Kafka Message Acknowledgement: A Deep Dive
Overview
Apache Kafka is a distributed event streaming platform that allows for high-speed, fault-tolerant, and scalable data streaming. Real-time data processing, event-driven architecture, and integration across various applications. Kafka Message acknowledgment is critical for assuring data consistency and dependability. Acknowledgement mechanisms ensure proper communication processing, storage, and data loss prevention, balancing dependability and performance. Optimizing Kafka setups and techniques can improve performance and address possible bottlenecks.
Brief Explanation of Apache Kafka
- Apache Kafka is a distributed event streaming framework that provides high-throughput, fault-tolerant, and scalable data streaming.
- It enables the publication and consumption of records streams, which might be structured data, logs, or event data.
- Kafka enables long-term storage of messages and effective distribution of messages across various producers and consumers.
- It supports real-time data processing, event-driven structures, and data integration in a variety of applications such as streaming analytics, data pipelines, and messaging systems.
Importance of Message Acknowledgement in Kafka
- To maintain data dependability and consistency, message acknowledgment is critical in Kafka.
- When a producer delivers a message, it wants confirmation that the message was received and processed correctly by Kafka.
- Acknowledgement methods like leader acknowledgements and in-sync replicas are crucial for data persistence. Producers can obtain acknowledgements from Kafka brokers, ensuring messages are retained and copied across multiple brokers.
- This reduces the danger of data loss while also ensuring data consistency, resulting in dependability and confidence in data processing and consumption.
Role in the Kafka Producer-Consumer Model
Role of Producer :
- The producer sends messages to Kafka topics and can wait for acknowledgment from the broker or continue without waiting.
- Waiting for acknowledgment allows the producer to determine if the message was successfully written to the subject, which may include the message's topic, partition, and offset.
Role of Kafka Broker:
- The Kafka broker accepts messages from producers and stores them in topic partitions.
- When a message is successfully written to a topic partition, the broker provides an acknowledgement to the producer.
- The acknowledgment validates the delivery status, indicating whether the message was properly written or if an issue occurred during the procedure.
Role of Consumers:
- Offsets are unique identifiers assigned to each message within a Kafka partition.
- They represent the consumer's progress in reading messages and enable resuming from where they left off.
- Offsets ensure fault tolerance by allowing consumers to handle failures gracefully.
- When a message is successfully processed, the consumer commits the offset, recording its progress.
- In case of a consumer failure and restart, the last committed offset is retrieved to resume from that point, avoiding data loss.
- Offsets also prevent message duplication in Kafka.
- Consumers commit offsets after processing messages, preventing reprocessing in case of failures or restarts.
- By committing the offset, the consumer signals that it has processed messages up to that point.
- When a consumer restarts, it starts consuming from the last committed offset, avoiding duplication of previously processed messages.
What is Kafka Message Acknowledgement
Definition of Kafka Message Acknowledgement
Kafka Message Acknowledgement acknowledges successful message processing by consumers using the offset commit mechanism, allowing consumers to regulate consumption rate and processing time.
- Kafka consumers automatically acknowledge message processing upon broker acquisition, ensuring instant processing regardless of efficiency, regardless of message efficiency.
- Manual Acknowledgement (Sync):
Consumers can manually acknowledge synchronous processing through the commitSync() function, ensuring balance accuracy and broker confirmation before proceeding with subsequent messages. - Manual Acknowledgement (Async):
The commitAsync() function enables consumers to acknowledge messages asynchronously, increasing throughput but causing potential message repetition in breakdown situations.
Importance in Data Reliability and Consistency
-
Data Integrity and Durability:
Kafka's message acknowledgment ensures data integrity and durability by confirming message saved and copied into brokers, ensuring data remains accessible even during failures or network challenges. -
Consistency in Distributed Systems:
Kafka enables distributed message processing with numerous consumers, ensuring data consistency through message acknowledgment. Consumers recognize processed messages' offsets, ensuring proper ingest and processing, ensuring data is in the proper condition. -
Message Delivery Reliability:
Message acknowledgement ensures dependable Kafka topic delivery, preventing message loss and data delivery dependability by confirming message success with the broker, ensuring data delivery reliability.
Understanding Acknowledgement Modes in Kafka
-
Kafka's acknowledgment modes, "acks=0", "acks=1," and "acks=all," impact message durability by affecting the message's content and ensuring its durability. "acks=0":
- In this mode, producers do not wait for the broker to acknowledge the message before considering it transmitted.
- As a result, there is no assurance that the message will last.
- If a broker fails before receiving the message, the data may be lost and irrecoverable.
"acks=1": - This mode has a medium amount of durability.
- Producers wait for the leader broker to indicate that the message has been written to its local log.
- When the message is acknowledged by the leader, the producer deems it to have been effectively conveyed.
- The message, however, will be lost if the leader broker fails before duplicating the message to other replicas.
"acks=all": - This mode has a medium amount of durability.
- Producers wait for the leader broker to indicate that the message has been written to its local log.
- When the message is acknowledged by the leader, the producer deems it to have been effectively conveyed.
- The message, however, will be lost if the leader broker fails before duplicating the message to other replicas.
-
Retries and Timeout:
In addition to the acknowledgement mode, Kafka producers can specify retries and timeouts.- The retries attribute specifies how many times a producer will deliver a message if an acknowledgement is not received. It aids in the handling of temporary failures.
- The retry.backoff.ms attribute defines how much time should elapse between retries.
- The delivery.timeout.ms attribute specifies how long the producer will wait for an acknowledgement before marking the message as unsuccessful.
Diving into Replicas and In-sync Replicas
Replicas in Kafka are copies of data that are kept in separate brokers inside a Kafka cluster. Replication ensures fault tolerance and data longevity by replicating data across several brokers.
Concept of Replication in Kafka
Kafka replication occurs at the partition level, with copies stored in multiple broker instances using the partition's write-ahead log. Each partition in a topic has a unique offset for identifying messages, and the replication factor determines the number of copies required.
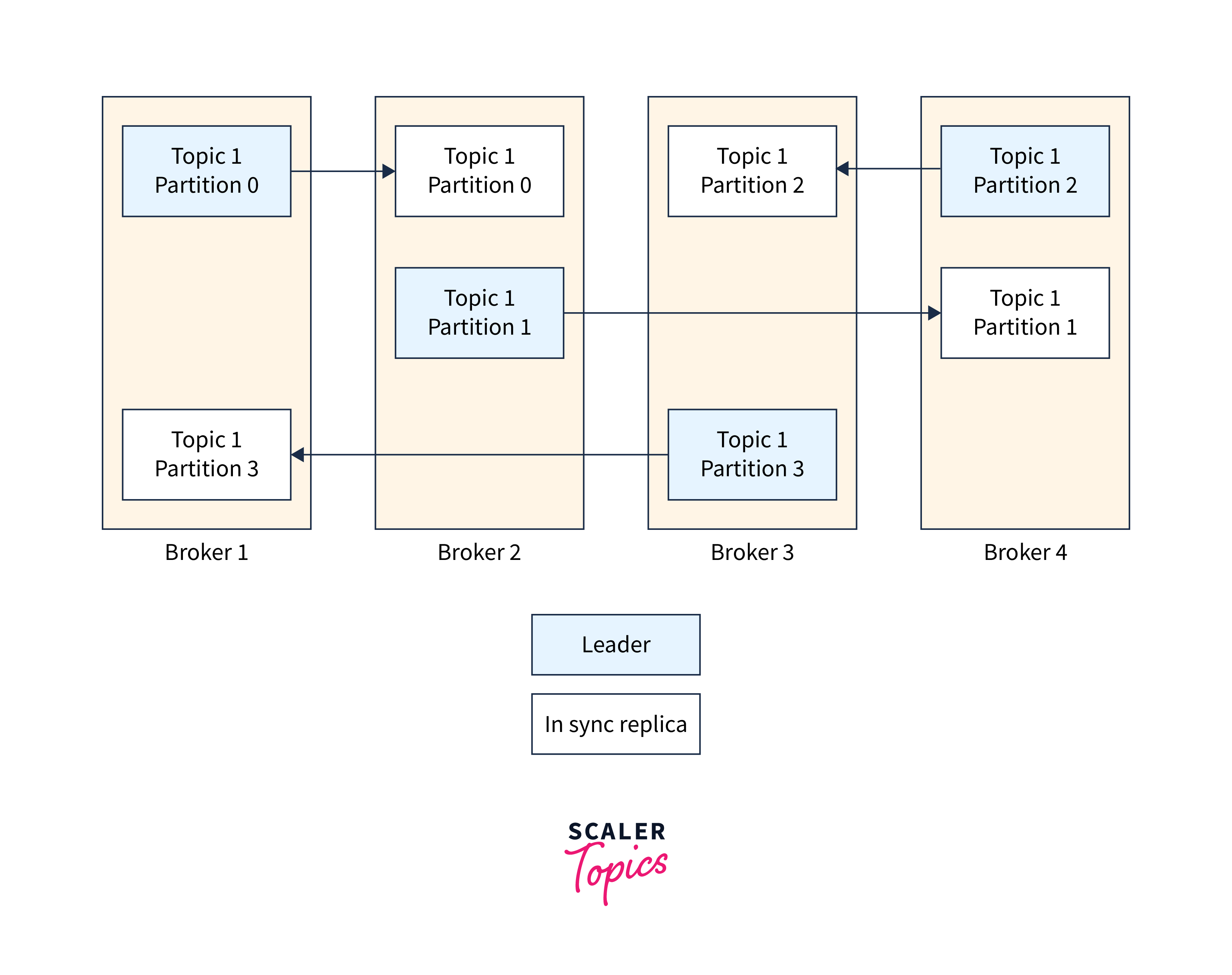
A replication factor of two indicates that each partition will have two copies.
Partition leader :
A replica is selected as the partition's leader for each partition. The Leader is in charge of both transmitting and receiving data for that partition. The partition's in-sync replicas (or followers) are all the other replicas.
Role of In-sync Replicas (ISRs)
- In-Sync Replicas (ISRs) in Apache Kafka are replicas that are synchronized with the leader replica for a partition.
- These replicas replicate all messages acknowledged by the leader and are considered in-sync.
- If a follower broker lags behind the latest data, it is no longer considered an in-sync replica.
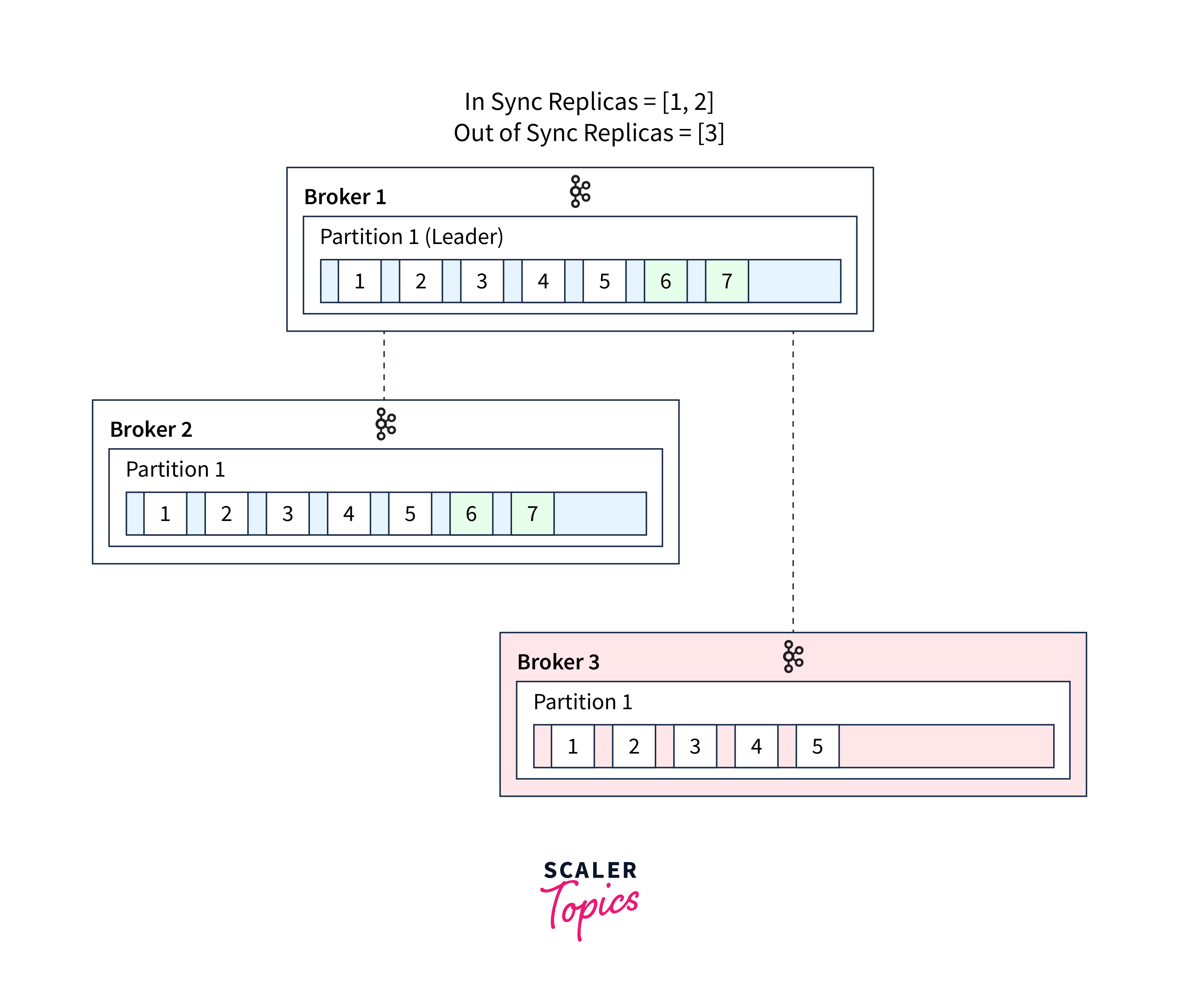
Data durability and consistency:
- ISRs maintain data durability and consistency by requiring messages to be successfully replicated to all replicas in the ISR group before they are considered committed.
- This ensures that communications are securely kept among many brokers, lowering the chance of data loss.
- Kafka gives strong assurances on data consistency by getting acknowledgments from ISRs.
Fault Tolerance:
- ISRs are crucial for maintaining fault tolerance and high availability in Kafka.
- In the event of a leader replica failure, one of the replicas from the ISR group is selected as the new leader.
- Since ISRs are already synchronized with the leader, the new leader can seamlessly handle read and write requests without data loss or inconsistency.
- ISRs serve as a pool of replicas eligible for leadership, ensuring high availability and fault tolerance during leader failures.
The Connection Between Replicas, ISRs, and Acknowledgements
In Apache Kafka, the link between replicas, In-Sync Replicas (ISRs), and acknowledgements is critical for maintaining data persistence, fault tolerance, and message dependability.
Replicas and Acknowledgements:
- Replicas are data copies that are distributed across various brokers in a Kafka cluster.
- When a producer delivers a message to a Kafka topic, it transmits it to the partition's leader replica.
- The leader replica is in charge of processing the produce request and communicating with the producer.
- The leader replica's acknowledgement shows that the message was successfully written to the leader's local log.
In-Sync Replicas (ISRs) and Acknowledgements:
- In-Sync Replicas (ISRs) are a subset of replicas that are synchronised and up-to-date with the partition's leader replica.
- When the leader replica gets a message and acknowledges it to the producer, the message is replicated to the ISRs as well.
- The acknowledgement from the leader replica is independent of the ISRs' acknowledgement.
- The leader replica, on the other hand, keeps track of the ISRs' acknowledgement state individually.
Acknowledgements and Durability:
- Acknowledgements are critical in Kafka for assuring data persistence.
- Kafka's default configuration sets "acks=1" to indicate leader replica acknowledges message in local log.
- This acknowledgement ensures that the message is held in at least one broker indefinitely.
- Replicas, including ISRs, replicate the message in the background asynchronously, guaranteeing redundancy and durability across many brokers.
Replication and Fault Tolerance:
- Replication, including the usage of ISRs, enables fault tolerance in Kafka.
- If the leader replica fails, one of the ISRs is picked to be the replacement leader replica.
- The new leader replica takes over the processing of read and write requests for the partition.
- Acknowledgements from ISRs are critical during leader failover to guarantee that the new leader replica has the most up-to-date data and can continue serving messages without data loss.
Handling Failures and Data Loss
The following are best practices for addressing faults and reducing data loss in Kafka:
Monitoring Techniques:
- Establish reliable monitoring mechanisms to track the health and performance of Kafka clusters, brokers, and consumers.
- Keep track of important parameters such as message throughput, latency, partition lag, and broker availability.
- Use monitoring technologies such as Prometheus, Grafana, or the built-in monitoring features of Kafka.
Retries and proper error handling:
- In your Kafka apps, utilise correct error handling and retries.
- Handle errors with mercy and have procedures in place to retry unsuccessful operations.
- To avoid overloading the system, configure suitable retry rules using backoff and exponential backoff techniques.
Health Replica:
- Ensure that Kafka replicas are healthy and synchronised.
- Keep an eye on the replication latency between the leader and follower replicas.
- Check the ISR (In-Sync Replicas) list on a regular basis to verify that replicas are up to current.
Recovery from a disaster:
- Disaster recovery measures, such as data replication across several data centres or regions, should be implemented.
- Make use of Kafka's built-in functionality, such as MirrorMaker, for cross-datacenter replication.
- Restore Kafka metadata and configurations on a regular basis.
Performance Considerations
The Impact of Acknowledgement Mode on Performance
- Kafka's acknowledgment mode determines message processing dependability and performance. Acks can be set to "all" for synchronous, "none" for asynchronous, or "1" for leader acknowledgement.
- Synchronous mode offers maximum dependability but may cause lesser throughput and latency.
- Asynchronous mode with "none" offers better throughput and reduced latency, but increases the risk of message loss.
Trade-Off Between Reliability and Performance
- Kafka balances dependability and performance, with higher degrees of dependability providing stronger assurances but potentially impacting performance due to increased latency and decreased throughput.
- Lower degrees, like asynchronous mode with "none" acknowledgements, may enhance speed but increase message loss risk.
Fault Tolerance
- Check that replication factors are properly configured to provide data redundancy and fault tolerance.
- Maintain the health of Kafka replicas to avoid data loss in the event of broker failure.
- For disaster recovery and high availability, consider deploying several Kafka clusters or datacenter replication.
Partitioning Techniques
- Proper topic partitioning is critical for spreading data and workload over numerous brokers while maintaining good throughput.
- Based on your use case, select an effective partitioning technique, taking into account aspects such as data distribution needs, key-based partitioning, and round-robin partitioning.
- Over-partitioning can have a detrimental influence on performance and increase overhead.
Load Balancing
- Distribute the load evenly across Kafka brokers to make the most use of resources.
- Consider placing a load balancer in front of Kafka brokers to ensure that client connections and requests are distributed equitably.
- Maintain optimal performance by monitoring broker metrics and adjusting the load balancing settings as appropriate.
Conclusion
- Apache Kafka is a distributed event streaming platform for high-throughput data streaming.
- Message acknowledgment in Kafka provides data dependability and consistency.
- In Kafka, acknowledgement modes trade-off between reliability and performance.
- Kafka's performance may be improved by optimising setups and methods.
- Replication and in-sync replicas (ISRs) enable data durability and fault tolerance.
- Managing failures in Kafka is critical for maintaining data consistency and minimising loss.
- Choosing the appropriate acknowledgement mode matches with specific use case needs.
- Performance limitations in Kafka are addressed by optimisation and monitoring.
Importance of Understanding Kafka Message Acknowledgement for Data Consistency
- Understanding Kafka message acknowledgment is critical for ensuring data integrity in Kafka.
- Message acknowledgment guarantees that producers obtain assurance that their messages have been correctly processed and duplicated by Kafka brokers.
- It ensures that messages are persistently saved and copied across several brokers, lowering the risk of data loss.
- Kafka's flexible acknowledgement methods, such as leader acknowledgements and in-sync replicas (ISRs), are critical in maintaining data consistency and durability.
- Users may accomplish dependable and consistent data processing and consumption by understanding and using Kafka message acknowledgment.
Encouragement to Further Explore Kafka Configurations
- Kafka provides a number of configuration options for users to fine-tune features such as acknowledgement modes, retries, timeouts, and partitioning algorithms.
- Understanding and modifying these variables based on individual use cases may significantly improve Kafka system efficiency and scalability.
- Producers and consumers can increase overall performance by optimising batch sizes, compression settings, and buffer sizes.
- For identifying and fixing performance bottlenecks, proper hardware provisioning, network optimisation, and monitoring are also required.