Understanding Kafka Serializers and Deserializers
Overview
Serialization is the process of conversion of data into storable format. Serialization encodes the data so that the data can be stored and transmitted. Kafka stores data in the form of an array of bytes only and thus we need serialization in Kafka to convert them into an array of bytes and transmit them.
Deserialization is the reverse process of serialization. It is the process of conversion of an array of bytes back into their original form. By using deserialization we get our serialized data back in its original form.
Introduction
Apache Kafka
Apache Kafka is an open-source distributed real-time streaming platform. Apache Kafka is highly scalable and used for building fault tolerant applications. We can scale out Kafka by adding more brokers. Kafka is also used for data integration and messaging and queueing service. Kafka was made by Linkedin and later on, it became open-source. Kafka was the main project of Apache. Apache then released different versions of Kafka.
Kafka is known for the following:
- High throughput
- Scalability
- Fault tolerance
Most Fortune 500 companies use Kafka for real-time streaming. Some examples of companies using Kafka are Uber, Linkedin, Airbnb etc.
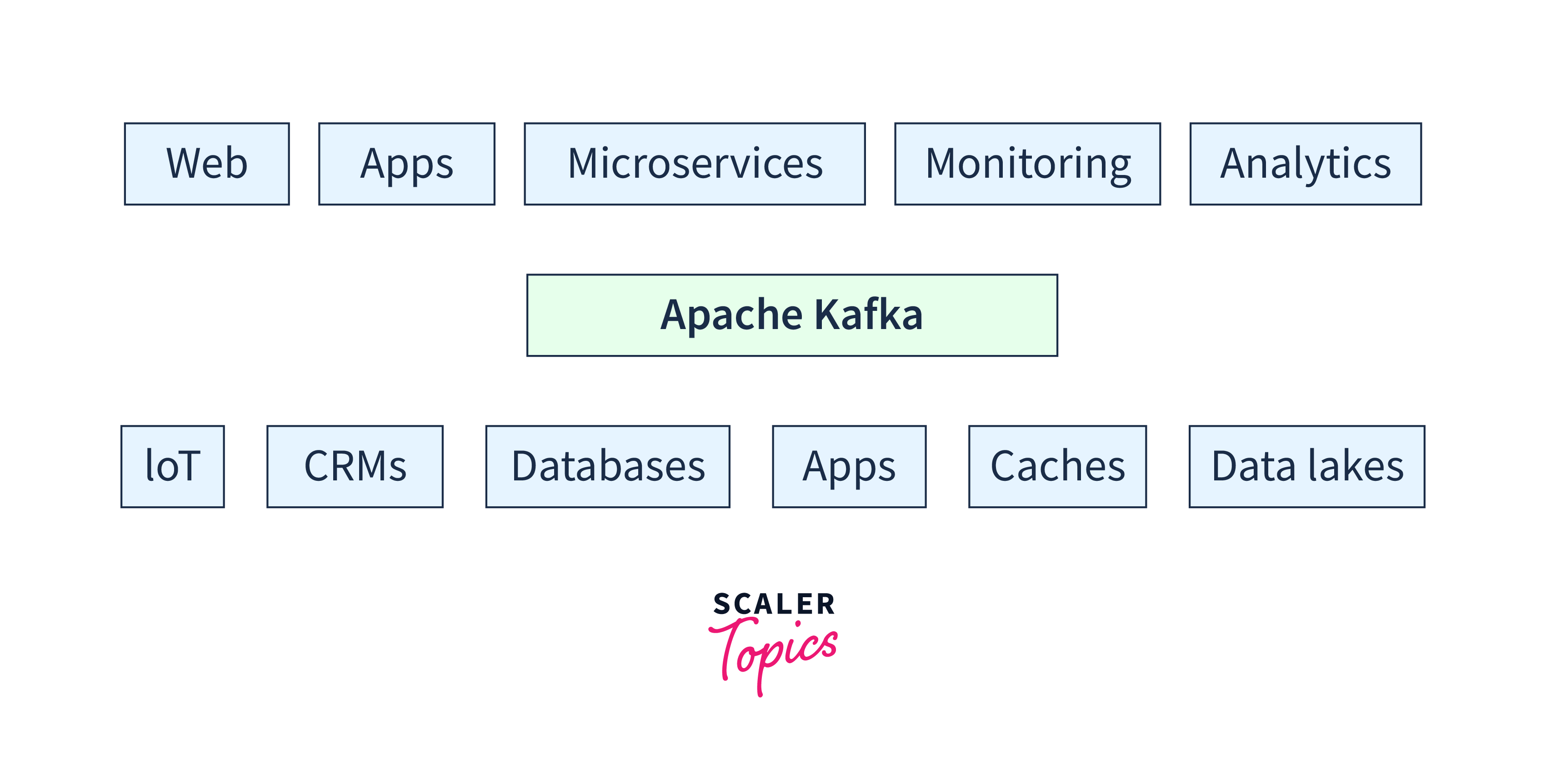
Kafka stores data only in the form of a bytes array. Thus we need serialization in Kafka to convert them into bytes and transmit them.
Kafka first serializes the data and then writes it into Kafka topics. The process compresses the data as well as makes it in a storable format. The data is then stored and streamed according to the requirement. On the consumer side, the data is deserialized and converted back into its original form.
Thus we see serialization and deserialization are very important processes in Kafka.
Role of Serialization and Deserialization in Kafka
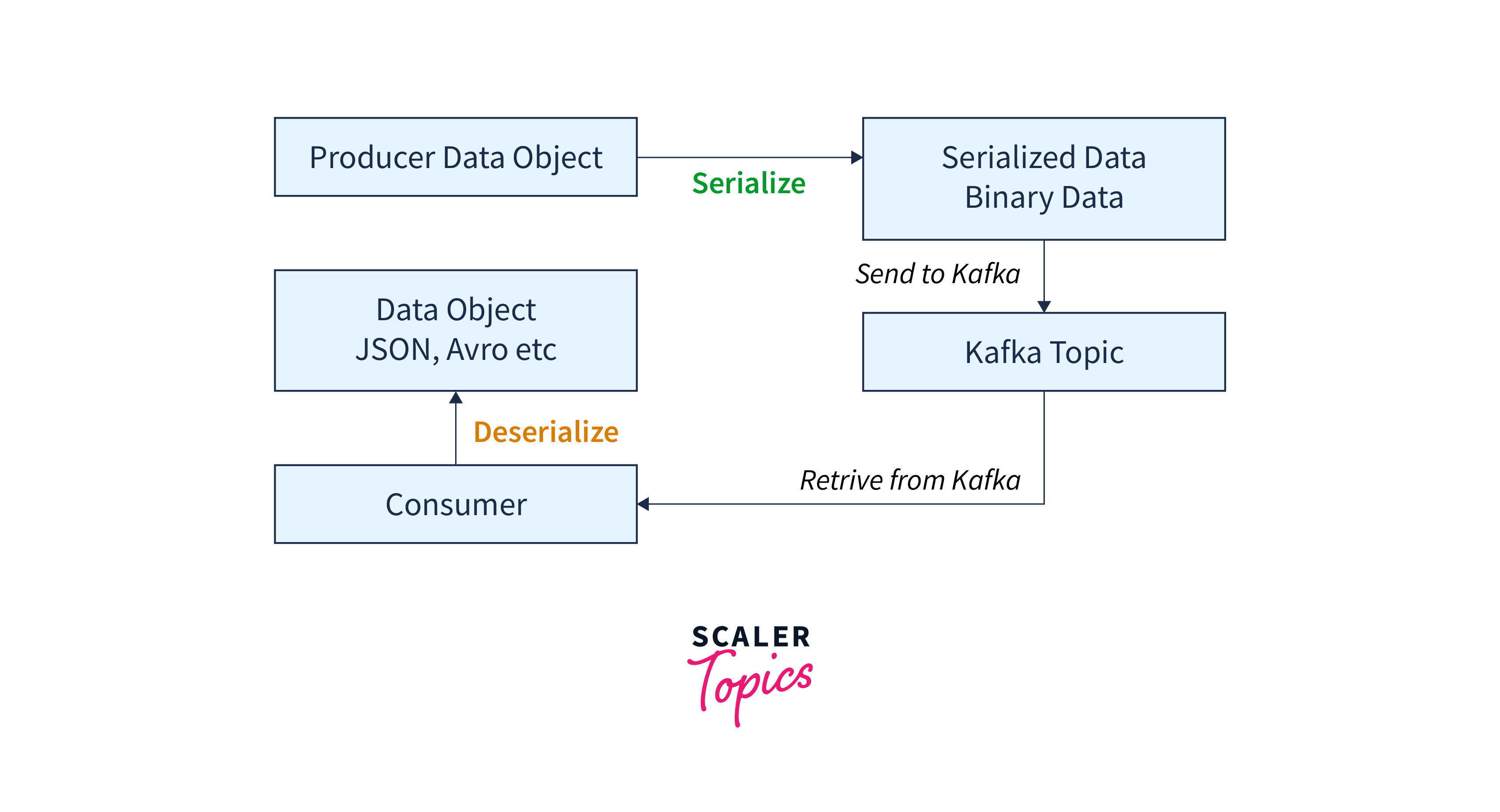
We can see the visulized process of serialization and deserialization in Kafka.
Serialization helps Kafka in increasing efficiency and compatibility.
- Efficiency:
Serializing the data helps us to compress the data and thus helps us reduce storage costs, transmission costs and transmission time. Thus serialization helps us achieve performance in Apache Kafka along with lower costs for storage and transmission. - Compatibility:
Serialization helps us to transfer any type of data by converting the data into an array of bytes and then transmitting it. It also allows different programming languages to serialize the data. - Better Interactivity:
Serialization converts the data into an array of bytes. This data can be used among different systems and programming languages. Thus serialization helps to achieve better interactivity. - Scalability:
Serialization helps to compress data and thus allows Kafka to achieve scalability. - Storable format:
Complex objects can't be stored in databases. Serialization converts the data into the proper format and thus the complex data can be stored as per our requirement.
Deserialization is converting the serialized data back into its original form. In Apache Kafka, consumers deserialize the data and convert the data back into its original form.
Deep Dive into Kafka
We need to serialize our messages in order to use Kafka. Kafka provides built-in serialisation methods such as Apache Avro, JSON, Protobuf, etc and also custom serialization methods. Serialization helps us to efficiently transfer data using Kafka. We will look into this in detail in the next sections. Kafka allows to use different serialization methods for key and value pair.
Understanding Serialization
What is Serialization?
Serialization is the conversion of data into a format that helps us in storage, transmission, etc. Serialization helps us to compress data and makes the data usable by any machine or language. Serialization is used to convert the data into a byte array, JSON, XML, etc.
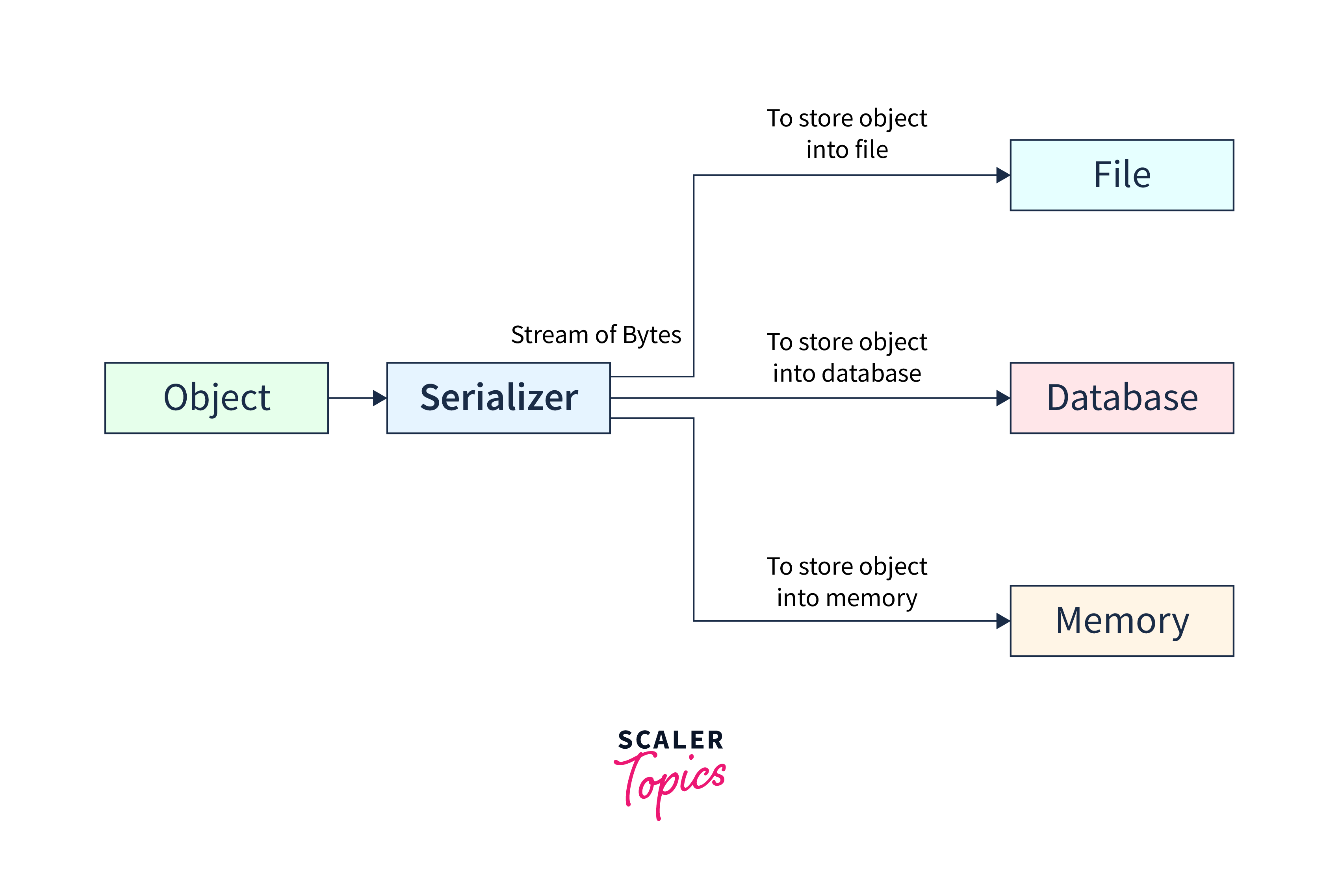
In the image above, we can see that the object is serialized into a stream of bytes. The array of bytes can be used at our convenience. In Kafka, it is then stored in Kafka topics and used for streaming purposes.
Why is Serialization Required in Kafka?
We know that Apache Kafka only streams data in the form of an array of bytes. However, our data might be in the form of String, Integer, Double, or other complex data types. The data need to be converted into array bytes in order to be used by Kafka. Thus we need serialization in Kafka.
Let us see the advantages of serialization
- Caching:
Frequently used messages can be cached using serialization and can be used to save time and data. - Data persistence:
Complex objects can't be stored in the database directly. However, the serialized data can be easily stored in any database. - Security:
Serialization of data can be used to protect the data.
As seen, serialization is necessary for a streaming platform.
Built-in Kafka Serializers
Apache Kafka provides various built-in serialization methods. Some of them are:
-
Protobuf:
Protobuf stands for Protocol buffers. Google developers have developed this serialization technique. Protobuf is advantageous when we want efficient data transfer. It transfers the data in binary format and is much more efficient than text based serializers. -
JSON:
JSON stands for** JavaScript Object Notation**. JSON serialization is a serialization method where the Kafka clients serialize data into javascript objects. JSON is simple, human-readable, lightweight and language-neutral. Due to this, it is easier than other serializers. -
Apache Avro:
Apache Avro is efficient data serialization and is used in various applications. Apache Avro supports dynamic typing. It uses compact binary storage. Yahoo developed Avro and later on, it became open-source as Apache Avro. Python, C++ and various other programming languages are supported by Apache Avro.
Some of the use cases of Avro include:- Hadoop:
Hadoop uses Apache Avro for storage purposes - Apache Kafka:
Apache Avro is used in Apache Kafka for serialization purposes - Apache Spark:
Here Avro is used for read and write of data.
- Hadoop:
-
String serialization:
String serialization helps Kafka clients to serialize the string data in the form of strings and publish them into Kafka topics. Apache Kafka provides a built-in class StringSerializer.class to serialize and deserialize string data. This inbuilt function helps us to directly import the class and use the class instead of writing logic and code. -
Java Serialization:
Java serialization helps Kafka clients to serialize the Java objects into an array of bytes.
The following are the built-in serialization methods in Kafka for Java Objects:
- IntegerSerializer
- ByteArraySerilizer
- LongSerializer
- DoubleSerializer
- StringSerializer
Let us look at the table below to understand better.
| Serializer | Data Type | Usage |
|---|---|---|
| IntegerSerializer | Integer | Serializes a Java integer value |
| ByteArraySerializer | Byte Array | Serializes a byte array |
| LongSerializer | Long | Serializes a Java long integer value |
| DoubleSerializer | Double | Serializes a Java double data type |
| StringSerializer | String | Serializes a Java String |
Apache Kafka provides has various classes like 'IntegerSerialization.class', 'ByteArraySerilization.class', 'LongSerialization.class', 'DoubleSerialization.class', and 'StringSerialization.class' for implementing serialization and deserialization of Integer, ByteArray, Long, Double and String data type respectively in Java. Apart from these classes, there are classes like 'KafkaAvroSerializer.class' etc for Apache Avro serialization and deserialization.
This class helps us to quickly serialize and deserialize any Java Object and saves us time.
Serialization has numerous advantages but it also has a few disadvantages. Some of them are:
- Backward Compatibility:
Kafka supports backward compatibility i.e. newer versions of Kafka supports data transfer from older versions. - Forward Compatibility:
Kafka supports forward compatibility i.e. data produced from older versions can be processed by newer versions. - Schema Registry:
Kafka provides schema registery which helps to maintain schemas in Kafka. Kafka producers and Kafka consumers use schemas which helps to ensure compatibility. - Performance overhead:
Serialization involves the conversion of data into simpler objects that are easy to store and stream. But this may add overhead both in case of time and computation. Efficient serialization techniques should be used to overcome this issue. - Data Compatibility:
We might get problems with different versions of serialization and deserialization. - Increase in bandwidth:
If the serialization method is not optimized, the serialized array of bytes might occupy a larger space than the original message. This might result in an increase in bandwidth. - Debugging:
Serialization and deserialization codes might bring errors into the system. Thus we may require to remove the bugs from the system. - Security issues:
Unoptimized serialization methods might invoke security issues in the system.
Serialization might have other disadvantages. Thus we must keep in mind to test and run the code before using it in a live project.
Understanding Deserialization
What is Deserialization?
Deserialization is the process of extracting the real data from the serialized data. Specifically, it is the process of getting back our original data from serialized data.
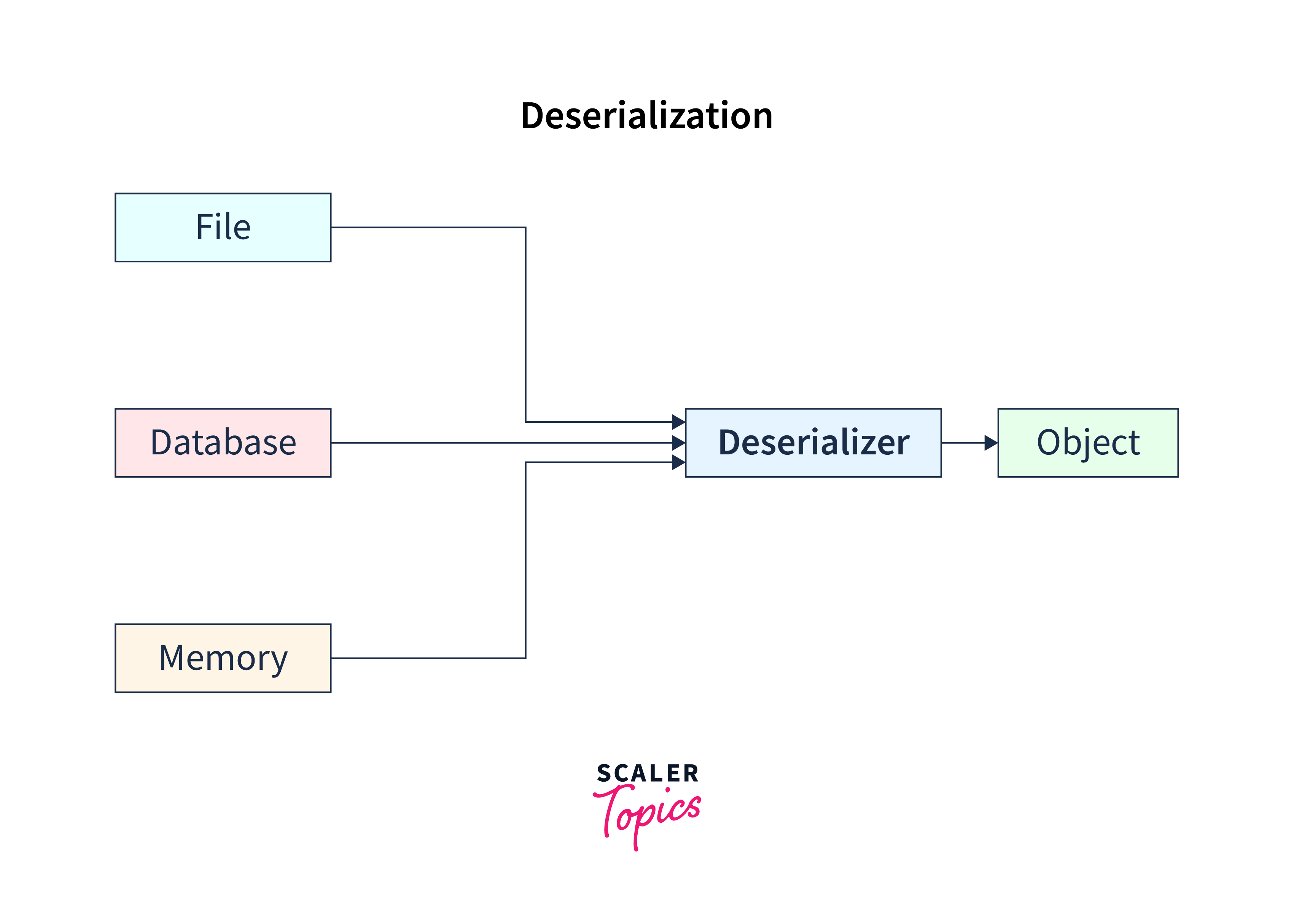
Why is Deserialization Necessary in Kafka?
As seen above, serialization is necessary for Kafka. However, we need to get our original data back from the Kafka consumer. Thus, the need for deserialization is to get the data back from the database, etc. Kafka Consumers use deserialization to get the original data from the Kafka topic.
Deserialization can be done in the following ways:
- Built-in deserialization: Many programming languages provide built-in deserialization to get the data back into specific objects.
- Custom deserialization: We can implement our own code and do the custom serialization and deserialization.
Built-in Kafka Deserializers
Apache Kafka provides various built-in serialization methods. Some of them are:
-
Protobuf Deserializer:
Protobuf deserializer is used to get back serialized data done by Protobuf serializer. -
JSON Deserializer:
JSON deserializer is used to get our original data back from JSON Serialized objects. -
Apache Avro Deserializers:
Apache Avro is used to get our original data back from Avro serialized data.
The following are the other built-in serialization methods in Kafka for Java Objects:
- IntegerDeserializer
- ByteArrayDeserilizer
- LongDeserializer
- DoubleDeserializer
- StringDeserializer
Let us look at the below table to understand their functions:
| Deserializer | Data Type | Usage |
|---|---|---|
| IntegerDeserializer | Integer | Deserializes an integer value |
| ByteArrayDeserializer | Byte Array | Deserializes a byte array |
| LongDeserializer | Long | Deserializes a long integer value |
| DoubleDeserializer | Double | Deserializes a double |
| StringDeserializer | String | Deserializes a string value |
This built-in serializer helps us to deserialize without writing custom code.
Custom Serialization and Deserialization
Custom serialization includes the serialization of data by using formats other than the built-in formats. Kafka supports custom serialization and deserialization methods.
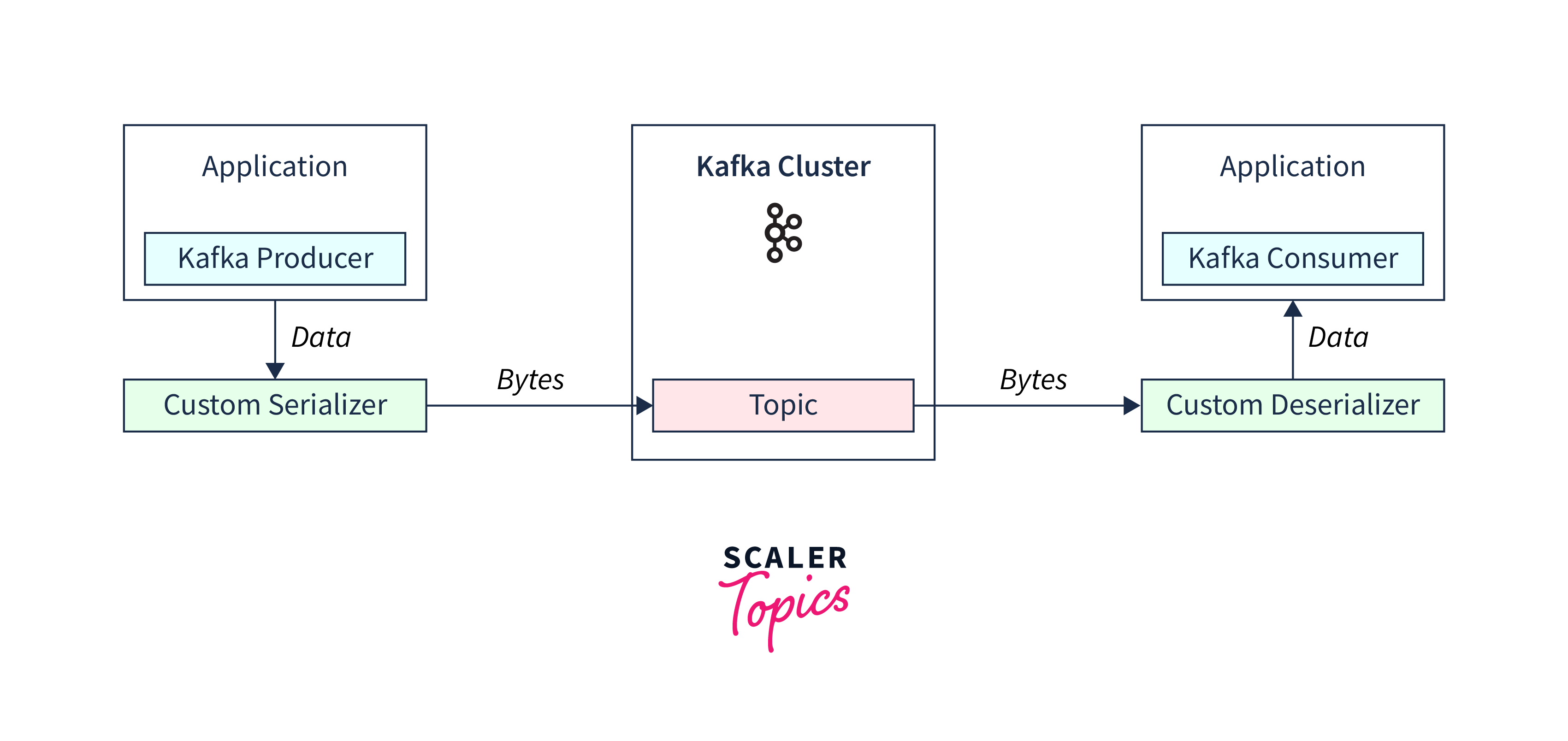
In the above image, we can see that the Kafka producer uses custom serialization and publishes the data into Kafka topics. After the data is streamed, the data is deserialized by Kafka Consumer using Custom deserializer.
When to Use Custom Serializer and Deserializer?
We might need to use a custom serializer in the following cases:
- We use custom serializers and deserializer when our data objects can't be serialized by the built-in serializers provided by Kafka.
- We have a better serializer which works better than the custom serializer.
How to Create Custom Serializer and Deserializer?
To use a custom serializer in Kafka we have to follow the following steps:
- Configure the class
- Implement the serialization code
- Close the object of the class
First, we need to configure the serializer class. Hence, we override the Serialization method configure(Map<String,?> configs). Kafka allows us to pass any additional arguments in the method configure too. After configuring our custom serializer class, we need to implement our custom code. The implementation may include writing a completely new algorithm or using the built-in algorithm provided by Kafka or even using both of the above to create a hybrid algorithm. We override the Serialize method i.e. serialize(String topic, <datatype> data) to write a new algorithm. This method takes the topic name and the data and serializes it into an array of bytes. Finally, after the usage of the object, we close it.
After implementing the custom serializer, we implement the custom deserializer using the following steps:
- Configure the deserializer class
- Implement the deserialization code
- Close object of the class
First, we configure our custom deserialization class. Here we override the deserialization method configure(Map<String,?> configs). Kafka allows us to pass any additional parameters to the above method configure too. Next in the implementation step, we have to write the specific code to implement our custom deserializer. This implementation involves getting the original object from the serialized array of bytes. We override the Deserialize method i.e. deserialize(String topic, byte[] data) to get the original data. This method returns the original data. Finally, We close the deserializer object.
After implementing the serializer and deserializer, we need to register them using the Kafka client library.
Performance Considerations
Serialization and deserialization are frequently used in Kafka streaming. Serialization and deserialization severely impact the performance of Kafka. Thus one must keep in mind these points while implementing the code.
Let us see how serialization and deserialization can impact our performance:
- Serialization and deserialization format:
One must select serialization and deserialization format keeping in mind the performance. The text based formats like JSON are widely used. Whereas the binary formats like protobuf are quite efficient compared to JSON like text based formats. - Overhead:
Serializing and deserializing require CPU computation. Complex Serializing and deserializing methods would result in higher CPU time and cost. Thus optimal methods need to be considered to reduce CPU overhead. - Batching:
Serializing and deserializing in batches reduces CPU time. Thus we need to batch the serialization process to save time. - Caching:
Caching stores the serialization of the most commonly used messages. Caching the Serializing and deserializing process saves us time by saving calculations on the Serializing and deserializing of the same message. However, it might increase the overhead as the caching process requires time and memory too. Thus proper caching algorithm should be there to tackle this issue. - Compression:
Kafka compresses the messages to reduce the data. A proper compression algorithm must be chosen. - Data impact:
We can select Serializing and deserializing depending on the data that we want to serialize. - Parallel serializing and deserializing:
We can improve the performance by Serializing and deserializing in parallel.
Conclusion
We conclude the following from this article:
- Serialization and deserialization play an important role in Kafka.
- Serialization in Kafka involves converting objects into an array of bytes. Deserialization on the other hand is converting the array of bytes back into the original objects.
- Kafka has built-in serialization and deserialization techniques and thus helps us to develop the app faster. The built-in serializers help us serialize and deserialize Java objects and other commonly used data types.
- Kafka also supports custom serialization for custom purposes. We must write efficient code to prevent any delay.
- The binary serializers like Avro are faster than text-based serializers like JSON. However, JSON is commonly used everywhere and thus using JSON becomes quite easy.
- We must choose serialization and deserialization techniques in order to improve the performance and CPU usage.