Understanding Kafka Partitioning Strategy
Overview
Apache Kafka is a distributed event streaming service that is open source and used for high-performance data pipelines, analytics, and integration. Scalability, ordering guarantees, parallel processing, and subject segmentation is achieved through the use of partitions, brokers, producers, consumers, topics, and ZooKeeper. Understanding the relationships between topics, partitions, and brokers is required for optimizing Kafka's performance.
Brief Overview of Apache Kafka
Apache Kafka is an open-source distributed event streaming service for high-performance data pipelines, analytics, integration, and critical applications, utilizing the publish/subscribe messaging system.
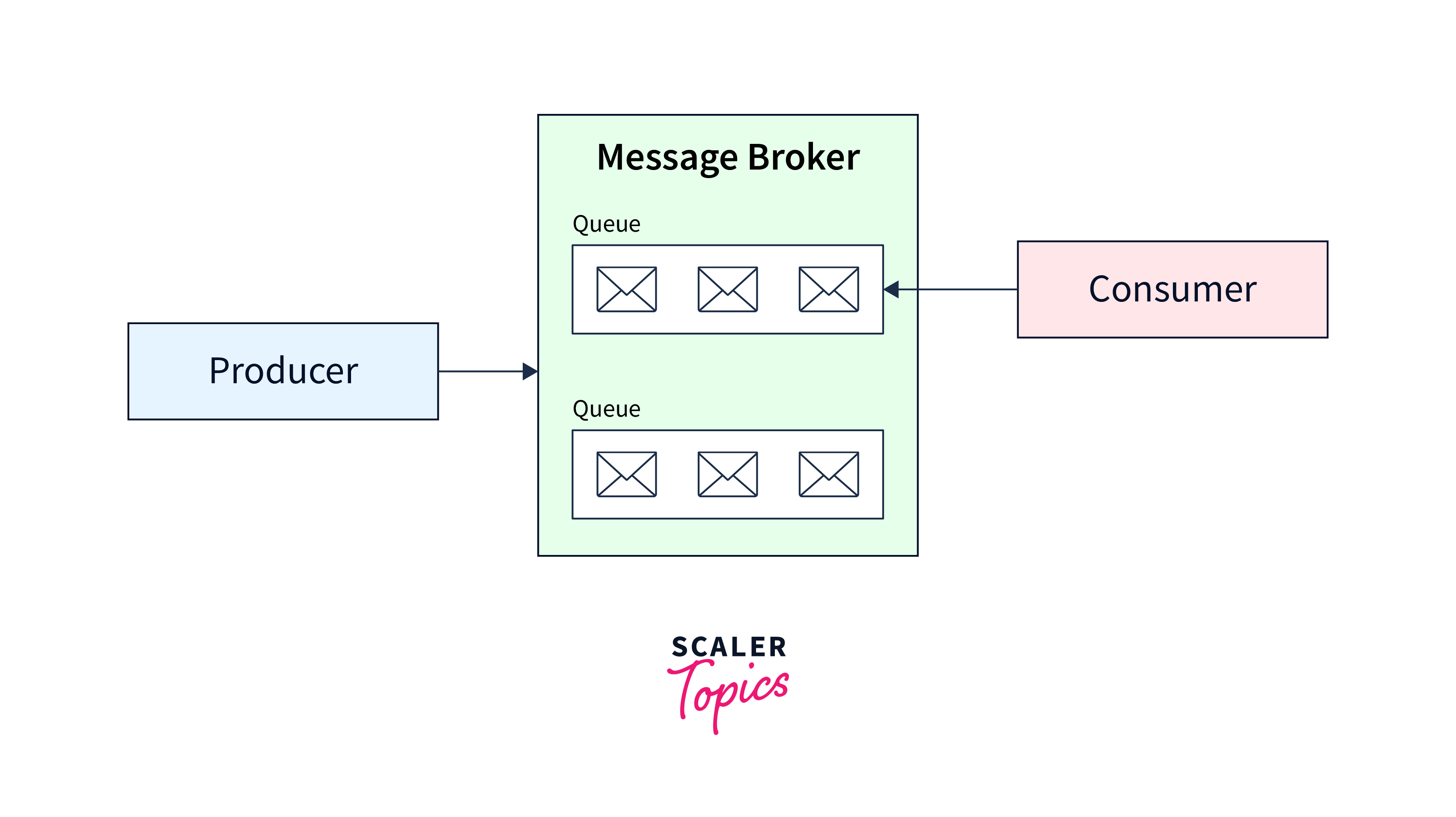
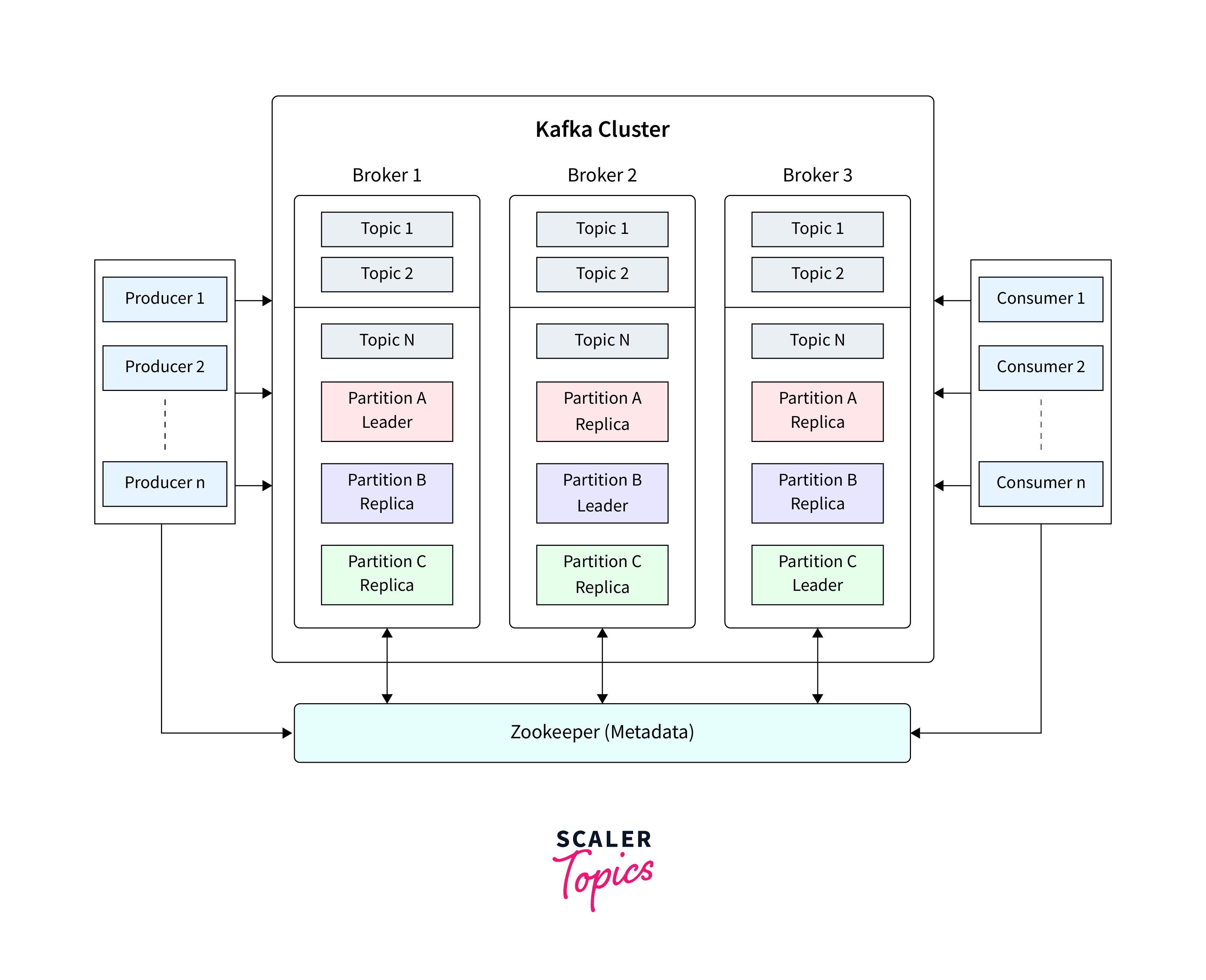
Various applications use different methodologies when developing the architecture of Apache Kafka. However, other fundamental components are required to build a strong Kafka architecture, including Kafka Cluster, Producers, Consumers, Brokers, Topics, Partitions, and Zookeeper.
Importance of Partitioning in Apache Kafka
Before we go into the Kafka partitioning strategy, it's useful to have a high-level understanding of Kafka's structural method for managing data (messages). Kafka messages are separated into topics, which are further divided into partitions. Kafka operates as a distributed system in a cluster, with each container in the cluster referred to as a broker. Partitioning allows messages to be distributed in parallel across several brokers in the cluster.
Kafka grows to serve numerous consumers and producers simultaneously using this parallelism approach. This partitioning strategy provides for linear scaling for both consumers and providers. When partition replicas are brought into the environment, Kafka handles redundancy in the same way.
Here are some of the main reasons why partitioning is crucial in Apache Kafka:
- Scalability:
Kafka topics are separated into many partitions, enabling for horizontal scalability of data storage and processing. Each partition may be distributed among several brokers in the cluster, allowing Kafka to manage massive volumes of data while maintaining excellent message throughput. - Parallel Processing:
Kafka may achieve parallelism in data processing by partitioning. Each partition of a subject can be consumed by a different consumer, allowing numerous consumers to handle data at the same time. - Ordering Guarantees:
While Kafka ensures the order of messages inside a partition, it does not offer global ordering across all partitions in a topic. Messages, on the other hand, are precisely organized inside a division. This allows you to manage the ordering and processing of messages for certain use scenarios. - Topic Segmentation:
Partitioning allows for the segmentation of data within a topic depending on particular criteria such as geographic location, time, or other factors. This segmentation might be beneficial in some use cases, such as data analytics and filtering.
Understanding Kafka and Partitioning
Apache Kafka is a distributed streaming technology that was originally created by LinkedIn and contributed to the Apache Software Foundation. The Scala and Java-based project seeks to create a uniform, high-throughput, low-latency framework for managing real-time data flows. A streaming platform, by definition, has three main capabilities:
- Publish and subscribe to record streams, much like a message queue or business messaging system.
- Store record streams in a fault-tolerant and long-lasting manner.
- Process record streams as they come in.
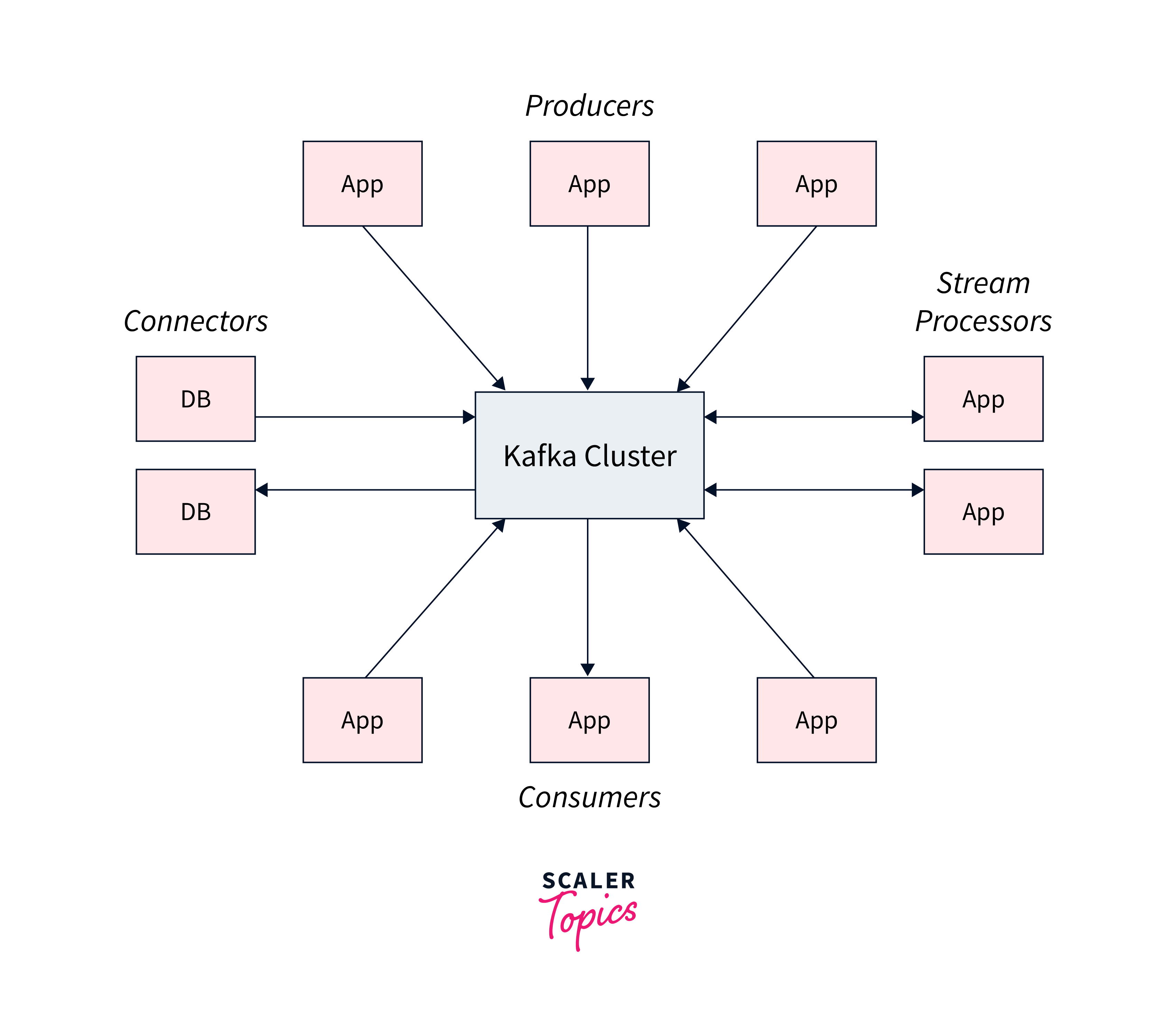
Kafka provides five key APIs for communication with topics:
- Producer API:
enables the publication of a stream of records to one or more topics. - Consumer API:
allows you to subscribe to one or more topics and handle the stream of records that are sent to you. - Streams API:
allows you to function as a stream processor, ingesting an input stream from one or more topics and providing an output stream to one or more output topics, thereby converting input streams to output streams. - Connector API:
Reusable producers and consumers link Kafka topics to existing applications or data systems. - Admin API:
lets you to manage and examine Kafka topics, brokers, and other objects.
Everything in Kafka revolves around partitions. They are vital in the structure of Kafka's storage as well as both the production and consumption of messages.
Kafka partitions function by splitting a single topic log into numerous logs and distributing them over one or more brokers. Partitions, as previously said, are what make Kafka scalable. The number of partitions can be specified while creating the topic, or they can be added afterward with the Kafka kafka-topics.sh utility.
Multiple partitions allow multiple clients to access a subject, but partitions only work with one consumer at a time, aiming for parity between clients and partitions for effective performance improvements.
Basics of Kafka Partitioning
Before we go into partitions, let's establish the context. Let's start with some high-level concepts and how they relate to partitions. Events, Streams, and Kafka Topics
Events:
An event is a record of "something that happened" in the world or in your business. In the documentation, it is sometimes referred to as a record or a message. When you read or send data to Kafka, you do it using events. An event has a key, a value, a timestamp, and optional metadata headers. Here is an example of an event:
- Event key:
"Bob" - Event value:
"Made a payment of $550 to person ABC" - Event timestamp:
"Aug. 27, 2021 at 3:30 p.m."
Write events in Kafka's distributed placement, where topics have multiple producers and subscribers, ensures scalability by enabling client applications to read and write data from multiple brokers simultaneously.
Streams :
In Kafka, the term "streams" refers to the fundamental abstraction made available by Kafka Streams, a compact Java framework for creating real-time data processing applications. Developers may stream-oriented process, alter, and analyse data from Kafka topics using Kafka Streams. Event streaming is used for a wide range of use cases in several sectors and organizations. Among its numerous instances are:
- Real-time payment and financial transaction processing, as in stock exchanges, banks, and insurance companies.
- Real-time tracking and monitoring of vehicles, trucks, fleets, and cargo, as in logistics and the automobile sector.
- Continuously collecting and analyzing sensor data from IoT devices or other equipment, such as those found in factories and wind farms.
- To gather and respond to consumer interactions and orders in real-time, as in retail, the hotel and travel sector, and mobile applications.
Topics :
- A topic is created when an event stream enters Kafka. A topic is a materialized event stream in Kafka's world. In other terms, a topic is a flowing stream.
- Topic gathers similar events and preserves them indefinitely. A Kafka topic is analogous to a table in a database or a folder in a file system.
- Topics are Kafka's core idea that separates producers and consumers. A consumer reads messages from a Kafka subject, whereas producers write messages to a Kafka topic. A topic might have a large number of producers and consumers.
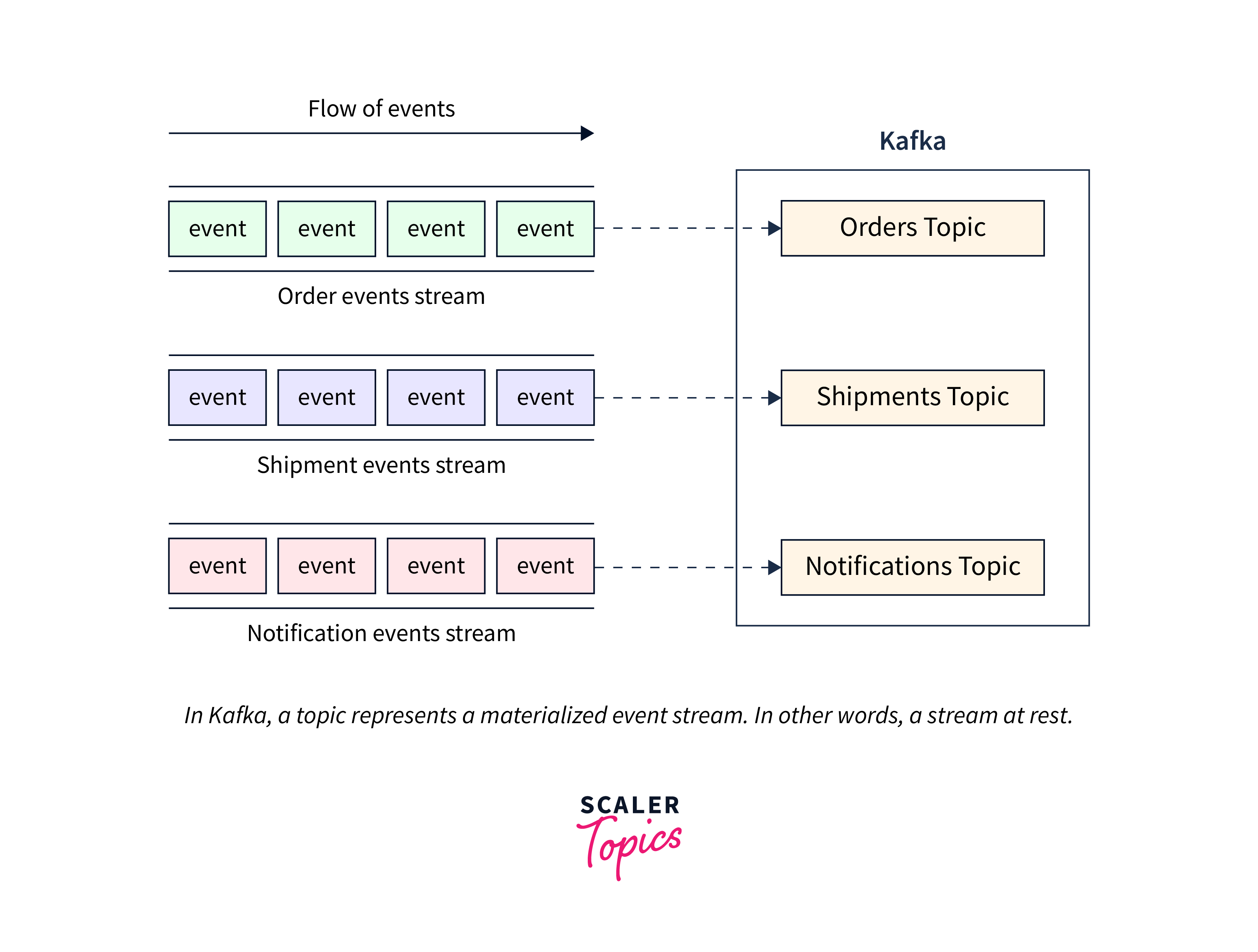
Partitions:
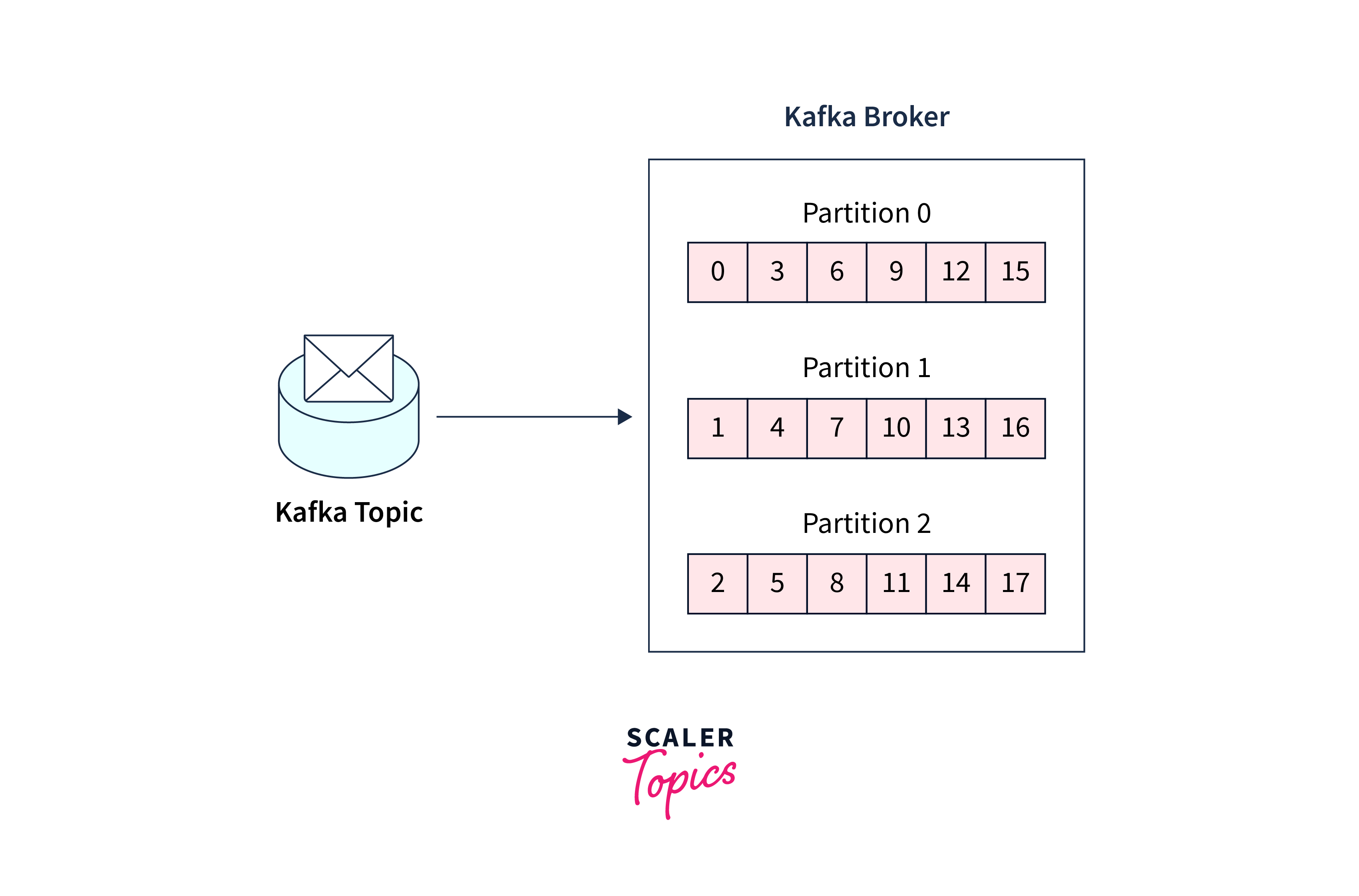
The topics of Kafka are grouped into numerous partitions. While a topic is a logical idea in Kafka, a partition is the smallest storage unit that contains a subset of a topic's records. Each partition consists of a single log file to which records are append-only fashion.
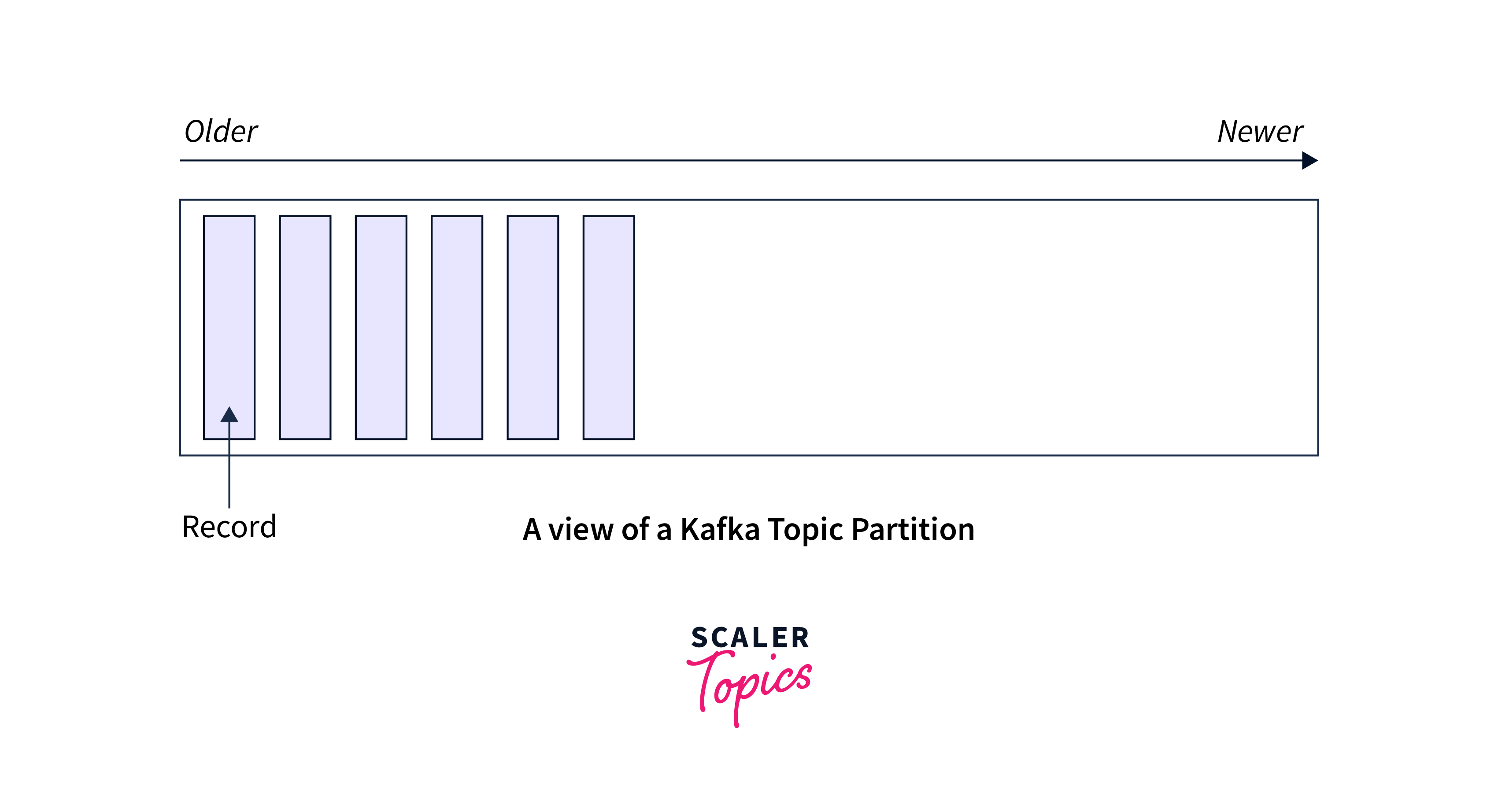
Offset Fundamentals:
Each partition in a Kafka topic has its own set of offsets, which are sequential, incremental, and immutable identifiers. For the first message in a partition, offsets begin at 0 and rise by one for each successive message.
Consumer Progress Monitoring:
- Offsets are used by consumers to track their progress inside a partition.
- When a consumer consumes messages from a partition, it maintains note of the last offset consumed, which indicates the next message to read.
Committing Offsets:
- Consumers must commit their offsets to prevent reprocessing messages and assure at-least-once message processing.
- Consumers accept that they have successfully processed up to a certain message in a partition by committing offsets.
Offsets and the ordering of messages
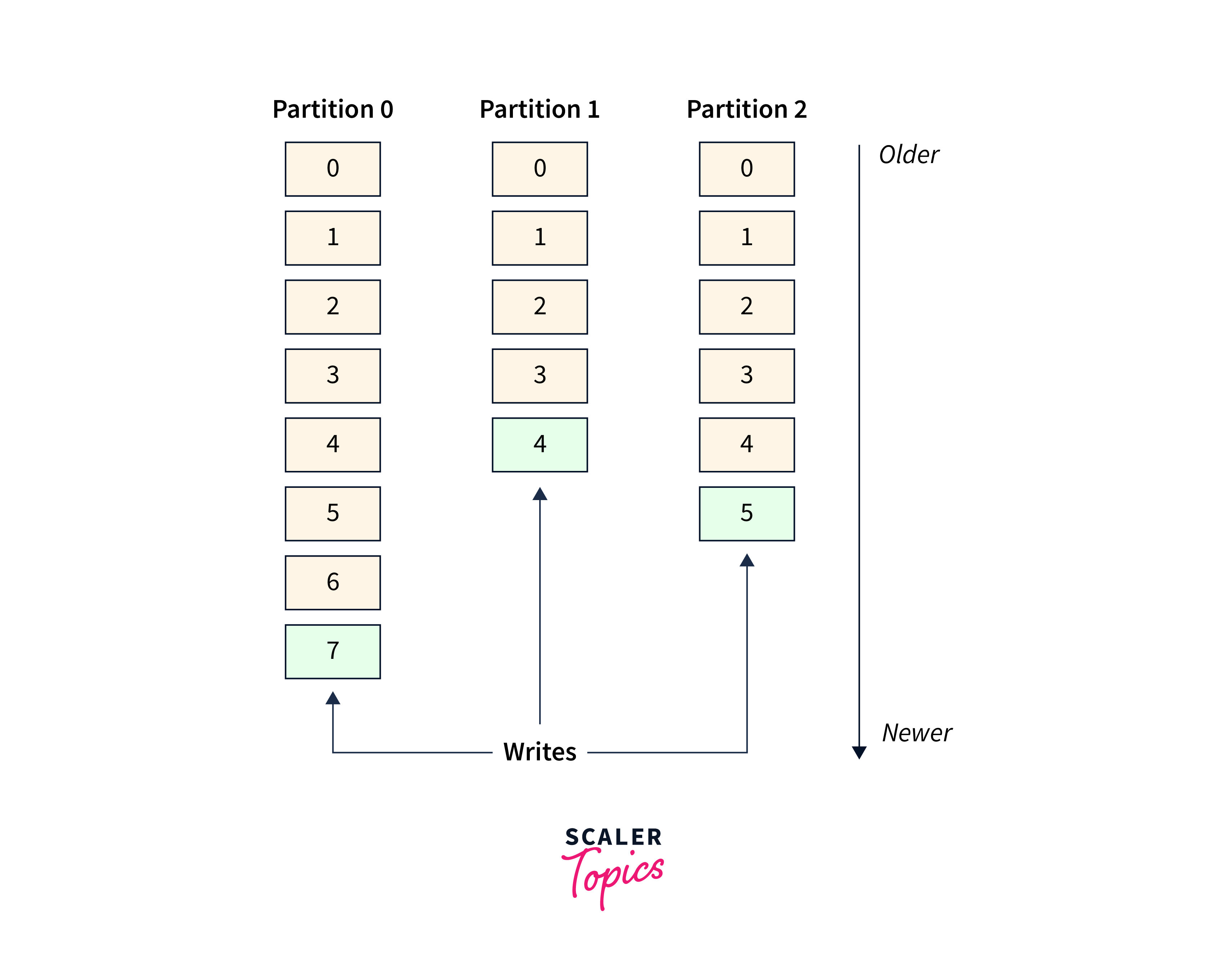
- Each partition's records are given a unique sequential identifier called the offset.
- Kafka keeps track of the offset, which is an incremental and immutable number. When a record is written to a partition, it is added to the end of the log and the next sequential offset is assigned. When reading data from a partition, offsets are very beneficial.
- The illustration below depicts a topic with three parts. Each one has records appended to the end.
- Messages within a partition are guaranteed to be sorted, whereas communications across a topic are not guaranteed to be ordered.
How Kafka Partitioning Works?
- After partitioning a topic, we need a means to decide which messages to write to which partitions.
- If a message lacks a key, future messages are distributed round-robin among all partitions of that topic.
- In this situation, all partitions receive an equal amount of the data, but the input messages are not ordered.
- If the message contains a key, the destination partition will be calculated using a hash of the key.
- This enables Kafka to ensure that messages with the same key always land in the same partition and are therefore always in order.
When transferring messages in Kafka, partitioning is handled by the producer. Producers may send messages with a key, and Kafka will utilize that key to determine the destination partition for the message. Messages with the same key can be handled in the same sequence as before. Let's look at an example of Java code utilizing the Kafka Producer API to understand how this works:
First, ensure that the Kafka client library is included in your Java project. You may include the following Maven dependency in your pom.xml:
Now, start a Kafka producer and deliver messages with the same key to guarantee they are processed in the same order:
In this example, we assign a specific key (my-key) to each message and send ten messages to the Kafka topic my-topic. Because all messages have the same key, Kafka's partitioning algorithm ensures that they are routed to the same partition inside the topic. As a result, when consumers read from the topic, they will receive the messages in the same order they were produced.
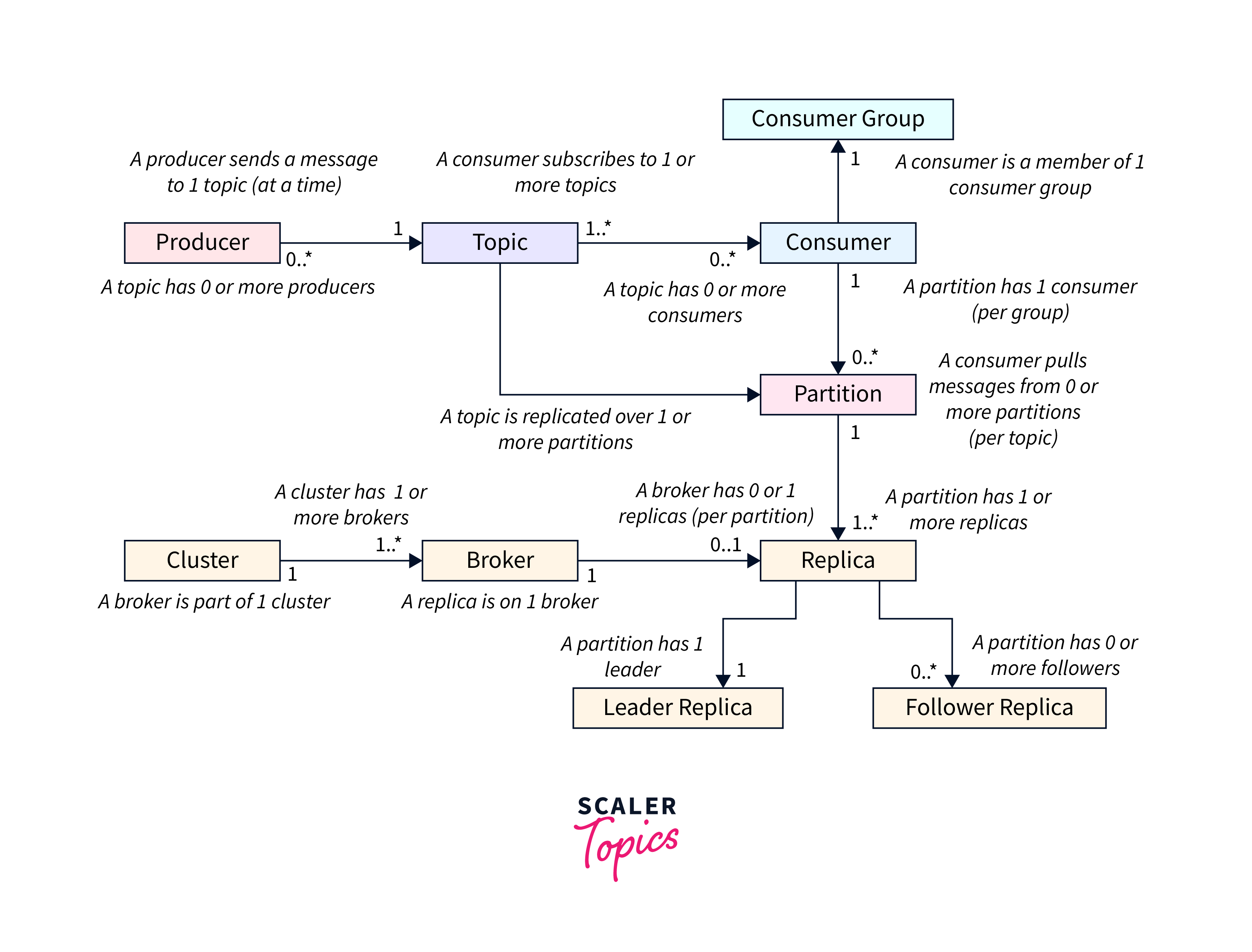
Understanding the Relationship Between Topics, Partitions, and Brokers
Kafka's primary architectural components are as follows:
- Producer:
Applications that use the Kafka Producer API to send data streams to topics in a Kafka cluster. A producer can transmit data to numerous Topics at the same time. - Topic :
A topic is a term for a category or feed to which records are published. In Kafka, topics are always multi-subscriber; that is, a topic might have zero, one, or many subscribers who subscribe to the data posted to it. It has a distinct name across the Kafka cluster. - Consumer :
Consumers are applications that use the Kafka consumer API to feed data streams on Kafka Topics. It may receive data streams from several Topics by subscribing to them. - Consumer Group:
A group of customers who have the same group-id.
Kafka Producers:
- Messages are optimized, written, and published to Kafka topics by producers.
- They have the ability to send messages to any number of topics.
- Partitioning is used by producers to serialize, compress, and load balance data among brokers.
Kafka Consumers:
- Consumers consume communications from topics to which they have subscribed.
- Consumers are organized into consumer groups.
- Each consumer in a group consumes a subset of subscribed topic partitions.
Kafka Brokers:
- A Kafka broker is a server that is part of a Kafka cluster.
- A Kafka cluster is made up of many brokers.
- Apache ZooKeeper is used by brokers for administration and coordination.
- ZooKeeper is used to manage client requests for particular topic divisions using broker elections.
- A reliable Kafka cluster will normally include at least three brokers.
Default Partitioning in Kafka
In Kafka, the default partitioning method is decided by whether or not the producer specifies a key when publishing a message to a topic.
If the producer includes a key with the following message:
- To determine the partition, Kafka computes the hash of the key.
- Messages with the same key are always written to the same partition, keeping them in order.
If the producer does not provide a key:
- To distribute messages among all partitions of the topic, Kafka employs a round-robin method.
- This ensures even data distribution but does not guarantee message ordering across partitions.
Custom Kafka Partitioning Strategies
Based on your individual requirements, custom Kafka partitioning techniques allow you to decide how messages are distributed across multiple partitions within a topic. Here are some examples of frequent custom partitioning strategies:
Partitioning via Round-Robin:
- Distribute messages on a round-robin basis among every topic partition.
- Suitable when you wish to distribute messages uniformly across partitions without taking message keys or values into consideration.
Partitioning of the Key Range:
- Define ranges for each key and assign each range to a distinct division.
- When you wish to combine messages with specified key ranges together on the same partition, this is useful.
Hash-based Partitioning:
- Create a hash value from the message key using a hash function, and then use modulo arithmetic to transfer the hash value to a partition.
- Messages with the same key are always assigned to the same partition, ensuring that they remain in the correct sequence.
- When you need to ensure that messages with the same key are handled by the same partition, this is useful.
Implementation of Custom Kafka Partitioner
Here is an example of a custom partitioner that is used to regulate and would want to divide messages among Kafka partitions. For even integers, this will generate partition number 0, while for odd numbers, it will return partition number 1.
And in order to divide odd and even integers into different Kafka partitions, the sample producer shown below employs the previously mentioned custom partitioner by instructing Kafka to use it in place of the default strategy using the partitioner.class kafka property.
Partitioning Strategy Impact on Kafka Performance
How Partitioning Affects Kafka's Throughput?
In the context of Kafka partitioning, throughput refers to the rate at which data may be consumed and processed by a Kafka cluster. It measures the quantity of data that may be sent and handled in a specific time period in terms of messages or bytes per second. The Kafka partitioning startegy in Kafka has a significant effect on the overall throughput of the system. When data is written to a Kafka topic, it is divided into multiple partitions. partition is essentially a separate stream of messages, and Kafka allows multiple producers and consumers to interact with these partitions at the same time.
- Parallelism:
Kafka split enables parallel data processing, enabling producers and consumers to write and consume simultaneously, increasing throughput. - Scalability:
Kafka expands horizontally by adding more brokers and partitions, increasing throughput. - Load Balancing:
Partial partitioning distributes data load among Kafka cluster brokers, preventing overburdening and underutilization, ensuring full capacity operation. - Consumer Throughput:
Subject partitions impact consumer throughput; less partitions lead to suboptimal performance, while too many cause coordination cost.
Partitioning and Data Locality
Data Locality in Kafka:
- Data locality guarantees that data is located close to the algorithm that processes it, resulting in improved overall performance.
- In Kafka, data locality involves co-locating consumers and their partitions on the same cluster nodes.
- Consumers that read from locally located partitions benefit from reduced network overhead and faster data access.
Relationship between Partitioning and Data Locality:
- Partitioning in Kafka governs how data is distributed across brokers in the cluster.
- When a consumer subscribes to a topic, they are allocated one or more partitions to read from.
- Partitioning solutions that are well-designed can ensure that consumers read from locally accessible partitions, hence improving data locality.
- Achieving complete data locality may be difficult in large or dynamic Kafka clusters with frequent partition reassignments because of scaling, rebalancing, or failures.
- Kafka uses optimization methods like rack awareness and consumer rebalancing to increase data locality despite cluster dynamics.
Effect of Partitioning on Failover and Replication
Failover :
Failover in Kafka clusters is the recovery process when a broker or node fails due to network difficulties.
Replication :
Kafka partitions can have replicas, copies distributed across different brokers. When a broker fails, replicas can serve read and write requests for affected partitions.
Effect of Partitioning:
- Kafka allows you to configure the replication factor, which determines the number of replicas for each partition.
- To achieve high availability and tolerate broker failures, the replication factor should be set to a value larger than one.
- A replication factor of three is typically utilized in production setups, ensuring that each partition has an additional two replicas.
Additionally, if a topic has too many partitions, the replication overhead increases, and it could lead to resource contention and potential performance issues during failover.
Replication:
Kafka replication improves data durability and fault tolerance by keeping redundant copies of each partition across various brokers. Each replica adheres to the leader-replica model, in which one of the replicas serves as the leader and the rest replicas serve as followers.
Effect of Partitioning:
- Partitioning has a direct impact on the distribution of copies among brokers.
- To offer improved resilience against hardware failures, network partitions, or data centre outages, Kafka guarantees that copies for a partition are dispersed among multiple brokers in the cluster (preferably on separate computers, racks, or data centers).
Conclusion
Summary of The Key Points
- Kafka offers five APIs: Producer, Consumer, Streams, Connector, and Admin, for publishing, subscribing, processing, linking, and managing Kafka objects.
- Kafka's architecture relies on partitions for parallel processing and scalability, allowing multiple clients to access a topic, but each partition can only be handled by one consumer at a time.
Emphasizing the Importance of A Suitable Partitioning Strategy for A Robust Kafka Setup
- Parallelism and Throughput:
Kafka partitioning enables parallel data processing, allowing multiple producers and consumers to work concurrently, ensuring optimal resource utilization and throughput. - Scalability :
Kafka's horizontal scalability is based on partitioning, allowing distributed data over several partitions to accommodate more brokers and enable smooth scalability. - Data Locality :
An effective partitioning strategy improves data locality by co-locating consumers and partitions on the same nodes, reducing network overhead and improving performance in large-scale distributed setups. - Load Balancing:
Effective partitioning distributes data equally among brokers, removing hotspots and performance bottlenecks. Load balancing guarantees that no one broker is overwhelmed maintaining consistent and efficient cluster performance.
Encouragement to Further Explore and Experiment with Kafka Partitioning Strategies
Kafka's architecture relies on partitioning, which optimizes performance and builds resilient, scalable systems. Experimenting with different partitioning strategies unlocks Kafka's full potential and maximizes its capabilities.
- Performance Optimization:
Optimize partitioning for Kafka clusters by experimenting with multiple techniques to maximize speed and efficiency. - Scalability Mastery:
Kafka's partitioning ensures horizontal scaling, scalability, and future-proofing by building subjects for applications' expanding demands. - Innovation and Creativity:
Create creative partitioning schemes to meet specific needs and enhance data streaming possibilities.