Configuring Kafka Streams: An In-depth Guide
Overview
Since the 0.10.0 release, Apache Kafka has included the Kafka Streams API, which is a Java library that empowers users to construct stateful stream processing applications that operate on real-time data from Kafka. Applications developed using the Streams API can efficiently process streaming data in real-time, taking into account the event time at which the data was originally generated. These applications also offer support for handling late-arriving records, and they can be easily scaled, distributed, and resilient to faults.
Brief Overview of Apache Kafka and Kafka Streams
Apache Kafka is an open-source distributed event streaming platform that is widely used for building real-time, scalable, and fault-tolerant data pipelines and streaming applications. It provides a high-throughput, fault-tolerant, and durable messaging system that allows you to publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.
Kafka Streams is a client library provided by Apache Kafka for building real-time stream processing applications. It enables developers to process and analyze data streams in real-time using a simple and scalable programming model. With Kafka Streams, you can transform, filter, aggregate, and join data streams in a distributed and fault-tolerant manner.
Importance of Configuration in Kafka Streams
Configuration plays a crucial role in Kafka Streams as it allows developers to tailor the behavior of their stream processing applications according to specific requirements. Here are some key reasons highlighting the importance of configuration in Kafka Streams:
- Customizing Application Behavior: Configuration parameters enable developers to customize various aspects of the stream processing application, such as the processing guarantees, resource allocation, and performance optimizations. It allows them to fine-tune the application to meet specific requirements and performance expectations.
- Connectivity and Integration: Kafka Streams configuration includes properties related to connecting to the Kafka cluster, such as specifying the bootstrap servers. It also involves setting up input and output topics, which determine the data sources and destinations for the stream processing application. The proper configuration ensures seamless connectivity and integration with the Kafka ecosystem.
- Serdes and Data Serialization: Kafka Streams relies on serializers and deserializers, known as Serdes, to convert data between binary format and Java objects. Configuration properties allow developers to specify the Serdes for the key and value types used in the stream. Proper configuration of Serdes ensures compatibility and efficient data serialization and deserialization.
- Performance Optimization: Kafka Streams provides automatic optimization of the processing topology. However, certain configuration properties allow developers to control aspects of optimization, such as specifying whether to optimize for security or performance. Fine-tuning these properties can significantly impact the overall performance and efficiency of the stream processing application.
Understanding Kafka Streams
Let us now understand what is kafka streams in details.
What is Kafka Streams?
Kafka Streams is a client library provided by Apache Kafka for building real-time stream processing applications. It enables developers to process and analyze data streams in real-time using a simple and scalable programming model.
At its core, Kafka Streams leverages the Kafka messaging system to consume streams of records from Kafka topics, perform processing operations on the records, and produce results back to Kafka topics or other external systems. It supports both event-time and processing-time semantics, allowing developers to process data based on the time it was generated in the real world.
Kafka Streams provides a high-level DSL (Domain-Specific Language) and a low-level Processor API, giving developers flexibility in choosing the level of abstraction for their application. The DSL offers a declarative and intuitive approach to define processing topologies using high-level operations such as filtering, transforming, aggregating, and joining streams of data.
The library also provides fault-tolerance and stateful processing capabilities. Kafka Streams maintains the state of the application, allowing it to handle failures gracefully and recover processing from the point of failure. This enables developers to build reliable and fault-tolerant stream processing applications without the need for external state stores.
Kafka Streams supports horizontal scalability by distributing the processing workload across multiple instances of the application, providing scalability and high throughput. It integrates seamlessly with the Kafka ecosystem, allowing applications to easily consume and produce data to Kafka topics and interact with other components of the Kafka ecosystem, such as Kafka Connect and Kafka Streams' interactive queries.
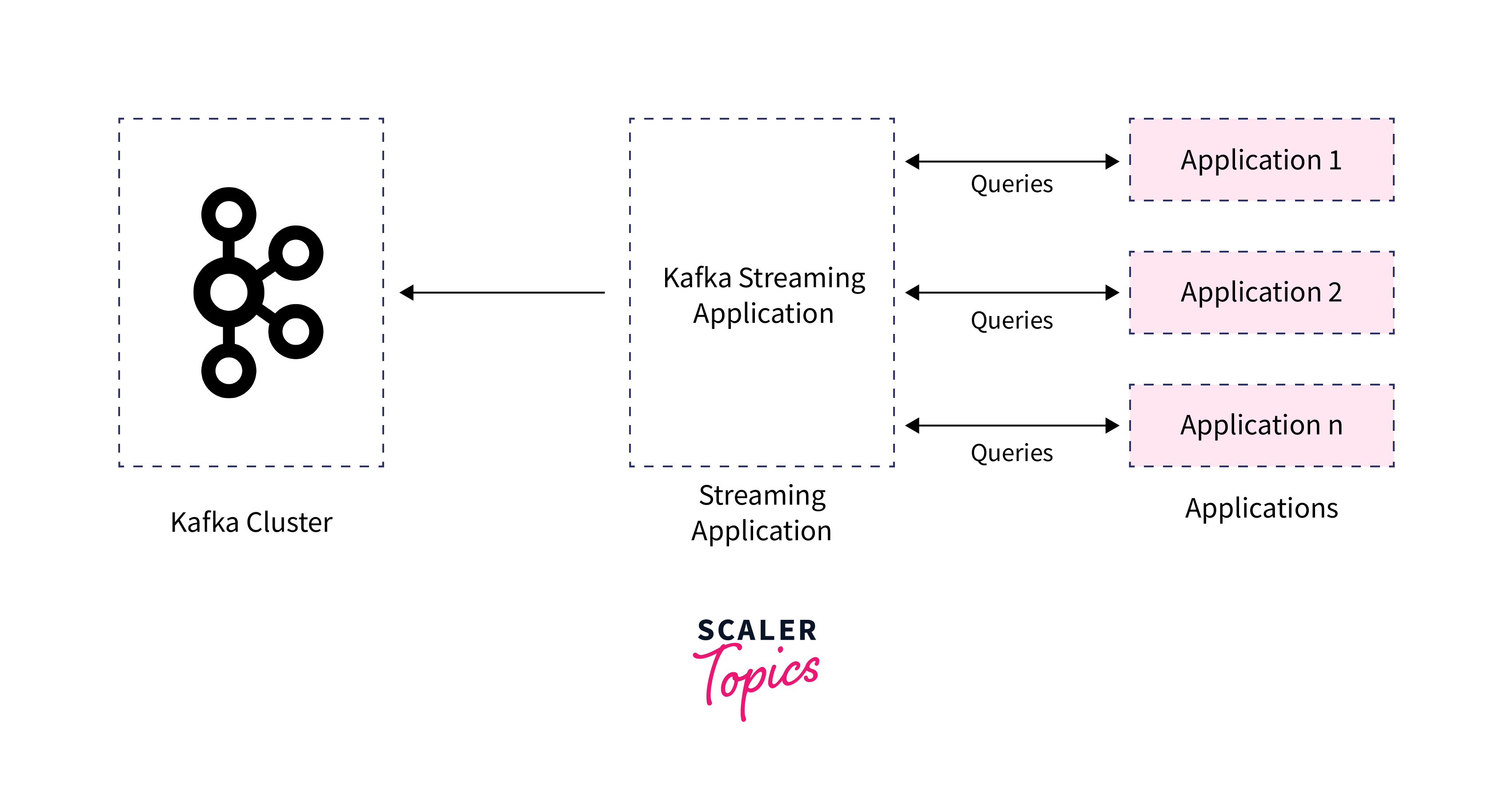
Key Features and Advantages of Kafka Streams
Kafka Streams offers several key features and advantages that make it a powerful choice for building real-time stream processing applications. Here are some of its key features and advantages:
- Stream Processing Library: Kafka Streams provides a lightweight and easy-to-use stream processing library that is seamlessly integrated with Apache Kafka. It allows developers to process and analyze data streams in real-time without the need for additional dependencies or external processing frameworks.
- Distributed and Scalable: Kafka Streams is designed to be distributed and scalable, allowing you to scale your stream processing applications horizontally by adding more instances to handle increased workloads. It leverages the distributed nature of Kafka to provide fault tolerance, reliability, and high throughput.
- Stateful Processing: Kafka Streams supports stateful processing, allowing you to maintain and query the state of your application. It simplifies the handling of state by providing built-in abstractions for managing state stores. This enables you to perform complex processing tasks that require maintaining and updating state, such as sessionization, aggregations, and joins.
- Event-Time Semantics: Kafka Streams supports event-time processing, which means it allows you to process events based on the time they occurred in the real world. It provides mechanisms for handling out-of-order events and late-arriving data, ensuring accurate and reliable processing of time-sensitive data.
- Fault Tolerance and Exactly-Once Processing: Kafka Streams provides strong fault-tolerance guarantees by leveraging the fault-tolerant design of Kafka. It ensures that the state of the application is preserved in the event of failures and enables exactly-once processing semantics, which guarantees that each record is processed exactly once, even in the presence of failures or restarts.
- Integration with Kafka Ecosystem: Kafka Streams seamlessly integrates with the broader Kafka ecosystem. It can consume and produce data from/to Kafka topics, interact with Kafka Connect for data ingestion and egress, and utilize interactive queries to retrieve and serve real-time queryable results from state stores.
- High-Level DSL and Processor API: Kafka Streams offers a high-level DSL that provides a declarative and intuitive way to define stream processing topologies. It also provides a lower-level Processor API for more advanced use cases and fine-grained control over the processing logic.
Kafka Streams Configuration Basics
Configuring Kafka Streams is essential to customize the behavior and performance of your stream processing application. Here are the basics of Kafka Streams configuration:
- Application ID: Each Kafka Streams application requires a unique identifier known as the application ID. It is used to maintain the state of the application and enable fault-tolerance and stateful processing. You can set the application ID using the application.id configuration property.
- Bootstrap Servers: Kafka Streams needs to connect to the Kafka cluster, and for that, you need to specify the address of one or more Kafka brokers. This is done through the bootstrap.servers configuration property.
- Serde Configurations: Kafka Streams requires serialization and deserialization configurations, known as Serdes, for the key and value types in the stream. You need to specify the Serde classes for your data types using properties like default.key.serde and default.value.serde.
- Topology Optimization: Kafka Streams automatically optimizes the processing topology for performance. However, you can control certain aspects of optimization by setting properties such as topology.optimization and optimization.security.enable.
- Error Handling: Kafka Streams provides built-in error handling mechanisms. You can configure the maximum number of attempts for handling a processing record using properties like max.task.attempts. You can also specify a dead-letter topic to redirect failed records using dead-letter-topic.name.
- Processing Guarantees: Kafka Streams offers two processing guarantees: "at least once" and "exactly once." The default guarantee is "at least once," which means that records might be processed more than once in case of failures. You can configure the processing guarantee using the processing.guarantee property.
- State Stores: Kafka Streams allows you to maintain and query stateful data by creating state stores. You can configure the store name, size, and retention properties using properties like state.store.name, state.store.max.bytes, and state.store.cleanup.delay.ms.
- Streams and Topics Configuration: You need to configure the input and output topics for your stream processing application. This includes specifying the source topic name using source.topic.name and the destination topic for processed records using sink.topic.name.
Here's an example of Kafka Streams configuration code
Configuring Fault Tolerance in Kafka Streams
Here are some key steps to configure fault tolerance in Kafka Streams:
- Enable the state store replication: Kafka Streams uses state stores to maintain the intermediate results and to provide fault tolerance. By default, Kafka Streams replicates the state stores to ensure durability. Ensure that the num.standby.replicas property is set appropriately to specify the number of standby replicas for each partition.
- Configure the application ID: The application ID is used to identify a Kafka Streams application and its associated state. It is crucial to set a unique and consistent application ID for each instance of your Kafka Streams application. This helps in ensuring that the application instances can seamlessly take over processing in case of failures.
- Define the processing guarantees: Kafka Streams provides two processing guarantees: "at least once" and "exactly once." You need to configure the desired processing guarantee based on your application's requirements. The choice of guarantee affects the level of fault tolerance and the deduplication of records.
- Configure the consumer and producer settings: Kafka Streams uses a Kafka consumer to read data from input topics and a Kafka producer to write data to output topics. Make sure to configure the consumer and producer settings to handle common error scenarios, such as network failures, broker unavailability, and retries.
- Handle exceptions and errors: Implement proper error handling in your Kafka Streams application. You can use the StreamsUncaughtExceptionHandler to handle uncaught exceptions and errors that occur during stream processing. This allows you to define custom logic to handle failures and errors gracefully, such as logging the error, sending a notification, or taking corrective actions.
- Monitor and manage your Kafka Streams application: Set up monitoring and observability for your Kafka Streams application. Monitor metrics related to processing rates, lag, and error rates. Use monitoring tools like Apache Kafka's built-in metrics or external monitoring solutions to gain insights into the health and performance of your application. This helps in identifying potential issues and taking proactive actions.
- Test fault tolerance scenarios: Validate the fault tolerance mechanisms of your Kafka Streams application by simulating failure scenarios. This includes testing scenarios like network failures, broker failures, and application failures. By simulating failures, you can ensure that your application can recover and resume processing without data loss.
Performance Considerations in Configuration
When configuring a Kafka Streams application, there are several performance considerations to keep in mind to optimize the processing speed and resource utilization:
The Impact of Configuration on Kafka Streams Performance
Here are some specific aspects of configuration that can influence Kafka Streams performance:
- Parallelism: Configuring the appropriate level of parallelism can significantly impact the performance of a Kafka Streams application. The num.stream.threads property determines the number of processing threads within each application instance. Increasing the parallelism allows for more concurrent processing, which can improve throughput. However, it's important to strike a balance, as increasing parallelism beyond the capacity of available resources may lead to resource contention and decreased performance.
- State store configuration: Kafka Streams maintains internal state stores for intermediate results. The configuration of state stores, such as their size and retention period, can impact performance. Oversizing state stores can lead to increased memory consumption, while undersizing them may result in frequent disk access, affecting processing speed. Careful estimation of state store size and proper configuration can help optimize performance.
- Windowing and retention periods: Kafka Streams supports windowed operations for time-based aggregations. The configuration of window sizes and retention periods can impact performance. Choosing appropriate window sizes is crucial to strike a balance between memory usage and processing efficiency. Longer retention periods may require more resources to maintain the state, while shorter periods may result in more frequent data eviction and recomputation.
- Caching configuration: Kafka Streams provides a local state cache to reduce disk access during processing. Configuring the cache size (cache.max.bytes.buffering) appropriately is important for optimizing read and write operations. A larger cache can improve performance by reducing disk I/O, but it may also increase memory consumption. Balancing the cache size with available memory resources is essential for optimal performance.
- Serde selection: The serialization and deserialization (Serde) mechanism used in Kafka Streams can impact performance. Choosing efficient and lightweight Serde implementations for your data types can minimize the overhead of data conversion, resulting in improved processing speed.
- Network and Kafka cluster configuration: The performance of a Kafka Streams application can be influenced by the configuration of the underlying Kafka cluster and the network settings. Properly configuring network buffers, socket timeouts, and relevant Kafka parameters can minimize latency and maximize throughput.
- Monitoring and optimization: Monitoring the performance metrics of a Kafka Streams application is crucial for identifying bottlenecks and optimizing its configuration. Monitoring tools can provide insights into processing rates, latency, and resource utilization. Based on these metrics, you can fine-tune the configuration parameters to improve performance.
Tuning Configurations for Performance (Buffer Sizes, Batch Sizes, Compression)
To tune configurations for performance in Kafka Streams, several parameters can be adjusted. Here are some key configuration options to consider:
- Buffer sizes:
- buffer.memory: This parameter specifies the total amount of memory available to the producer for buffering records. Increasing the buffer memory can improve performance by allowing more records to be batched and sent in a single request. However, setting it too high can lead to increased memory consumption.
- fetch.min.bytes: This parameter defines the minimum amount of data that the consumer fetches in a single request. Increasing this value can reduce the frequency of network requests, improving performance by reducing overhead. However, it may increase latency.
- Batch sizes:
- batch.size: This parameter sets the maximum size of a batch before it is sent by the producer. A larger batch size can improve throughput by reducing the number of network roundtrips. However, larger batches also increase the memory footprint and introduce additional latency. It's important to find an optimal value based on your use case and available resources.
- max.poll.records: This parameter determines the maximum number of records the consumer will fetch in a single poll. Increasing this value can improve throughput by fetching more records in each request, but it may also increase the processing time per poll.
- Compression:
- compression.type: Kafka supports compression of message payloads. Enabling compression (e.g., using the gzip or snappy compression types) can reduce network bandwidth usage, especially when dealing with large amounts of data. However, compressing and decompressing data also introduces CPU overhead, so it's important to evaluate the trade-off between network bandwidth savings and CPU utilization.
- Consumer configuration:
- max.partition.fetch.bytes: This parameter defines the maximum number of bytes to fetch from a single partition in a single request. Increasing this value can reduce the frequency of network requests, improving performance. However, it may also increase the time taken to process a single batch of records.
- Producer configuration:
- linger.ms: This parameter controls the amount of time the producer waits before sending a batch of records. Setting a non-zero value can allow more records to be batched together, improving throughput by reducing the number of requests. However, it may introduce additional latency.
- Monitoring and optimization:
- Monitor performance metrics such as throughput, latency, and resource utilization. Use Kafka's built-in metrics or external monitoring tools to gain insights into the behavior of your Kafka Streams application. Identify bottlenecks and areas for improvement, and adjust the configuration parameters accordingly.
Memory Management
In Kafka Streams, memory management is an important aspect to consider for efficient and reliable processing of streaming data. Kafka Streams provides mechanisms to manage memory consumption and optimize performance.
Memory management in Kafka Streams involves managing two key components: the record caches and the state stores.
Record Caches: Kafka Streams uses record caches to buffer incoming and outgoing records during processing. These record caches are managed in two main ways:
- Input Record Cache:
The input record cache buffers incoming records from Kafka topics before they are processed. The size of the input record cache can be configured using the cache.max.bytes.buffering property. By default, it is set to 10 MB.
Example configuration:
- Output Record Cache:
The output record cache buffers records that are produced to Kafka topics. This cache helps in achieving higher throughput by batching multiple records before writing them to Kafka. The size of the output record cache can be configured using the buffered.records.per.partition property. By default, it is set to 1000 records.
Example configuration:
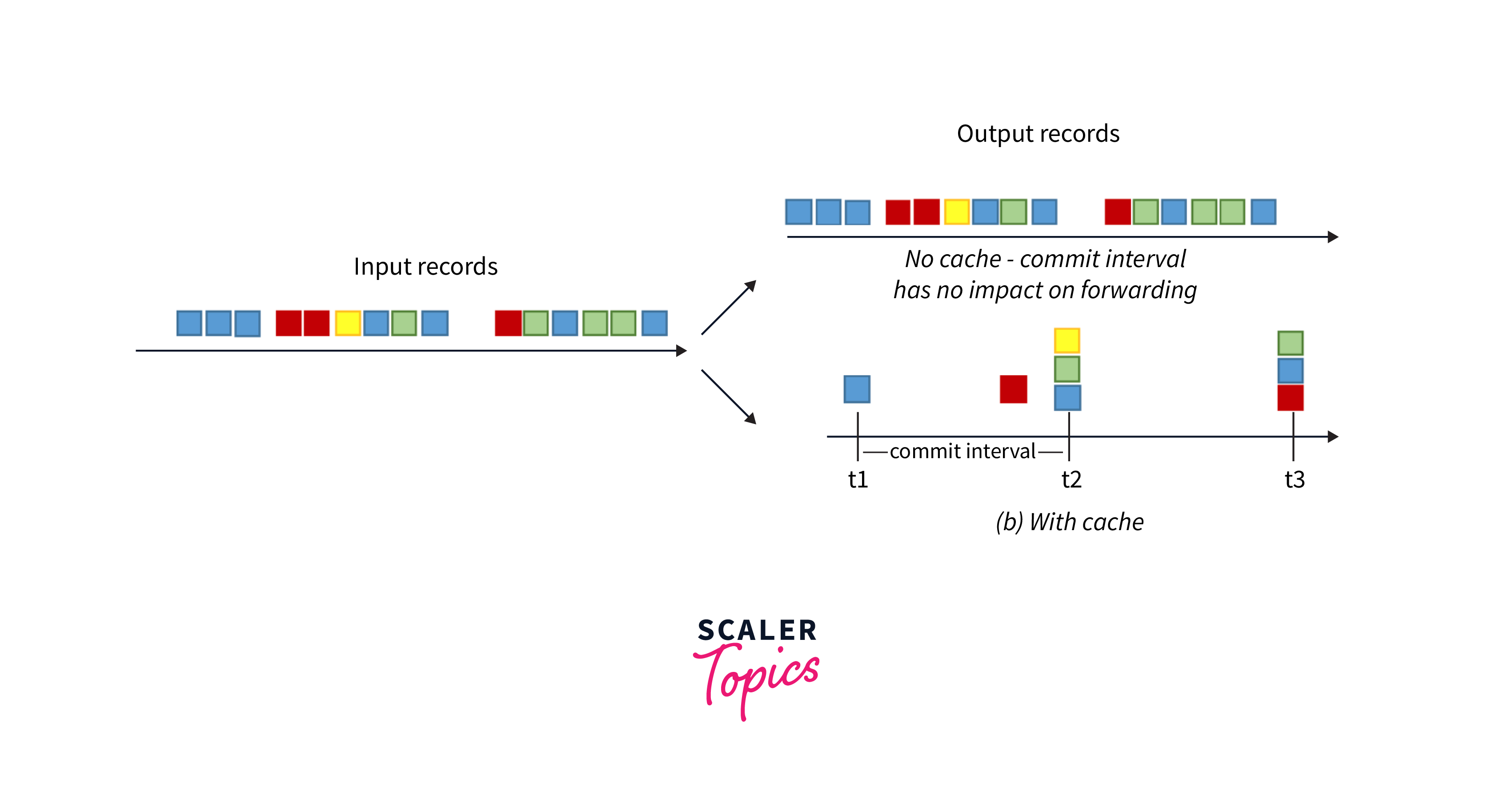
State Stores: Kafka Streams allows maintaining stateful operations by using state stores. These state stores are used to store and manage the intermediate results and windowed data. Proper memory management for state stores is crucial for efficient processing. Some considerations for managing state stores include:
- Configuring the Maximum State Size:
You can configure the maximum size of the state stores using the state.store.max.bytes property. This property defines the maximum number of bytes that can be used for state storage. If the state store exceeds this limit, older entries will be evicted to make room for new entries.
Example configuration:
- Enabling Changelog Compression:
Kafka Streams provides the option to enable compression for the changelog topics used by state stores. This helps reduce the storage footprint and memory consumption.
Example configuration:
These are some of the key aspects of memory management in Kafka Streams. It is important to configure these properties based on your application's requirements and available resources to achieve optimal performance and stability.
Conclusion
- Kafka Streams is a powerful library for building real-time stream processing applications on top of Apache Kafka.
- Configuration is essential for fine-tuning and customizing the behavior of Kafka Streams applications to meet specific requirements.
- The configuration for Kafka Streams can be set using properties files or programmatically through the Kafka Streams API.
- Monitoring and metrics configuration enables monitoring the health and performance of Kafka Streams applications, allowing for timely detection of issues and performance bottlenecks.
- Proper configuration management practices involve version control and documentation of the configuration settings to ensure consistency and ease of maintenance.
- By understanding and correctly configuring Kafka Streams, developers can optimize the behavior, performance, security, and monitoring of their real-time stream processing applications, ensuring reliable and efficient data processing on the Kafka platform.