Introduction to Kafka Streams
Overview
Kafka streams as continuous and real-time data flow where the data can be either facts or key-value data records. For building various systems, microservices, and applications, Kafka offers Kafka Streams as its lightweight in-built library. With Kafka streams, the input, and output data can be stored in Kafka clusters. It effectively integrates the simplicity for writing and deploying the Java and Scala applications/microservices over the client side.
What are Kafka Streams
Streams can be defined as the data elements flowing provided over time. We can define Kafka streams as continuous and real-time data flow where the data can be either facts or key-value data records. For building various systems, microservices, and applications, Kafka offers Kafka Streams as its lightweight in-built library.
With Kafka streams, the input, and output data can be stored in Kafka clusters. It offers a robust and horizontally scalable messaging system. It can be easily integrated with application code offering a cluster-free mechanism and a sturdy framework to tackle the targeted streaming service. It effectively integrates the simplicity for writing and deploying the Java and Scala applications/microservices over the client side.
Some key points about Kafka streams are listed below:
- Kafka Streams offers a combination of stream concepts as well as tables which can be used for simplifying the processing mechanism.
- Kafka Streams provide uniform and faster data processing even when the new iteration of already running components is added with each new instance.
- To maintain a balance for load processing, a local state might persist on disk while new instances of the same configuration can be created and added with Kafka.
Within Kafka, the Kafka Streams is an easier way to approach the data processing and transformation library. It offers a robust and horizontally scalable messaging system. It can be easily integrated with application code offering a cluster-free mechanism and a sturdy framework to tackle the targeted streaming service.
Why Kafka Streams?
When we try to find the answer if we need Kafka streams, we can vouch for it because of its fault-tolerance and scalability factors. Stream Processing offers integration with Data Storage having stream persistence, as well as static table/data stream joins. Many other frameworks do not offer deployment, composition, as well as network specifics all controlled completely at once. But with Kafka Streams, you get sturdy options for accommodating these requirements.
Advantages offered by the Kafka Streams:
- Offers fault-tolerant architecture.
- Highly scalable which makes it applicable for handling the stream of messages each passing second.
- Offers easy deployment by directly connecting the Kafka Streams to Kafka.
- Easily accessible on Mac, Linux, along with Windows Operating Systems, via traditional Scala or even Java code scripts.
- Effectively handle sensitive data in a much more protected and credible way. This can be done by easily integrating it with Kafka Security.
Kafka Streams Architecture
The illustration gives us a glimpse of the Kafka Streams Architecture where the Streams API is leveraged. A logical view of Kafka Streams contains various stream threads, coating different stream tasks as shown.
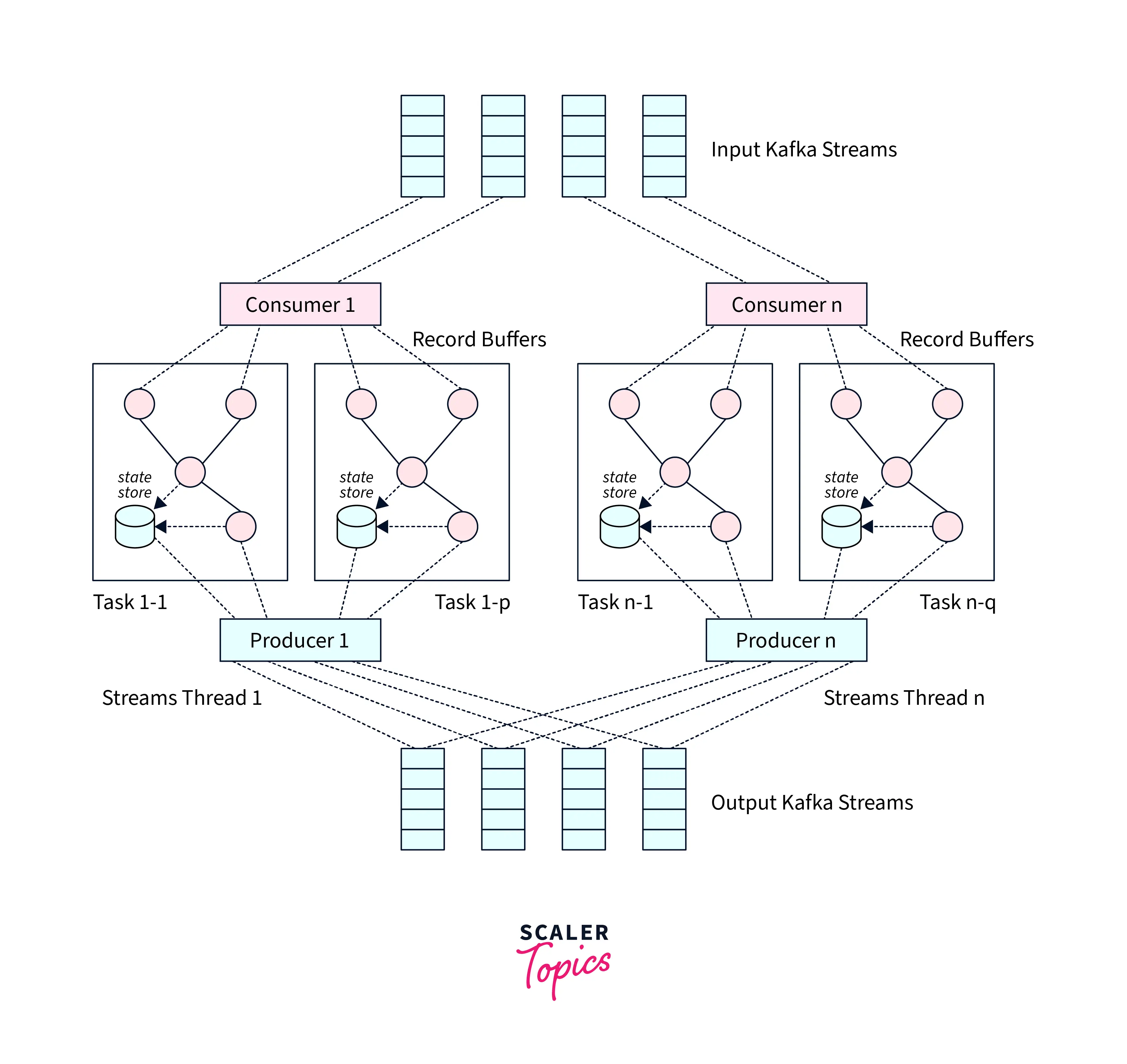
Kafka Streams Architecture
We define a Processor topology (widely known as topology) as the Stream Processing Computational logic for the systems. It shows how the input data gets transformed into the output data. Topology can be decried as a graph of nodes or stream processors which are usually connected by edges ( or streams) or any shared state stores. Developers define their defied topologies either via the low-level processor API or the Kafka Streams DSL. The logical topology is substantiated at runtime well as can be replicated within the application to offer parallel processing to the applications.
As seen in the below illustration, the stream processing topology has two special processors:
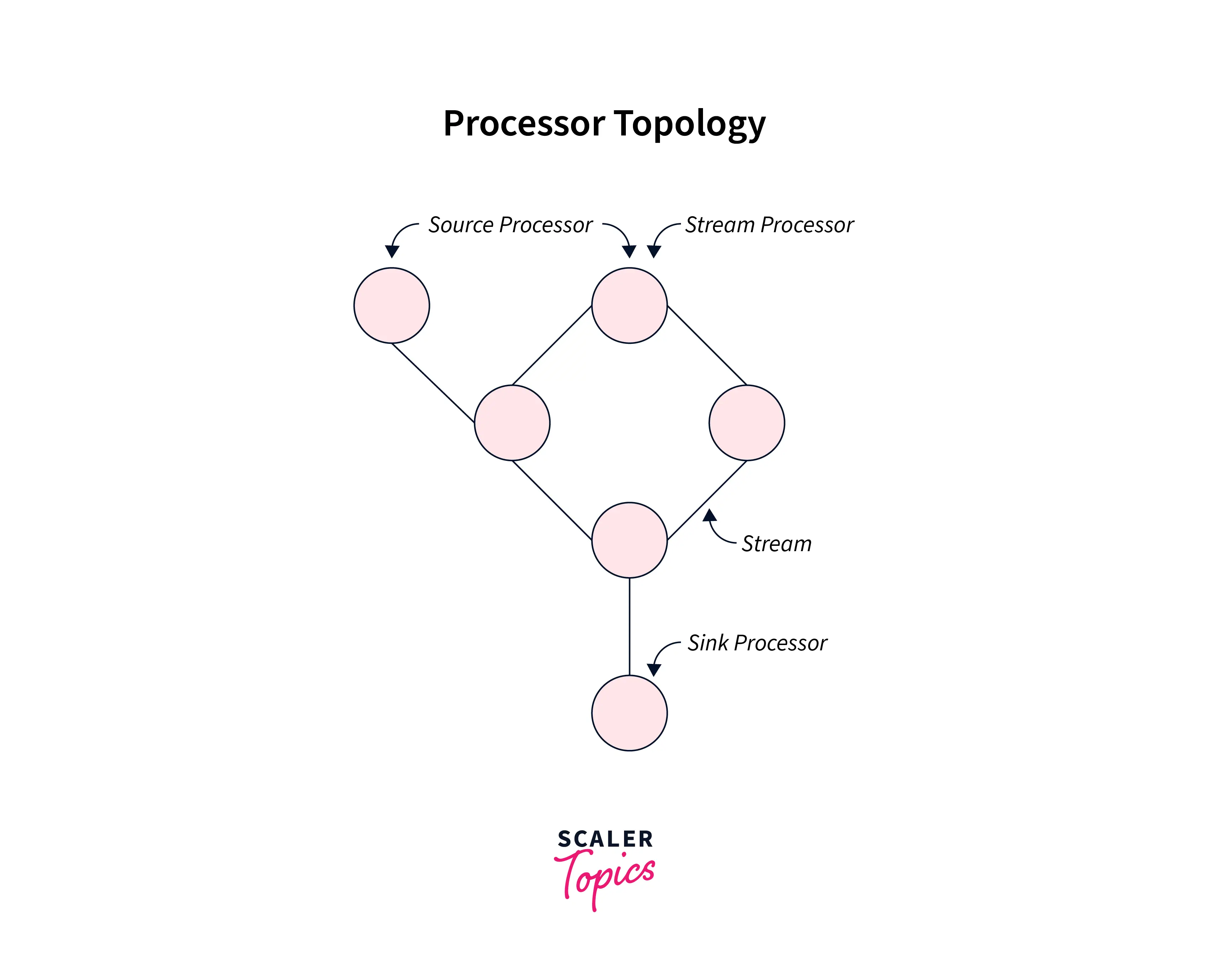
Source Processor: We can define a Source Processor as a stream processor which not leverage any of the upstream processors. Whereas it produces an input stream for its topology for more than one Kafka topic. It does so by extracting records from the Kafka topics and pushing them to the defined downstream processors.
Sink Processor: We can define a Sink Processor as a stream processor which does not have downstream processors. Here it sends the records received from the upstream processors at a defined Kafka topic. There are no downstream processors in the sink processor.
Kafka Streams also offers two ways for representing the stream processing topology as described below:
Kafka Streams DSL: Built on top of Stream Processors API, Kafka Streams DSL refers to the 'Domain Specific Language'. It is widely implemented and used by beginners.
Processor API: Implmeneted widely by the developers for defining the arbitrary stream processors. Here, it processes one record received at a time. Moreover, it connects the processors with their state stores for composing the processor topology. It is this collected topology describing a customized processing logic.
Stream Processing
Stream processing can be understood as something like data-flow programming. With stream processing, users can easily exploit a limited form for parallel processing. Thus, making parallel execution simpler.
Stream Processing Topology
As already studied, Kafka Streams are ordered, fault-tolerant, and repayable, sequences of immutable records.
The stream processing uses the Kafka Streams library for defining its computational code, it can also leverage more than one processor topology. Graphically, the processor topologies are where the 'stream processors' are at the nodes, while each node gets connected with 'streams' as its edges. The overall functioning of the stream processor works like receiving one input record from the upstream processors, performing operations to transform, and finally producing more than one output record to the downstream processors. This way, the stream processor defined the steps by the method of transforming the data in streams.
Scaling Kafka Streams
When it comes to scaling the Kafka streams, Kafka allows its users to achieve high scalability for its applications by balancing load and state between the instances as per the same pipeline. Kafka streams allow its users to search and find out the node that hosts the key when the results are aggregated results and distributed across the defined set of nodes. This helps the users to keep track of the application that could collect the data from the correct node or even for sending the data to the clients, the correct node could be selected.
Interactive Queries
Let us talk about how Kafka streams help for the use case of interactive queries. Applications are distributed across various instances, where each of these applications are locally managed state store, users need a solution where they can externally query the application.
Kafka Streams makes it possible with its interactive queries which enable the applications could be queried from outside via the Kafka Streams API from outside the application. The local state store of an application instance can efficiently be queried from outside by the developers like through a local key-value store, a local window store, or a local user-defined state store. Also, developers get the capability to add an RPC (Remote Procedure Call) layer to the system like REST API. This helps the developer to expose the application’s RPC endpoint, and eventually discover the system instance along with its local state store. Lastly, the developer can then externally query the remote state store over the entire application.
Stream Threading
We should know that there is an automatic handling of the distribution of Kafka topic partitions to Kafka stream threads in Apchae Kafka streams. The number of threads can be set according to the requirement of your system for the parallel processing of system instances. Because of this, more than one Kafka stream job can independently perform. For effective parallel processing, users can set the configuration such that there is a launch of more stream threads or across more instances of a system. This shall replicate the topology which will let another subset of Kafka partitions process it effectively. No coordination between the threads is necessary as the threads in stream threading do not share the same state.
Stream-Table Duality
The processes of both a stream as well a table are demanded from Kafka's end when practical use cases are concerned. And the Kafka Stream can provide this functionality to its users with its Stream Table Duality. In the Stream table duality, both the tables as well as streams work together to make your application or systems more elastic, offer stateful fault-tolerant data processing along with execute the Kafka Streams Interactive Queries contrary to the system’s data processing outputs.
Users can view the Kafka streams as past table modifications where each record present in the stream is ready to record the modification made in the element of the table. Hence, a Kafka stream can easily be transformed into a “actual” table and acts like one. From beginning to end, by simply echoing the changelog and reviving the table, a stream can start to act like a table.
With that being said, a table can also be seen as a snapshot of every key in its past value at a specific instance in time at the stream. The record is generally stated as a key and value pair in the stream. Hence, the table behaves like a stream. It can simply be transformed into a “actual” stream by allowing the simple iteration over every key-value entry present in the table.
What is Kafka Streams API?
To ease the Stream Processing process, Kafka offers the Kafka streams API from multiple disparate topics. With the Kafka stream API, users can achieve scalability, data parallelism, coordination across distributed clusters, as well as fault tolerance. The approach of tasks along with the partitions being considered as logical units are significantly leveraged by the Kafka streams API. This is strongly linked with the topic partitions as well as seamlessly interacting with the Kafka cluster. The differentiating factor offered by Kafka streams AI is applications could be easily built with traditional Java applications which can seamlessly be deployed, monitored, or packaged, like any Java application.
Kafka Streams API: Use Cases
Let us have a look at some of the useful use cases offered by Kafka streams API for simplifying any applications:
- Finance Industry: Users can build systems/applications that will gather and accumulate various data sources for real-time views of any potential threats/exposures. This will help to detect and eventually minimize any fraudulent transactions.
- Travel Industry: Organizations can leverage the Kafka API to build applications that could help them invest more time in taking decisions based on the real-time output coming. This shall offer suitable pricing for individual customers allowing them to cross-sell the additional services or process reservations and bookings.
- Retailers Industry: Firms are leveraging the Kafka API to offer the next best offers, personalized promotions, pricing, and inventory management with real-time data streaming.
- Logistics organizations These are building systems or applications to track shipments quickly, reliably, and most important in real-time.
Kafka Streams vs. Kafka Consumer
We shall now differentiate between Kafka Streams vs. Kafka Consumer to get a better glance between the two. While Kafka streams can be defined as simple data processing as well as a transformation library that is inbuilt into Kafka and utilized as a messaging system. While we define the Kafka consumer API as a mechanism that offers the applications to process the various messages from the topics. While Kafka streams consist of a single stream from where it can consume and produce, for Kafka consumers the stream where it can consume and produce are separated. With Kafka, consumer users get the ability to write across various Kafka clusters, while with Kafka streams users can interact only with a single Kafka cluster.
Users can easily perform any complex data processing through Kafka streams but batch processing is restricted. In Kafka consumer, users can perform only single processing and can batch process the jobs. With Kafka streams, you get both stateless and stateful operations, while with Kafka consumer-only stateless operations are supported.
Conclusion
- Kafka Streams offers a combination of stream concepts as well as tables which can be used for simplifying the processing mechanism.
- With the Kafka stream API, users can achieve scalability, data parallelism, coordination across distributed clusters, and fault tolerance. The concepts of partitions and tasks as logical units are significantly leveraged by the Kafka streams API.
- Users can view the Kafka Streams as a history of table changes where every record in the stream is ready to record the change in the state of the table. Hence, a Kafka stream can easily be turned into a “real” table and acts like one.
- The number of threads can be set according to the requirement of your system for parallel processing of system instances. Because of this, more than one Kafka stream job can independently perform.
- For effective parallel processing, users can set the configuration such that there is a launch of more stream threads or across more instances of a system.