Troubleshooting Kafka Common Issues and Their Resolutions
Overview
Apache Kafka is a distributed streaming system for managing real-time data flows, offering high throughput and low latency. It operates as a cluster across multiple machines in data centres and organizes data into topics. Troubleshooting Kafka is crucial for maintaining system stability, data integrity, and optimal performance. Addressing issues like message loss, consumer lag, and ZooKeeper dependency enhances data streaming system stability, performance, and reliability.
Brief Overview of Apache Kafka
Apache Kafka is an open-source distributed event streaming service for high-performance data pipelines, analytics, integration, and critical applications, utilizing the publish/subscribe messaging system.
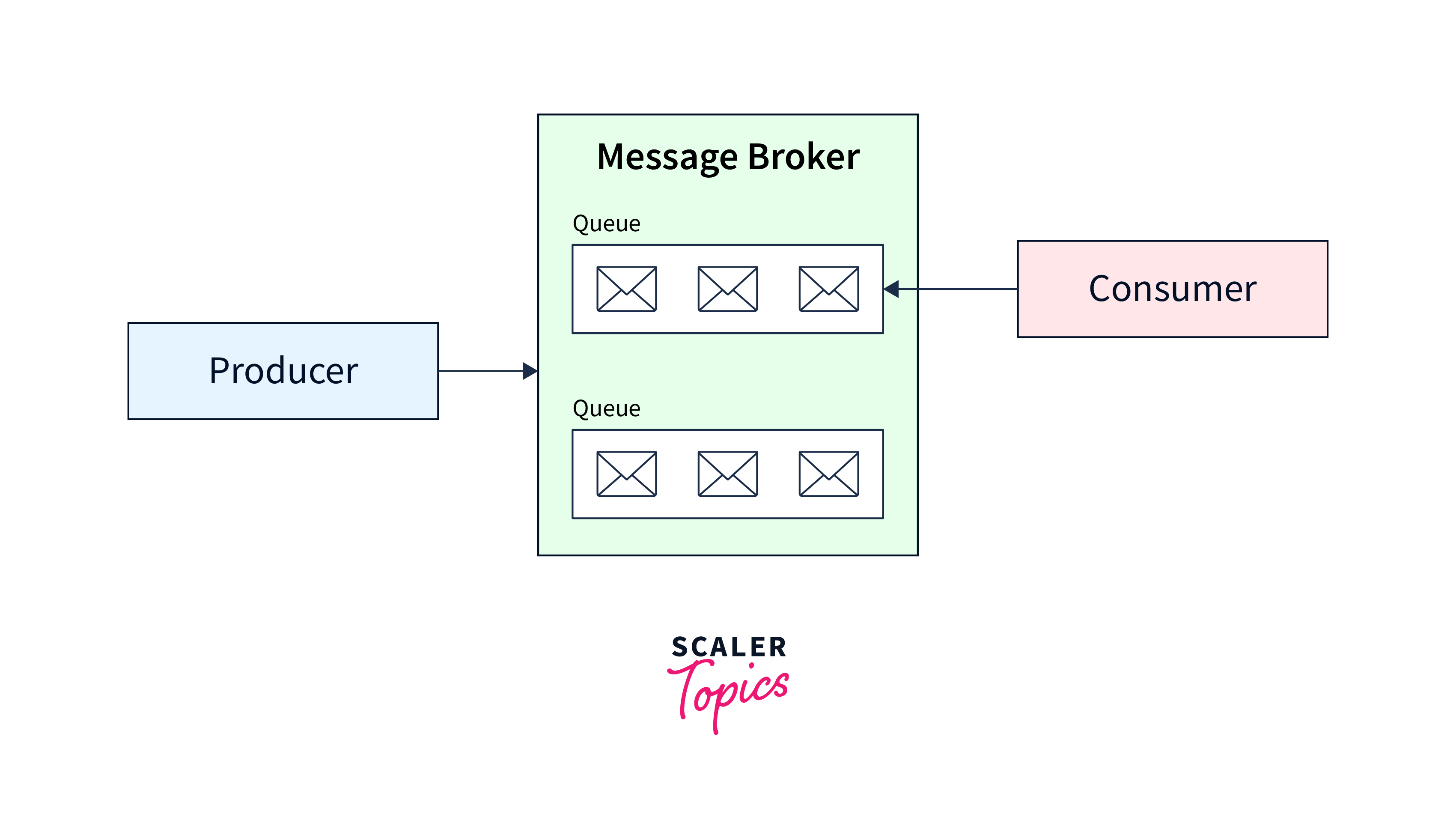
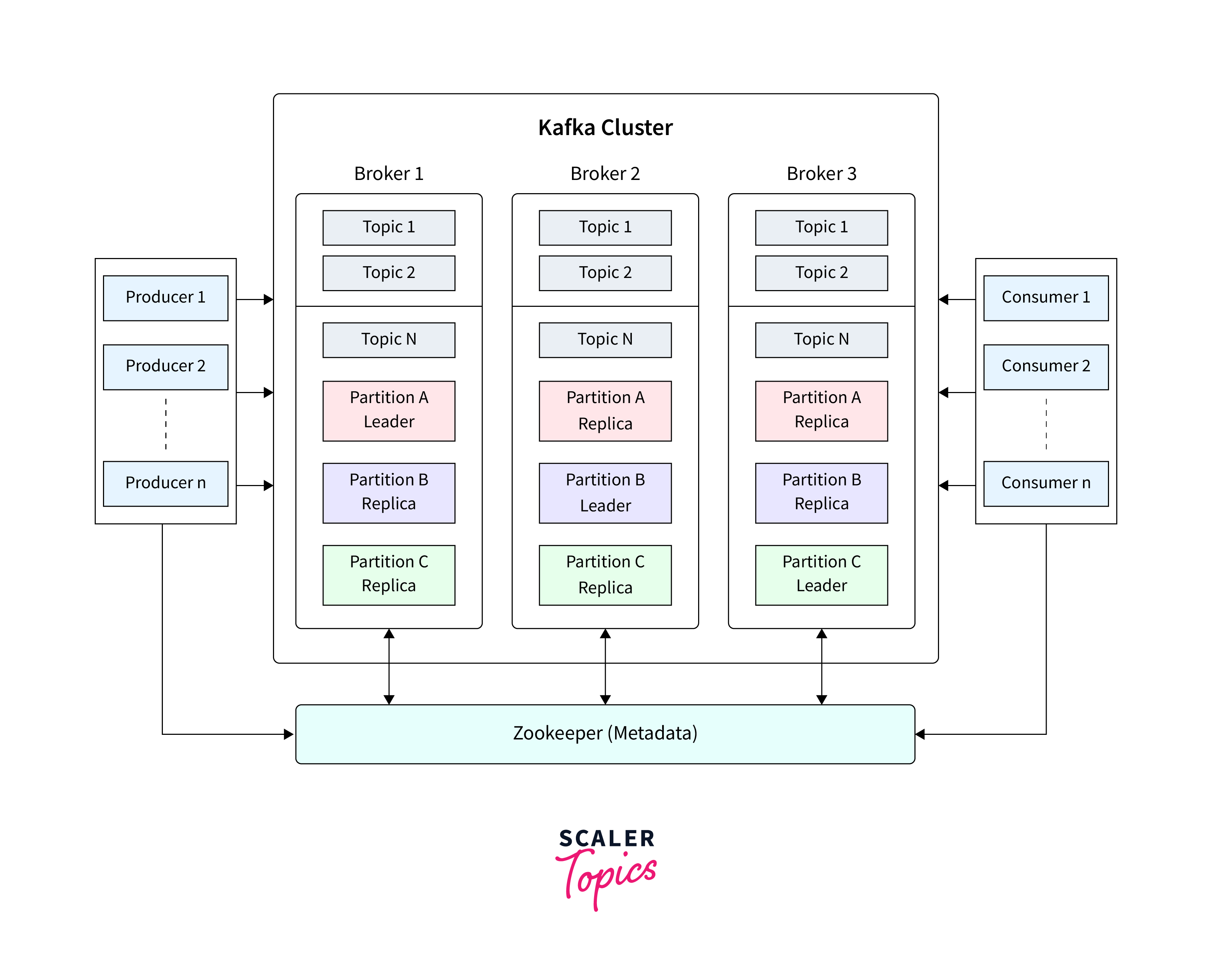
Various applications use different methodologies when developing the architecture of Apache Kafka. However, other fundamental components are required to build a strong Kafka architecture, including Kafka Cluster, Producers, Consumers, Brokers, Topics, Partitions, and Zookeepers.
Importance of Troubleshooting in Maintaining a Robust Kafka Setup
Troubleshooting is vital for keeping a stable Kafka configuration. It aids in rapidly identifying and resolving faults, ensuring the system's stability and dependability.
1.Set log configuration parameters to keep logs manageable
- Log behaviour in Kafka may be tweaked using settings like log.segment.bytes, log.segment.ms, and log.cleanup.policy.
- The log.segment.bytes option specifies the maximum byte size of each log segment.
- The log.segment.ms parameter sets how long a log segment can be open before it is closed and a new segment is produced.
- The log.cleanup.policy or topic-level equivalent argument controls how logs are maintained.
- Setting cleanup.policy to "delete" instructs Kafka to remove log files of a given size or after a certain period.
2.Understand Kafka's (minimal) hardware requirements.
- CPU : Kafka requires a powerful CPU for SSL and log compression, with more cores enhancing parallelization. LZ4 codec is recommended for optimal performance when compression isn't a factor.
- RAM : In most circumstances, 6 GB of RAM for heap space is sufficient for Kafka to function properly. Use computers with 32 GB or more for extremely severe production loads. Extra RAM will be utilised to beef up the OS's page cache and boost client performance.
- Disk : When employing many discs in a RAID configuration, Kafka flourishes. Because of Kafka's sequential disc I/O architecture, SSDs provide little benefit, and NAS should be avoided.
- Network and filesystem : XFS is advised, as is maintaining your cluster in a single data centre if possible. Additionally, provide as much network bandwidth as feasible.
3.Use parallel processing
- Kafka is built for parallel processing, which necessitates a careful balance to best utilize its potential.
- In Kafka, the partition count controls the amount of parallelization and performance.
- More partitions result in more parallelization and performance.
- However, having additional divisions increases replication delay, rebalancing cost, and the number of open server files.
- According to a conservative estimate, one partition on a single topic can generate 10 MB/s of throughput.
- You may compute the total throughput required by extrapolating from this estimate and determining the number of partitions appropriately.
- Another option for testing is to employ one partition per broker per topic and assess the outcomes. If you need greater throughput, you may double the number of partitions.
- It is typically advised that the total number of partitions for topic be less than 10, and the total number of partitions for the cluster be less than 10,000.
Understanding Apache Kafka
What is Apache Kafka?
Apache Kafka is a distributed streaming technology that was created by LinkedIn and contributed to the Apache Software Foundation. The Scala and Java-based project seeks to create a uniform, high-throughput, low-latency framework for managing real-time data flows. A streaming platform, by definition, has three main capabilities:
- Publish and subscribe to record streams, much like a message queue or business messaging system.
- Store record streams in a fault-tolerant and long-lasting manner.
- Process record streams as they come in.
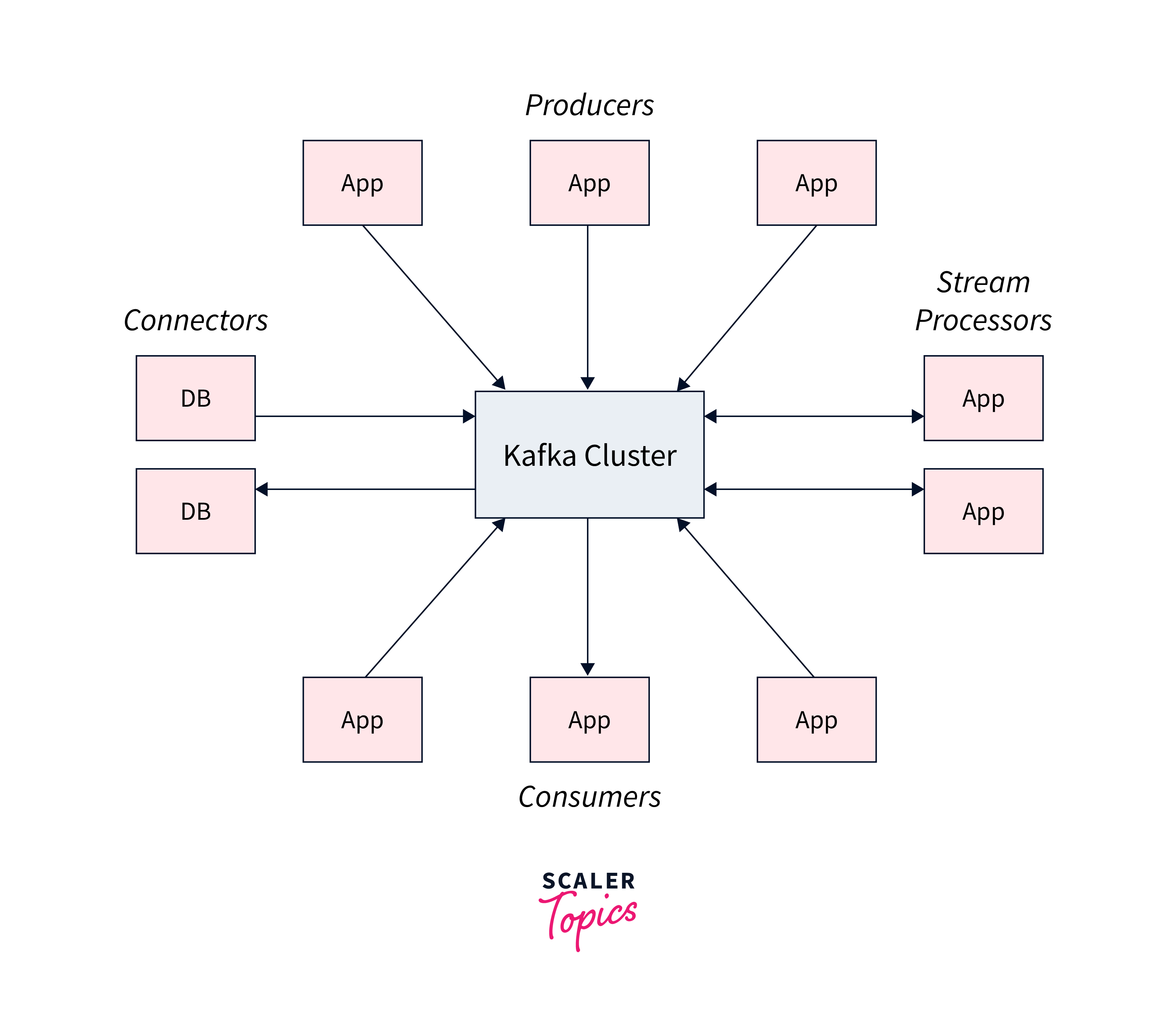
Kafka provides five key APIs for communication with topics:
- Producer API : enables the publication of a stream of records to one or more topics.
- Consumer API : allows you to subscribe to one or more topics and handle the stream of records that are sent to you.
- Streams API : allows you to function as a stream processor, ingesting an input stream from one or more topics and providing an output stream to one or more output topics, thereby converting input streams to output streams.
- Connector API : Reusable producers and consumers link Kafka topics to existing applications or data systems.
- Admin API : lets you manage and examine Kafka topics, brokers, and other objects.
Basic Components of Kafka: Producers, Consumers, Brokers, Topics
a. Producers
- Producers publish data to Kafka topics.
- Producers determine which partition within a topic a record should be assigned to.
- Partition assignment can be done in a round-robin fashion or based on a specified function.
- The key of a record is used to determine the partition assignment.
- The key can be of any data type, such as a string or number.
- If the key is null, data is sent to partitions in a round-robin manner.
- If the key is not null, all messages with the same key will go to the same partition.
b. Consumers
- Consumers are recognised by a consumer group name when they read data from Kafka topics.
- Consumer groups guarantee that all members of the group read from exclusive partitions.
- Some consumers will be idle if there are more customers than partitions.
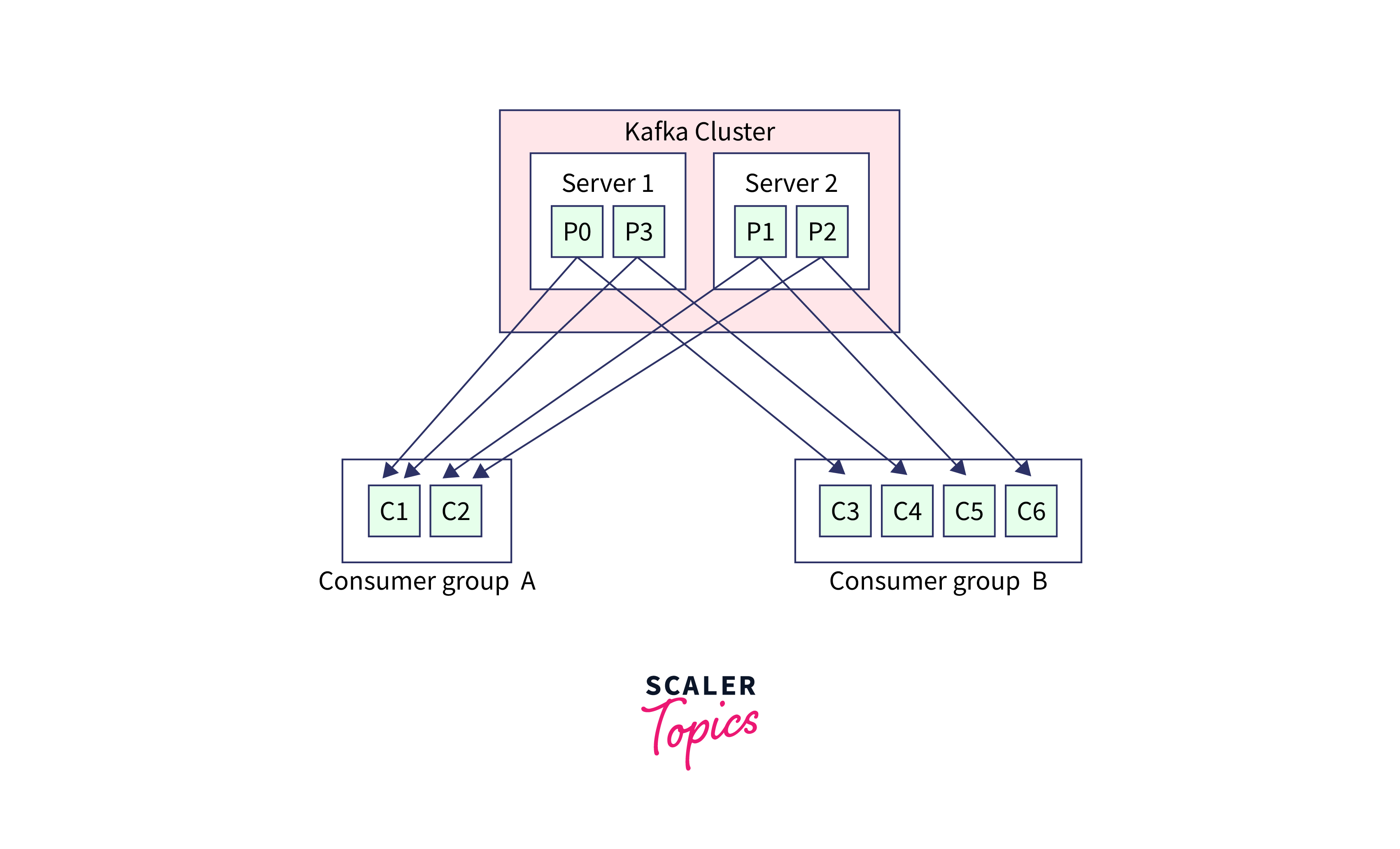
- Consumer offsets represent a consumer group's perspective on an issue.
- Consumer offsets are saved in Kafka's internal __consumer_offsets topic.
- After consuming a message, offsets must be committed to guarantee that it is not consumed again until the offset is reset.
- Consumers are aware of which broker to read from and can failover if one fails.
- Consumers who read from a partition preserve the sequence of record publication.
- There is no set order for two divisions of the same topic.
- For customers, Kafka has three delivery semantics: at most once, at least once, and exactly once.
- At most : At most, once commits offsets as soon as a message is received, which may result in missing messages.
- At least : At least once commits offsets after processing a message, allowing for message reprocessing in the event of errors.
- Exactly once : It is possible to accomplish this utilising the Kafka Streams API for Kafka-to-Kafka workflows and idempotent consumers for Kafka-to-External System workflows.
c. Brokers
- A single Kafka server is referred to as a Kafka Broker. That Kafka broker is a program that operates on the Java Virtual Machine, and typically, a server designed to be a Kafka broker will only execute the essential program and nothing more.
- A Kafka cluster is a group of Kafka brokers that work together. Some clusters may have only one broker, while others may have three or hundreds of brokers.
- A broker in a cluster is recognised by a unique numeric ID. The Kafka cluster in the diagram below is made up of three Kafka brokers.
- Companies like Netflix and Uber often operate large Kafka clusters with hundreds or thousands of brokers to handle their data.
- Each broker within a Kafka cluster is identified by a unique numeric ID.
- In a typical Kafka cluster, multiple brokers work together to handle data processing and replication tasks.
d.Topics
- In Kafka, a topic is a category or a common name used to store and publish a specific stream of data.
- Topics in Kafka are similar to tables in a database but do not have the same constraints.
- Multiple topics can be created in Kafka, and each topic is identified by its name, chosen by the user.
- Producers publish data to topics, while consumers read data from topics by subscribing to them.
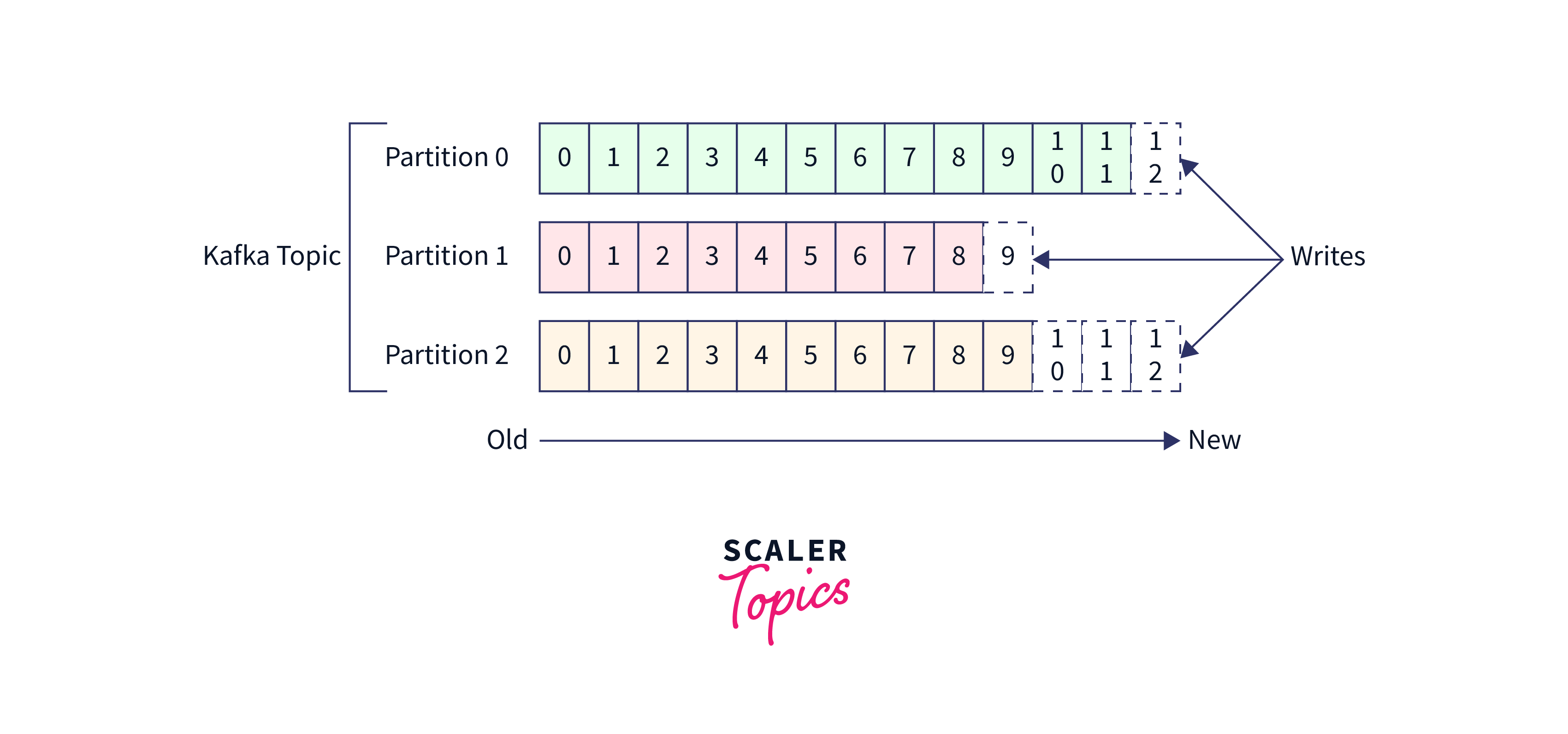
- A topic is divided into partitions, which are separate and ordered parts of the topic.
- The data content is stored within the partitions of a topic.
- When creating a topic in Kafka, the number of partitions needs to be specified.
Common Kafka Issues
Description of Common Kafka Problems
- Message Loss: Messages may be lost in some situations during producer-to-broker or broker-to-consumer contact. This might occur as a result of network difficulties, misconfiguration, or wrong acknowledgement handling.
- High Consumer Lag: Consumer lag is the time lag between when communications are created and when they are consumed by consumers. When customers are unable to keep up with the message pace or when there are challenges with consumer group rebalancing, high consumer lag might emerge.
- Slow Consumer Performance : When consumers process messages, they may encounter slower performance, resulting in bottlenecks and delays in data processing. Inefficient consumer code, high processing times, or insufficient resource allocation can all contribute to this.
- Unbalanced Partition Distribution : Kafka partitions should be uniformly distributed between brokers and consumer instances. However, an imbalanced partition distribution might develop as a result of misconfigurations, failing brokers, or unequal consumer group rebalancing. This can have an influence on performance and produce unequal workloads.
- ZooKeeper Dependency Issues : Apache ZooKeeper is used by Kafka to manage cluster coordination and metadata. ZooKeeper concerns, such as speed issues, connection issues, or data corruption, might have an influence on Kafka's overall stability and functioning.
Importance of Understanding and Addressing these Issues
- System Stability : Addressing these challenges contributes to the Kafka system's stability and dependability. You can minimise service disruptions, avoid data loss, and maintain the seamless running of your data pipelines by correcting problems as soon as they arise.
- Data Integrity : Kafka is essential for mission-critical data processing, requiring identification and resolution of concerns to ensure data integrity. Addressing issues like inconsistencies, message loss, and corruption can improve dependability and reliability.
- Performance Improvement : Common Kafka performance issues can cause delayed message processing, excessive latency, or resource constraints. Understanding these issues optimizes setups, tweaks performance, and manages resources, improving system performance and throughput.
- Efficient Troubleshooting : Understanding typical problems helps efficiently troubleshoot issues by identifying potential problems, their causes, and alternative solutions, reducing mean time to resolution and operational downtime.
- Minimizing Downtime : Identifying and resolving issues as soon as possible helps to reduce system downtime. By proactively correcting errors, you may minimise the impact on downstream operations, eliminate cascade failures, and ensure uninterrupted data availability for customers.
Broker Issues and Their Solutions
The following are some frequent broker concerns and associated solutions:
- Broker Error:
- Problem: A broker fails due to hardware problems, network challenges, or other factors.
- Solution: Kafka is built to gracefully manage broker failures. It employs replication to ensure data replication across several brokers. When a broker fails, Kafka automatically chooses a new leader for the partitions hosted by the failed broker.
- Partitions with Insufficient Replication:
- Problem: A topic's replication factor is set to more than one, yet certain partitions have fewer copies than the preset replication factor.
- Solution: This problem can arise when a broker is unavailable or when a new broker is introduced but not properly replicated. Kafka continually checks the replication state and reassigns replicas to maintain the appropriate replication factor.
- Election of an Unclean Leader:
- Problem: By default, Kafka permits unclean leader election, which implies that a replica that is not completely caught up with the leader might be elected as the new leader during a broker failure.
- Solution: An Unclean leader election might result in data loss. To avoid this, set the unclean.leader.election.enable property in the broker settings to false.
- Problems with the network:
- Problem: Kafka brokers may face network connectivity issues, resulting in data replication or client connection delays or failures.
- Solution: Keep track of the network connectivity between brokers and customers. Figure out that the network infrastructure is stable and well-configured. Troubleshoot any network difficulties and think about creating redundant network pathways for high availability.
Producer Issues and Their Solutions
Producers in Apache Kafka topics face challenges in data input and dependability, including issues with data input and reliability. Possible solutions include:
- Message Send Error:
- Problem: The producer fails to deliver messages to Kafka owing to network problems, broker outages, or other faults.
- Solution: In the producer application, implement correct error handling and retries. Configure necessary configuration parameters like retries and retry.backoff.ms is used to set the number of retries and the duration between retries. For retries, consider using an exponential backoff method.
- Data Error:
- Problem: The producer's messages are not correctly written to Kafka, resulting in data loss.
- Solution: Set the proper acks setting on the producer. Setting acks to "all" for example guarantees that messages are sent to all in-sync replicas before an acknowledgment is sent back to the producer. Consider using the idempotent producer configuration to offer idempotent message delivery, which aids in preventing duplicate messages during retries.
- Problems with Configuration:
- Problem: Improper or poor producer configuration might cause performance problems or failures.
- Solution: Examine and confirm the producer setup parameters. Based on your needs and circumstances, be sure to provide suitable values for attributes such as bootstrap.servers, acks, retries, batch.size, linger.ms, and so on. For extensive descriptions of each configuration property and its suggested settings, see to the Kafka manual.
- Producer Efficiency:
- Problem: The producer is unable to maintain the necessary message throughput, resulting in latency or limits.
- Solution: Monitoring producer performance parameters such as message rate, latency, and buffer utilization is the solution. Ascertain that the producer is operating on hardware capable of handling the specified workload. To optimize batching behaviour and decrease network cost, modify the batch.size and linger.ms configuration variables. Consider asynchronous sending with callbacks to increase speed by allowing the producer to keep delivering messages while waiting for acknowledgements.
Consumer Issues and Their Solutions
Consumers in Apache Kafka handle data consumption and application dependability, encountering challenges like data consumption and application dependability. Common problems and solutions include:
- Imbalance in the Consumer Group:
- Problem: Consumers within a consumer group may be unequally distributed among partitions, resulting in uneven data processing and possible performance bottlenecks.
- Solution: Monitor and rebalance the partition assignment of the consumer group. Ascertain that the group's size corresponds to the intended parallelism. When a customer quits or enters the group, Kafka does an automated rebalancing. The configuration parameters group.max.session.timeout.ms and group.min.session.timeout.ms are used to manage the rebalancing behaviour.
- Offset Management:
- Problem: Consumers may experience offset management concerns such as committing offsets too frequently, not committing offsets at all, or committing erroneous offsets.
- Solution: Understand and apply the required offset management technique depending on your application needs. To control when offsets are committed, use the commitSync() or commitAsync() methods. To balance offset commit frequency, use an appropriate auto.commit.interval.ms.If necessary, consider utilizing the seek() and seekToBeginning() methods to reset the consumer's location inside a partition.
- Impact on Rebalancing:
- Problem: Rebalancing consumer groups might momentarily impair data processing, creating delays or pauses.
- Solution: Understand the rebalancing behaviour and how it affects your consumer application. To regulate the rebalancing behaviour, choose suitable consumer session timeouts (session.timeout.ms) and heartbeat intervals (heartbeat.interval.ms). To manage rebalance-related problems and guarantee smooth recovery, include error handling and retry capabilities in your consumer application.
Conclusion
- Apache Kafka : Distributed streaming system for real-time data flow management.
- Common Kafka issues Message loss, high consumer lag, slow consumer performance, unbalanced partition distribution, ZooKeeper dependency problems.
- Challenges for Producers and Consumers : Message send errors, data errors, configuration problems, efficiency issues.
Importance of Proactive Troubleshooting for Kafka's Optimal Performance
- Early Detection of challenges : Kafka proactive monitoring and troubleshooting detect anomalies and bottlenecks early, enabling resolution and minimizing system impact through performance metrics.
- Prevention of System Downtime : Proactive troubleshooting monitors Kafka brokers, producers, and consumers' health, identifying issues before critical failures, and ensuring cluster availability and reliability.
- Optimal Resource Usage : Proactive troubleshooting optimizes Kafka cluster resource utilization by monitoring CPU, memory, and disk I/O metrics, identifying bottlenecks, and adjusting allocations for smooth operation.
- Performance Optimization : Proactive troubleshooting helps identify and address performance bottlenecks in Kafka deployment by monitoring latency, consumer lag, and network throughput. Optimizing configurations, consumer group assignments and resource scaling can improve overall performance and reduce latency.
Encouragement to Further Explore Kafka Troubleshooting
- Improve Your Problem-Solving Skills : Troubleshooting Kafka fosters critical thinking and creative problem-solving, enabling users to analyze symptoms, identify causes, and apply remedies, promoting professional advancement across various disciplines.
- Contribute to the Community : Learn Kafka troubleshooting to contribute to the community by sharing knowledge and experiences. Participate in forums, discussion groups, and open-source initiatives to help others solve issues and increase knowledge exchange.
- Improve System Dependability : Explore Kafka troubleshooting to identify and fix system dependability issues, including broker failures, data loss, and consumer slowness, ensuring high system uptime.
- Gain a Detailed Knowledge of Kafka Architecture : Troubleshooting Kafka helps understand its fundamental architecture and its components, including topics, partitions, brokers, producers, and consumers. This knowledge helps make informed decisions and build robust Kafka solutions.