Mastering Kafka Essential Best Practices for Optimal Performance
Overview
Mastering Kafka involves becoming proficient in utilizing Apache Kafka, an open-source distributed event streaming platform. Kafka serves as a high-throughput, fault-tolerant, and scalable solution for handling real-time data streams. To master Kafka, one must grasp its core concepts, such as topics, partitions, brokers, and producers/consumers, and understand how they interact within the Kafka ecosystem. Efficiently configuring Kafka clusters, ensuring data replication for reliability, and optimizing performance are crucial aspects of expertise.
Introduction
Brief overview of Apache Kafka
Apache Kafka, developed by the Apache Software Foundation, is a distributed streaming platform that operates as open-source software. Its primary purpose is to effectively manage and process large amounts of data streams in real time. Due to its ability to scale seamlessly and maintain resilience in the face of failures, Kafka has gained significant popularity as a preferred solution for constructing fault-tolerant data pipelines and event-driven applications.
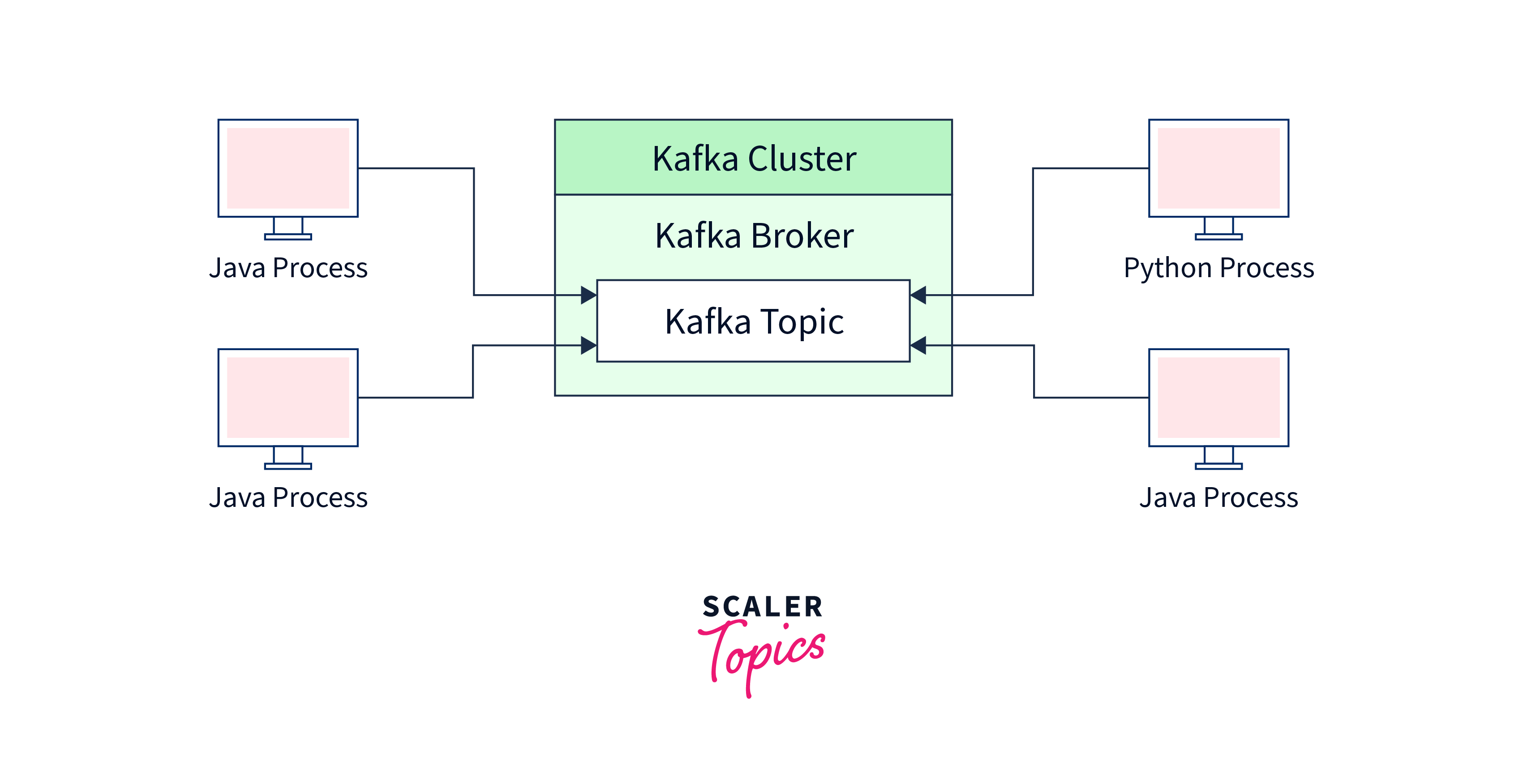
Importance of best practices in Apache Kafka
- Performance and Scalability: Kafka is designed to handle high-throughput, real-time data streams. Following best practices ensures that Kafka clusters are configured optimally, replication factors are set appropriately, and partitions are balanced, leading to improved performance and scalability. Properly tuned Kafka deployments can handle large volumes of data without compromising on speed and efficiency.
- Data Integrity and Reliability: Best practices in Kafka emphasize data replication and fault-tolerance mechanisms. By configuring replication and ensuring proper topic partitioning, data integrity and reliability are enhanced. This means that even if some brokers fail or encounter issues, the data can still be accessed and processed, maintaining consistency in the event streaming system.
- Security: Kafka deals with sensitive data in many applications, making security a paramount concern. Best practices guide administrators to set up secure communication channels, implement proper authentication and authorization mechanisms, and protect against potential threats like unauthorized access and data breaches.
- Resource Management: Kafka can be resource-intensive, especially when dealing with high-velocity data. Adhering to best practices helps in managing resources efficiently, such as optimizing disk usage, memory allocation, and network utilization, ensuring the system runs smoothly without unnecessary bottlenecks.
- Compatibility and Upgrades: As Kafka evolves, new versions are released with improvements and bug fixes. Following best practices ensures that the implementation remains compatible with future updates, making the upgrade process smoother and minimizing the risk of unexpected issues.
- Monitoring and Troubleshooting: Effective monitoring is vital for understanding the health and performance of Kafka clusters. Best practices recommend setting up appropriate monitoring tools and defining relevant metrics to identify potential bottlenecks or anomalies. This, in turn, enables prompt troubleshooting and proactive maintenance.
- Integration and Ecosystem: Kafka is often part of a larger data ecosystem, where data is processed, analyzed, and transformed using various tools like stream processing frameworks (e.g., Apache Flink, Spark Streaming) and data stores. Adhering to best practices in Kafka ensures seamless integration with these tools and smooth data flow within the broader architecture.
- Ease of Management: Implementing best practices in Kafka simplifies the overall management of the system. It leads to a consistent configuration across clusters, reduces the likelihood of misconfigurations, and makes it easier for administrators to maintain and support the infrastructure.
Understanding Kafka
What is Apache Kafka?
Apache Kafka is an open-source distributed streaming platform that provides a scalable, fault-tolerant, and high-throughput system for handling real-time data feeds. It was originally developed at LinkedIn and later became an Apache Software Foundation project.
At its core, Kafka is designed to handle the publish-subscribe model, where producers publish messages to specific topics, and consumers subscribe to those topics to receive the messages. It acts as a highly durable and fault-tolerant storage system, storing and replicating the published messages across a cluster of servers called brokers.
Kafka architecture and components
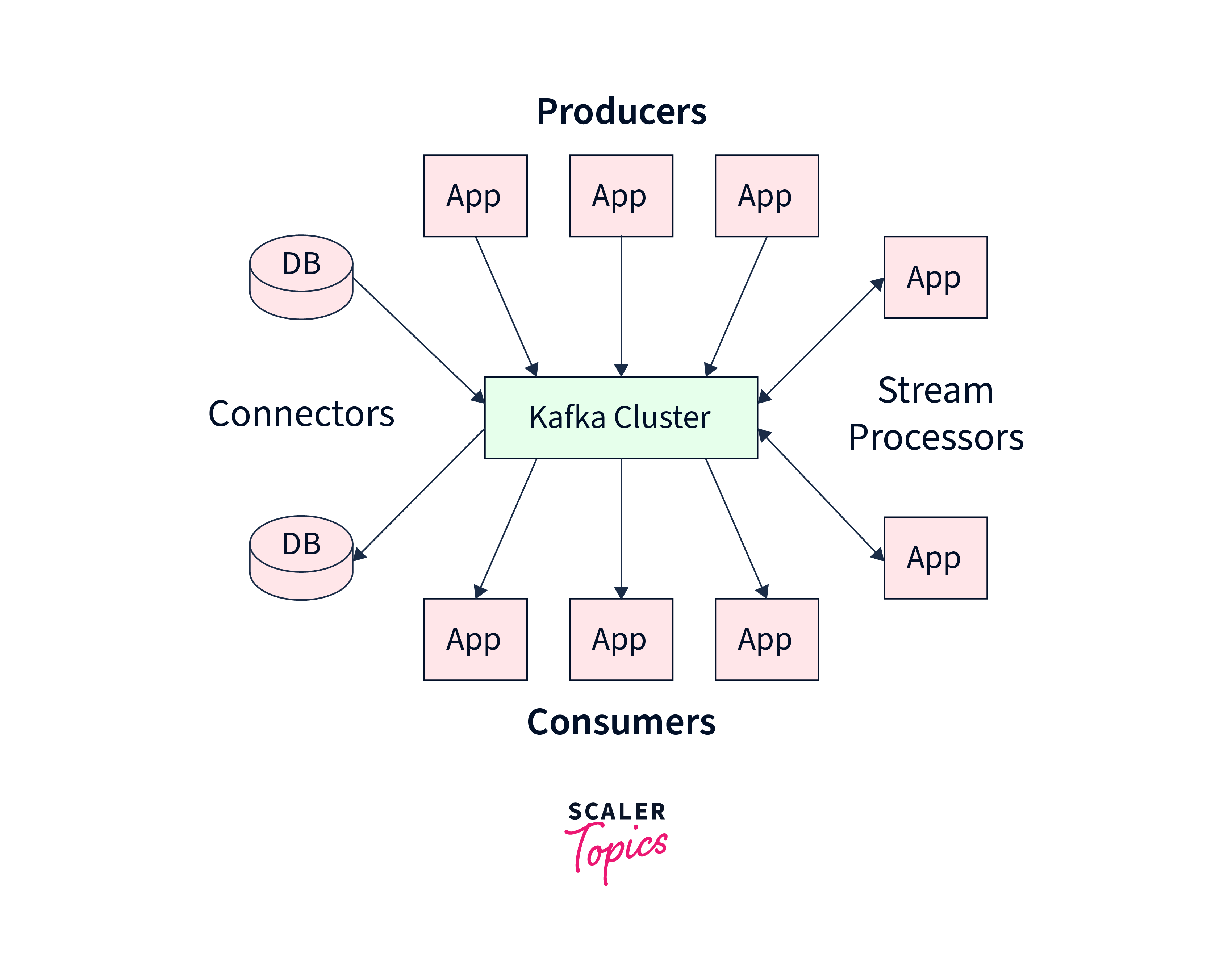
Apache Kafka is a distributed event streaming platform with a unique architecture that allows it to handle high-throughput, real-time data streams efficiently. The Kafka architecture consists of the following main components:

Broker: A Kafka cluster consists of one or more brokers, which are individual instances responsible for storing and managing data. Each broker is a server that hosts Kafka topics and partitions. Brokers work together to form a distributed and fault-tolerant system.
Topic: A topic is a category or feed name to which messages are published. It represents a stream of records in Kafka. Producers write data to a topic, and consumers read data from it. Topics are divided into partitions to enable parallel processing and scalable storage.
Partition: Each topic is divided into multiple partitions. Partitions are the basic unit of parallelism in Kafka. They allow data to be distributed across multiple brokers and processed in parallel. Each partition is an ordered, immutable sequence of records.
Producer: Producers are applications or processes that publish data to Kafka topics. They write messages to specific topics, and Kafka handles the distribution of messages to partitions within those topics.
Consumer: Consumers are applications or processes that read and process data from Kafka topics. They subscribe to one or more topics and read messages from the partitions of those topics. Each consumer keeps track of its position in each partition with an offset, allowing it to control what data it consumes.
Consumer Group: Consumers reading from a topic can be organized into consumer groups. Each consumer within a group processes a subset of the partitions of the subscribed topics. This allows for load balancing and scalability, as multiple consumers can work together to process messages in parallel.
Zookeeper: Zookeeper is used for coordination and management within Kafka clusters. It maintains metadata about brokers, topics, partitions, consumer groups, and their corresponding offsets. Zookeeper helps in leader election for partitions and keeps track of the health of the Kafka cluster.
Connectors: Kafka Connect is a framework for easily and reliably integrating Kafka with other data systems. Connectors are plugins that facilitate the movement of data between Kafka topics and external data sources or sinks, enabling seamless integration with databases, file systems, and other systems.
Typical Kafka use cases
Apache Kafka is a versatile event streaming platform with a wide range of use cases across various industries. Some typical Kafka use cases include:
- Real-Time Event Streaming:
Kafka is commonly used to stream and process real-time events, such as log data, telemetry data from IoT devices, user interactions, and application metrics. It enables efficient, low-latency data ingestion and processing, making it suitable for event-driven architectures.
- Log Aggregation:
Kafka serves as a central hub for collecting logs generated by applications and services in a distributed system. By aggregating logs from multiple sources, Kafka simplifies log management, analysis, and debugging.
- Data Integration:
Kafka facilitates data integration between various systems and applications. It acts as a reliable data pipeline, allowing seamless and scalable data movement across different components of the architecture.
- Microservices Communication:
In microservices architectures, Kafka acts as a communication channel between services. It allows decoupling of services, enabling them to exchange messages and events efficiently without direct dependencies.
- Event Sourcing:
Kafka can be used as an event sourcing mechanism, where all changes to the state of an application are captured as events in topics. This approach enables rebuilding application state by replaying events, aiding in data consistency and auditability.
- Metrics Monitoring:
Kafka can be employed to collect and process metrics data from various sources. It enables real-time monitoring, alerting, and analytics, helping organizations gain insights into the performance of their systems.
- Stream Processing:
Kafka can be integrated with stream processing frameworks like Apache Flink or Spark Streaming to perform real-time data analytics, transformation, and enrichment. This allows organizations to derive valuable insights from data as it arrives.
- IoT Data Ingestion:
With its ability to handle large-scale data streams, Kafka is well-suited for ingesting and processing data from Internet of Things (IoT) devices. It enables real-time analysis of sensor data and facilitates immediate actions based on the insights gained.
- Commit Log for Distributed Systems:
Kafka's commit log-like structure makes it an excellent choice for building distributed systems. It ensures that data is durably stored and can be reliably replicated across multiple nodes.
- Machine Learning Pipelines:
Kafka can be used to build real-time machine learning pipelines. Data scientists can ingest data into Kafka topics, and then stream that data to machine learning models for training and real-time inference.
Kafka Producer Best Practices
Here are some Kafka producer best practices:
- Batching and Compression:
Producers can improve throughput by batching multiple records into a single message before sending it to Kafka. Additionally, enabling compression for batches can reduce network overhead and storage costs.
- Use Asynchronous Send:
Use asynchronous send mode for the producer to maximize throughput. This allows the producer to continue processing and sending new records without waiting for acknowledgment from Kafka.
- Message Key Selection:
When possible, choose an appropriate message key that helps in partitioning and ensures related records go to the same partition. This can help maintain message order within partitions and improve data locality for certain use cases.
- Partitioning Strategy:
Select a suitable partitioning strategy to evenly distribute data across partitions. The default partitioner uses a hash of the message key, but custom partitioners can be used for more specific partitioning requirements.
- Producer Buffer Size:
Adjust the producer buffer size appropriately based on the memory available and expected message throughput. This ensures the producer can efficiently accumulate messages before sending them in batches.
- Acknowledge Mode:
Configure the acknowledge mode based on the desired level of reliability. For example, using the "acks" configuration, you can choose to wait for acknowledgment from all replicas or a subset of replicas before considering the message sent.
- Retries and Timeout Settings:
Configure appropriate values for message retries and request timeouts to handle transient errors. This ensures that messages are eventually sent successfully even in the presence of network hiccups.
- Error Handling:
Implement proper error handling and logging in the producer code. Understanding and handling errors gracefully helps in diagnosing issues and maintaining system stability.
- Monitoring and Metrics:
Set up monitoring and metrics to track producer performance and health. Utilize Kafka's built-in metrics or integrate with monitoring systems to gain insights into producer behavior.
- Producer Partition Caching:
Consider using producer partition caching to minimize the overhead of partition lookups, especially if the producer sends records to the same topic-partition frequently.
- Producer Configuration Tuning:
Fine-tune various producer configurations, such as batch size, linger time, and buffer memory, based on the specific use case and wor**kload. 12. Handle Throttling:
Be mindful of potential broker or network throttling. If the producer is sending a large volume of data, ensure that the Kafka cluster and network infrastructure can handle the load.
Kafka Consumer Best Practices
Here are some Kafka consumer best practices:
- Consumer Group Management: Group consumers based on their functionality and processing needs. Each consumer group processes a subset of partitions, enabling parallel processing and load balancing. Avoid using a single consumer for all partitions, as it can limit scalability.
- Enable Auto Commit Wisely: Choose the appropriate auto-commit mode (enable or disable) based on your application's requirements. Automatic commits can result in potential message duplication in case of failures. Consider using manual commits for better control over offsets.
- Monitor Lag and Offsets: Regularly monitor consumer lag, which indicates the difference between the latest produced messages and the messages consumed by consumers. Ensure that consumers are not falling too far behind to avoid data processing delays.
- Handle Rebalances Gracefully: Consumers in a group may undergo rebalancing when new consumers join or leave the group. Prepare your application to handle rebalancing gracefully to avoid interruptions and data processing issues.
- Offset Management and Error Handling: Handle offsets carefully to ensure that data is not skipped or processed more than once. Implement proper error handling to deal with processing failures and ensure that offsets are committed correctly.
- Batch Fetching and Processing: Use batch fetching and processing to reduce the number of requests made to the Kafka broker, which can improve overall performance and reduce network overhead.
- Consumer Tuning: Fine-tune consumer configuration settings, such as fetch min and max bytes, max poll records, and fetch max wait time, based on the expected workload and message size to optimize consumer performance.
- Use Seek to Re-process Messages: In certain scenarios, you may need to re-process messages from specific offsets. Use the seek method to reset the consumer's position to a particular offset for re-processing.
- Avoid Long-running Processing: Try to avoid performing time-consuming operations within the consumer loop, as this can affect the consumer's ability to keep up with incoming messages.
- Graceful Shutdown: Implement a graceful shutdown mechanism for consumers to ensure that they complete processing their current batch of messages before shutting down. This helps avoid data loss and ensures clean resource release.
- Partition Assignment Strategies: If using custom partition assignment strategies, thoroughly test and evaluate their behavior to ensure that partitions are evenly and efficiently distributed among consumers.
- Monitor Consumer Lag: Keep a close eye on consumer lag to identify any potential bottlenecks or issues in your consumer application. This helps you proactively address problems and maintain the system's health.
Kafka Broker and Cluster Best Practices
Here are some Kafka Broker and Cluster best practices:
- Hardware and Resource Planning:
- Choose hardware that aligns with your workload and performance requirements. Consider factors such as CPU, memory, disk speed, and network bandwidth.
- Allocate sufficient resources to each broker to handle the expected message throughput and storage needs.
- Monitor resource usage regularly to identify potential bottlenecks and scaling needs.
- Replication Factor:
- Configure an appropriate replication factor for each topic based on the desired level of data redundancy and fault tolerance. A replication factor of at least 3 is recommended to handle broker failures.
- Partition Count:
- Determine an optimal number of partitions for each topic, considering the rate of data ingestion, consumer parallelism, and cluster size. Avoid having too few or too many partitions, as it can impact performance.
- Network Configuration:
- Set up high-bandwidth and low-latency network connections between brokers to ensure efficient communication and data replication.
- Enable encryption for secure data transmission, especially in multi-data-center environments.
- Disk Management:
- Use high-performance disks, such as SSDs, to handle disk-intensive workloads effectively.
- Monitor disk usage and plan for adequate storage capacity to avoid running out of space.
- Monitoring and Alerting:
- Implement comprehensive monitoring for Kafka brokers and the entire cluster. Monitor key metrics like CPU, memory, disk usage, and network traffic.
- Set up alerts to notify administrators of any abnormal conditions or potential issues.
- JVM and Garbage Collection (GC):
- Tune the Java Virtual Machine (JVM) settings, including heap size, to match the available memory and workload requirements.
- Choose an appropriate Garbage Collection (GC) algorithm and configuration to minimize GC pauses and improve overall performance.
- Maintenance and Upgrades:
- Plan and schedule maintenance tasks and upgrades during low-traffic periods to minimize disruption.
- Test upgrades in a staging environment before deploying them to the production cluster.
- Kafka Broker Configurations:
- Review and optimize Kafka broker configurations, such as maximum message size, retention policies, and socket buffer sizes, based on your specific use case and workload.
- Zookeeper Best Practices:
- Maintain a well-configured and stable Zookeeper ensemble, as Zookeeper plays a critical role in Kafka cluster coordination.
- Monitor Zookeeper's health and performance to ensure it remains stable and available.
- Disaster Recovery and Backup:
- Implement a disaster recovery plan, including regular backups of data and configurations to prevent data loss in the event of failures.
- Security Best Practices:
- Follow security best practices to protect your Kafka cluster and data from unauthorized access or tampering.
Kafka Monitoring Best Practices
Monitoring is crucial for maintaining the health, performance, and stability of a Kafka cluster. Here are some Kafka monitoring best practices to ensure effective monitoring:
-
Comprehensive Metrics: Monitor various Kafka metrics, including broker health, message throughput, disk usage, network traffic, partition status, and consumer lag. Comprehensive metrics provide insights into the overall system performance.
-
Real-Time Alerts: Set up real-time alerts based on predefined thresholds for critical metrics. Alerts can notify administrators immediately of any abnormal conditions or potential issues that require attention.
-
Centralized Monitoring: Use a centralized monitoring system to collect, store, and visualize Kafka metrics. This allows for easy analysis and correlation of data across multiple brokers and clusters.
-
Historical Monitoring: Store historical metrics data for trend analysis and capacity planning. This helps in identifying long-term performance patterns and understanding resource utilization trends.
-
Retention Policies for Monitoring Data: Set appropriate retention policies for monitoring data to balance storage needs with the ability to analyze historical trends effectively.
-
Monitor Zookeeper: Keep a close eye on the health and performance of the Zookeeper ensemble used by Kafka for cluster coordination.
-
Performance Baselines: Establish performance baselines for critical metrics to understand the normal behavior of the Kafka cluster. Deviations from baselines can indicate potential issues.
-
Custom Metrics: Consider creating custom metrics to track specific application-specific performance indicators that are relevant to your use case.
-
Distributed Tracing: Implement distributed tracing to gain insights into message flow and latencies across the Kafka cluster and its connected systems.
-
Proactive Maintenance: Use monitoring data proactively to identify potential performance bottlenecks, resource limitations, or upcoming capacity issues. Take preventive measures to address these before they become critical.
-
Integration with Alerting Systems: Integrate Kafka monitoring with an alerting system to ensure that the right stakeholders are notified promptly when issues arise.
-
Monitor Consumers: Monitor the lag of consumer groups to ensure that consumers are processing data efficiently. Identify and address consumer-related issues that could impact data processing.
-
Monitor Connectors: If using Kafka Connect, monitor the performance and status of connectors, as monitoring Kafka Connect connectors involves tracking the performance, status, and health of the plugins responsible for data movement between Kafka and external systems.
Conclusion
- Event Streaming Powerhouse: Kafka is a powerful distributed event streaming platform designed for handling real-time data streams efficiently.
- Core Concepts: Master the core concepts of Kafka, including topics, partitions, brokers, producers, consumers, and consumer groups.
- Scalability and Fault-Tolerance: Understand how Kafka achieves scalability and fault-tolerance through replication and partitioning.
- Optimizing Performance: Efficiently configure Kafka clusters, batching, compression, and tuning to achieve high performance and low latency.
- Integration and Ecosystem: Integrate Kafka with other systems, such as stream processing frameworks (e.g., Flink, Spark) and data stores, to build robust data pipelines.
- Security and Administration: Implement robust security measures and monitoring to safeguard Kafka clusters, and master Kafka administration tasks.
- Real-Time Analytics: Utilize Kafka for real-time analytics, processing, and machine learning pipelines.
- Microservices and IoT Integration: Apply Kafka as a communication hub for microservices and handle IoT data ingestion and processing.
- Log Aggregation and Monitoring: Use Kafka for log aggregation and efficient monitoring of distributed systems.
- Data Integration: Kafka serves as a reliable data integration tool, facilitating seamless movement of data across applications and systems.
- Event Sourcing and Commit Log: Employ Kafka for event sourcing and maintaining a durable commit log for distributed systems.