Data Enrichment with Apache Kafka
Overview
Apache Kafka is a robust distributed streaming platform built for real-time data processing. It performs well in large-scale applications due to its high throughput, low latency, fault tolerance, and scalability. Data is saved and published to topics using Kafka's publish-subscribe messaging architecture and distributed commit logs. Kafka Streams may be used for data enrichment, which is the practise of augmenting raw data with additional information for context and insights. Kafka offers real-time processing of enhanced data by integrating data from several sources, applying business rules, and accessing databases/APIs. This combination of Kafka Connect, Kafka Streams, and other sources provides useful applications like as fraud detection, personalised recommendations, geolocation services, and more. The scalability, real-time processing, durability, and integration features of Kafka make it an appealing candidate for data enrichment across a wide range of fields.
Brief Overview of Apache Kafka
Apache Software Foundation created Kafka, a distributed streaming platform. It offers a uniform, high-throughput, low-latency platform for dealing with real-time data sources. Kafka is built to be fault-tolerant, scalable, and long-lasting, making it ideal for large-scale data processing and streaming applications.
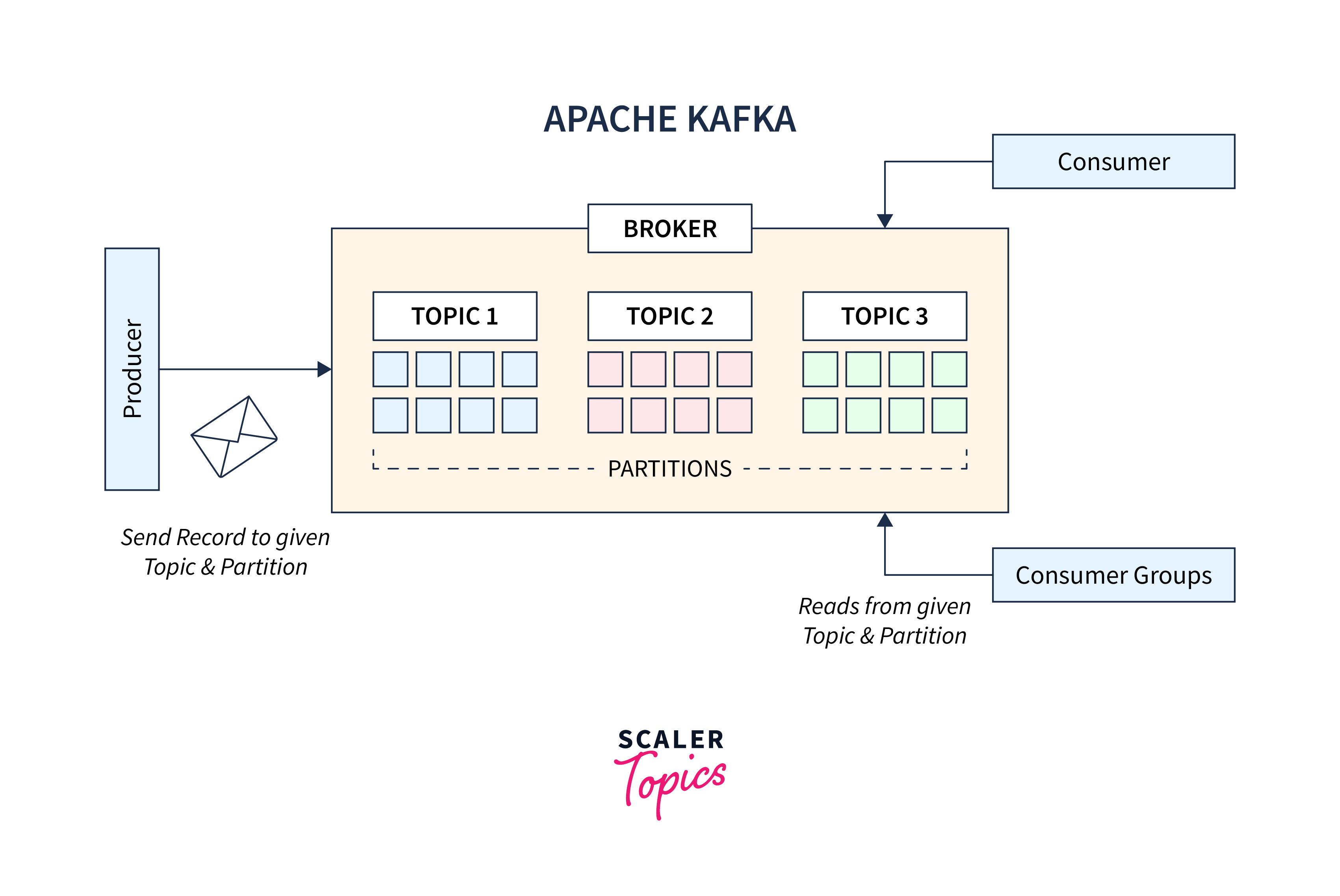
- Kafka is a distributed publish-subscribe messaging system that stores streams of records in a distributed commit log.
- Records in Kafka are published to one or more topics, providing a mechanism for organizing data.
- Producers are responsible for adding data to Kafka topics, while consumers can access and process the data in real-time or at their own pace.
- Kafka supports parallel record processing, enabling high throughput and scalability for handling large volumes of data.
Understanding Data Enrichment
Data Enrichment is the process of augmenting missing or partial data with relevant context received from other sources to improve current information. It is the process of upgrading, refining, and supplementing basic data in layman's terms.
This is accomplished by combining third-party data from an authoritative external source with an existing database of first-party client data. The primary goals of Data Enrichment are to improve data accuracy, quality, and value.
Customer data is initially raw and lacks immediate utility. It is saved in a central repository, but must be cleaned and organized to make it useful. External data enrichment is then added to enhance the original dataset, providing additional useful information.
Understanding Kafka and Data Enrichment
Data enrichment involves supplementing raw data with additional information to provide more context, insights, or value.Enrichment can include adding important qualities to the original data or incorporating data from other sources.
- Data enrichment enhances the quality and usability of data for various applications such as analysis and machine learning.
- In the context of Kafka, data enrichment often involves processing the data stream in real-time using Kafka Streams.
- Kafka Streams is a client library designed for building real-time stream processing applications on top of Kafka.
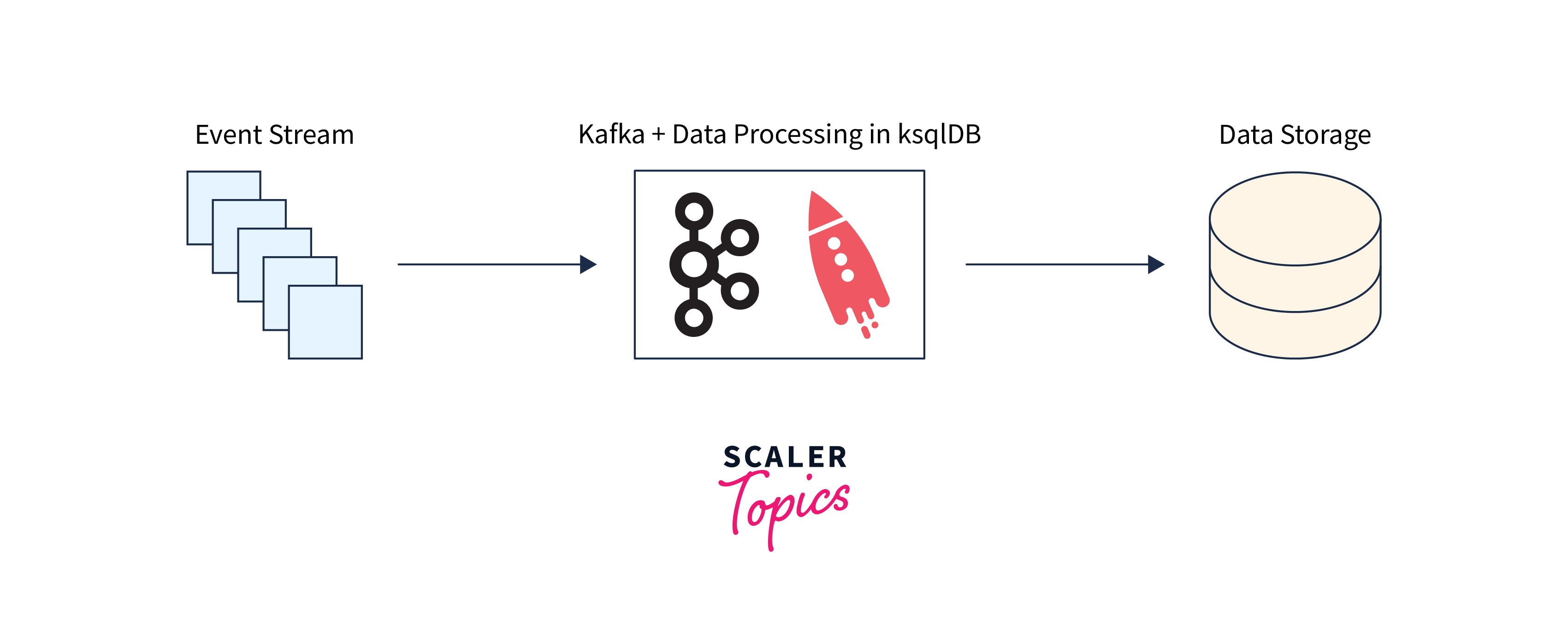
Here's a high-level description of how Kafka may be used to do data enrichment:
- Data Ingestion:
Raw data is created by many sources (e.g., apps, devices) and delivered to Kafka topics via producers. - Enrichment Logic:
A Kafka consumer takes data from Kafka topics using Kafka Streams or other stream processing frameworks. The enrichment logic is applied by the consumer, which might include merging data from various sources, conducting computations, applying business rules, or any other necessary processing. - Data Enrichment:
The consumer adds more information or qualities to the receiving data. This might include queries to external databases or APIs, lookups, or complicated transformations. - Output:
The enhanced data is subsequently sent to new Kafka topics or transmitted to other systems for processing, analysis, or storage.
Basics of Data Enrichment
The practice of improving raw or basic data with additional information to offer more context, increase quality, or provide more value is known as data enrichment. It entails supplementing current data with additional features, data points, or insights received from external or internal systems.

Here are some fundamentals of data enrichment:
- The goal of data enrichment is to increase the value and usability of data by including important information that was not previously available in raw data. This additional data can aid in data analysis, decision-making, personalization, and targeting across a wide range of applications and sectors.
- Sources of data:
Enrichment data may be obtained from a variety of internal and external sources, including third-party data providers, public databases, APIs, social media platforms, customer relationship management (CRM) systems, data aggregators, and others. - Strategies for Data Enrichment:
Depending on the nature of the data and the desired conclusion, many strategies for data enrichment are utilized. Among the most prevalent approaches are:- Adding additional properties or fields to an existing dataset, such as demographic information, geographical data, or behavioral data, is known as data appending.
- Data cleansing is the process of improving data quality by detecting and fixing flaws, inconsistencies, or missing values in a dataset.
- Data deduplication is the process of identifying and deleting duplicate records in order to assure data integrity and correctness.
- Data Normalization is the process of standardizing data formats, units, or representations in order to assure consistency and compatibility across several sources.
- Implementation:
Depending on the individual needs, data enrichment can be accomplished using a variety of tools, technologies, or computer languages. This can range from utilizing scripting languages like Python or R for small-scale enrichment jobs to using specific data integration or data enrichment systems that provide automation, scalability, and integration.
Different Types of Data Enrichment
Data Enrichment comes in a variety of formats that are commonly utilised today.
- Contact Enrichment:
Contact Enrichment is the practise of adding contact information (legitimate business emails, job titles, and phone numbers) to an existing database in order to create a comprehensive database of customers/leads. - Geographic Enrichment is the practise of adding address data, as well as latitude and longitude data, to customer and contact information.
- Behavioural Enrichment is the practise of examining client behavioural patterns such as prior purchases and browsing behaviours. This typically requires following a user's purchasing behaviour in order to identify key areas of interest for each customer.
- Demographic Enrichment is the practise of adding value to consumer datasets by inserting information such as marital status, family size, income level, credit score, and so on.
Advantages of Data Enrichment
-
Spend less money
- Data enrichment involves integrating valuable details from external resources to enhance your database by adding missing information, resulting in increased value and potential monetary benefits.
- Data enrichment saves businesses on expensive web services while gaining enriched records.
-
Create and Improve Customer Experience
- Data enrichment filters consumer preferences, pain areas, and requirements, enabling personalized promotional messages and communications.
- This improves understanding and builds customer relationships, enhancing businesses' ability to effectively communicate and engage with customers.
-
Increase Conversion Rate
- Data analysis helps organizations categorize consumers based on conversion potential by studying past occurrences and influencing purchasing decisions.
- Businesses may use this data to provide targeted discounts, complementary goods, or services to convert potential consumers into loyal customers, hence boosting conversion rates and driving business development.
-
Highest Quality
- Data enrichment eliminates redundancies and ensures valuable details, reducing the risk of losses and improving data management.
- By integrating data enrichment tools and techniques, businesses can automate the process, leading to efficient verification, validation, and elimination of unnecessary data entries, enhancing data accuracy and reliability.
Challenges of data enrichment:
- Data Quality and Accuracy:
External sources enhance existing data, but ensuring accuracy and quality can be challenging due to their dependability and validity, potentially causing mistakes or inconsistencies in the augmented data. - Data Integration and Compatibility:
Integrating enhanced data with existing datasets can be challenging due to compatibility checks and data transformation operations, requiring smooth and consistent data integrity. - Privacy and Security Concerns:
Data enrichment involves combining external sources like third-party suppliers and public databases, posing privacy and security concerns for organizations handling sensitive information. - Cost and Resources:
Data enrichment requires significant resources, time, and money, including acquiring, integrating, maintaining data quality, and applying appropriate technologies and tools, depending on its complexity and size.
Data Enrichment Strategies in Kafka
Data enrichment strategies in Kafka may be implemented utilizing a variety of approaches and components of the Kafka ecosystem. Here are some typical Kafka data enrichment strategies:
Data Enrichment using External Lookup in Kafka Streams
- External Lookup:
- For each click event generated in the Stream, an external lookup is performed.
- The external database user information is then integrated with the original click event.
- The combined event, which includes both the click and the user information, is saved to another subject for later processing or analysis.

-
In-App Cache
- The approach involves caching information from the database within the stream processing application.
- The cached data provides quick access to frequently accessed information, reducing the need for repeated database queries.
- However, challenges arise in ensuring the cache remains up to date as changes occur in the underlying database, requiring strategies for cache invalidation and data synchronization.
-
Change Data Capture in Stream Processing for Database Updates
- This method makes use of the change data capture (CDC) techniques or connectors included with Kafka Connect.
- CDC tasks and connections record database changes and generate a stream of events that reflect those changes.
- Stream-processing applications can listen to this event stream and update the cache in real-time based on database change events, guaranteeing that the cache is always up to current with the most recent data.
Database Joins:
- Perform database joins within Kafka consumers if the enrichment data is stored in a database.
- Consumer apps retrieve data from Kafka topics and combine it with data from databases using common IDs.
- Enhance data with database qualities or information, such as client profiles or product specifics.
Implementing Data Enrichment with Kafka Streams
KStream, KTable, and the combination of KStream and KTable, known as KStream-KTable, are stream processing abstractions offered by the Kafka Streams module in Apache Kafka.
KStream:
- KStream is a record stream abstraction in which records are treated as an unbounded, continually updating collection of records.
- It is a series of key-value pairs, with each record representing a single event or data point.
- KStream provides a high-level API for executing stream operations and transformations such as filtering, mapping, aggregation, joining, and windowing.
- KStream considers data to be an immutable and time-ordered stream of records, and it provides event-driven processing of individual events as they occur.
KTable:
- KTable is an abstraction of a changelog stream, which is a stream of table changes.
- It may be seen as a materialized representation of a stream, with each update representing the most recent value for a given key.
- KTable represents data in a table-like format, allowing for quick searching and lookup operations.
- It provides key-based operations such as table joining, filtering, aggregation, and windowing.
Methods for Enriching Kafka
Here are two approaches to Kafka Enrichment:
Join Enrichment in Kafka
- To enhance the data, this approach includes combining streams or tables in Kafka.
- Additional information can be acquired and added to the original data by matching keys between multiple streams or tables.
- Kafka Streams API or other stream processing frameworks coupled with Kafka can be used to conduct joins.
Scenario : Enriching using static (or mostly static) data:
In this scenario, you have a stream of address updates, and each message contains a state (province). You need to enrich this information with sales tax rates, which are relatively static. The code snippet shows how to perform a simple KStream-KTable non-windowed join to achieve this:
- Create a KStream from the "address-updates" topic.
- Create a KTable from the "sales-taxes" topic, where the state is the key and the sales tax rate is the value.
- Perform a selectKey operation on the address updates stream to set the state code as the new key.
- Join the address updates stream with the sales taxes table using the state code as the key.
- Perform any necessary transformations or updates on the joined data.
- Optionally, perform another selectKey operation to set the original message ID as the new key.
- Write the enriched data to the "address-updates-enriched" topic.
SQL Enrichment for Kafka
- This solution focuses on adding customer information to customer call events using Apache Kafka streaming SQL.
- The objective is to enhance data streams through quick lookups and the addition of pertinent information.
- Additional information can be collected and attached to the original event data by running SQL queries against other data sources such as databases or data lakes.
- This method allows for the real-time enrichment of streaming data with relevant consumer information, increasing the data's overall value and context.
Scenario:
cust_details: Messages carrying client information.
customer_call_details: Contains information about the call.
Make a new topic called cust_details:
Make a new topic called cust_call_details:
You may use SQL to validate the outcomes of Kafka Enrichment by retrieving the enriched data and comparing it to the original data. Here's an example of how to format your SQL query.
Case Study: Real-World Data Enrichment Scenario
Consider the following real-world data enrichment scenario: we have a stream of user activity events that we wish to enhance with extra user information obtained from an external REST API.
Here's a Java code example that shows how to accomplish this situation using Kafka Streams:
In this case:
- We set up the Kafka Streams properties, such as the application ID, bootstrap servers, and default key and value serdes.
- To specify the processing architecture, we build a StreamsBuilder object.
- The "user-activity-topic" is converted into a KStream, which represents the stream of user activity events.
- We utilize the mapValues transformation to supplement each user action event with extra user information obtained from an external API. The ValueMapper method uses the user ID from the event to query the external API and returns an EnrichedUserActivity object that combines the original user activity with the returned user information.
- The enhanced user activity events are sent to the "enriched-user-activity-topic".
- Using the stated architecture and characteristics, we develop the Kafka Streams application.
- We launch the Kafka Streams application and add a shutdown hook to handle application closure gracefully.
Conclusion
Summary of the key points:
- Data enrichment strives to boost the value and usefulness of data by including previously unavailable information.
- Enrichment data may be obtained from a variety of sources, including third-party data providers, public databases, APIs, social media platforms, CRM systems, and data aggregators.
- Data enrichment strategies include data appending, cleaning, deduplication, and normalisation.
- Data enrichment implementation can range from simple scripting languages like Python or R for small-scale activities to specialised data integration or enrichment systems.
- Cost savings, greater customer experience, higher conversion rates, and higher data quality are all advantages of data enrichment.
- Kafka supports data enrichment through external lookup, in-app cache, change data capture, and database joins, enhancing processing and analysis.
The importance of Kafka in modern data enrichment tasks:
- Scalability:
Kafka is designed for large-scale data processing, enabling horizontal scaling and real-time analysis of massive volumes. - Real-time Processing:
Because Kafka can handle streaming data in real-time, it is perfect for data enrichment jobs that demand quick processing and response. It supports low-latency data intake and processing, enabling you to enhance data as it moves through the system. - Data Durability:
Kafka provides long-term, fault-tolerant storage for data streams, reducing data loss risk. It integrates with various data sources, including databases, APIs, and external services, using Kafka Connect for quick data enrichment. - Exactly-once Processing Semantics:
Kafka Streams uses precisely-once processing semantics, processing each record once, ensuring data consistency, integrity, and prevents duplication or loss during enrichment.
Encouragement to further explore and implement data enrichment with Kafka
Ideas for encouraging further investigation and implementation of data enrichment with Kafka in many domains:
- Real-time Fraud Detection:
Implement a data enrichment pipeline that enriches transactional data with historical fraud trends, user behaviour analytics, and other data sources to detect and prevent fraud in real-time. - Personalized Recommendations:
Create a recommendation system by enhancing user profiles with demographic information, browsing history, buying trends, and social media activities. Use this augmented data to provide personalized suggestions to users in real-time. - Geolocation-based Services:
Add geolocation information from GPS or IP addresses to user data. Use this enhanced data to offer location-based services, targeted advertising, or optimized route planning. - Real-time IoT Data Enrichment:
Combine data from IoT devices with contextual information such as weather, user profiles, or historical data. This improved data may be utilized for real-time monitoring, predictive maintenance, and anomaly detection. - Dynamic Pricing:
Combine pricing data with market trends, competitor prices, and customer demand information. Use this improved data to dynamically change pricing in real-time, increasing revenue and competition.