Optimizing Kafka Consumer Performance
Overview
Optimizing Kafka Consumer Performance involves enhancing the efficiency and throughput of data consumption from Kafka brokers. Key strategies include tuning consumer group settings, adjusting batch sizes, managing offsets, and utilizing parallelism. Efficient configuration of consumers ensures minimized processing time and maximized data processing rates, leading to better scalability and reduced latency. Fine-tuning consumer parameters based on workload characteristics and hardware capabilities optimizes resource utilization and delivers a smoother data ingestion experience. This article is a comprehensive article that explores the techniques and methodologies to enhance the efficiency and throughput of Kafka consumers.
Introduction
Brief Overview of Apache Kafka

Apache Kafka is a distributed streaming platform designed to handle high-throughput, real time data feeds. It allows for the efficient, fault-tolerant, and scalable processing of large volumes of data in real-time. Kafka operates on a publish-subscribe model, where producers publish records to topics, and consumers subscribe to these topics to receive data. The system ensures data durability and reliability by persistently storing messages in distributed partitions across multiple servers, called brokers.
Kafka's architecture enables the decoupling of data producers and consumers, providing a robust and flexible solution for data integration and processing. Its use cases span various domains, including log aggregation, event sourcing, real-time analytics, and messaging systems.
With its distributed nature, fault tolerance, and horizontal scalability, Apache Kafka has become a popular choice for building data pipelines and streaming applications, allowing organizations to harness the power of real-time data processing effectively.
Importance of Kafka Consumer Performance
The importance of Kafka consumer performance lies in its crucial role in ensuring efficient and timely data processing and delivery within the Kafka ecosystem. Consumers are responsible for extracting data from Kafka topics and processing it for various use cases, such as analytics, monitoring, or feeding downstream applications. Optimal consumer performance directly impacts the overall system's** efficiency, scalability, and responsiveness**.
A high-performing consumer is essential to keep up with the continuous influx of data, preventing backlogs and reducing latency between data production and consumption. It enables real-time or near-real-time processing, making it easier to react to events as they happen, which is critical in time-sensitive applications.
Efficient consumer performance also ensures resource utilization is maximized, minimizing operational costs and infrastructure requirements. It enables organizations to scale their Kafka clusters as needed, accommodating growing data volumes without sacrificing data reliability or processing speed.
Kafka consumer performance directly impacts the system's ability to handle large-scale data streams effectively, enabling businesses to gain valuable insights and deliver responsive, data-driven services to their customers.
Understanding Kafka and Kafka Consumer
Kafka is an open-source distributed event streaming platform designed for high-throughput, fault-tolerant, and real-time data processing. It acts as a message broker, allowing applications to publish and consume streams of records while providing scalability and durability. Kafka uses a publish-subscribe model, where producers send data to topics, and consumers read from those topics. Key components include brokers (servers), producers, consumers, and topics. Its architecture enables seamless data integration across systems, making it ideal for use cases like real-time analytics, log aggregation, and data pipeline creation. Kafka has become a fundamental tool for modern data-driven applications and microservices architectures.
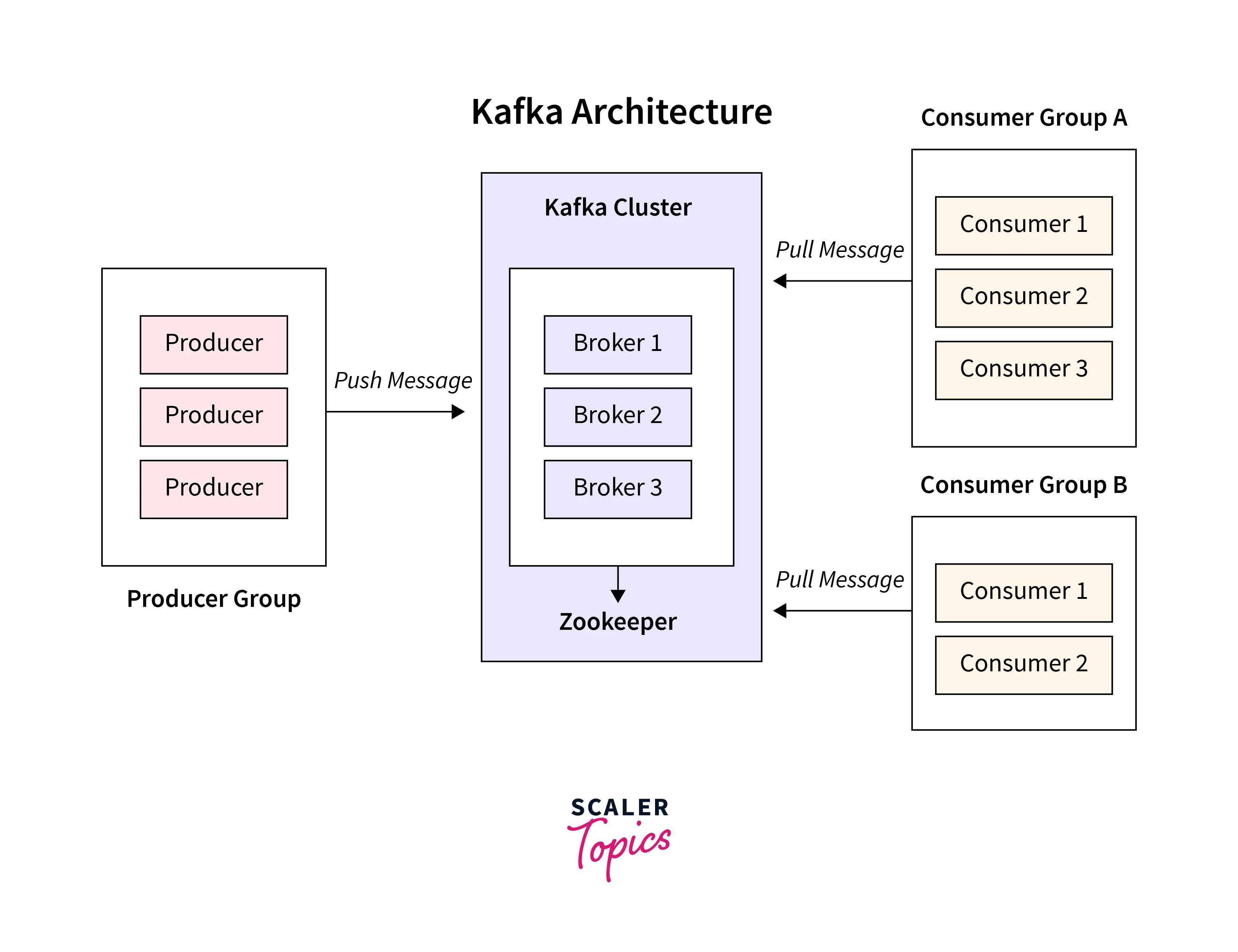
Kafka Consumers play a critical role in the Kafka ecosystem. They are applications or processes responsible for reading data from Kafka topics and processing it for various purposes. Consumers can be part of a consumer group, where each consumer in the group reads from a subset of partitions, enabling parallel processing and load balancing. This allows for horizontal scaling and efficient utilization of resources.
Understanding Kafka Consumers is essential because they determine how quickly data is consumed and processed, impacting the overall system's performance. Consumers must keep pace with the rate of data production to prevent backlogs and ensure real-time or near-real-time data processing. Proper configuration and optimization of consumers are vital for achieving low-latency data delivery and responsiveness in applications.
Furthermore, consumer design affects data reliability and data consistency. The "at-least-once" delivery semantics ensure that data is not lost even if a consumer fails, but it may result in duplicate processing. In contrast, "exactly-once" semantics require careful implementation but guarantee that each message is processed only once, providing data integrity.
Basics of Kafka Consumer Performance
Key Performance Metrics for Kafka Consumers
Key performance metrics for Kafka Consumers are crucial for ensuring efficient and reliable data processing within the Kafka ecosystem. Monitoring these metrics allows developers and operations teams to identify and address performance bottlenecks, optimize resource utilization, and maintain a responsive data streaming pipeline.
- Throughput:
Measures the rate at which data is consumed from Kafka topics. High throughput ensures timely processing of data, preventing backlogs and reducing latency. - Latency:
Represents the time taken by consumers to process messages from ingestion to retrieval. Low latency is critical for real-time or near-real-time applications. - Consumer Lag:
Indicates the time lag between the latest data produced and the data consumed by consumers. Minimizing consumer lag is vital for staying up-to-date with incoming data. - Error Rates:
Tracks the number of processing errors and failures encountered by consumers. Identifying and addressing errors promptly ensures data integrity and system stability. - Resource Utilization:
Monitors CPU, memory, and network usage of consumer instances. Optimizing resource utilization helps scale the system efficiently. - Partition Distribution:
Ensures an even distribution of partitions among consumers in a consumer group, promoting load balancing and parallel processing. - Rebalance Rate:
Measures how frequently consumer rebalancing occurs within the group. Frequent rebalancing can impact stability and performance. - Message Commit Latency:
Tracks the time taken for a consumer to acknowledge message processing completion. Lower commit latency enhances data reliability and reduces duplicates.
Factors Affecting Consumer Performance
Consumer performance in Kafka can be influenced by various factors that impact how efficiently and effectively consumers process data from Kafka topics. Understanding these factors is crucial for optimizing consumer behavior and maintaining a responsive data streaming pipeline:
- Message Size:
Larger messages require more processing time, potentially leading to increased latency and reduced throughput. - Consumer Group Size:
An appropriately sized consumer group ensures parallel processing, but too many consumers in a group may lead to contention and reduced performance. - Hardware Resources:
CPU, memory, and network capabilities of consumer instances significantly affect processing speed and overall performance. - Commit Interval:
The frequency of message acknowledgments (committing offsets) can influence throughput and message processing order. - Network Latency:
High network latency between Kafka brokers and consumers can introduce delays in data delivery. - Data Processing Logic:
The complexity and efficiency of consumer logic impact the time it takes to process each message. - Consumer Configuration:
Properly tuning consumer settings, such as batch size and fetch intervals, can improve performance. - Message Rate:
The rate at which messages are produced to Kafka topics can affect consumer lag and throughput. - Data Volume:
Higher data volumes may overwhelm consumers, necessitating better resource allocation and scaling. - Data Distribution:
Uneven partition distribution or skewed data can lead to uneven workload among consumers, affecting load balancing.
Optimizing Kafka Consumer Configuration
Understanding Consumer Configurations
Understanding consumer configurations in Kafka is essential for effectively optimizing the behavior of Kafka consumers to meet specific application requirements. Kafka consumers play a critical role in extracting and processing data from Kafka topics, and their configurations influence various aspects of their behavior.
- Batch Size:
The batch size determines the maximum number of records fetched in a single request. Adjusting this parameter affects how much data the consumer processes in each iteration, impacting throughput and memory consumption. - Fetch Interval:
The fetch interval specifies the time interval between each fetch request made by the consumer to Kafka brokers. Proper tuning of this setting can minimize network overhead and latency. - Max.Poll.Records:
This parameter sets the maximum number of records returned in a single poll request. It impacts the size of message batches consumed, influencing processing efficiency. - Auto Commit:
Enabling auto-commit allows the consumer to automatically commit its current offset to Kafka after processing each batch of messages. However, this may lead to message duplication on consumer failures. - Commit Interval:
This setting determines how often the consumer commits its offset. A shorter commit interval may result in more frequent commits but can reduce the risk of reprocessing messages. - Session Timeout:
The session timeout specifies the time a consumer can remain inactive before being considered dead and removed from the consumer group. Properly setting this value ensures timely removal of failed consumers and efficient rebalancing. - Heartbeat Interval:
The heartbeat interval controls how often the consumer sends heartbeats to indicate its liveness to the Kafka broker. Adjusting this value influences consumer responsiveness and rebalancing frequency. - Concurrency and Parallelism:
Developers can optimize consumer performance by fine-tuning the number of consumer instances and threads based on the available hardware resources. Increasing parallelism can enhance data processing capabilities.
Tuning Key Consumer Configurations for Optimal Performance
Tuning key consumer configurations is essential to achieve optimal performance and responsiveness in Kafka consumers. Several important configurations can be adjusted to enhance the consumer's efficiency and data processing capabilities.
- Fetch Size:
This parameter determines the maximum amount of data fetched from a Kafka broker in one request. Increasing the fetch size can boost throughput and reduce network round trips, improving overall consumer performance. - Max.poll.records :
Controls the maximum number of records returned in a single poll request. Adjusting this parameter affects the batch size of messages processed at once, impacting processing speed and memory consumption. - Max.poll.interval.ms:
Sets the maximum time allowed for a single poll request before a rebalance is triggered. Balancing between processing speed and rebalance frequency is crucial for efficient resource utilization. - Enable Auto Commit:
Deciding whether to enable auto-commit or handle commits manually affects data consistency and possible duplicate processing. - Session Timeout:
Defines the time a consumer can remain inactive before being considered disconnected from the consumer group. Proper session timeout settings avoid unnecessary rebalancing. - Heartbeat Interval:
Specifies the frequency of heartbeats sent by consumers to indicate their liveness. Balancing this parameter with the session timeout helps maintain consumer group stability. - Concurrency and Parallelism:
Fine-tuning the number of consumer instances and threads based on hardware resources can maximize processing capabilities.
Use of Compression to Improve Performance
Compression involves encoding data in a more efficient representation, reducing its size and resulting in several performance benefits. One of the significant advantages of compression is the reduction in data size, which leads to lower network bandwidth consumption. When transferring data over networks, compressed data requires less time to transmit, resulting in faster data transfer speeds and reduced latency. This is particularly beneficial for data-intensive applications, large-scale data streams, or scenarios with limited network resources.
Compression optimizes storage utilization. Compressed data occupies less disk space, resulting in reduced storage costs and enabling faster data retrieval from storage systems. It can also lead to improved cache utilization, as more data can be stored in memory due to its reduced size.
In the context of real-time data streaming platforms like Kafka, compression plays a crucial role in improving overall system performance. By compressing messages before publishing them to Kafka topics, producers can increase throughput and reduce disk I/O, as smaller data sizes require less disk write operations. Similarly, consumers can benefit from compressed data, as it results in lower network traffic, faster message retrieval, and reduced processing overhead.
It is essential to consider the trade-offs when using compression. While compression improves data transmission and storage efficiency, it comes with the cost of additional CPU resources required for compression and decompression. Choosing the right compression algorithm and settings depends on the data characteristics, hardware resources, and specific use case requirements to strike a balance between compression efficiency and processing overhead.
Scaling Kafka Consumers
Scaling Kafka consumers is a critical aspect of building robust and high-performance data streaming applications. As data volumes and processing requirements grow, it becomes necessary to distribute the workload across multiple consumers to maintain system responsiveness and handle increasing data throughput.
There are two primary approaches to scaling Kafka consumers:
1. Horizontal Scaling:
Horizontal scaling involves adding more consumer instances to a consumer group. Each consumer in the group processes a subset of the Kafka partitions, allowing parallel processing of data. This approach is particularly effective when the Kafka topic has multiple partitions, as each consumer can read from a separate partition concurrently. Horizontal scaling allows for linear improvements in throughput and processing speed as more consumers are added.
2. Vertical Scaling:
Vertical scaling focuses on improving the performance of individual consumer instances by upgrading hardware resources, such as increasing CPU cores, memory, or network bandwidth. This approach is suitable when a single consumer instance can handle the entire workload, but it requires more substantial hardware investments compared to horizontal scaling.
To ensure effective scaling, it's important to consider the following factors:
- Partition Count:
Kafka topics are divided into partitions, and the number of partitions affects the maximum level of parallelism. Increasing the partition count enables more consumers to be added to the consumer group for better horizontal scaling. - Consumer Group Design:
A well-designed consumer group ensures that each consumer is responsible for processing only a subset of partitions, avoiding duplicate processing and ensuring load balancing. - Offset Management:
Managing offsets correctly is crucial when scaling consumers. Using automatic offset management ensures that each consumer knows where it left off, even when new consumers join or existing ones leave the group. - Failure Handling:
Scaling consumers can result in more frequent consumer rebalances. Robust handling of consumer failures and rebalancing events is essential to maintaining data processing integrity. - Monitoring and Autoscaling:
Implementing monitoring and autoscaling mechanisms can dynamically adjust the number of consumer instances based on workload and resource utilization, ensuring efficient resource allocation. - Consumer Lag:
Monitoring consumer lag helps identify any bottlenecks or underperforming consumers, enabling timely scaling adjustments to prevent data backlogs.
Scaling Kafka consumers requires careful consideration of the architecture, consumer group design, offset management, and monitoring. By effectively scaling consumers, data streaming applications can handle increasing data volumes, maintain responsiveness, and provide seamless user experiences in real-time data processing scenarios.
Kafka Consumer Performance Monitoring
Kafka consumer performance monitoring is a crucial aspect of managing and optimizing data streaming applications using Kafka. Monitoring consumers allows developers and operations teams to gain insights into how efficiently consumers are processing data from Kafka topics and identify potential bottlenecks or issues.
There are several key metrics that should be monitored to assess Kafka consumer performance:
- Throughput:
Monitoring consumer throughput provides a clear indication of how quickly data is being processed from Kafka topics. High throughput indicates efficient data consumption and processing. - Latency:
Latency measures the time taken for messages to be processed from the time they are produced to the time they are consumed. Low latency ensures real-time or near-real-time data processing. - Consumer Lag:
Consumer lag measures the time difference between the latest message produced and the last message consumed by the consumer. High consumer lag indicates potential processing delays or resource limitations. - Error Rates:
Monitoring error rates helps identify any processing failures or issues with data consumption, allowing timely intervention to ensure data integrity. - Resource Utilization:
Tracking CPU, memory, and network usage of consumer instances helps ensure efficient resource allocation and performance optimization. - Rebalance Rate:
Monitoring how often consumer group rebalancing occurs can reveal stability issues within the group or uneven workload distribution. - Message Commit Latency:
Tracking commit latency helps gauge the time it takes for a consumer to acknowledge message processing completion, impacting data reliability and duplicates. - Network Latency:
Monitoring network latency between Kafka brokers and consumers can help identify potential communication bottlenecks.
To effectively monitor Kafka consumer performance, various tools and techniques can be employed:
- Monitoring Tools:
Use tools like Kafka's built-in JMX metrics, Kafka Manager, or third-party monitoring solutions to collect and analyze consumer metrics. - Alerting:
Set up alerting mechanisms to notify teams of performance issues or anomalies in consumer behavior, allowing for proactive response. - Logging and Tracing:
Implement detailed logging and tracing to track consumer behavior and diagnose performance-related issues. - Automated Scaling:
Implement automated scaling mechanisms to dynamically adjust the number of consumer instances based on workload and performance metrics. - Dashboard Visualization:
Create dashboards that provide real-time insights into consumer performance, enabling quick assessment and troubleshooting.
By actively monitoring Kafka consumer performance, organizations can ensure data streaming applications run smoothly, identify and address performance bottlenecks, optimize resource utilization, and provide a seamless and responsive data processing experience to end-users.
Conclusion
- Apache Kafka is a distributed event streaming platform for real-time data processing, facilitating high-throughput, fault-tolerant, and scalable data integration across applications.
- Kafka Consumer Performance refers to the efficiency and speed at which consumers can read and process messages from Kafka topics, ensuring high throughput and low latency.
- Kafka Consumer is an application or component that reads data from Kafka topics, processing and consuming messages published by producers for various data processing tasks.
- Throughput, latency, consumer lag, error rates, resource utilization, rebalance rate, message commit latency, and network latency are key performance metrics for Kafka consumers.
- Message size, consumer group size, hardware resources, commit interval, network latency, data processing logic, consumer configuration, data volume, data distribution, and message rate affect consumer performance.
- Understanding consumer configurations involves tuning parameters like batch size, fetch intervals, and commit intervals to optimize Kafka consumers' behavior for efficient data processing.
- Tuning consumer configurations, such as fetch size and max.poll.records, improves Kafka consumer performance by optimizing data processing and resource utilization for optimal throughput.
- Optimized Kafka consumer performance ensures efficient data processing, low latency, and real-time insights, enabling timely reactions to events and maintaining a responsive data-driven ecosystem.
- Compression improves performance by reducing data size, leading to faster data transfer, lower network bandwidth usage, and optimized storage utilization.
- Scaling Kafka consumers involves adding more consumer instances horizontally or upgrading hardware resources vertically to handle increased data throughput and maintain responsiveness.
- Kafka consumer performance monitoring involves tracking metrics like throughput, latency, and consumer lag to assess efficiency and identify potential issues for optimal data processing.
- Exploring and experimenting with Kafka partitioning strategies is encouraged to find the most suitable approach for maximizing scalability, performance, and data distribution in data streaming applications.