafka broker logs for any issues or warnings linked to connecting to ZooKeeper.
- To communicate with Kafka and conduct actions such as creating topics, generating messages, and consuming messages, use the Kafka command-line tools or Kafka client libraries.
ZooKeeper will be utilized in the Kafka cluster for cluster coordination, metadata storage, leader election, and other key functions.
Setting ZooKeeper Connection Properties in Kafka
Apache Zookeeper is a centralized service that provides distributed synchronization by keeping configuration information. ZooKeeper is used in Kafka to manage clusters and keep topic information synchronized.
Some settings provide both a global default and topic-level overrides. The topic level attributes are in CSV format (for example, "xyz.per.topic=topic1
Launch the server.properties file with the parameters:
Explanation:
- zookeeper.connect: No default value. This is a comma-separated value representing the Zookeeper connection in the form of a hostname
string. The use of several connections maintains the Kafka cluster's dependability and continuity. When a node dies, Zookeeper utilizes the chroot path (/chroot/path) to make the data accessible via that path. This allows the Zookeeper cluster to be accessible to various Kafka clusters. This route must be defined before the Kafka cluster can be started, and consumers must use the same string. - zookeeper.connection.timeout.ms: The default value is 6000. This is the maximum time the client will wait while attempting to connect to Zookeeper.
- zookeeper.sync.time.ms: The default value is 2000. This is the period when a Zookeeper follower can support their Zookeeper leader.
- zookeeper.session.timeout.ms: The default value is 6000. Session timeout indicates that if a heartbeat from the server is not received within this period, the session is deemed dead. This parameter is critical because if it is too lengthy and the server is down, the entire system will fail.
Best Practices for ZooKeeper Configuration
Separating ZooKeeper and Kafka Nodes
Here are some best practices for ZooKeeper settings when separating ZooKeeper and Kafka nodes:
- Odd number of ZooKeeper nodes: To establish a majority for consensus, deploy an odd number of ZooKeeper nodes (e.g., 3, 5, 7). This guarantees fault tolerance and high availability.
- Quorum configuration: In the zoo.cfg file, give the list of ZooKeeper nodes and their IP addresses to configure the ZooKeeper ensemble. Ensure that each ZooKeeper node in the ensemble is aware of the other nodes in the ensemble.
- Secure Zookeeper: sensitive data within ZooKeeper by using security features such as SSL/TLS encryption, authentication, and access control methods.
- Configure ZooKeeper client connections: Update the Kafka broker configuration file (server.properties) to point to the ZooKeeper ensemble. Set the zookeeper.connect property to a comma-separated list of ZooKeeper nodes, containing their IP addresses and ports.
- Daily Backups: Establish a backup mechanism for the ZooKeeper data directory. Back up transaction logs and snapshots regularly to avoid data loss in the event of a breakdown.
Memory Allocation and JVM Settings
- JVM settings: Fine-tune the JVM parameters for ZooKeeper based on the needs of your deployment. To enhance speed, optimize heap size, garbage collector settings, and other important JVM parameters.
- Estimate memory prerequisites: Based on the workload and data amount handled by ZooKeeper, determine memory requirements. Consider the number of nodes, znode data size, and the number of concurrent client connections.
- Allocate heap capacity: In the JVM settings, select a suitable heap memory amount for ZooKeeper by defining the -Xmx and -Xms arguments. The -Xmx option defines the maximum heap size, whereas the -Xms option determines the beginning heap size. Allocate memory by the needs, ensuring that adequate memory is available for the demand.
- Modify the file descriptor limits to ensure ZooKeeper can manage the needed number of client connections. If necessary, change the ulimit settings on the operating system to increase the limit.
- Consider utilizing off-heap memory: Consider using off-heap memory for ZooKeeper in higher deployments or circumstances with high memory needs. Off-heap memory allocation may ease heap tension and enhance performance. Off-heap memory for ZooKeeper may be allocated using tools such as Apache BookKeeper's ByteBufferAllocator.
Monitoring and Metrics
Monitoring and collecting metrics from ZooKeeper is critical to ensuring its health, performance, and stability.
-
Monitor key metrics: Keep track of key indicators to obtain insight into ZooKeeper's behavior. Some critical metrics include:
- Monitoring the status and availability of individual ZooKeeper nodes.
- Latency: To maintain optimal performance, monitor the average and maximum latency of ZooKeeper processes.
- Throughput: Determine the workload and capacity by measuring the pace of ZooKeeper queries and answers.
- Connection count: Keep an eye on the number of active client connections for any strange patterns or spikes.
- File descriptor utilization: Monitor file descriptor utilization to ensure ZooKeeper can manage the necessary number of client connections.
-
Use health checks: Use health checks to evaluate ZooKeeper's functioning regularly. Verifying the state of ZooKeeper nodes, determining the ensemble's consensus, and guaranteeing data consistency among nodes are all examples of health checks.
-
Metrics collection and visualization: Collect and aggregate ZooKeeper metrics in a centralized repository or monitoring system. To acquire insights into ZooKeeper's behavior and performance patterns over time, use visualization tools like as dashboards or graphs.
-
Monitor system resources: Apart from ZooKeeper-specific data, keep an eye on underlying system resources including CPU consumption, memory utilization, disc I/O, and network traffic. Identifying resource bottlenecks or abnormalities can assist in identifying issues that may influence ZooKeeper's performance.
-
Track ZooKeeper logs: ZooKeeper logs should be monitored for any warning or error signals. Log analysis can provide important information regarding possible problems or misconfigurations.