Setting up a Kafka Cluster
Overview
A Kafka cluster is a collection of interconnected Kafka brokers that operate together to address data streaming and processing loads. In kafka cluster setup, it requires installing Kafka on multiple nodes, configuring the cluster properties, and establishing inter-broker communication. In kafka cluster setup, also requires planning the hardware and infrastructure, determining the cluster size based on data volume and throughput requirements, and configuring replication and fault tolerance settings. Proper deployment, monitoring, and security measures should also be implemented to ensure the reliable and efficient functioning of the Kafka cluster.
Introduction
The architecture of a Kafka cluster provides fault tolerance, scalability, and high throughput for processing real-time data streams. It allows for distributed data storage, parallel processing, and seamless integration with various applications and systems.
Kafka clusters are designed to handle large-scale event streaming. They are widely used in scenarios requiring real-time data processing, such as log aggregation, messaging systems, and stream processing pipelines.
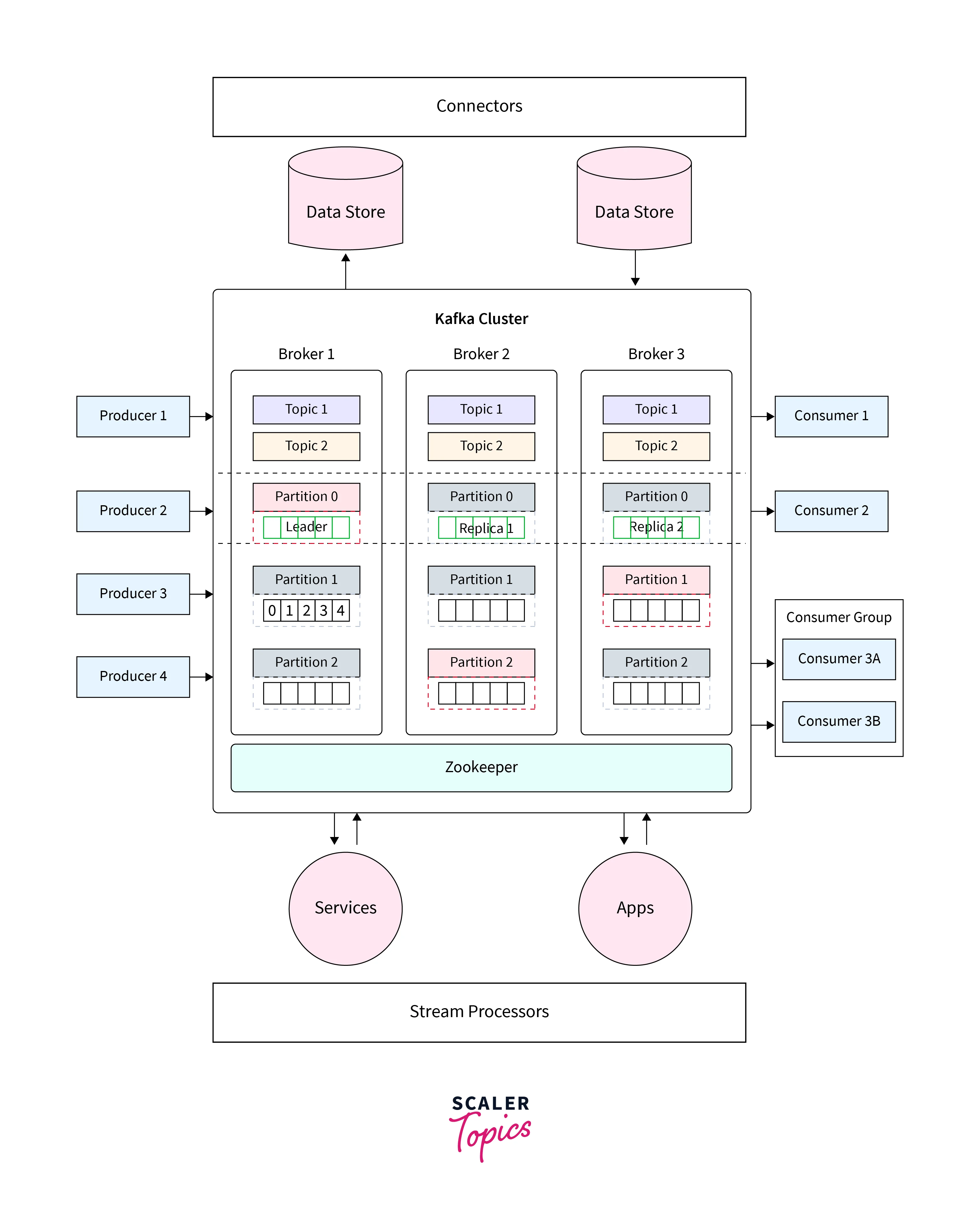
Most of the Kafka Cluster Architecture is made up of the following five components:
-
Kafka Brokers:
The essential elements of a Kafka cluster are Kafka brokers. They manage incoming communications, organize data into topics and respond to customer requests. -
Topics:
According to Kafka, topics are divisions or streams of messages. They serve as the means through which data is arranged and divided. To facilitate parallel processing and scalability, topics are separated into segments. The messages included in each partition are given a distinct offset, and each partition is sorted and immutable. -
Zookeeper:
It serves as a Master Management Node for the Kafka Clusters, overseeing and maintaining the Brokers, Topics, and Partitions. The Brokers of the Kafka Clusters are tracked by the Zookeeper. It calculates the lifespan of each Broker, as well as which Brokers have recently been added to the Kafka Clusters and which Brokers went down. -
Producers:
Producers are in charge of posting data or occurrences related to Kafka topics. They send messages to certain topics, and Kafka handles spreading those messages throughout the topic's partitions. -
Consumers:
Consumers receive messages from one or more partitions and subscribe to one or several topics. Consumers keep track of their offset to see how many messages they have consumed from a partition. To facilitate simultaneous consumption and load balancing, they might be a part of a consumer group.
Users can utilize Apache Kafka, a preferred distributed streaming technology, to manage massive event streaming and data processing by setting up a Kafka cluster.
The first step in establishing a Kafka cluster setup is to install Kafka in your desired environment. Kafka may be installed on a variety of operating systems, including Linux, macOS, and Windows. It is necessary to ensure that the necessary prerequisites and dependencies are installed.
Organizations can effectively manage large real-time data streams by setting up a Kafka cluster.
Features of Kafka Cluster
-
Scalability:
Kafka clusters are designed to extend horizontally by adding more brokers as message flow increases. This enables you to handle high-volume data streams and meet expanding data demands. -
Fault Tolerance:
Kafka enables fault tolerance by replicating data. Each subject can have many partitions, with replicas dispersed across brokers for each partition. If a broker fails, the copies assure data availability and avoid data loss. -
Durability:
Kafka stores messages on disk, ensuring durability even when brokers fail. This ensures that messages are not lost and that they may be recovered even if the system restarts or fails. -
Kafka is designed to manage high message throughput and low-latency data processing. It is capable of handling millions of messages per second and provides effective data compression algorithms to optimize network and storage utilization.
-
Real-time stream processing:
Kafka clusters offer real-time stream processing, allowing applications to process and respond to data as it comes. This is accomplished using Kafka Streams, a lightweight stream processing module included in the Kafka environment. -
Distributed Architecture:
Kafka clusters are distributed systems that share the load over several brokers. This enables parallel processing and effective resource utilization, resulting in excellent performance and scalability.
Steps to Setup Kafka Cluster
There are various phases involved in setting up a Kafka cluster to construct a distributed streaming platform. The following are involved in the Kafka cluster setup:
1. Install Kafka:
-
Download the most recent stable version of Kafka from the Apache Kafka website (https://kafka.apache.org/downloads).
-
Select the appropriate compressed file for your operating system from the binary distribution.
-
Using the proper extraction application, extract the downloaded file to a location of your preference.
-
Use the following command to extract a tar.gz file, for instance, if you downloaded it onto a Unix-like system:
The Kafka version number should be used in place of the version in the above syntax.
- The following environment variables should be set up to make it easier to utilize Kafka commands:
- KAFKA_HOME:
Put the location of Kafka's extraction in this variable. - PATH:
Add the binary directory for Kafka to the system's PATH setting.
- KAFKA_HOME:
To verify the Installation, Run the following command in a new terminal to make sure Kafka is properly installed:
2. Start the Kafka Environment
In kafka cluster setup, follow these steps to launch the Kafka environment and create a Kafka cluster:
For Kafka coordination, ZooKeeper is a necessary component. Use the terminal to run the following command to launch ZooKeeper:
Using the zookeeper.properties configuration file as a starting point, this command runs ZooKeeper.
Set up Kafka Brokers:
For each Kafka broker that intends to launch, open a new terminal. Run the following command to launch a Kafka broker in each terminal:
Using the server.properties configuration file as a starting point, this application launches a Kafka broker.
Verify the Kafka Cluster:
Check the status of the Kafka brokers and topics to make sure the Kafka cluster is functioning properly. Run the following command in an entirely new terminal to see a list of active Kafka brokers:
The Kafka cluster functions properly if the command runs successfully and provides a list of topics.
3. Create a Topic
To handle topics in a Kafka cluster setup, use the command-line utility kafka-topics.sh. To execute the following command, open a new terminal and type:
- create: Indicates your want to create a topic.
- Define the name of the topic you wish to create with the subject test_topic option.
- bootstrap-server localhost:9092: The list of Kafka brokers and their addresses are specified by the --bootstrap-server option at localhost:9092.
- replication-factor 3: Defines the topic's replication factor. Change it based on the number of Kafka brokers in your cluster and the desired level of fault tolerance.
- partitions 3: Specify how many partitions there are for this topic. It should be adjusted based on your needs, taking parallelism and throughput into account.
4. Produce Events
Create a Kafka producer instance in your preferred programming language (such as Python, Java, or Scala) to communicate with the Kafka cluster.
The send() function of the producer is used to create events. In the following example, we use ProducerRecord objects to deliver three events to the given topic; the topic and the event value are the first and second parameters, respectively.
An example using the command-line interface will include kafka-console-producer.sh:
- Define the name of the topic you wish to create with the topic test_topic option.
- bootstrap-server localhost:9092: The list of Kafka brokers and their addresses are specified by the --bootstrap-server option at localhost:9092.
The events are currently accessible in the chosen topic and are available for Kafka consumers to consume.
5. Consume Events
Create a Kafka consumer example in your preferred programming language (such as Python, Java, or Scala) to connect with the Kafka cluster.
Using the subscribe() method of the consumer, we subscribe to the topic to consume events. Using Collections.singletonList(subject), we subscribe to a single topic in our example.
We then employ the poll() method of the consumer to poll continually for fresh records. A ConsumerRecords object containing the records collected from Kafka is the result of the poll() method. We go through the records again, processing each one as necessary. In this illustration, we only report the value of each event that was received.
An example using the command-line interface will include kafka-console-consumer.sh:
- Define the name of the topic you wish to create with the subject test_topic option.
- bootstrap-server localhost:9092:
The list of Kafka brokers and their addresses are specified by the --bootstrap-server option at localhost:9092. - from-beginning:
Indicates that the reader should begin reading events at the topic's beginning. If you want to consume all events in the subject, even those created before the consumer started, use this flag.
You may customize consumer behavior based on your needs by configuring multiple consumer configuration parameters.
6. Import/Export Data with Kafka Connect
-
Configure Kafka Connect:
Change the connections and their configurations in the Kafka Connect configuration file (connect-distributed.properties or connect-standalone.properties). -
connect-distributed.properties:
When executing Kafka Connect in distributed mode, this configuration file is utilized. Kafka Connect spreads work over numerous worker nodes in the distributed mode for scalability and fault tolerance. -
connect-standalone.properties:
When executing Kafka Connect in solo mode, this configuration file is utilized. Kafka Connect works on a single worker node in standalone mode and does not spread work across many nodes. This mode is appropriate for testing or small-scale deployments.
When launching Kafka Connect, you must specify the location of the configuration file. To start Kafka Connect in distributed mode, for example, use the connect-distributed.properties file and run:
7. Process Events with Kafka Streams
Create a Kafka Streams application example in your choice of programming language (e.g., Java) to process events. Install the required components and set up your application. Execute the desired processing logic, such as data transformation, aggregation, filtering, and so on.
Here is an example as follows given below:
In this example, we will build a basic Kafka Streams application that takes data from an input topic, converts the values to uppercase, and outputs the processed stream to the console.
To execute this application, ensure that the necessary Kafka dependencies are included in your build file (e.g., Maven or Gradle). Change the bootstrap servers and topic name in the code to fit your Kafka cluster configuration. The code which has been created may then be built and executed using your favorite IDE or command line tools.
8. Terminate the Kafka Environment
Press Ctrl+C in the terminal where the Kafka broker is operating to terminate it.
Stop ZooKeeper using the following command:
Conclusion
- Finally, establishing a Kafka cluster gives businesses a strong and expandable framework for managing real-time data streams.
- One can create powerful and efficient data processing pipelines by following the essential procedures, such as installing Kafka, establishing the cluster, creating topics, producing and consuming events, and using extra capabilities like Kafka Connect and Kafka Streams.
- Kafka clusters provide scalability, fault tolerance, high throughput, durability, and real-time stream processing, enabling horizontal scaling to meet growing message volumes.
- Monitoring and management solutions enable organizations to keep track of the health and performance of the Kafka cluster, assuring optimal operation and recognizing any problems.
- Kafka clusters also include characteristics such as distributed architecture, communication and interaction with external systems, security methods, and monitoring capabilities.