Scaling Your Kafka Cluster A Strategic Approach
Overview
Scaling a Kafka cluster is a critical aspect of managing a high-throughput, distributed messaging system designed to handle vast streams of data in real-time. As data volumes and user demands grow, the need for scalability becomes apparent to ensure seamless performance and reliability. Scaling a Kafka cluster involves both horizontal and vertical approaches. While scaling provides numerous benefits, managing a larger Kafka cluster requires careful consideration of factors such as data replication, network performance, and monitoring. Proper load balancing and partition management are crucial to maintaining low latency and ensuring even distribution of messages across brokers.
Introduction
Brief Overview of Apache Kafka
Apache Kafka, developed by the Apache Software Foundation, is a distributed streaming platform that operates as open-source software. Its primary purpose is to effectively manage and process large amounts of data streams in real time. Due to its ability to scale seamlessly and maintain resilience in the face of failures, Kafka has gained significant popularity as a preferred solution for constructing fault-tolerant data pipelines and event-driven applications.
Importance of Scalability in Apache Kafka
Scalability is of paramount importance in Apache Kafka for several critical reasons:
- Handling High Data Throughput:
Apache Kafka is designed to handle massive volumes of data in real-time. As data sources and message streams grow, the Kafka cluster must be able to scale to accommodate the increasing data throughput without compromising performance or introducing bottlenecks. - Managing Data Growth:
With the exponential growth of data in modern organizations, a scalable Kafka cluster ensures that the system can effectively manage and store the growing data streams. By adding more broker nodes or upgrading hardware, Kafka can continue to store and process large volumes of data without sacrificing data retention policies or data integrity. - Meeting User Demands:
As more applications and services depend on Kafka for real-time data streaming and event processing, the system needs to scale to meet the demands of these users. Scalability allows Kafka to serve multiple clients concurrently and efficiently, providing low latency and high availability for data consumers. - Ensuring Fault Tolerance:
Scalability enhances the fault tolerance of Apache Kafka. By distributing data across multiple broker nodes and replicas, Kafka can continue to function even in the presence of node failures. Scaling horizontally provides redundancy, mitigating the risk of data loss and ensuring high availability. - Enabling Elasticity:
Scalability enables the concept of elasticity, allowing the Kafka cluster to dynamically adapt to varying workloads. With auto-scaling mechanisms, the system can automatically adjust its resources based on demand, efficiently utilizing resources during peak times and reducing costs during low traffic periods.
Understanding Kafka and Scalability
What is Apache Kafka?
Apache Kafka is an open-source distributed streaming platform that provides a scalable, fault-tolerant, and high-throughput system for handling real-time data feeds. It was originally developed at LinkedIn and later became an Apache Software Foundation project.
At its core, Kafka is designed to handle the publish-subscribe model, where producers publish messages to specific topics, and consumers subscribe to those topics to receive the messages. It acts as a highly durable and fault-tolerant storage system, storing and replicating the published messages across a cluster of servers called brokers.
What Is Scalability in Distributed Systems?
Scalability in distributed systems refers to the system's ability to handle increasing workloads and growing demands by efficiently and effectively adding resources without significantly affecting performance. It is a critical characteristic of distributed systems, as it allows them to adapt to changing requirements, accommodate more users, process larger amounts of data, and support additional services seamlessly.
In a distributed system, various components (nodes) work together to achieve a common goal, sharing the processing load and communicating with each other over a network. Scalability addresses the challenges that arise when the system needs to grow to meet higher demands while maintaining performance, reliability, and fault tolerance. There are typically two main aspects of scalability in distributed systems:
- Horizontal Scalability:
Horizontal scalability, also known as scale-out, involves adding more nodes (computers, servers, or instances) to the system. As the workload increases, new nodes are added to distribute the load, allowing the system to handle a larger number of requests and process more data in parallel. Horizontal scalability is particularly beneficial when the system needs to accommodate a massive number of users or data streams. Distributed databases, load balancers, and message queues often rely on horizontal scaling.
- Vertical Scalability:
Vertical scalability, also known as scale-up, focuses on enhancing the resources (CPU, memory, storage) of individual nodes in the system. This approach involves upgrading existing hardware or increasing the capacity of the current resources to handle larger workloads. Vertical scaling is useful when a single component becomes a performance bottleneck, and it is not feasible or cost-effective to add more nodes. It is often employed for systems that require significant computational power for specific tasks.
Why is Scalability Important in Kafka Clusters?
Scalability is of utmost importance in Kafka clusters for several reasons:
- Handling High Data Throughput:
Kafka is designed to handle and process massive volumes of data in real-time. As data streams grow, a scalable Kafka cluster can efficiently accommodate increasing data throughput, ensuring smooth data ingestion and distribution. - Meeting Growing Demands:
As more applications and services depend on Kafka for real-time data streaming, a scalable cluster ensures that the system can handle the demands of a growing number of users and data consumers without compromising performance. - Enabling Fault Tolerance:
Scalability enhances the fault tolerance of Kafka. By distributing data across multiple broker nodes and replicas, Kafka can continue to function even in the presence of node failures. Scaling horizontally provides redundancy, ensuring high availability and reducing the risk of data loss. - Elasticity and Resource Utilization:
Scalability allows the Kafka cluster to dynamically adjust its resources based on demand. With auto-scaling mechanisms, the system can efficiently utilize resources during peak times and scale down during low traffic periods, optimizing resource usage and cost-effectiveness. - Supporting Big Data Architectures:
In big data architectures, Kafka serves as a critical component for ingesting and distributing data to various downstream data processing systems. A scalable Kafka cluster can handle the vast data flows from multiple sources and efficiently feed them to data processing frameworks.
Basics of Kafka Cluster
Kafka Brokers, Topics, and Partitions
In Apache Kafka, Brokers, Topics, and Partitions are fundamental components that collectively form the distributed messaging system. Let's understand each of them:
- Kafka Brokers:
Kafka Brokers are the core components of the Kafka cluster. They are individual servers responsible for handling the storage and exchange of messages within the system. Brokers receive messages from producers, store them for a configurable retention period, and serve them to consumers. Each Kafka broker is a part of the distributed architecture and communicates with other brokers to ensure fault tolerance and replication of data. The Kafka cluster typically consists of multiple brokers, and each broker can handle one or more partitions of Kafka topics. Horizontal scaling is achieved by adding more brokers to the cluster, distributing the data and processing load across them. - Kafka Topics:
Kafka Topics are logical categories or streams of messages. They act as message queues, where producers publish messages, and consumers subscribe to receive those messages. Topics are analogous to message channels or categories that allow data to be organized and partitioned based on a particular theme, application, or data source. For example, a financial application might have separate topics for stock market data, transaction logs, and customer interactions. Topics are designed to be durable, meaning they retain messages for a configurable retention period (even after consumers have processed them), allowing new consumers to consume past data. - Partitions:
Kafka Topics are divided into one or more Partitions. Each partition is an ordered, immutable sequence of messages, and it acts as a data shard within the topic. Partitions are the unit of parallelism in Kafka, enabling distributed storage and parallel processing of messages across multiple broker nodes. When a new message is produced to a topic, Kafka uses a partitioning strategy (usually based on the message key) to determine which partition the message should be assigned to. This helps ensure that related messages are stored together, preserving the order of messages within a partition.
Overview of Kafka Cluster Architecture
The Kafka cluster architecture is the foundation of Apache Kafka, a distributed streaming platform designed to handle real-time data streams efficiently. At its core, Kafka is built on a distributed and fault-tolerant architecture to provide high throughput, low latency, and scalability. Below is an overview of the key components and their interactions within a Kafka cluster:
- Brokers:
Kafka Brokers are the individual servers that form the core of the cluster. They are responsible for handling incoming messages from producers, storing those messages in partitions, and serving messages to consumers. Each broker is identified by a unique integer ID and can host one or more partitions of Kafka topics. A Kafka cluster typically comprises multiple brokers, and they work together to create a distributed and fault-tolerant system.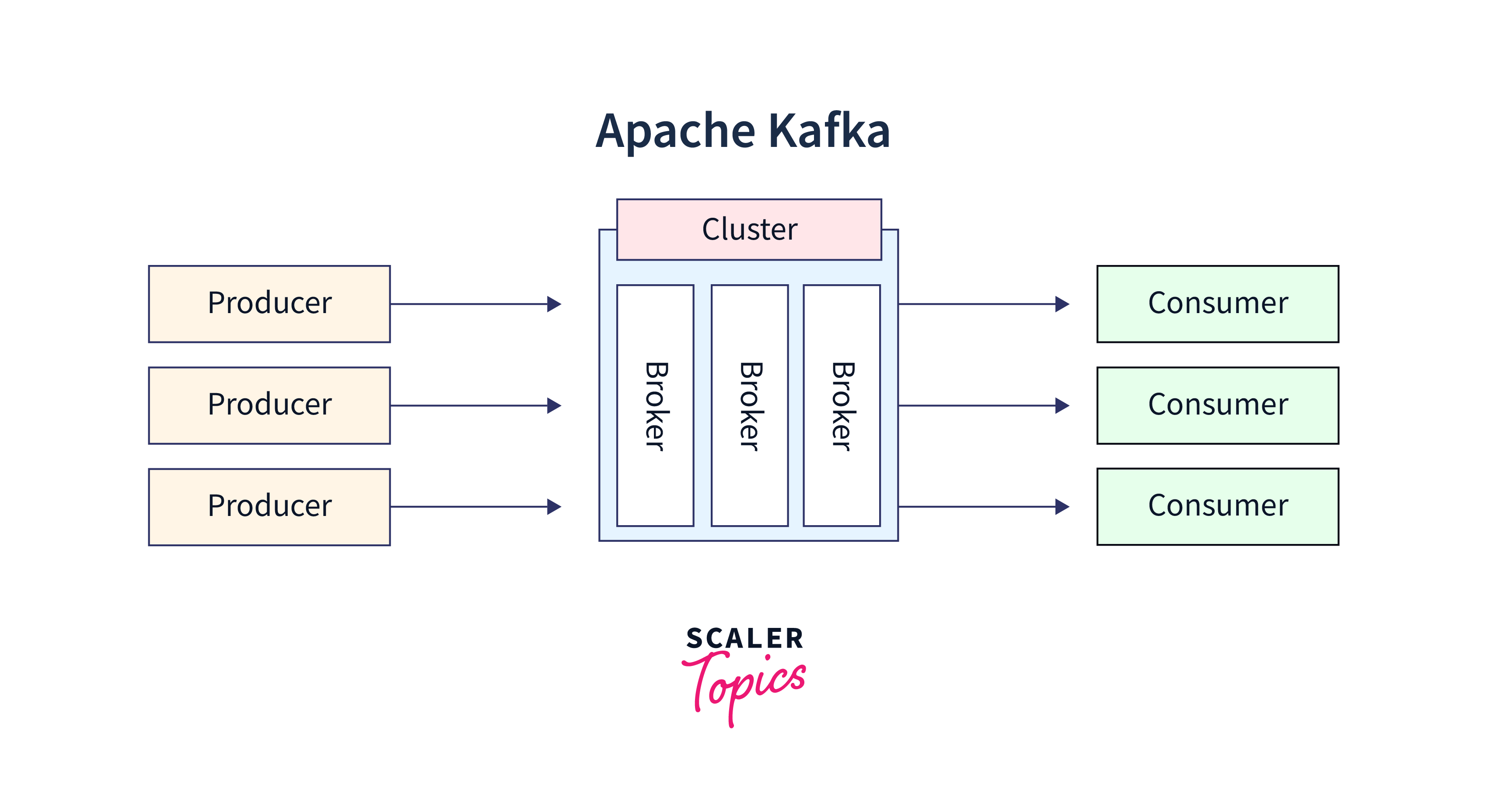
- Topics:
Kafka Topics represent logical categories or streams of messages. Producers publish messages to specific topics, and consumers subscribe to those topics to receive and process the messages. Topics are organized into partitions to enable parallel processing and scalability. Each topic can have multiple partitions, and the division of messages into partitions is managed by the brokers. - Partitions:
Partitions are the basic unit of data organization within Kafka topics. They are ordered and immutable sequences of messages that serve as data shards within a topic. The number of partitions for a topic directly affects the level of parallelism in data processing. More partitions allow for higher throughput and enable distributed processing across multiple brokers and consumer groups. - Producers:
Producers are applications or components that publish messages to Kafka topics. They send data to a specific topic, and the Kafka brokers handle the partitioning and distribution of the data. Producers can choose to specify a key for each message, which helps in determining the partition to which the message is assigned. - Consumers:
Consumers are applications or components that subscribe to Kafka topics and read messages from partitions. Consumer groups, which consist of one or more consumers, work together to parallelize data processing and ensure each message is processed only once. Each partition in a topic can have at most one consumer from a consumer group, providing load balancing and parallelism. - Consumer Groups:
Consumer Groups are logical sets of consumers that work together to read data from Kafka topics. Each consumer within a group is responsible for processing messages from one or more partitions. When a new consumer joins or leaves a group, the partitions are dynamically reassigned to maintain an even distribution of workload. - ZooKeeper:
ZooKeeper is a crucial component that manages the Kafka cluster's metadata, including broker availability, topic configuration, and consumer group coordination. Kafka relies on ZooKeeper to maintain the cluster's state and handle leader election for partitions.
Vertical vs. Horizontal Scaling in Kafka
| Aspect | Vertical Scaling | Horizontal Scaling |
|---|---|---|
| Definition | Increasing the resources (CPU, Memory, Storage) of a single node or server. | Adding more nodes (servers) to the Kafka cluster. |
| Purpose | To enhance the capacity of individual nodes to handle increased workloads. | To distribute the workload across multiple nodes for increased overall capacity. |
| Scalability Approach | Scale Up | Scale Out |
| Use Cases | Suitable for scenarios where a single node becomes a bottleneck and needs more resources. | Suitable for scenarios where the system requires higher throughput and handling of growing data volume. |
| Benefits | Improved performance and capacity without significant changes to the cluster architecture. | Better fault tolerance, higher throughput, and the ability to handle more data. |
| Limitations | Limited by the maximum capacity of a single node, and there is a practical limit to how much it can be scaled up. | Potential complexities in managing and synchronizing data across multiple nodes. |
| Cost Consideration | Can be more expensive as upgrading resources or purchasing high-end hardware can be costly. | More cost-effective, as it involves adding commodity hardware to the cluster. |
| Resource Utilization | Typically involves underutilized resources, as not all components may be fully utilized. | Provides better resource utilization as the workload can be distributed efficiently. |
| Elasticity | Less elastic, as it may require downtime or maintenance windows for hardware upgrades. | More elastic, as nodes can be added or removed dynamically to adapt to varying workloads. |
| Example | Upgrading CPU and RAM of a Kafka broker to handle increased data processing. | Adding more Kafka brokers to the cluster to handle additional data streams. |
Scaling Kafka Cluster Horizontally
Scaling a Kafka cluster horizontally involves adding more brokers to the cluster to distribute the workload and handle increased data throughput. The process typically includes repartitioning existing topics, adjusting topic configurations for new partitions, and closely monitoring and managing the cluster after scaling. Let's go through each step in more detail:
-
Adding more brokers to a Kafka cluster:
- Provision new servers or instances that meet the hardware requirements for Kafka brokers.
- Install Kafka software on the new machines and ensure they can communicate with the existing Kafka cluster and ZooKeeper ensemble.
- Update the configuration files of the new brokers to match the existing cluster's configuration.
- Start the new Kafka brokers, and they will automatically join the existing cluster as part of the new Kafka broker group.
-
Repartitioning existing topics:
- Before adding new brokers, determine the optimal number of partitions for each topic. More partitions allow for better parallelism and improved throughput.
- Use Kafka's partition reassignment tool to rebalance partitions across the new and existing brokers, ensuring an even distribution of partitions.
- The reassignment process should be performed carefully to avoid unnecessary data movement and maintain the order of messages within each partition.
-
Adjusting topic configurations for new partitions:
- After repartitioning, update the topic configurations to reflect the changes in the number of partitions.
- Review the replication factor setting to ensure that there are enough replicas to maintain data redundancy and fault tolerance.
-
Monitoring and managing the cluster after scaling:
- Regularly monitor the performance metrics of the Kafka cluster, such as throughput, latency, and resource utilization, using monitoring tools like Prometheus, Grafana, or other Kafka-specific monitoring solutions.
- Check the consumer lag to ensure that consumers are keeping up with the data flow and not falling behind.
- Monitor the disk usage on brokers to ensure that there is sufficient storage capacity for data retention.
- Keep an eye on the health of ZooKeeper ensemble as it is critical for Kafka's metadata management.
- If needed, adjust resource allocations for brokers based on the observed metrics to ensure optimal performance.
Scaling Kafka Cluster Vertically
Scaling a Kafka cluster vertically involves upgrading the existing hardware resources of the Kafka brokers to handle increased workloads and improve performance. The process includes adjusting Kafka configurations for better resource utilization and carefully monitoring and managing the cluster after scaling. Let's delve into each step in more detail:
-
Upgrading existing hardware:
- Identify the performance bottlenecks in the Kafka cluster, such as CPU, memory, or storage limitations.
- Plan the hardware upgrades based on the identified bottlenecks. For example, upgrading to higher CPU cores, increasing memory capacity, or using faster storage devices (e.g., SSDs).
- Schedule downtime or maintenance windows to perform the hardware upgrades on each Kafka broker.
- During the upgrade process, ensure proper backups and redundancy to minimize the risk of data loss.
-
Adjusting Kafka configurations for better resource utilization:
- After upgrading the hardware, review the Kafka configurations to optimize resource utilization.
- Tune the Kafka server properties such as num.io.threads, num.network.threads, and num.partitions to make efficient use of the upgraded CPU and network resources.
- Adjust the memory settings (heap size, page cache, etc.) based on the new hardware capacity to ensure optimal performance.
-
Monitoring and managing the cluster after scaling:
- Regularly monitor the performance metrics of the Kafka cluster to ensure that the hardware upgrades have resulted in improved throughput and reduced bottlenecks.
- Use monitoring tools to track CPU usage, memory consumption, and disk I/O of each Kafka broker.
- Observe Kafka's internal metrics (e.g., Kafka JMX metrics) to identify any anomalies or potential issues.
- Monitor the consumer lag to ensure that consumers are consuming messages at an acceptable rate and not falling behind.
- Continuously monitor the health of ZooKeeper ensemble, as it plays a critical role in Kafka's metadata management.
- Conduct load testing to assess the performance of the upgraded cluster under various workloads and stress conditions.
Conclusion
- Scalability is critical:
Scaling your Kafka cluster is essential to accommodate increasing data volumes, growing user demands, and maintain high performance in handling real-time data streams. - Horizontal scaling for capacity:
Adding more brokers to the Kafka cluster through horizontal scaling distributes the workload, improves fault tolerance, and increases the system's overall capacity. - Vertical scaling for performance:
Upgrading existing hardware resources of Kafka brokers through vertical scaling enhances individual node performance and allows for handling more significant workloads. - Balancing trade-offs:
Choosing between horizontal and vertical scaling depends on factors like hardware limitations, cost considerations, and future growth projections. - Proper planning is key:
Before scaling, careful planning, testing, and monitoring are crucial to ensure a smooth transition and minimize disruptions. - Repartitioning and configuration adjustments:
When scaling horizontally, repartitioning existing topics and adjusting topic configurations help optimize parallelism and resource utilization. - Monitoring for success:
Continuous monitoring of Kafka cluster metrics, consumer lag, ZooKeeper health, and load testing are vital to assess the effectiveness of scaling and make informed decisions for future improvements.