Mastering the Kafka Connect API
Overview
This article offers an overview of the Kafka Connect API, a powerful data integration tool in Apache Kafka. It covers the basics, key components, and APIs, as well as its role, connector types, and plugin usage. The article also discusses the architecture, key concepts, and provides a step-by-step guide for setting up and using the API.
Brief Overview of Apache Kafka
Apache Kafka is a distributed streaming system that allows you to manage real-time data flows. It has high throughput and low latency, making it ideal for real-time event streaming systems. Kafka runs as a cluster on numerous machines spread across multiple datacenters. The cluster divides data into topics, which represent records streams. In Kafka, each record contains a key, value, and timestamp.
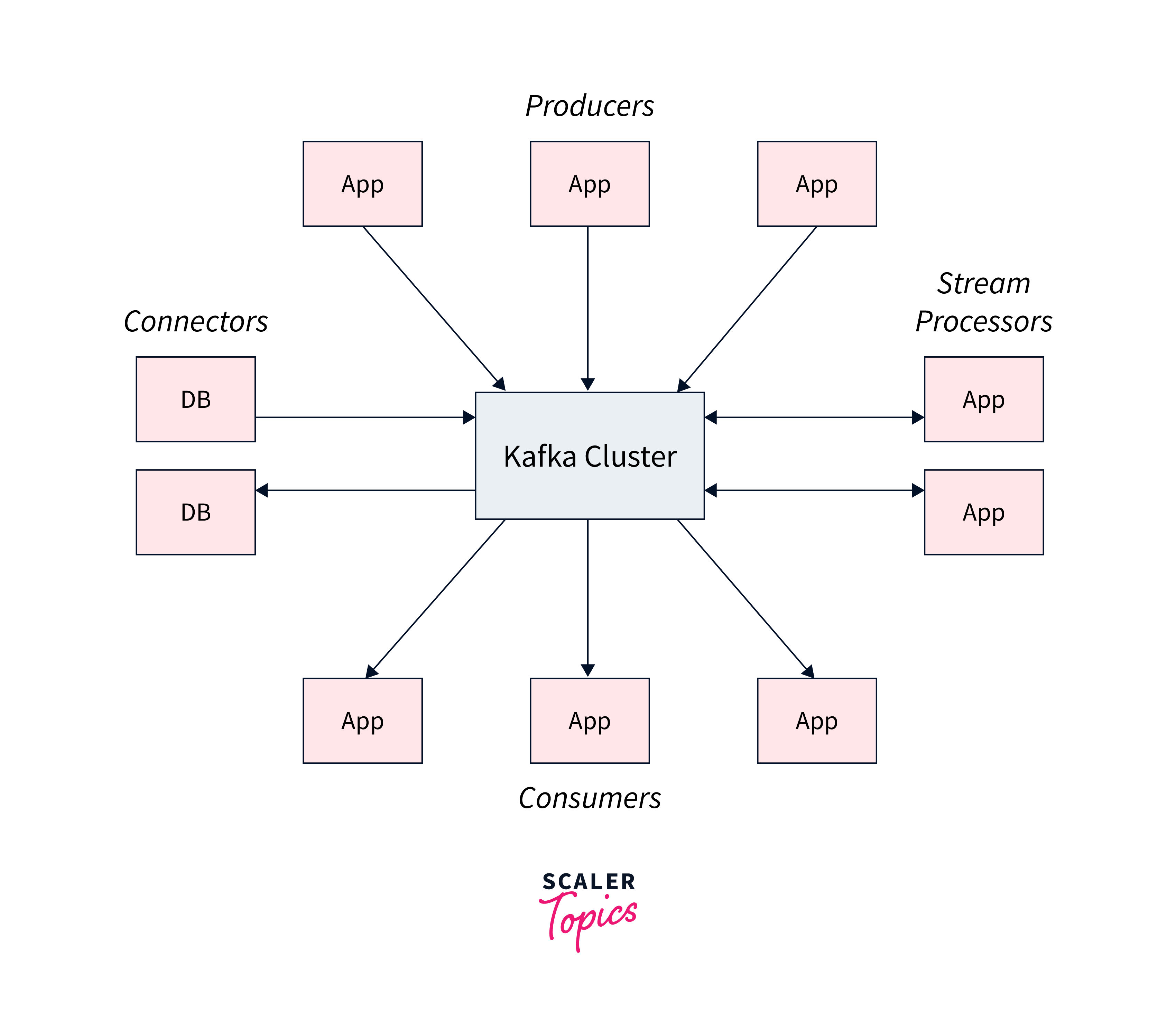
Kafka provides five key APIs for communication with topics:
- Producer API:
Allows records to be published to one or more topics. - Consumer API:
Allows topics to be subscribed to and incoming records to be processed. - Streams API:
Makes stream processing easier by consuming input streams and producing output streams. - Connector API:
Allows Kafka topics to be integrated with external applications or data systems. - Admin API:
Allows you to manage and monitor Kafka topics, brokers, and other components.
Kafka guarantees that record streams are fault-tolerant and long-lasting. It enables real-time processing of record streams as they come.
Understanding Kafka Connect API
The Kafka Connect API is an important part of Apache Kafka that allows for simple and scalable data integration between Kafka and other systems. Here's a quick rundown of the Kafka Connect API:
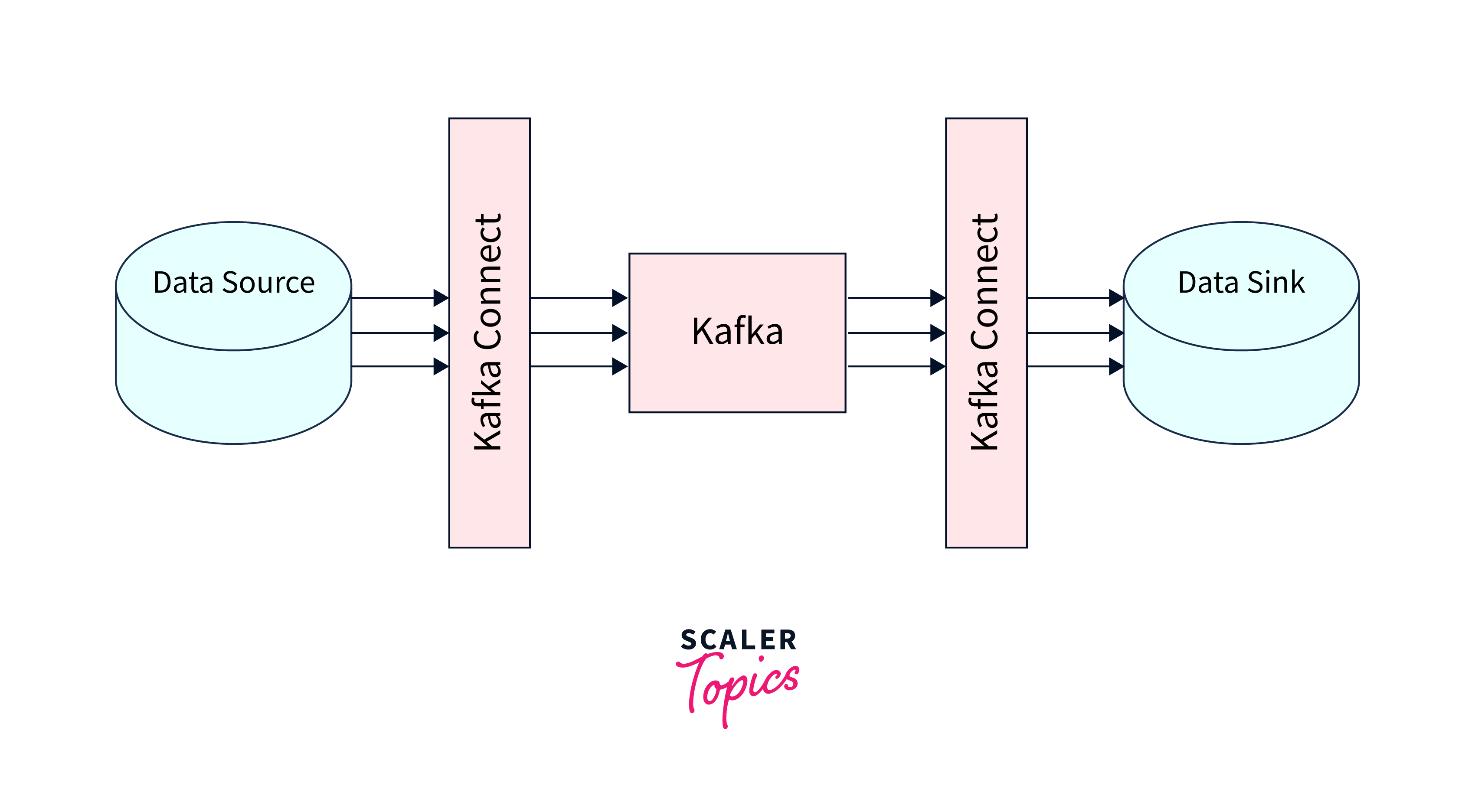
- Data Integration:
The Kafka Connect API allows data to be moved into and out of Kafka, offering an efficient and dependable means of data integration. - Connector Types:
It divides connectors depending on data transport direction:- Source Connector:
This component reads data from external sources and publishes it to Kafka topics. - Sink Connector:
Reads and publishes data from Kafka topics to external data systems.
- Source Connector:
- Connector Plugins:
To facilitate data transfer scenarios between Kafka and multiple data sources, Kafka Connect employs connector plugins, which are community-developed libraries. These plugins provide standardized implementations for widely used databases, messaging systems, cloud storage, and other applications. - Connector and Task Relationship:
Tasks, which stand in for units of work inside a connection, are managed and coordinated by connectors. For scalability and fault tolerance, a cluster of tasks can be spread. - State management:
Task states are saved in distinct Kafka topics, facilitating fault tolerance and simple job restarts.
Apache Kafka and the Connect API
What is Apache Kafka?
Apache Kafka is a distributed streaming technology that was originally created by LinkedIn and contributed to the Apache Software Foundation. The Scala and Java-based project seeks to create a uniform, high-throughput, low-latency framework for managing real-time data flows. A streaming platform, by definition, has three main capabilities:
- Publish and subscribe to record streams, much like a message queue or business messaging system.
- Store record streams in a fault-tolerant and long-lasting manner.
- Process record streams as they come in.
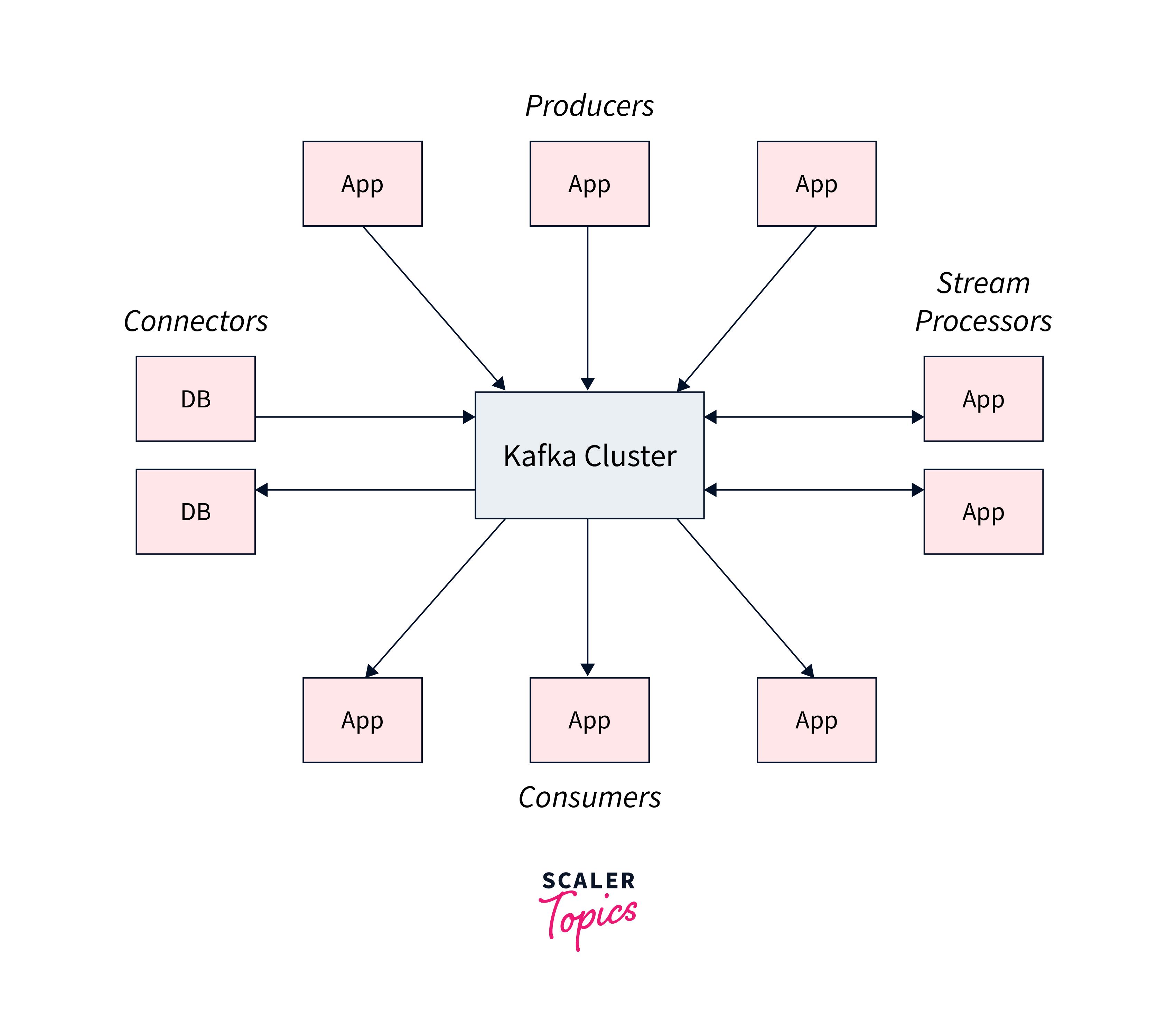
Kafka provides five key APIs for communication with topics:
- Producer API:
enables the publication of a stream of records to one or more topics. - Consumer API:
allows you to subscribe to one or more topics and handle the stream of records that are sent to you. - Streams API:
allows you to function as a stream processor, ingesting an input stream from one or more topics and providing an output stream to one or more output topics, thereby converting input streams to output streams. - Connector API:
Reusable producers and consumers link Kafka topics to existing applications or data systems. - Admin API:
lets you to manage and examine Kafka topics, brokers, and other objects.
The Role and Importance of Kafka Connect API in Kafka’s Ecosystem
Kafka Connect is an open source Apache Kafka component that allows you to quickly transport data IN and OUT of Kafka. It offers a scalable, dependable, and easier method of moving data between Kafka and other data sources. The connection is categorised according on the direction of data movement:
- Source Connector:
This connector reads data from a datasource and publishes it to a Kafka topic. - Sink Connector:
This connector reads data from a Kafka topic and publishes it to a datasource.
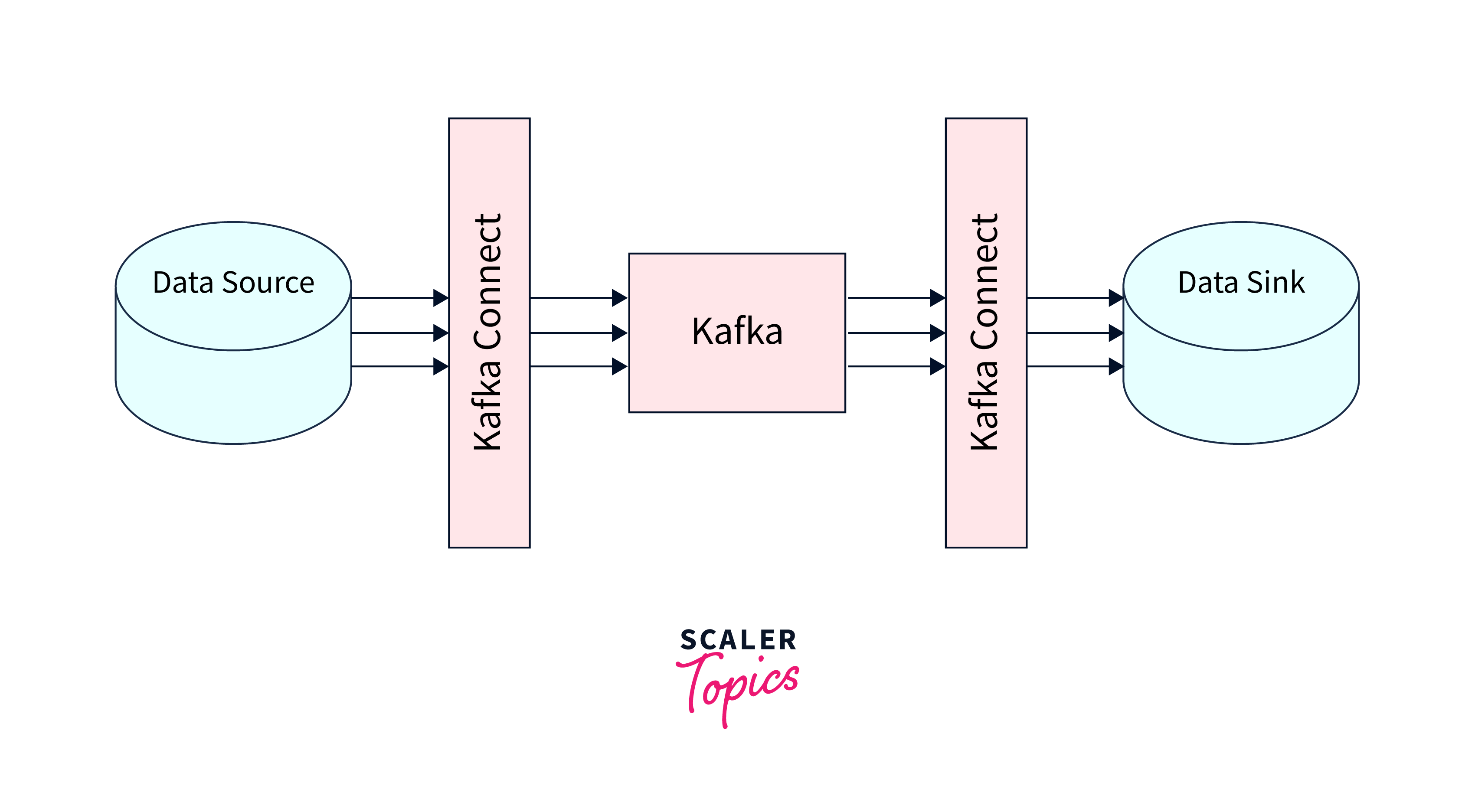
Kafka Connect uses connector plugins, community-developed libraries, to support data transfer across various databases like PostgreSQL, MySQL, Cassandra, MongoDB, Redis, JDBC, FTP, MQTT, Couchbase, REST API, S3, and ElasticSearch. These plugins provide a standardized implementation for transporting data.
Utilize a Connector to handle implementation specifics like fault tolerance, delivery semantics, and ordering, and transport data using connector plugins. This simplifies data transportation and simplifies the process.
Basics of Kafka Connect API
Architecture of Kafka Connect
- It is a distinct Cluster.Each Worker includes one or more Connector Tasks.
- A cluster can contain several workers, and workers only run on the cluster.
- If a task fails, it is immediately load-balanced, as demonstrated in the image below.
- Above all, depending on the kind of Connector, jobs in Kafka Connect behave as Producers or Consumers.
- There are several loaded connections in the Kafka connect cluster.
Connectors and Tasks
- Connectors are in charge of managing the tasks that will be executed. They must select how data will be divided across tasks and assign tasks with precise configurations in order for them to do their jobs successfully.
- Tasks manage Kafka connections, with the worker providing context and initialized with a Properties object. When initiated, they poll an external source and return a list of records, which the worker sends to a Kafka broker.
Sinks and sources
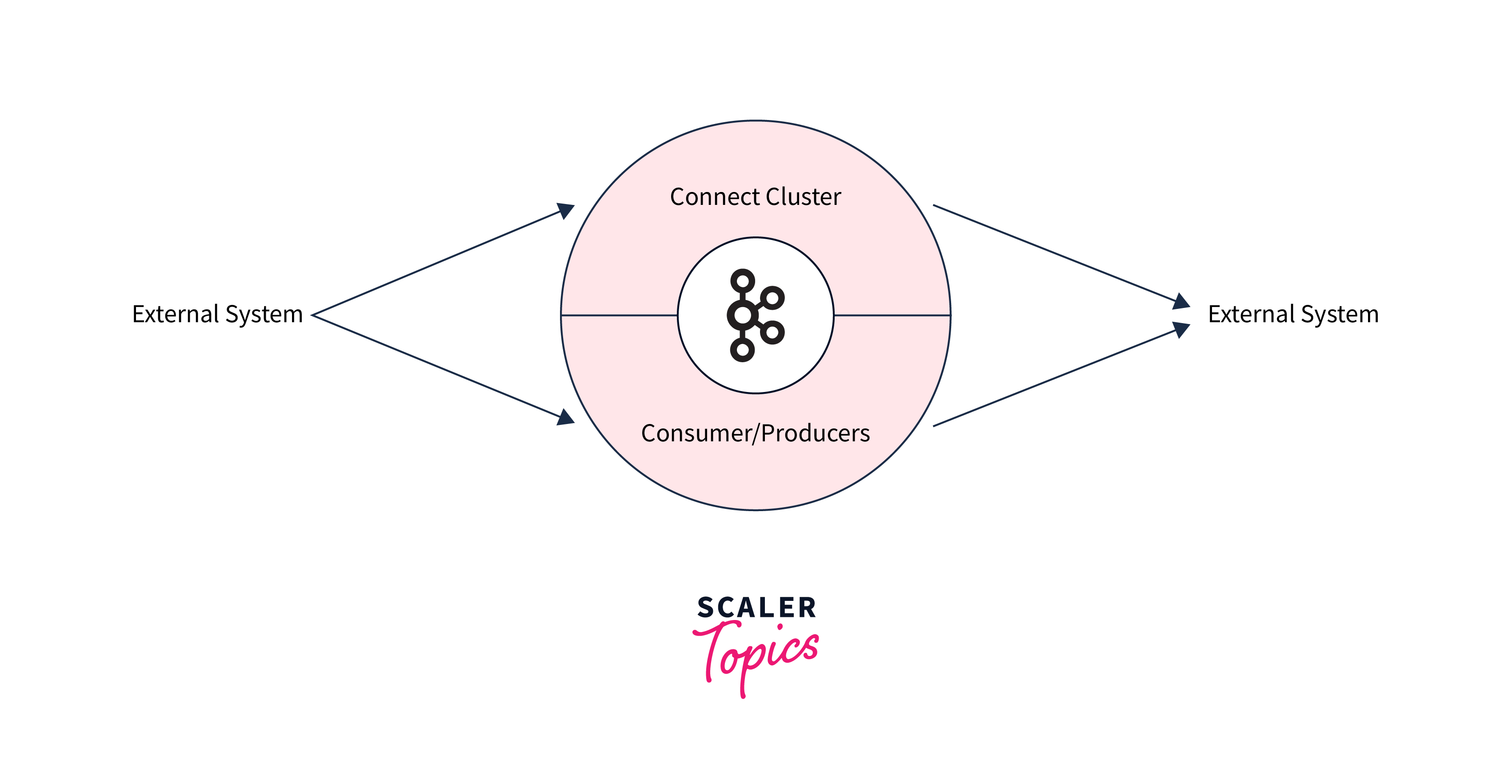
Kafka Connects are focused on streaming data to and from Kafka. Connectors are categorised based on the direction of the data transported.
- Source connector -
Connector consumes databases, feeds table changes to Kafka topics, gathers application server metrics, and stores data for low-latency stream processing. - Sink connection -
Sends data from Kafka topics to secondary indexes like Elasticsearch or batch systems like Hadoop for offline processing.
Workers
- Kafka link workers executes worker tasks.Workers execute connectors within jar files, operating in solitary or distributed mode.
- If a worker crashes, the system rebalances using the heartbeat feature from Kafka consumer's Protocol.
- Workers join clusters by detecting and allocating connections or tasks, sharing the same group.id attribute.
Modes: Standalone vs. Distributed
- Standalone
- Both connections and tasks are run by a single process.
- Use configuration.properties documents.
- Very simple to learn and use for development and testing.
- Not fault tolerant, lacks scalability, and is difficult to monitor.
- Distributed
- Connectors and tasks are run by several workers.
- A REST API is used to configure the system.
- Simple to scale and fault tolerant (rebalancing if a worker dies)
- Useful for connection production deployment.
Setting Up Kafka Connect API
Setting up the Kafka Connect API involves installing and installing Apache Kafka Connect, enabling external system interaction and developing connectors for data streaming between Kafka and other sources.
Here's a full description of how to set up the Kafka Connect API, as well as a Java code example:
Step 1 : Dependencies
Include necessary dependencies in Java project, like kafka-connect-api artefact, for Kafka Connect classes and interfaces.
Step 2: Configure the Connectors
Create a Properties object to define connector configuration, including class, job count, and settings. As an example:
Step 3: Install the Kafka Connect Worker
Create a Kafka Connect worker instance to manage the connections and their duties. You must supply a configuration object that contains the attributes of the Kafka Connect worker. Here's an example that makes use of the ConnectConfig and Connect classes:
The ConnectConfig class encapsulates the connection configuration information, whereas the Connect class represents the Kafka Connect worker. The Kafka Connect worker is started using the start() function.
Step 4: Submit Connector Configuration
Use Kafka Connect REST API to send connection settings in JSON format via HTTP POST. Here's an example using the Java standard library's HttpClient:
In this example, connectorConfigUrl is the URL of the Kafka Connect REST API, and connectorConfigJson is the connector configuration's JSON form. The code sends an HTTP POST request to the Kafka Connect REST API endpoint with the connection setup JSON data.
Working with Connectors
Kafka Connect uses the Producer and Consumer API in Kafka 0.9.0, while Confluent platform includes Connect Service and Apache Kafka. Connectors provide a simple connection setup, while the framework handles scaling, distribution, and state persistence.
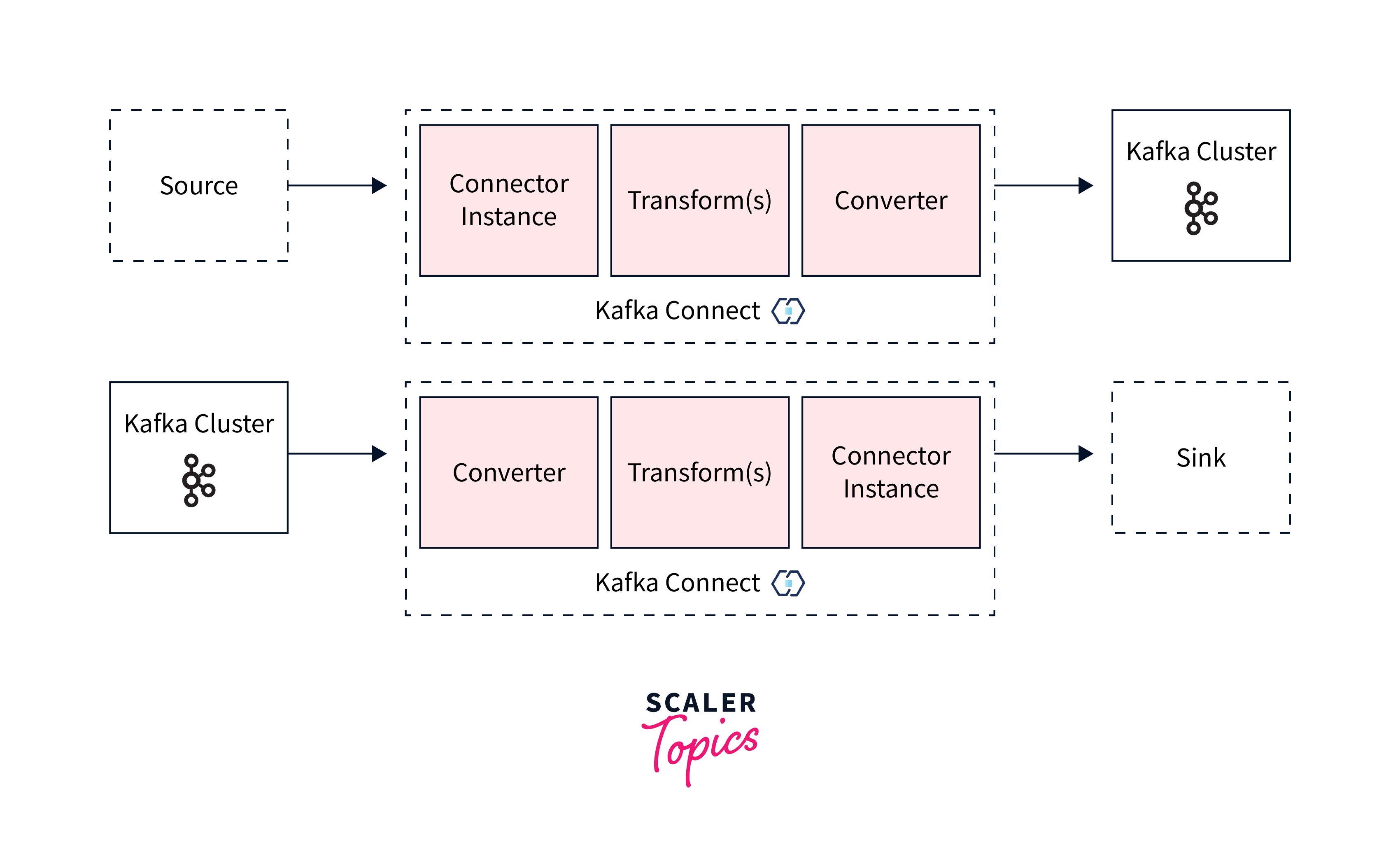
Core concepts:
- Connectors -
A high-level abstraction that manages jobs to coordinate data streaming. - (Source) Tasks -
The implementation of how data from an external system is copied to Kafka. - Workers :
Workers are the processes that run and perform connectors and tasks. - Converters :
Converters are pieces of code that transform data between Connect and the system delivering or receiving data. - Transforms :
Transforms are simple logic that can be used to change each message created by or transmitted to a connector.
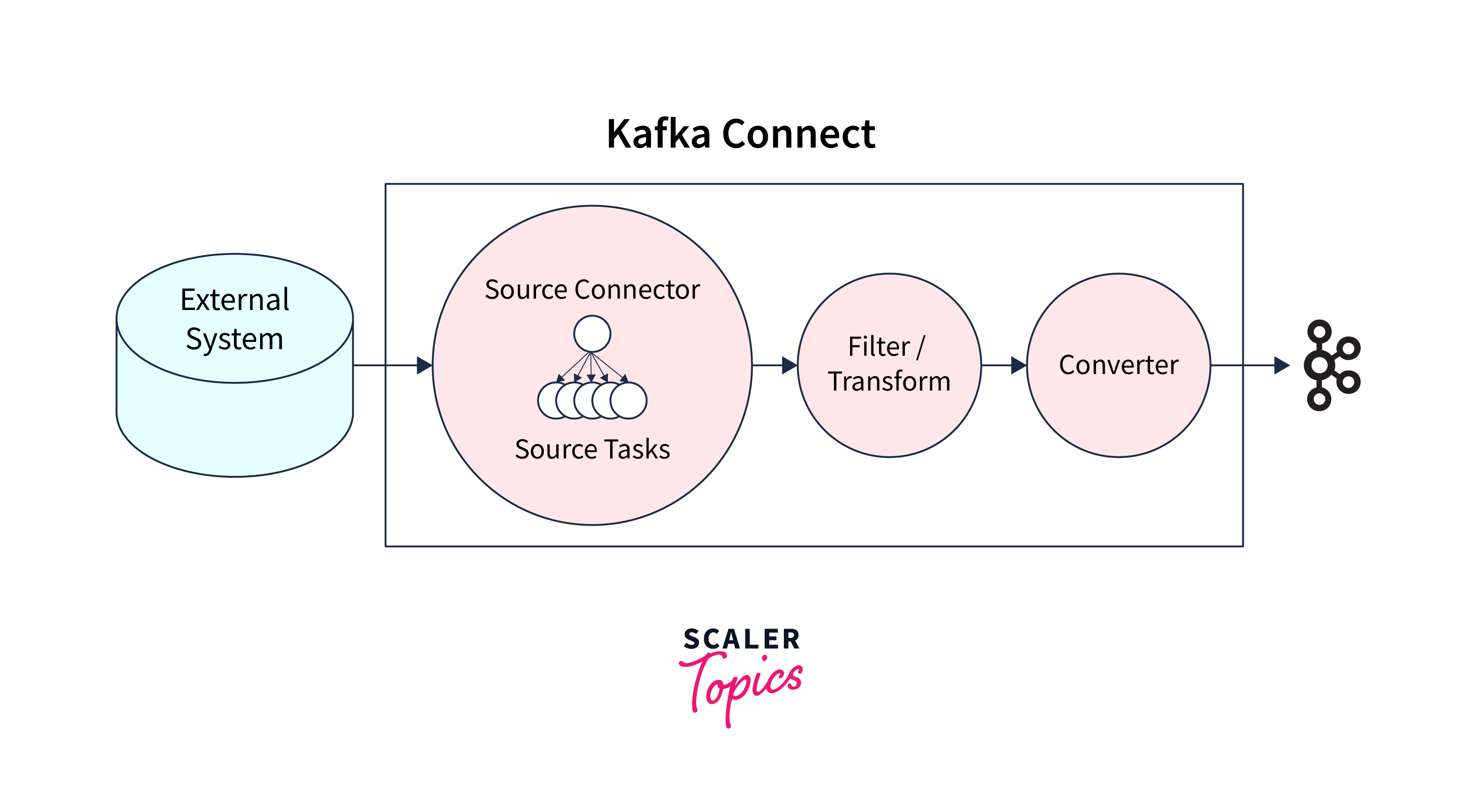
A source connector gathers data from systems like databases, streaming tables, and message brokers, enabling low-latency stream processing.
A sink connector transfers data from Kafka topics to other systems, such as databases of any kind, indexes like Elasticsearch, or batch systems like Hadoop.
Install Confluent Platform, a Kafka distribution by Confluent, Inc., for additional tools, clients, and pre-built Connectors. Explore Kafka Connect concept using file source and sink connectors.
Confluent Platform includes both of these connections, as well as reference setups.
- Configuration of the Source Connector
The reference configuration for the source connector is accessible at $CONFLUENT_HOME/etc/kafka/connect-file-source.properties:
Some attributes are shared by all source connections in this configuration:
- name is a name assigned by the user to the connection instance
- connector.class indicates the implementing class, which is essentially the type of connection
- tasks.max provides how many simultaneous instances of our source connector should execute.
- topic gives the topic to which the connection should deliver the output.
- file specifies the file from which the connection should read input data.
- Configuration of Sink Connectors
We'll use the reference configuration from $CONFLUENT_HOME/etc/kafka/connect-file-sink.properties for our sink connector:
-
Finally, we must configure the Connect worker, which will merge our two connections and do the reading and writing from the source connector to the sink connector.
We may use $CONFLUENT_HOME/etc/kafka/connect-standalone.properties for this:
We can keep the following options at their default values:
- bootstrap.servers includes the addresses of the Kafka
- brokers.converter and value.converter create converter classes that serialize and deserialize data as it travels from the source into Kafka and subsequently from Kafka to the sink.
- key.converter.schemas.enable and value.converter.schemas.enable are converter-specific options.
- offset.flush.interval.ms specifies the frequency at which the worker attempts to commit offsets for tasks.
- The most crucial parameter when using Connect in standalone mode is offset.storage.file.filename since it specifies where Connect should store its offset data.
-
Install the Connector :
There are two ways to install the connector: standalone and distributed mode. 4.1 Standalone Mode:First, we may use the command line to examine the topic's content:
We can see that the source connector converted the data from the file_test.txt file into JSON before sending it to Kafka:
Additionally, if we look at the folder $CONFLUENT_HOME, we can see that the following file, file_test.sink.txt, was generated:
4.2 Connecting to Kafka in Distributed Mode :
Standalone mode is ideal for development and testing, while distributed mode utilizes Kafka's distributed nature, storing connection settings and information stateless on worker nodes.The file $CONFLUENT_HOME/etc/kafka/connect-distributed.properties contains a reference configuration for the distributed mode.
The majority of the parameters are the same as in standalone mode. Only a few things are different:
- group.id specifies the name of the Connect cluster group. The value must be distinct from any consumer group ID.
- offset.storage.topic, config.storage.topic and status.storage.topic: Topics for these settings should be defined. We may also set a replication factor for each topic.
We may start Connect in distributed mode by doing the following:
In contrast to the solo starting command, no connection settings were supplied as parameters. Instead, we must use the REST API to construct the connections.
To recreate our previous example, we must send two POST requests to http://localhost:8083/connectors containing the following JSON structs:
First, we must generate the source connector POST body as a JSON file. We'll refer to it as connect-file-source.json in this case:
Take note of how similar this appears to the reference configuration file we used the previous time.After that, we POST:
Then, for the sink connector, we'll use the file connect-file-sink.json:
And then, as previously, do the POST:
If necessary, we can confirm that this configuration is correct:
And, if we check in the folder $CONFLUENT_HOME, we can see that the following file was created: test-distributed.sink.txt
Let's cleaned up after we tried the dispersed configuration by disconnecting the two connectors:
Case Study: Real-World Use of Kafka Connect API
Use Case: Relational Database and Data Integration
Company XYZ uses a core relational database for its e-commerce platform, storing customer and order information. They use Kafka Connect to provide real-time processing and analytics on this data.
Overview of the solution
The database changes will be sent in real-time to Kafka topics via Kafka Connect. The popular open-source connector Debezium will be used to record database updates. To manage large data traffic, the integration will be implemented in distributed manner.
Code Illustration
First step: Dependencies
Ensure that your Java project contains the required dependencies. We'll use the Debezium connector for MySQL and the Kafka Connect API in this example:
Replace the relevant versions with $kafka.version and $debezium.version.
Step 2: Configure the Connectors:
To define the connection settings, create a Properties object. Here's an example Debezium MySQL connection configuration:
Adjust the configuration parameters according to your MySQL database configuration.
Step 3: Install the Connector:
Deploy Kafka Connect REST API, deploy connection in distributed mode, send HTTP POST request. Here's an example that makes use of Apache HttpClient:
Step 4: Manage and Monitor the Connector:
Kafka Connect REST API for connectivity monitoring and connector state information. As an example:
To stop, resume, or remove the connection, use HTTP POST or delete queries to the relevant endpoints.
Case study demonstrates real-world application of Kafka Connect API for combining relational database with Kafka, including dependencies, configuring, deploying, and monitoring progress.
Conclusion
Summary of The Key Points
- Kafka Connect API enhances data integration, scalability, fault tolerance, schema evolution, and ecosystem integration.
- Kafka Connect provides source and sink connectors for real-time data pipelines and smooth integration.
The Power of Kafka Connect API for Data Integration
The Kafka Connect API is a strong data connection platform that enables easy and scalable interaction between Kafka and other systems. Here are some of the primary benefits and capabilities of the Kafka Connect API for data integration:
- Simplified Data Integration:
Kafka Connect simplifies data pipeline building with standardized API and connectors, reducing integration complexity and allowing developers to focus on connector configuration. - Scalable and Distributed:
Kafka Connect expands horizontally and manages high data throughput in distributed mode, allowing for data integration operations to be parallelized across clusters for effective handling of large-scale data pipelines. - Fault Tolerance and Data Reliability:
Kafka Connect guarantees data reliability and fault tolerance using Kafka's replication and fault-tolerance capabilities, ensuring at least-once delivery guarantees during integration failures. - Schema Evolution and Compatibility:
Kafka Connect offers schema evolution, allowing connectors to manage changes in data integration while assuring smooth integration via automated registration, compatibility checks, and evolution. - Seamless Integration with Kafka Ecosystem:
Kafka Connect integrates with Kafka components like KSQL, Kafka Streams, and Sink Connectors, enabling seamless data processing and analytics pipelines.
Encouragement to Further Explore and Use Kafka Connect API
Kafka Connect may be utilized for a variety of data in and out of Kafka use cases. In this part, we will look at the most typical use cases for Kafka Connect and describe the benefits they bring to data management and processing.
The following are the usage cases:
- Capturing databases changes
Change Data Capture (CDC) is a requirement for data pipelines, allowing applications to track changes in databases in real-time. Kafka Connect connectors stream changes, reducing database load and enabling schema evolution. Some connector plugins access change log files for reliable updates, reducing database load. - Kafka cluster mirroring
Kafka Connect enables data mirroring between clusters for disaster recovery, migration, and geo-replication, while MirrorMaker connections ensure synchronization, failure minimization, and data availability. - Modernizing legacy systems
Modern designs favour tiny applications, which causes problems with legacy systems. Kafka, a publish/subscribe messaging system, acts as a bridge between systems, allowing older programs to process data in batches rather than in real-time. - Log aggregation
Kafka Connect simplifies data aggregation and analysis using low latency and large data capacity, enabling easy cluster deployment and format changes for efficient infrastructure protection.