Brokers, Producers, Consumers, and Zookeeper
Overview
Kafka Broker, Consumer, Producer, and Zookeeper are the core components of the Kafka cluster architecture. While the producer shall be pushing the message into the Kafka cluster, it is the Kafka broker that helps to transfer the message from the producer to the consumer. The zookeeper works as the centralized controller which manages the entire metadata information for the Kafka producers, brokers, and consumers. Finally, the message reaches the end of the Kafka cluster, where it could be easily read by the consumers.
Introduction to Apache Kafka Architecture
Let us briefly discuss Kafka's architecture. While Kafka utilizes both the point-in-point as well as publish-subscribe messaging systems for publishing data records across various topics. Every topic consists of a partitioned and structured log commit log, which helps to keep track of the records. As the new record is always appended at the end of this log in real-time, offering zero data loss. High scalability, fault tolerance, as well as parallelism are offered by the distributed and replicated partitions across various servers.
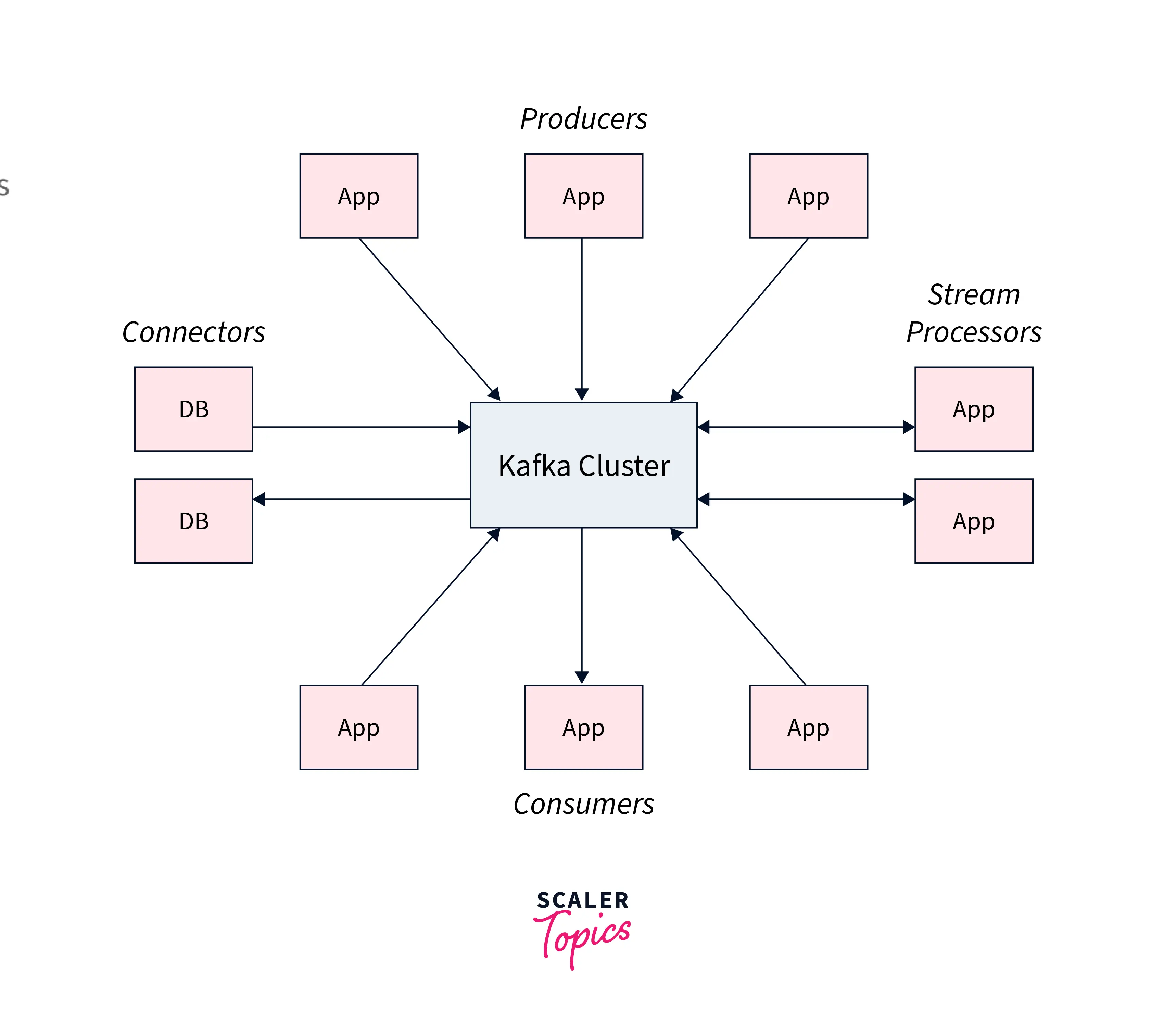
Every consumer who wants the data from the Kafka log is assigned a partition allowing various consumers at the same time to use the data while the order of the data in the log is maintained simultaneously. The data records are seamlessly written and replicated to the disk which makes Kafka a highly scalable and fault-tolerant storage system. Users can set a retention time limit for the data stored on disk until it runs out of space.
Four important APIs which is widely used in Kafka's architecture are described below:
Producer API: For publishing a stream of data records to a Kafka topic, Kafka uses the producer API. Consumer API: For subscribing to Kafka's topics and processing their streams of data records, Kafka uses the consumer API. Streams API: With the Streams API, Kafka authorizes the systems to work as stream processors. Here, the input stream is taken up from the topic which is then transformed into the output stream transferring the data records across various output topics. Connector API: With the Connector API, any external system or application can be easily integrated with the Kafa architecture. The stems can be automated with the data system to any of their current Kafka topics.
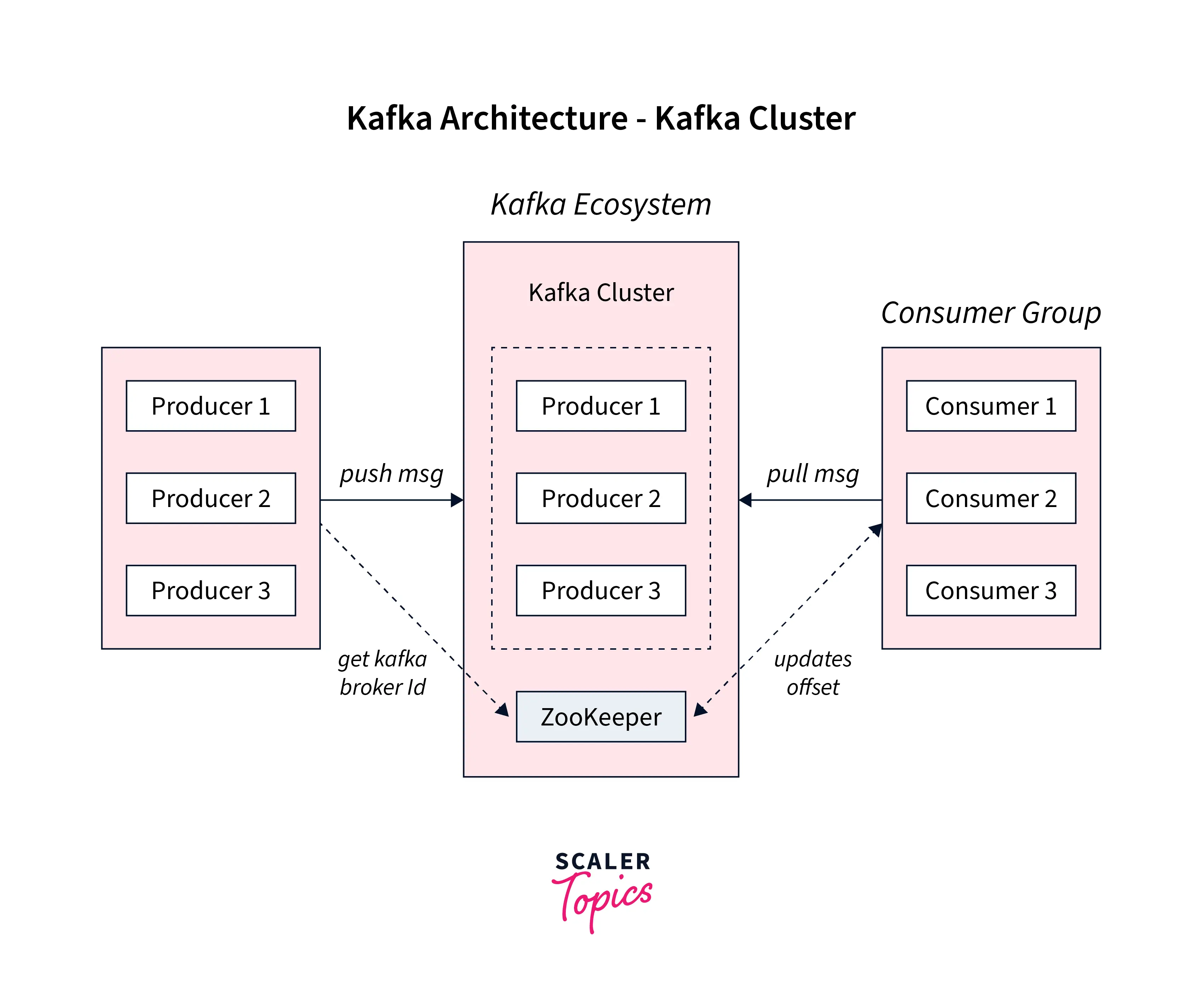
As per the cluster architecture of Apache Kafka, we have four broad components:
- Kafka Broker
- Kafka Consumer
- Kafka Producer
- Kafka Zookeeper
As we proceed with this article we shall be learning about each component, below is the representation of how the cluster architecture of Apache Kafka looks like before we start talking about it.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
What is Kafka Broker?
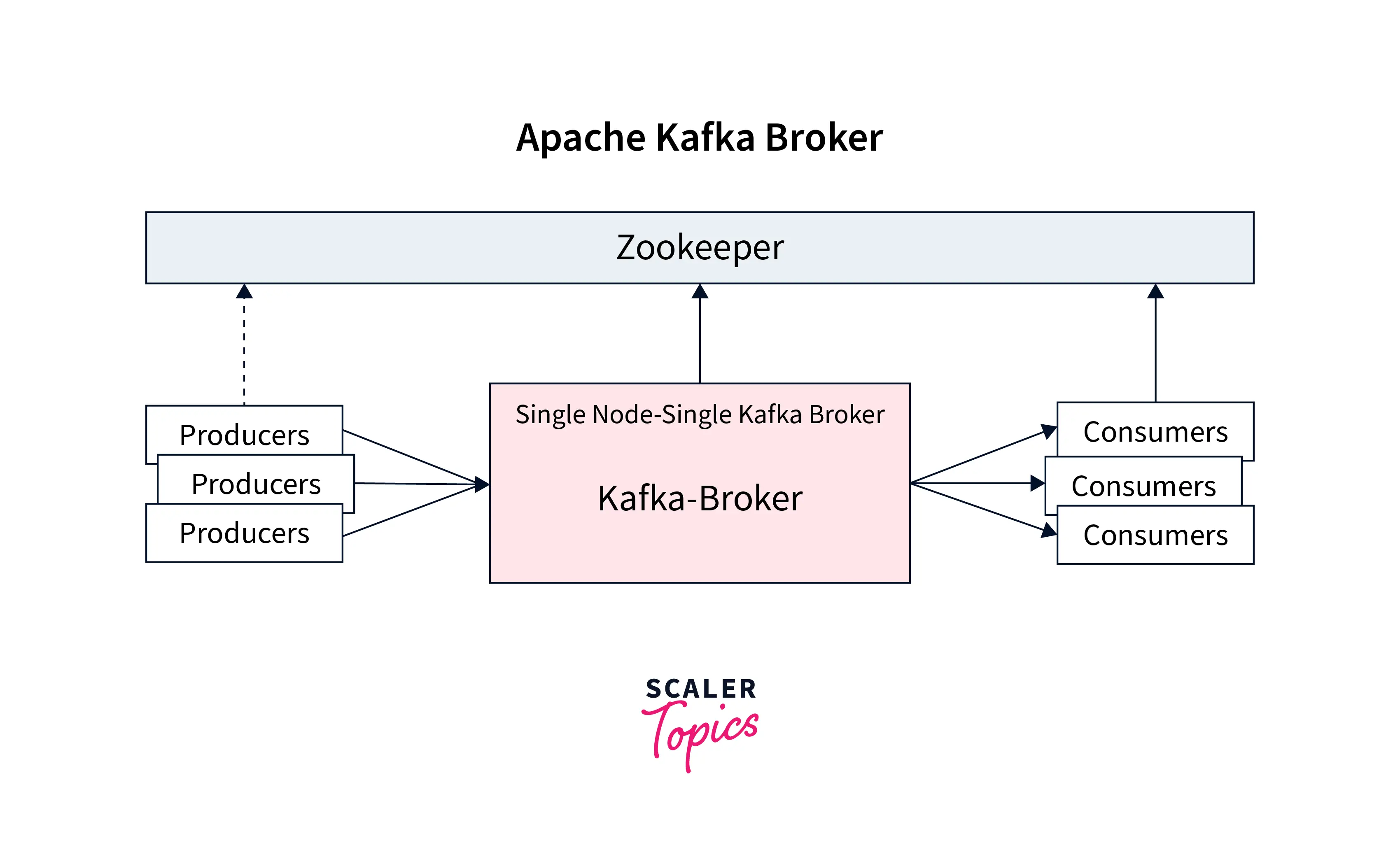 As seen in the illustration above, the Kafka broker can be defined as one of the core components of the Kafka architecture. It is also widely known as the Kafka server and a Kafka node. The Kafka broker is used for managing the storage of the data records/messages in the topic. It can be simply understood as the mediator between the two. We define a Kafka cluster when there is more than one broker present. The Kafka broker is responsible for transferring the conversation that the publisher is pushing in the Kafka log commit and the subscriber shall be consuming these messages. The conversation is mediated between the multiple systems, enabling the delivery of the data records/ message to process to the right consumer.
As seen in the illustration above, the Kafka broker can be defined as one of the core components of the Kafka architecture. It is also widely known as the Kafka server and a Kafka node. The Kafka broker is used for managing the storage of the data records/messages in the topic. It can be simply understood as the mediator between the two. We define a Kafka cluster when there is more than one broker present. The Kafka broker is responsible for transferring the conversation that the publisher is pushing in the Kafka log commit and the subscriber shall be consuming these messages. The conversation is mediated between the multiple systems, enabling the delivery of the data records/ message to process to the right consumer.
While the Kafka cluster consists of various brokers. Kafka cluster implements the Zookeeper for maintaining the state of the cluster. It has also been seen that an individual broker can handle thousands of requests for reads and writes per second. When no performance impact is seen then every broker in the Kafka cluster can handle terabytes of messages. ZooKeeper also performs the broker leader election.
Kafka Broker is structured as a KafkaServer, that is hosting various topics. The stated topics must be partitioned across the various brokers spread in a Kafka cluster. The single broker is hosting the topic partitions for more than one topic, while a topic is partitioned for a single partition. Also, the Kafka producers push a message to a broker. Then the broker receives the data record and stores it over the disk that is keyed by a distinct offset. However, the partition, topic, and offset of a broker allow consumers to fetch messages.
Hence, the brokers could create the Kafka cluster by exchanging information with each other either directly or indirectly via the Zookeeper. It is one broker among all the brokers in a Kafka cluster that acts as the controller.
How to Start Kafka Broker?
It is with the Kafka-server-start. sh, script, which can help the users to kick-start the Kafka broker.
Steps:
-
Start the Zookeeper via the below command: ./bin/zookeeper-server-start.sh config/zookeeper.properties
-
Once the Zookeeper is up and running, users are ready to start a Kafka server via the below command:
- The kafka-server-start. sh starts the Kafka broker.
It is recommended that the Zookeeper is checked if it is up and running before triggering the kafka-server-start. sh, script. Utilize the zookeeper-server-start shell script.
The kafka-server-start. sh implements the config/log4j.properties for logging the configuration that could be overridden via the KAFKA_LOG4J_OPTS environment variable.
Some of the Kafka Command-line Options are mentioned below:
| Command-line Options | Descriptions |
|---|---|
| –override property=value | Represents the value that must be overridden for the value set of the property in the server properties file. |
| -daemon | Enables the daemon mode. |
| -logic | Automatically enabled when Kafka is in daemon mode. |
| -name | Used as defaults for representing the kafkaServer when it is in the daemon mode. |
What is Kafka Producers?
We can define the Kafka Producers as the one from where the users can publish, push messages, or writes the data records to the topics within various partitions. It is automatically detected by the producers about what data must be written at which of the partition and broker. The user doesn't need to define the broker and the partition.
How Does the Producer Write Data to the Cluster?
To write the message or the data record to the topic across various partitions, Kafka Producer implements the following strategies:
- Message Keys
- Acknowledgment
Message Keys To send the message that is being pushed to the Kafka cluster via the producer, it utilizes the concept of the key for pushing the data records in a defined order. The key enables the Kafka Producer with two wide points, i.e., either to automatically push the data record to each partition or push data records to a defined partition only. It is only with the message keys or the partition keys that a defined message could be sent into the Kafka cluster in the defined manner. When the key is applied over the data record, that message shall always be pushed to the same partition every time.
But, when the partition or message key is not applied while writing the message, it could be sent in a roundtable manner. This is widely known as the process of load balancing. Across Kafka, the load balancing is implemented when the message is pushed to the Kafka topic without the keys being defined, then it is the Kafka that distributes little-little bit of the records to every partition. A message key could be anything from a string, number, or anything which helps the users to determine the message.
To help the users understand, if a message was pushed with or without a key the following criteria could be validated:
- When the value of 'key=NULL', it reflects that the message is sent without a key. Hence it is subjected to be distributed in a roundtable manner.
- When the value of the 'key!=NULL', it reflects that the key is defined with the message, and hence all data records will always be pushed and received to the same partition in the same manner.
Acknowledgment To write data to the Kafka cluster, the producer has another choice of acknowledgment. It means the producer can get a confirmation of its data writes by receiving the following acknowledgments:
acks=0: This means that the producer sends the data to the broker but does not wait for the acknowledgment. This leads to possible data loss because without confirming that the data is successfully sent to the broker or maybe the broker is down, it sends another one. acks=1: This means that the producer will wait for the leader's acknowledgment. The leader asks the broker whether it successfully received the data, and then returns feedback to the producer. In such cases, there is limited data loss only. acks=all: Here, the acknowledgment is done by both the leader and their followers. When they successfully acknowledge the data, it means the data is successfully received. In this case, there is no data loss.
Turn Learning into Career Growth
What is Kafka ZooKeeper?
We know that with ZooKeeper users get an in-sync view for their Kafka cluster while Kafka is primarily implemented for handling the real connections from the producers and subscribers. But if we want to understand how is Kafka managed between its brokers as well as clients and maintain the track of more than one broker at once. Well, it's entirely with the help of the Zookeeper.
-
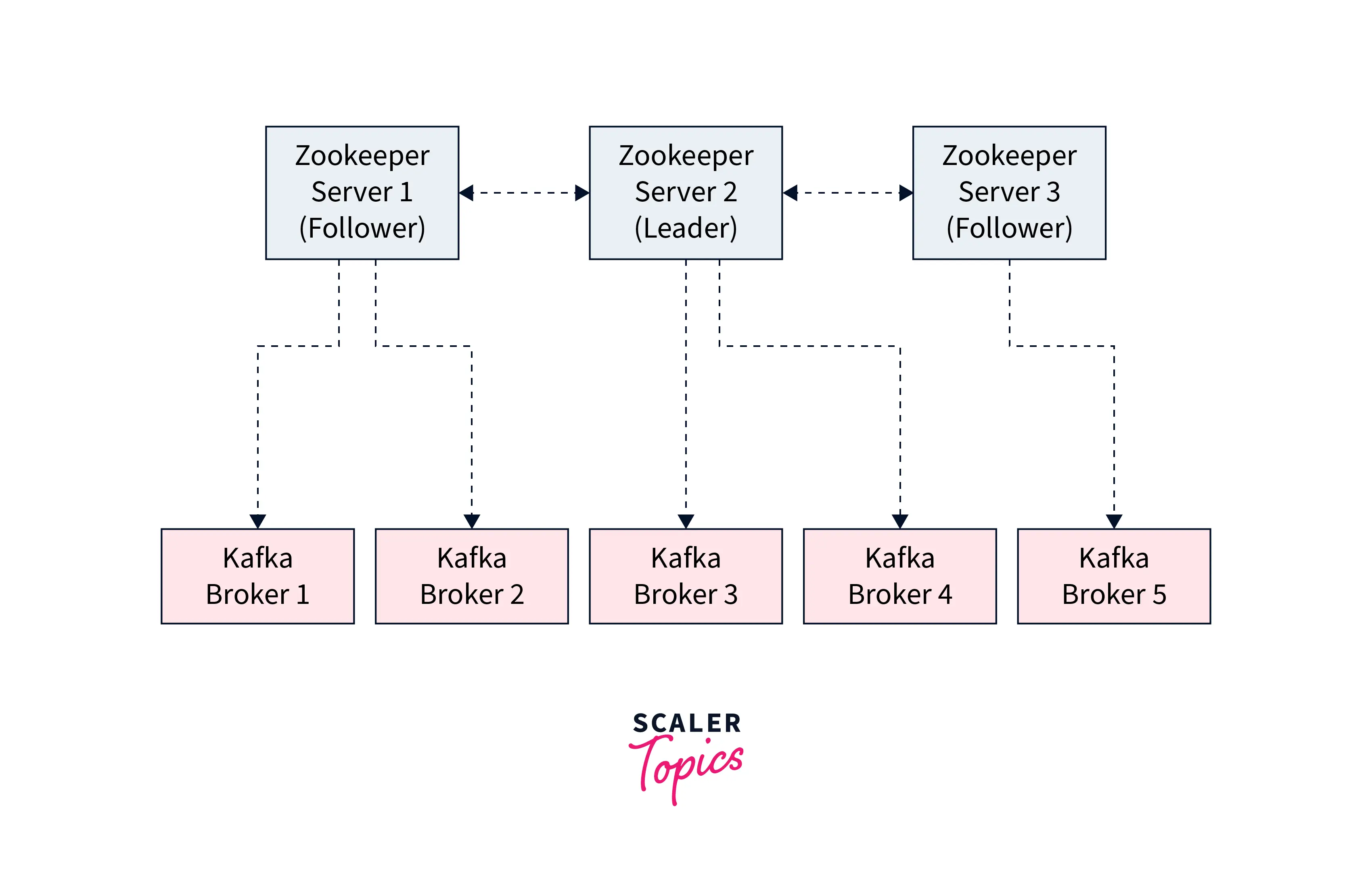
The metadata in Kafka is managed by the Zookeeper. Here, Zookeeper maintains track of all the brokers n the Kafka cluster. With the Zookeeper, it is easier to regulate which broker is taking the leader position for the specific partition and the topic along with performing the leadership elections.
-
It helps to store the configurations for the permissions and topics. Every modification is tracked where the Zookeeper sends the notifications to Kafka as a broker dies, deletes topics, a new topic, a broker comes up, etc.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
What Does Zookeeper Do?
It is important to note that the Zookeeper is NOT storing the consumer offsets with the Kafka clients for more than equal to v0.10
We define a Zookeeper cluster as an ensemble. Users are recommended to implement an odd number of servers for operating the ensemble. It can be 3, 5, 7, 9, etc. This helps the Zookeeper to easily manage the response to multiple requests as a rigid majority of the ensemble members (widely known as a quorum). Also, the Zookeeper has one entirely defined as the leader that is handling the writes, while the remaining servers are described as the followers that handle the read operations.
Below illustration of how Zookeeper in Kafka works.
Should You Use Zookeeper with Kafka Clients?
It has been a while, that the Apache Kafka clients along with the command line interface could be migrated together with the advantage of the brokers acting as a connection endpoint irrespective of the Zookeeper. From Kafka 0.10 version, the subscribers were used to store the offset in Kafka and Zookeeper while the option to connect with the Zookeeper was deprecated.
The entire set of the APIs and commands that used to previously leverage the Zookeeper were migrated to implement Kafka instead of it. Hence, as the clusters migrated to work without Zookeeper, this modification is invisible to the Kafka clients. As far as security is concerned, the Zookeeper ports are opened to allow the traffic from the Kafka brokers, and not entirely from the Kafka clients
Summing up, these days Kafka developers, are recommending not to implement Zookeeper as a configuration in the Kafka clients.
What are Consumer and Consumer Groups?
In this section, we shall be discussing the Kafka Consumer and Consumer Groups.
Kafka Consumer:
We can describe a consumer as one who is subscribing to the records or messages that are being pushed into the Kafka cluster in a topic via the producer. The subscriber is well aware of the broker, from where it shall read the data. It reads the data within every partition as an ordered sequence. It can also read from various brokers at the same time like a subscriber will not read the data from offset 1 before it starts reading from offset 0.
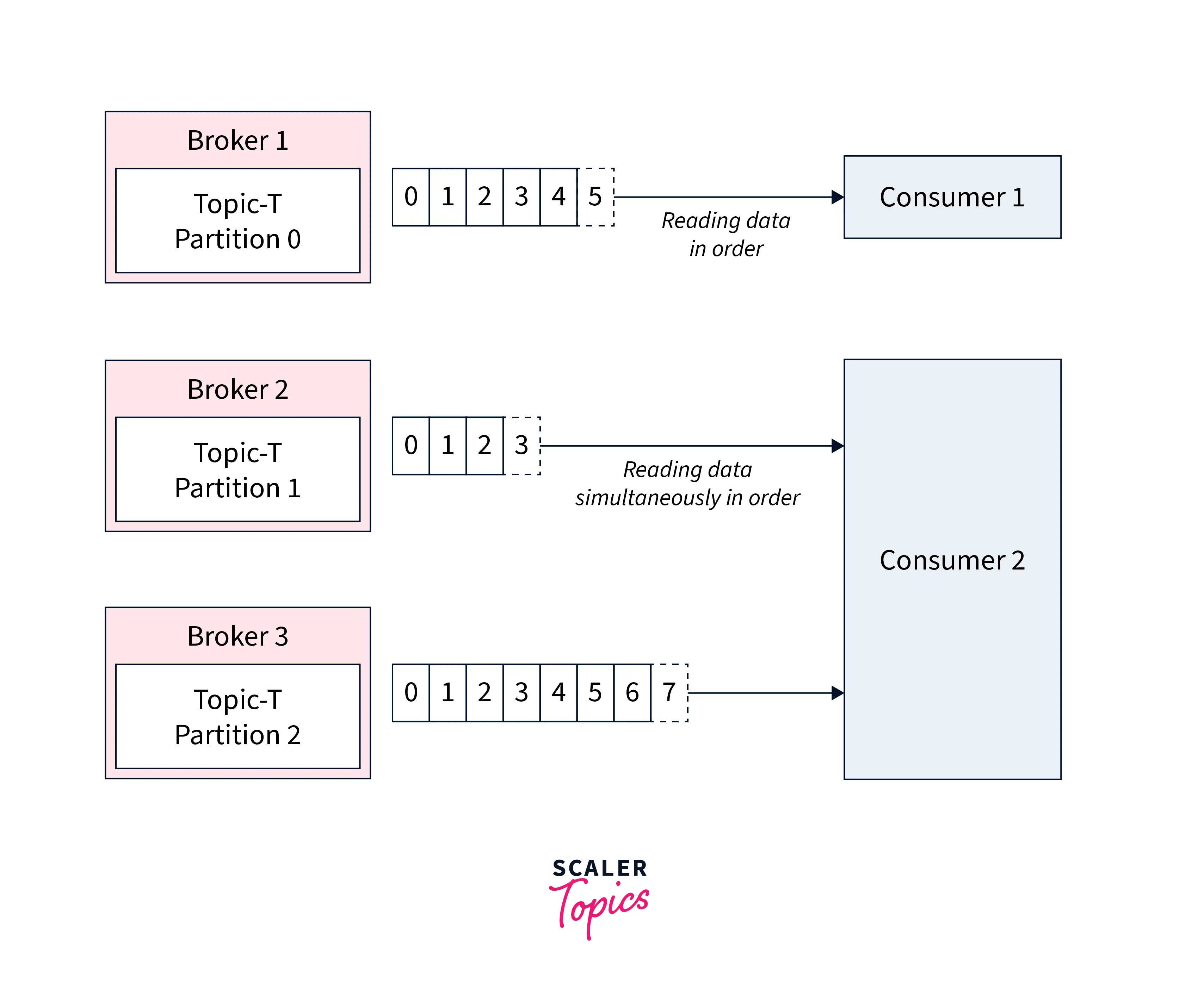
To understand it better let us consider an example. Suppose we have two subscribers as seen in the illustration above, consumer 1 and consumer 2. These subscribers are reading the messages from the brokers. As seen, consumer 1 will read the message from broker 1 in a defined sequential manner. While, as seen consumer 2 is reading the message simultaneously between broker 2 and broker 3. As we see that consumer 2, read the message parallelly. Hence, offset 2 from broker 2 is not at all connected with the message in offset 2 in broker 3.
Kafka Consumer Groups:
We can describe a consumer group as a group of various consumers who are subscribing to the message as an application. Every consumer that is residing in any of these consumer groups shall be directly reading the message from the specific partitions that are defined for it. When a scenario arises where the number of consumers is comparatively more than the number of partitions, the remaining unassigned consumers stay in the inactive state. And during any disaster, if any, it is this inactive subscriber that takes up as the active subscriber within the group to read the message.
The question that might be striking your mind is, how could you decide which of the following subscriber in a consumer group will be the first to read the message and from which partition?
Well, these decisions are entirely taken via the 'GroupCoordinator' and one 'ConsumerCoordinator' automatically. This assigns the subscriber to its defined partition. This characteristic is implemented in Kafka, and the user can simply get started with it without taking up any hassle.
Conclusion
-
Kafka Broker, Consumer, Producer and Zookeeper are teh core compoenet of teh Kafka cluster architecture.
-
While the producer shall be pushing the message into the Kafka cluster, it is the Kafka broker that helps to transfer the message from the producer to the consumer.
-
The ZooKeeper works as the centralized controller which manages the entire metadata information for the Kafka producers, brokers, and consumers. Finally, the message reached the end of the Kafka cluster where it could be easily read by the consumers.
-
Consumer groups are described as a group of various consumers who are subscribing to the message as an application. Every consumer that is residing in any of these consumer groups shall be directly reading the message from the specific partitions that are defined for it.