Key Features and Benefits of Kafka
Overview
Apache Kafka is distributed platform with various key features like distributed architecture, scalability, durability, and high throughput due to which more than 60% of Fortune 500 companies use it. The key feature of Kafka is to deliver a large number of messages with minimal latency and without fault and achieve scalability. The complex and distributed architecture of Kafka helps us achieve these key features.
Introduction
Apache Kafka is an open-source and distributed streaming platform that can handle the streaming of large data with extremely low latency. Kafka was developed by LinkedIn and later on, became open source by Apache. It is free to use and download. Kafka provides greater flexibility. Kafka is implemented in Java and Scala but we can use Python, Java, Scala, etc to write Kafka code i.e. communicate with Kafka clusters and topics.
What is Kafka Used for?
Kafka is used in almost every industry ranging from small startups to Fortune 500 companies. Kafka is used almost in every sector ranging from healthcare to the tech industry. Below are a few cases where Kafka is used:
- User activity:
Linkedin made Apache Kafka to track a user's activity on its application. The user's activity includes liking, reading, creating and sharing new posts, searching other people, connecting, following, and unfollowing people. Thus a huge amount of data needed to be processed, LinkedIn made Apache Kafka to keep track of this huge data consisting of activities. - Log changes:
Kafka can be used to keep track of logs in the databases. Various changes like create, read, update and delete (CRUD) operations can be recorded with extremely low latency. - Notification:
Kafka can be used to send notifications and messages to users. Kafka is used to deliver large volumes of data in messaging applications. Kafka is used to handling real-time chatting between users.
Key Features of Kafka
There are several benefits of Kafka due to its key features. Kafka has higher throughput and low latency and thus it is widely used by most companies. It is highly scalable and free to use.
Distributed Architecture
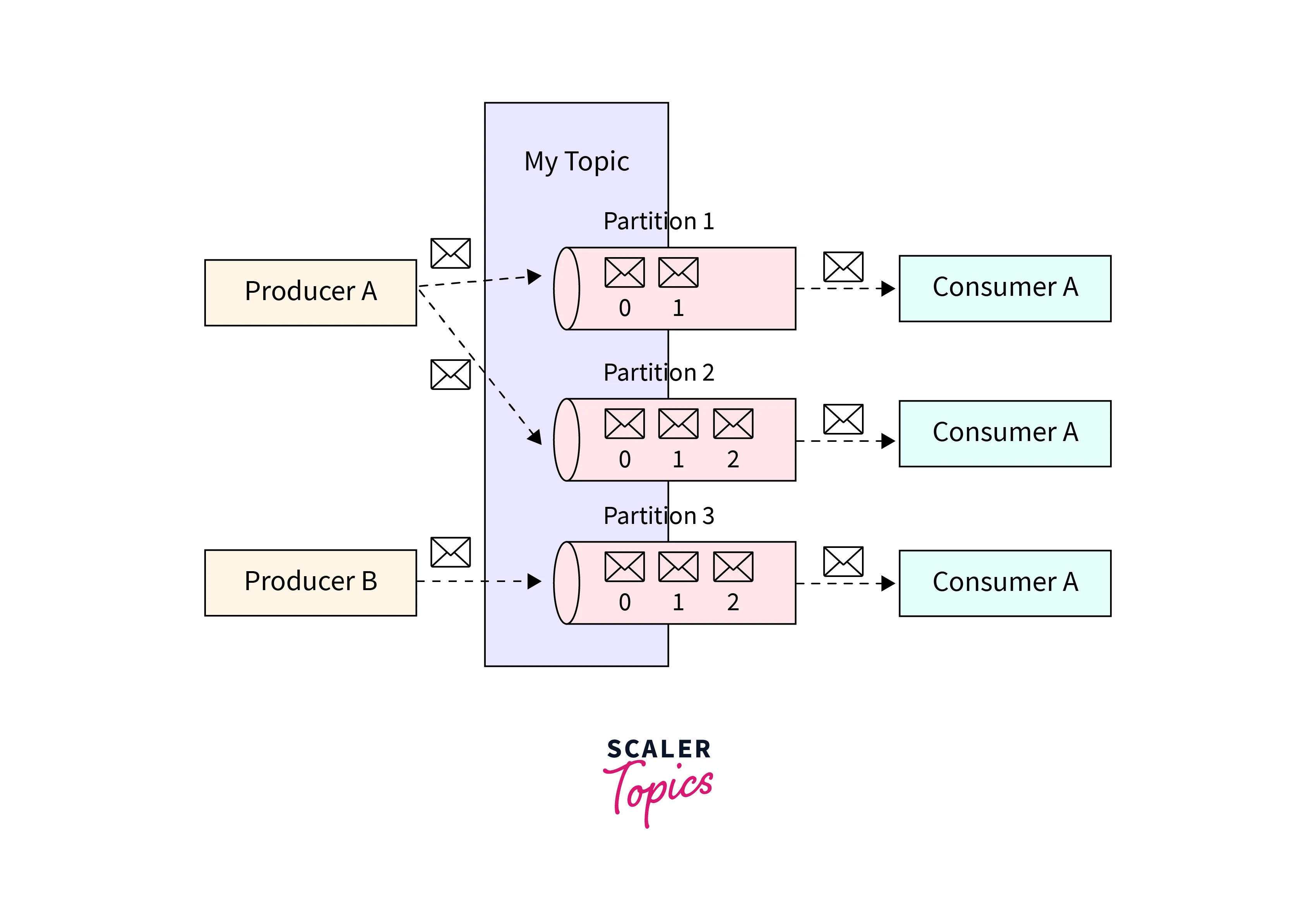
Kafka's distributed model helps it to stream large volumes of data with extremely low latency. Data is divided across brokers i.e. data is parallel processed across brokers which helps us to handle large volumes of data.
Scalability
One of the reasons why Kafka is widely used is scalability. Kafka allows horizontal scaling which allows us to add new servers to handle large amounts of data. Kafka allows us to add hundreds of servers. During the addition of servers, the Kafka system remains online and does not go down.
Kafka achieves scalability using partitioning, replication, and rebalancing. Each topic is divided into multiple partitions which helps us in achieving parallel processing. This helps us to achieve scalability.
Durability
Kafka guarantees that the message will be delivered to the consumer at least once i.e. it provides at least one delivery message service. Thus it ensures that the data is not lost and is delivered at least once.
Kafka achieves durability by using replication. Each message of Kafka is written into multiple brokers thus creating multiple copies of the data. Thus the data in a particular broker is not lost during the broker failure as multiple copies of the data are present.
Real-time processing
Kafka can achieve real-time processing because of its low latency and high throughput. Kafka offers a pub-sub messaging model where producers publish data and consumers subscribe to the topic to get the data in real time.
Integration with Other Technologies
Kafka is a very powerful open-source tool. It allows us to integrate with third-party applications so that we can use Pub-sub with Kafka. Some of the key technologies that Kafka integrates include Apache Spark, Apache Hadoop, Elasticsearch, etc.
Low Latency
Kafka provides extremely low latency by using batching, partitioning, and compression of data.
- Batching:
We can read and write data in batches. This allows us to reduce the number of requests and helps us to reduce latency. - Partitioning:
Partitioning helps us divide data among different brokers and do parallel processing. - Compression:
Whenever data is written to a Kafka topic, it is compressed using algorithms like ZStandard, LZ4, Gzip, Snappy etc. to reduce read and write bandwidth. As the data amount is less, it can be delivered quickly and thus results in low latency. Compression also reduces storage costs.
Benefits of Kafka
- Scalability
Apache Kafka provides high scalability. Scalability is also one of the best features of Kafka. Scalability can be achieved by using distribution and partitioning. Kafka uses partition to do parallel processing by transferring messages across multiple brokers. It stores messages across different partitions and thus several consumers can read messages from different partitions. This improves the performance of Kafka. - Multiple producers and consumers
Multiple producers can produce data in Kafka simultaneously and multiple consumers can consume data from Apache Kafka. Multiple producers can write data into the same Kafka topic and thus do parallel processing. The Kafka topic creates a partition that helps in increasing the throughput of the system. Similarly, multiple consumers can read data from the same Kafka topic and do parallel processing.
Kafka allows multiple producers and consumers to use the following APIs:- Kafka producer API:
Kafka producer API allows third-party applications to produce data into Apache Kafka topics. The API supports several programming languages like Java, Scala, Python, etc. - Kafka consumer API:
Kafka consumer API allows third-party applications to consume data from Apache Kafka topics. The API is too written in several languages.
- Kafka producer API:
- Support for different consumption needs
Kafka allows you to read data in real-time as well as in batch mode and with your individual rate. Kafka also allows you to set data retention time which allows you to keep the data as long as you want into the disk. The default data retention time is 1 week but we can change this time according to our requirement. - High-performance
Kafka has extremely high performance. It achieves high performance due to its architecture. Several factors like distributed architecture, partitioning, compression, batching, caching, asynchronous processing, etc help us achieve high performance. Uber uses Kafka to process more than a trillion messages per day. The Chinese company Tencent processes more than ten trillion messages per day. This shows that Kafka has a very high performance. At peak rates, LinkedIn processes over million messages per second using Kafka. - Low Latency
Low latency is one of the key features of Apache Kafka. Lower latency means the data can be read and written in Apache Kafka in lesser time. Kafka achieves low latency by using a distributed architecture, persistent storage, compression, batch processing, parallel processing, and partitioning.- Caching: Kafka maintains a cache of frequently used data to reduce the processing time.
- Distributed architecture: Apache Kafka allows distributed architecture where data can be read and written across multiple nodes. This helps in parallel processing of the data.
- Asynchronous processing: This allows producers and consumers to work independently of each other and improve overall performance.
- Compression: Compression helps us to reduce the amount of data that is to be transferred and stored in the partition. This helps us to achieve faster data transfer along with lower storage costs. Kafka uses various compression algorithms like ZStandard, LZ4, Gzip, Snappy, etc to compress the data. The default compression library used by Kafka is Snappy.
- Partitioning: Partitioning allows messages to write and read messages across multiple nodes. This reduces data read and write time and helps in achieving lower latency.
- Batch processing: Kafka processes data in a batch which improves the performance. By using batch processing, we can write and read data in batches which improves the performance significantly.
- Storage type: Apache Kafka stores data on disk. Storing data on disk helps us to achieve persistence, scalability, durability and improve performance. The data on the disk is not lost during times of system failure.
- Kafka Connect for simple integration
Kafka Connect, an open-source framework that helps us to integrate Kafka with its third-party applications by using hundreds of connector plugins. Kafka Connect helps us to read and write data from Kafka. This framework helps us to connect Kafka with third-party applications with high performance. - Flexibility
Kafka is highly flexible and allows you to change broker and cluster configuration, change replication factor, and data retention time. One can change the configuration according to our requirements. - Multi-language environment
Kafka is written in Java and Scala but we can work with Kafka by using a variety of languages like Scala, Java, Python, C++ etc. There is a wide range of libraries that help us to work with Kafka using these languages. - Security
We can secure data in Kafka by using various security features offered by Kafka like SSL/TLS (Secure socket layer/Transport layer security) encryption as well as the ACL (Access control list) feature. - Large user community
Kafka is an open-source system with a large user community. There are thousands of projects which are trying to improve Kafka by making it more scalable, durable, and improve performance. - Multiple Kafka vendors
There are several vendors which provide Kafka-based services. Some examples include Confluent, AWS, Microsoft Azure, IBM Cloud, Google Cloud, etc.- Confluent:
The creators of Kafka founded Confluent and provide streaming platforms like Confluent Platform, Confluent Cloud, and Kubernetes Confluent. - Amazon Web Services:
Amazon Web Services (AWS) provides a completely managed Kafka service i.e. Amazon Managing Stream for Kafka (Amazon MSK). It is helpful to run systems that use Kafka. - Google Cloud:
Google Cloud provides Cloud Pub/Sub for Kafka which is completely managed Kafka services.
- Confluent:
- Rich documentation, guides, and learning resources
There is rich and detailed documentation on Kafka concepts, how to use Kafka, and other helpful software. A beginner can understand Kafka by reading documentation, papers, books and videos that explain how to use Kafka in detail.
Disadvantages of Using Kafka
Although there are several benefits of Kafka, it has some disadvantages too. Let us discuss each of them one by one:
- Steep learning curve and technological complexity
Those who are learning Kafka may find it difficult to learn and understand. The reason is that it has complex architecture and requires an understanding of how to integrate various third-party applications etc.
Let us see each of the reasons in detail:- Complex architecture:
Kafka has several components that form the distributed system. One has to understand the working and usage of Zookeeper, Cluster, broker, partitions, topics, etc. When working in a complex environment, one has to know how to configure them together to get the best output. - Distributed System:
Kafka consists of several nodes and brokers that control it. Configuring and deploying them for the first time can be quite challenging. - Performance tuning:
One has to take care of configuration and tuning otherwise one may not get the desired throughput and latency. The developers have to take care of the security to prevent data leaks. One must learn the following things in the beginning. - Third-party integrations:
Kafka can be integrated with various third-party applications. One has to learn how to integrate with them which requires special knowledge and expertise.
- Complex architecture:
- Need for extra tech experts
We need to have a team of experts with experience in the integration, design, and deployment of the Kafka project. Let us look at the reasons why we require tech support:- Implementation:
Organizations that are new to distributed system finds it tough to implement Kafka clusters. By using an expert team, we can achieve the throughput that even rabbit mq and AWS Kinesis can't achieve. - Integration:
Kafka can be challenging to integrate with the existing systems. - Code:
One may encounter several bugs while writing Kafka's code and configuring it during a complex project. Even in the deployment of Kafka, a team of experts is required to monitor it. - Performance:
Kafka's performance depends on its configuration and optimization. For best performance, we need a team of experts to configure and use it in the best way possible. - Security:
While streaming sensitive and important data, one may need to set up Kafka clusters such that the data is extremely secure.
- Implementation:
- No managing and monitoring tools
Apache Kafka does not have built-in User Interface (UI) for monitoring data. Although there are third-party applications that provide monitoring tools, the tools are not built-in in Kafka and this creates problems for developers. The team has to spend time for creating a new User Interface (UI) or use third-party software for monitoring the data. - ZooKeeper issue
Apache Zookeeper is a third-party instrument that is used to manage Kafka clusters. It is used to store metadata and information about brokers, topics, and partitions. The developer has to depend on this third-party tool i.e. Zookeeper for Kafka's work.
The following are the issues of Apache Zookeeper:- Zookeeper does not allow more than 200k partitions.
- Degrades Kafka's performance when a new broker joins the cluster or leaves the cluster.
- Kafka version 2.8.0 and higher has introduced a new version namely KRaft which works completely without Zookeeper.
- Do not support wildcard topic selection Kafka does not support wildcard topic selection for producing messages. One can't use wildcards like "\*", "?", "$" etc. in writing topic selection commands in Kafka. For producing messages, you must specify the exact topic using which we want to send messages. If we want to produce a message to multiple topics, we need to run the command multiple times. For example, if there are three topics namely topic_1, topic_2, and topic_3 and we want to produce a message to all of them, then we can't use topic_* to produce a message to all of them. Instead, we have to specify all three topics and run the command.
- Lack some message paradigms
While Kafka is powerful and integrable according to our choice, it lacks some of the features which other systems like AWS Kinesis, and rabbit MQ provides. Here are some of the paradigms that Kafka lacks:- Message priority:
Kafka does not provide a feature where messages are given priority and delivered accordingly to the consumer. All the messages are considered equal and processed in the order in which they arrive in Kafka. Although if there is a need to set up this feature where messages are given priority, we can do additional configuration by appropriate coding and set up this feature. But the trade-off is that our configuration may not perform as well as the distributed systems that provide this feature. - Exactly-once message delivery:
Kafka does not provide exactly-once message delivery. During a network failure, it may deliver a message more than once which may create a problem. However, Kafka delivers messages at least once. - Message expiration:
Kafka does not provide this feature where messages are automatically removed from the topic after a certain period. This may result in the accumulation of stale messages and higher storage costs. Although we can implement this feature by writing additional code, it may degrade the performance of Kafka.
- Message priority: