Streaming Data with Kafka
Overview
Apache Kafka is a distributed streaming technology that allows for real-time data processing and analysis. It includes features such as log aggregation, event streaming, and data integration. Kafka Streams is a streaming data client library that allows developers to construct real-time applications on top of Kafka. Kafka offers elasticity, fault tolerance, and scalability, as well as integration with common languages and exactly-once processing. Data is streamed into Kafka topics by producers, while data is read and processed by consumers. Kafka's streaming features make it an effective platform for managing real-time data.
Introduction
Apache Kafka is an open-source distributed streaming platform for real-time data processing and analysis. It supports log aggregation, event streaming, and data integration. Kafka Streams, a client library, offers high-level APIs for processing streaming data. Configuring Kafka Streams is crucial for optimizing performance, fault tolerance, and scalability.
Brief Overview of Apache Kafka and Kafka Streams
Apache Kafka is a distributed streaming platform that is available as open-source software. It enables the creation of real-time streaming applications that handle and analyze data as it is received. Kafka is widely used across various scenarios, including:
- Log aggregation:
Kafka serves as a central platform for collecting and storing logs from diverse sources. These logs can then undergo analysis to identify patterns, troubleshoot issues, and enhance overall performance. - Event streaming:
Kafka enables real-time event streaming, enabling real-time applications to respond to events. - Data integration:
Kafka enables the integration of data from different sources. The integrated data can subsequently be processed and analyzed to gain valuable insights into business operations.
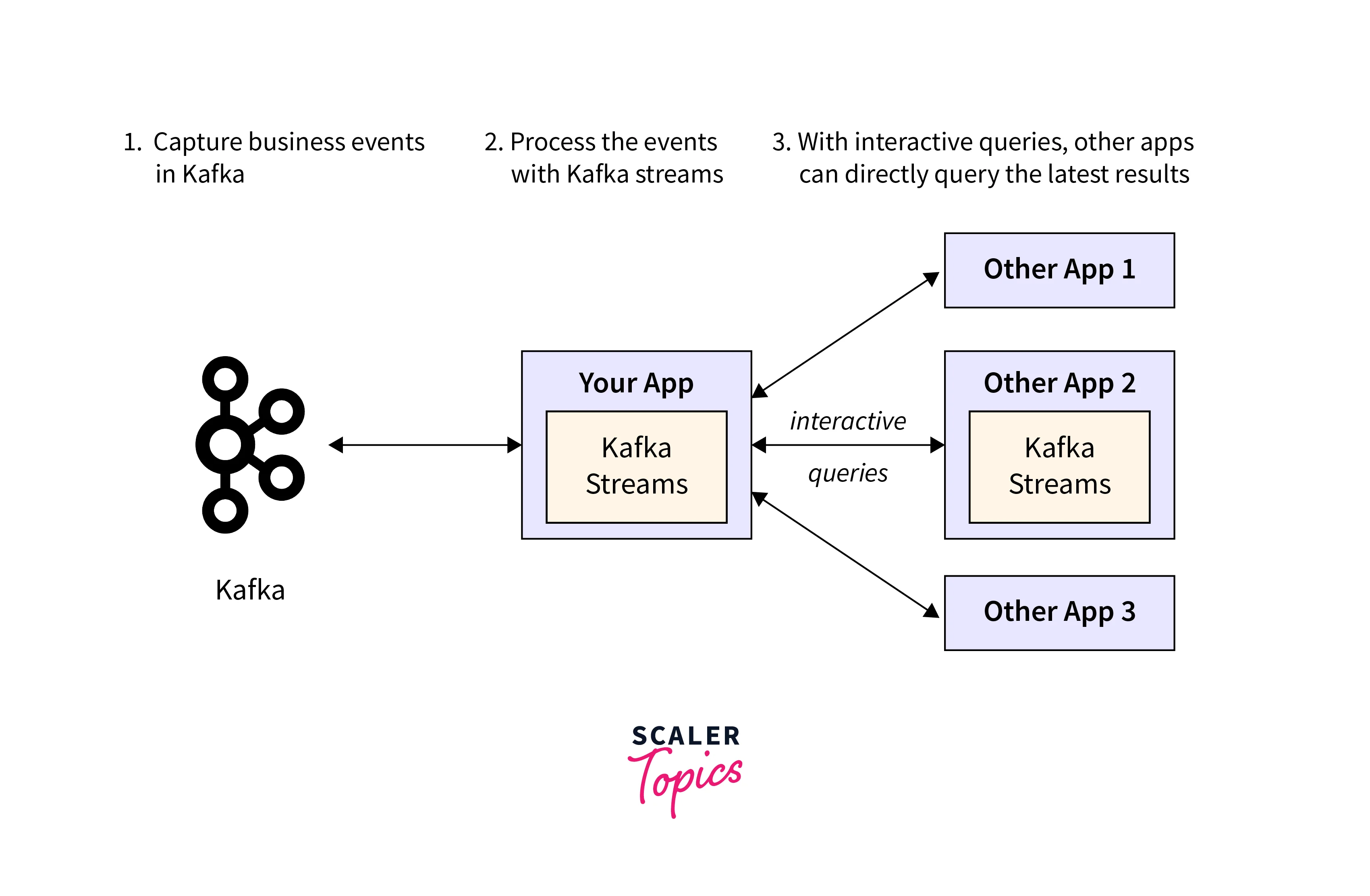
Kafka Streams is a client library for building applications and microservices on top of Apache Kafka. It provides a high-level API for processing streaming data. Kafka Streams can be used to perform a variety of operations on streaming data, including:
- Filtering:
Kafka Streams can be used to filter streaming data based on certain criteria. - Aggregation:
Kafka Streams can be used to aggregate streaming data, such as counting the number of events or calculating the average value. - Joining:
Kafka Streams can be used to join streaming data from different sources. - Windowing:
Kafka Streams can be used to window streaming data, such as grouping events by time or by user.
Importance of Configuration in Kafka Streams
The setting of Kafka Streams is critical since it influences the application's performance, scalability, and dependability. Some of the most critical configuration settings are as follows:
- Replication factor :
The replication factor specifies how many copies of each Kafka Streams topic are saved. A greater replication factor increases fault tolerance but consumes more storage capacity. - Partitions:
Kafka cluster data distribution depends on partitions in Kafka Streams topic, affecting speed and application complexity. - The retention period specifies how long Kafka Streams topics are stored. A longer retention time allows for the storing of more historical data, but it also raises storage needs.
- Consumer lag is the delay between the most recent record in a Kafka Streams topic and the most recent record consumed by the application. A significant consumer latency may suggest that the application is struggling to keep up with the incoming data.
Before utilising the Streams API, several fundamental setup settings must be configured. Create a streams.properties file with the following content for this example. Make concerned to update the bootstrap.servers list to reflect the IP addresses of your own Kafka cluster.
Understanding Kafka Streams
What is Kafka Streams?
Apache Kafka Streams is a free and open-source client library for building applications and microservices. It stores both input and output data in Kafka clusters. Kafka Streams provides a seamless integration that allows developers to effectively process and analyse data in real-time by combining the flexibility of designing and deploying normal Scala and Java apps with the power of Kafka's server-side cluster technology.
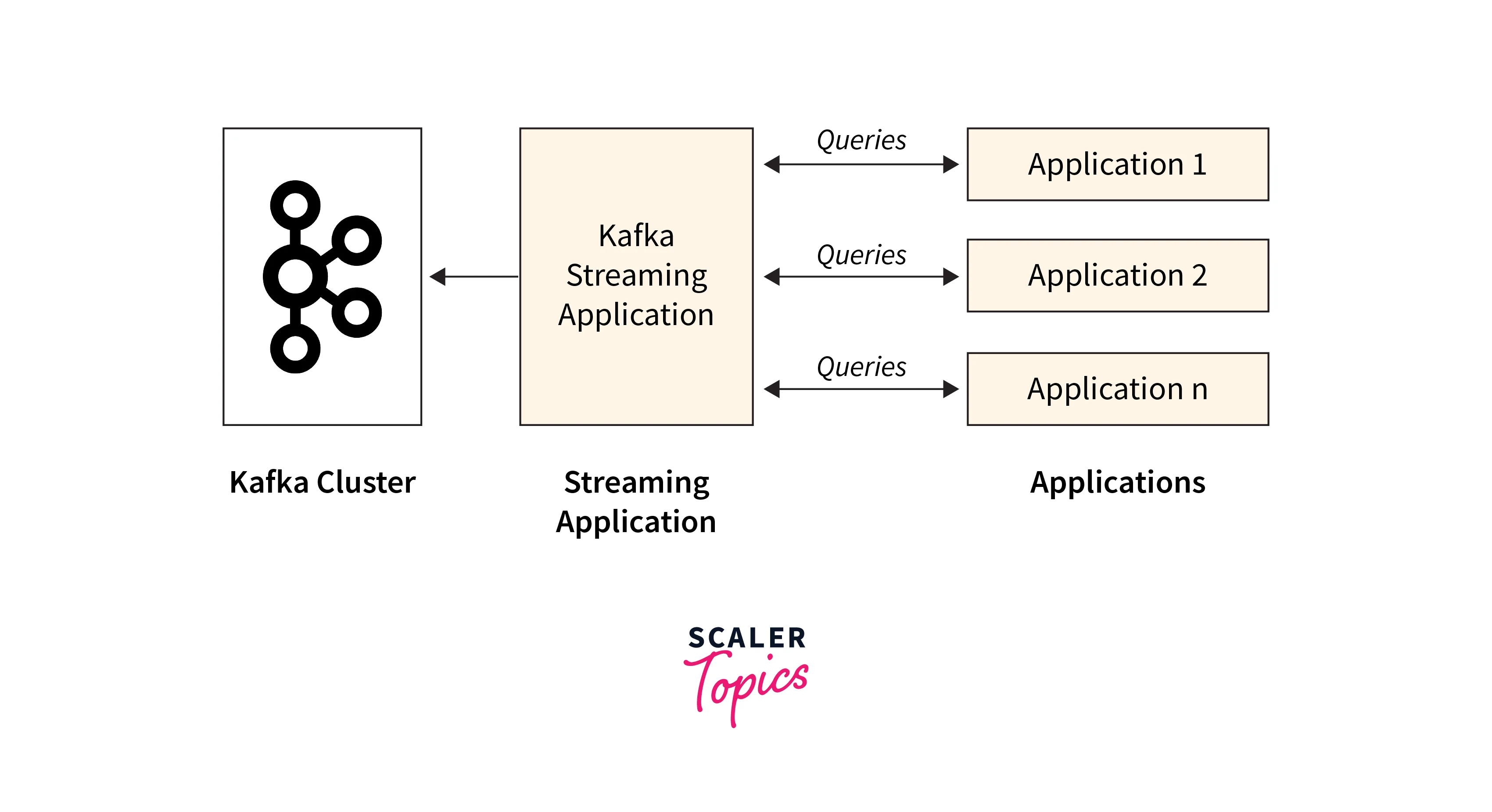
Key Features and Advantages of Kafka Streams

- Elastic :
Kafka is an open-source project aiming for high availability and horizontal scalability, resulting in an elastic streams API and easy extension. - Fault-tolerant :
Kafka partitions data logs, sharing them among cluster servers for fault tolerance and replicating each partition across multiple servers. - Highly feasible :
Kafka clusters offer versatile use cases, supporting small, medium, and large-scale use cases due to their availability. - Integrated Security :
Kafka has three primary security components that provide best-in-class data security in its clusters.They are listed in the following order:- Data encryption using SSL/TLS
- Authentication of SSL/SASL
- Authorization of ACLs
- Java and Scala support :
Kafka Streams API integrates with popular programming languages like Java and Scala, simplifying server-side application creation and deployment. - Semantics of exactly-once processing :
Kafka stream processing executes infinite successions of data or events, with Exactly-Once ensuring user-defined statements are executed once and state changes committed in long-term back-end store.
Advantages of Kafka Streams:
- Real-time Processing:
Allows for the real-time processing and analysis of streaming data. - Integrates easily with Apache Kafka, utilising its powerful cluster technologies.
- Scalability:
Allows for horizontal scalability to accommodate growing data loads. - Fault Tolerance:
Provides built-in fault tolerance and high availability methods. - Stateful Processing:
Provides support for stateful activities by quickly preserving and updating state information. - Stream-Table Join:
Allows real-time linking of streaming and static data. - Developer-Friendly:
Provides a high-level API for creating streaming apps and microservices.
Kafka Producers: Streaming Data into Kafka
Understanding Kafka Producers
Kafka Producers are Apache Kafka components responsible for publishing data to Kafka topics, ensuring data is written to the appropriate partition and broker, without user specification.
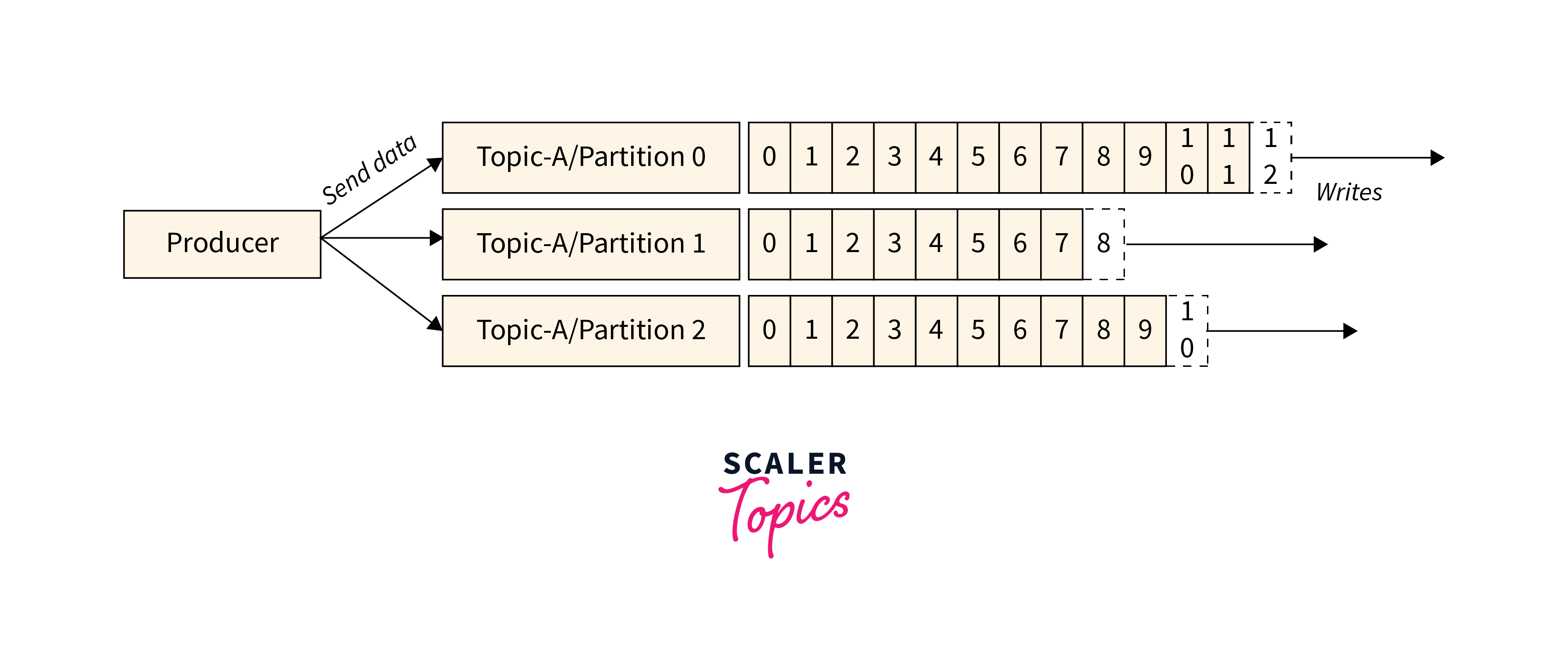
There are two methods which helps the producer use to write data to the cluster
Message Keys:
- The use of a key in Kafka allows for precise message ordering.
- Producers have two options for transmitting data based on the key: sending to all partitions automatically or sending exclusively to a selected partition.
- By applying message keys, producers can send data to specific partitions consistently.
- If a key is not used by the producer when writing data, it will be sent in a round-robin fashion, known as load balancing.
Acknowledgment:
The producer has an additional option for acknowledgment when writing data to the Kafka cluster. It implies that the producer may authenticate its data writes by obtaining the following acknowledgments:
- acks=0:
Producer sends data without acknowledgment, potentially causing data loss or broker downtime, potentially causing disruption. - acks=1:
Producer awaits leader's confirmation, checks with broker, and provides feedback, minimizing data loss. - acks=all:
Leader and followers acknowledge each other, ensuring data is received without loss of information.
How to Create and Configure a Kafka Producer
Apache Kafka provides a number of Kafka Properties that may be utilised to build a producer. To learn more about each attribute, go to the Apache website. Navigate to Kafka>Documents>Configurations>Producer Configurations.
There, users may learn about all of the producer attributes provided by Apache Kafka. Here, we will go through the necessary attributes, such as:
- bootstrap.servers:
This is a list of port pairs that are used to connect to the Kafka cluster for the first time. Users can only utilize the bootstrap servers to establish an initial connection. This server can be found in the form host:port, host:port,... - key.serializer:
It is a kind of Serializer class that implements the org.apache.kafka.common.serialization.Serializer interface. - value.serializer :
It is a Serializer class that implements the interface org.apache.kafka.common.serialization.Serializer.
The code creates a Kafka Producer connecting to localhost:9092 brokers. It serializes key and value objects using the StringSerializer class, stores them in the ProducerRecord object, and submits it to Kafka using the send() function.
Writing Data to Kafka with a Producer
- The example demonstrates the creation of a KafkaProducer instance with specified attributes like bootstrap servers, key and value serializers.
- A ProducerRecord is constructed with the desired topic and message.
- The record is sent to Kafka using the send() function of the producer.
- The outcome of the send operation, whether it is successful or a failure, is handled in the callback provided as the second parameter.
Kafka Consumers: Reading Data from Kafka
Understanding Kafka Consumers
- Kafka Consumers can read data from a subject and recognise the topic by its name.
- Consumers understand which broker to use and which partitions to consume data from.
- Consumers have the capacity to recover in the case of a broker failure, offering fault tolerance.
- Data is read progressively inside each partition to maintain the sequence of messages within a partition.
- For example, if a Consumer consumes from Topic-A/Partition-0, it will read messages from 0 to 11 in sequential sequence.
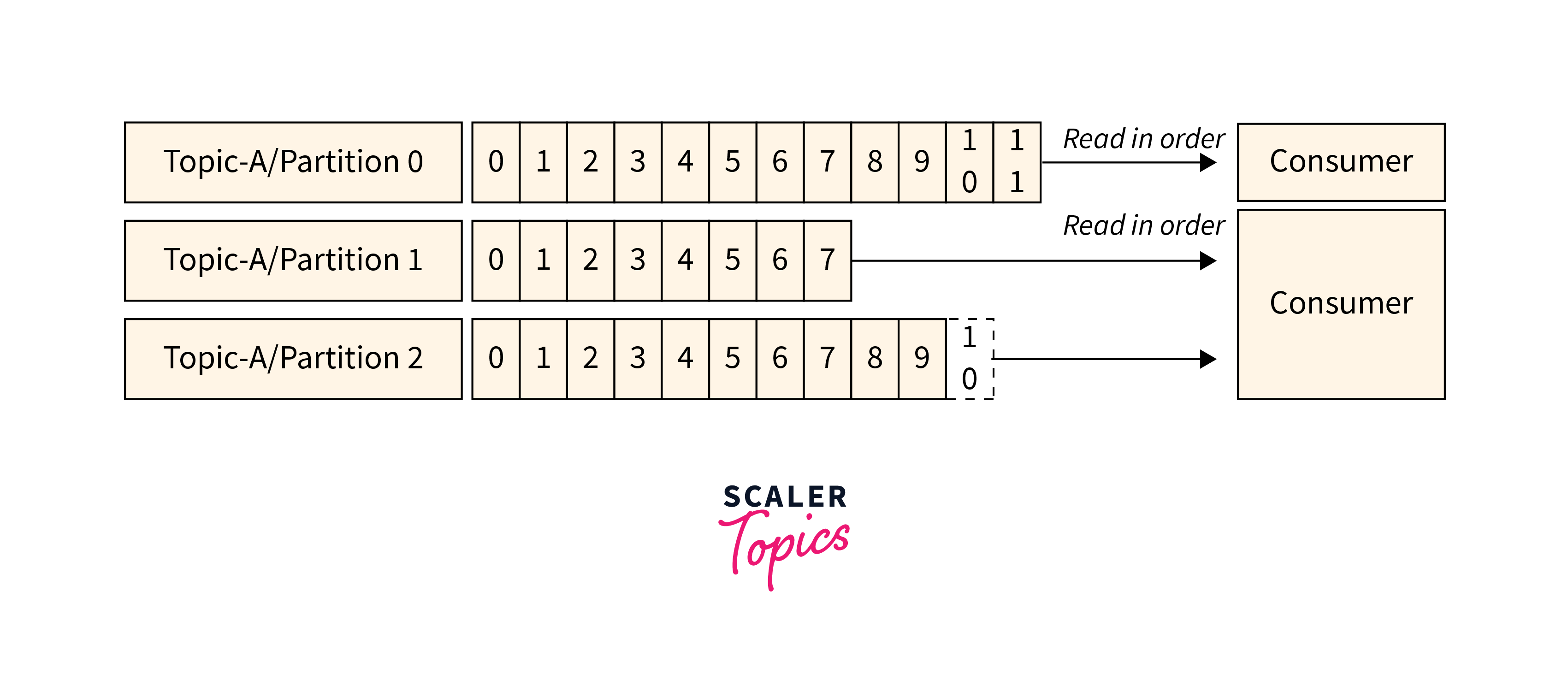
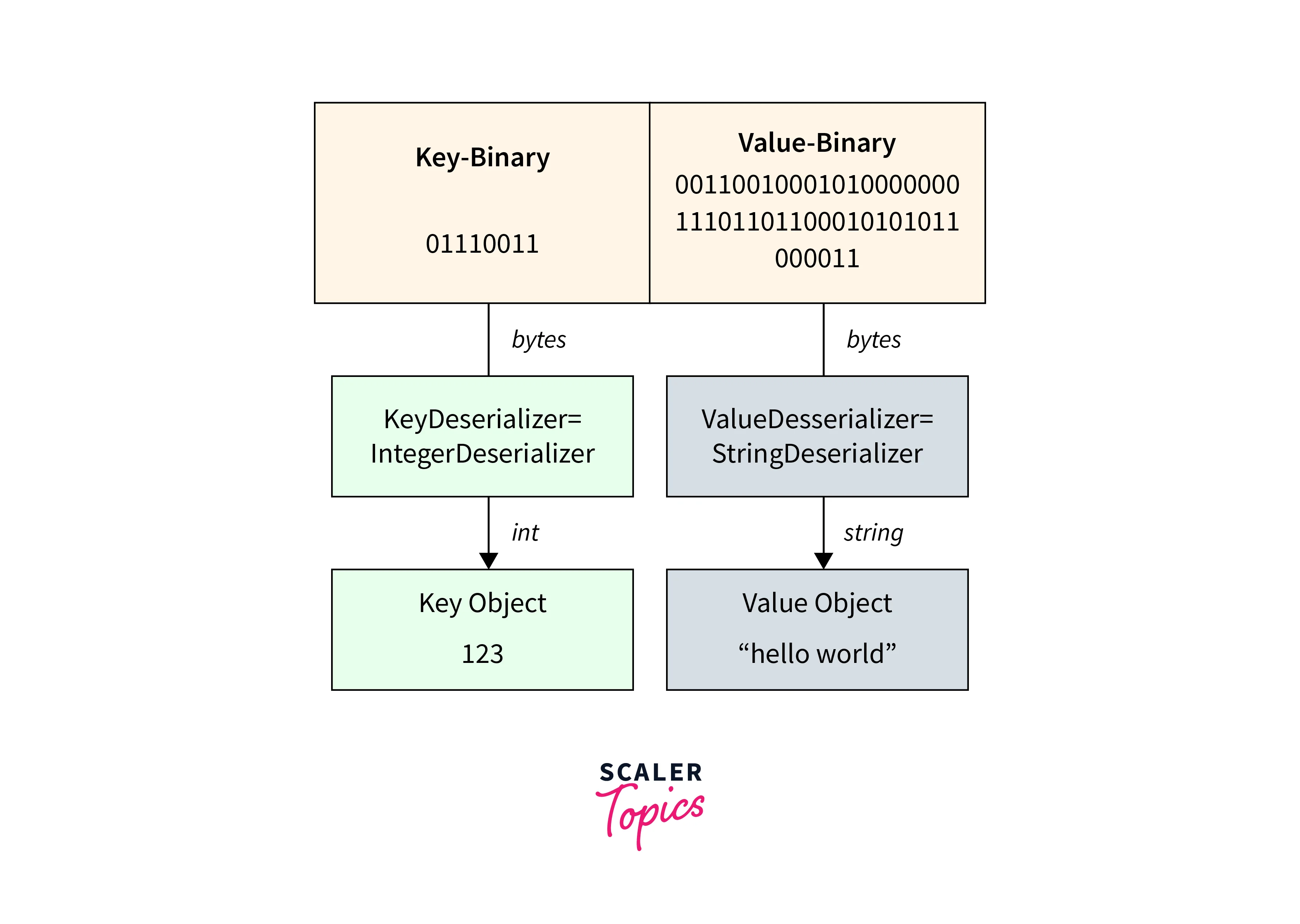
- Kafka consumers read Kafka messages, which are represented as bytes.
- A Deserializer is necessary to convert these bytes back into objects or data.
- Deserializers are applied to the message's key and value.
- A KeyDeserializer of type IntegerDeserializer, for example, can convert the binary key field to an integer, yielding the value 123.
- Similarly, a StringDeserializer may convert the binary value field to a string, allowing the consumer to read the object's value as "hello world".
How to Create and Configure a Kafka Consumer?
- bootstrap.servers:
A list of Kafka broker addresses in the format <host>:<port> is specified. This option is used to connect to the Kafka cluster for the first time. - group.id:
Kafka uses group IDs to track consumer progress within a group, ensuring consumers belong to the same group. - key.deserializer and value.deserializer:
Specifies the deserializer classes for the key and value of the consumed messages. These classes are in charge of converting the binary data received from Kafka into Java objects. - auto.offset.reset :
Determines what to do when there is no committed offset for a consumer group or the existing offset is invalid. It can be set to one of the following values:- earliest:
Begin consuming from the most recent available offset. - latest:
Begin consuming from the most recent offset (the default). - none :
If no offset is discovered, throw an exception.
- earliest:
- max.poll.records:
Limits the amount of records returned by poll() in a single call. The batch size of records fetched from Kafka is controlled by this option.
Reading Data from Kafka with a Consumer
- The example demonstrates the usage of Apache Kafka Java client library to read data from Kafka with a Consumer.
- The bootstrapServers variable is set to the Kafka broker's address, and the desired topic is specified for consumption.
- Kafka consumer properties are configured using the Properties class, including bootstrap servers, group ID, and deserializer classes for key and value.
- A KafkaConsumer instance is created by passing the properties, and subscription to the topic is done using the subscribe method.
- Within the while loop, the poll method is used to fetch batches of records within a specified duration.
- Each received ConsumerRecord is processed as needed, with retrieval of key, value, offset, and partition information.
- This example showcases the basic steps involved in setting up and using a Kafka Consumer to read data from Kafka.
Real-Time Data Processing with Kafka Streams
Kafka Streams real-time data processing allows for the processing of streaming data as it arrives. Here are some major features concerning Kafka Streams real-time data processing:
- Kafka Streams Library:
Kafka Streams is a client library for building real-time streaming applications on top of Apache Kafka. It offers a simple API for handling and analyzing data streams. - Stream-Table Duality:
A sophisticated stream-table duality concept is provided by Kafka Streams. It respects streams (continuous data flows) and tables (immutable data snapshots) as first-class citizens, allowing smooth interaction between them. - Event-Driven Processing:
Kafka Streams enable event-driven processing, in which applications may react in real-time to events as they occur. This enables the creation of applications for real-time analytics, monitoring, and alerting. - Windowing and Time-Based Operations:
Kafka Streams offers windowing and time-based operations, enabling developers to aggregate data based on time frames and event timestamps for computations. - Fault Tolerance and Scalability:
Kafka Streams utilizes Apache Kafka's fault-tolerance and scalability features for automatic fault management and high availability.
Let's start with a fundamental knowledge of how real data flows in it.
Data Extraction into Kafka is the first stage in gathering data for the application.
- Kafka provides connectors in the Kafka Connect architecture for transferring data from multiple sources into Kafka.
- Connectors serve as a data hub, enabling seamless data flow between Kafka and other data storage platforms.
- Kafka allows consuming databases, enabling streaming applications to access data with low latency.
- JDBC connections can be utilized as source connectors to extract data from SQL Lite sources.
- With JDBC connection, records are processed individually, creating a data stream in Kafka.
Data transformation using the Kafka Streams API:
- Kafka enables multiple applications to read data from topics published by a source.
- Data read from Kafka topics is not initially enhanced or modified.
- Kafka Streams provides real-time stream APIs for transforming and aggregating data.
- Individual communications can be modified by changing their content or structure.
- Filters can selectively process communications based on specific circumstances or criteria.
- Advanced data processing like join operations, aggregations, and windowing can be performed on records.
- Enhanced data can be returned to Kafka topics for consumption by other sources or applications.
The Flow of Data Downstream:
-
The last step in the data processing pipeline is downstream or sinking the data.
-
Multiple target sinks can be used, and Kafka Connect with multiple connectors is employed to handle this.
-
Kafka Connect allows data to be sent to various systems, enabling flexibility in choosing the destination for the data.
-
For instance, an Amazon S3 bucket can be utilized as a sink for the data.
-
By connecting the output topic with the sink connector and running it using Kafka Connect, the data can be delivered to the desired destination in the required form.
Conclusion
Summary of The Key Points
- Apache Kafka is an open-source distributed streaming platform used for real-time streaming applications, log aggregation, event streaming, and data integration.
- Kafka Streams is a client library that enables the development of real-time streaming applications and microservices on top of Kafka.
- Kafka Streams offers a high-level API for processing streaming data, including filtering, aggregating, joining, and windowing, making it versatile and developer-friendly for a wide range of use cases.
The Power and Potential of Streaming Data with Kafka

Separation of Data Producers and Consumers: Kafka allows data producers to send data without considering consumers' needs, while customers can subscribe to relevant topics and consume data at their leisure.
Exactly-Once Data Processing: Kafka uses exactly-once data processing, ensuring each message is processed precisely, eliminating duplicate or missing data concerns.
Capture of Change Data:
Connectors in Kafka Connect collect data changes from a variety of sources, including databases, message queues, and file systems. These connections continually monitor the data sources and capture any changes in real time. Once the changes have been collected, they are converted into Kafka messages that may be ingested and processed by downstream systems.
Data Integration and Ecosystem: Kafka is a central data integration platform for seamless data integration from various sources, supporting connectors and enabling organizations to build comprehensive data pipelines and architectures.
With high throughput and a low latency: Kafka data pipelines handle thousands of messages per second with minimal latency, making it ideal for real-time applications like reporting and monitoring systems.
Persistence & Durability : Kafka stores data fault-tolerantly, ensuring no loss during transit or processing, and enables replay of data streams for recovery, debugging, and reprocessing.
Encouragement to Further Explore and Implement Kafka Data Streaming
-
Energy Production and Distribution via Smart Grid:
- The high-throughput, fault-tolerant, and scalable Kafka platform serves as a primary nervous system for smart grid management.
- Kafka integrates real-time data in smart grid settings for load adjustment, pricing, and peak leveling.
- Smart grids become more efficient using Kafka data pipelines, enabling real-time decision-making and enhanced analytics.
-
Healthcare:
- Kafka is critical in real-time data processing and automation throughout the healthcare value chain.
- Kafka's decoupled, scalable infrastructure improves functionality and seamless integration across systems and data formats.
- Kafka enhances productivity, reduces risks, and finds applications in pharmaceuticals, healthcare, and insurance.
-
Detection of Fraud:
-
Kafka is critical in current anti-fraud management systems, allowing for real-time data processing to detect and respond to fraudulent acts.
-
Kafka's data pipeline features, including Streams and machine learning, enable real-time analysis of data to detect fraud anomalies..
-
Companies that have used Kafka for fraud detection include PayPal, ING Bank, Kakao Games, and Capital One.
-