The Kafka Data Pipeline and Data Flow
Overview
In this article, we shall understand about the Kafka data pipeline and data flow. Starting with data pipeline and the Lambda architecture that talks about both (real-time and batch data processing) including Kafka architecture and step by step guide how one can build a streaming Kafka Data Pipeline. We also throw light on the benefits offered by Kafka and the best practices one must follow in the Kafka data pipeline and data flow.
What is a Data Pipeline?
Before we jump onto understanding the details of the Kafka data pipeline and data flow, let us start with a basic understanding of what is meant by a Kafka data pipeline.
A data pipeline can be defined as the flow where at one end, a user starts to ingest the raw data that could have been gathered from one or more sources. Once the data is ingested, it travels via the data processing part, including masking, filtering, aggregations, etc. This stage occurs between the data ingestion and standardization is being performed. Once the data is transformed, cleansed, and standardized as per user requirement, the data is ported to a data store, such as a data warehouse, data mart, or data lake. It is this data which is utilized for analysis by the business.
Below is the Kafka data pipeline and data flow to highlight how data is processed from source to target:
When we have to understand this flow from a Kafka perspective, the transformed data is ingested into the Kafka log commit partitioned model via the producers. The data stays in the Kafka log commit until its expiration. And the consumers need to subscribe to the data for fetching the data records.
What is its purpose?
The purpose of having a data pipeline set, ensure that the data collected is put into some tangible use case. It is used to facilitate the efficient and reliable flow of data from various sources to its destination, typically a data storage or processing system. A data pipeline consists of a series of steps and processes that transform and transport data from its point of origin to where it is needed for analysis, reporting, or other applications.
The consolidated data enables easier and quick data analysis for generating business insights. This maintains consistency and ensures data quality, which is absolutely critical for reliable and effective business insights.
Lambda Architecture (Real-Time and Batch)
In this section, we will be learning about Lambda Architecture, which can be quickly defined as an amalgamation of both the real-time and batch processing of the data.
Lambda Architecture is considered a design pattern that offers the processing of huge amounts of data in a scalable, robust, and fault-tolerant manner. One can see a striking balance in this architectural approach. It offers a balance between both real-time and batch processing that eventually helps for reliable and accurate data insights. This is usually offered from batch processing as well as stream processing, offering low latency insights.
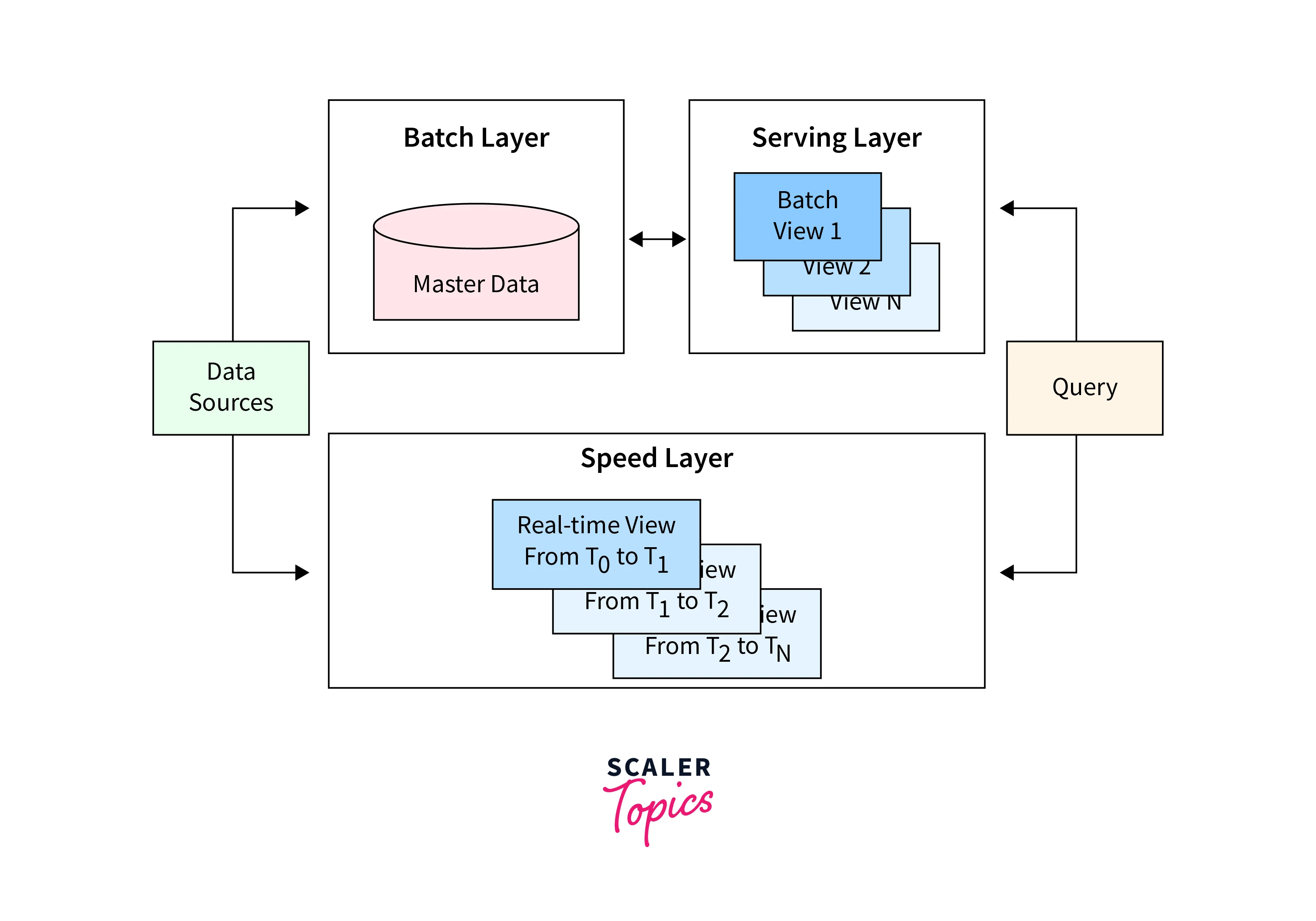
The Lambda Architecture consists of three main components:
Batch Layer: In the batch layer, the data records are batch-processed, including the functionalities of storing large volumes of data processing in batches. For a defined period of time, data is collected that could be set in order of hours, days, months, or years. All the collected data is processed to generate valuable insights. For batch processing, the quantity of data utilized for every batch depends on what kind of analysis we are looking to derive.
Speed Layer: Widely popular as the Stream Layer, the speed layer is mostly utilized for performing real-time analysis of the data. With the latency seen in data aggregation, the data present in this layer is not yet processed via the batch layer. The speed layer offers low latency insights, which sometimes might not even be as accurate or complete as provided by the batch layer. The stream layer utilizes the batch layer output as the reference data for deriving certain insights.
Serving Layer: The serving layer acts as an interface for the user to query the output for batch and speed layers. Users usually utilize the results of the batch layer that is indexed, while the results from the stream layer are utilized for offering real-time views of the system.
Below is the Lambda Architecture (Real-Time and Batch) in the Kafka data pipeline and data flow:
What is Batch and Stream Ingestion?
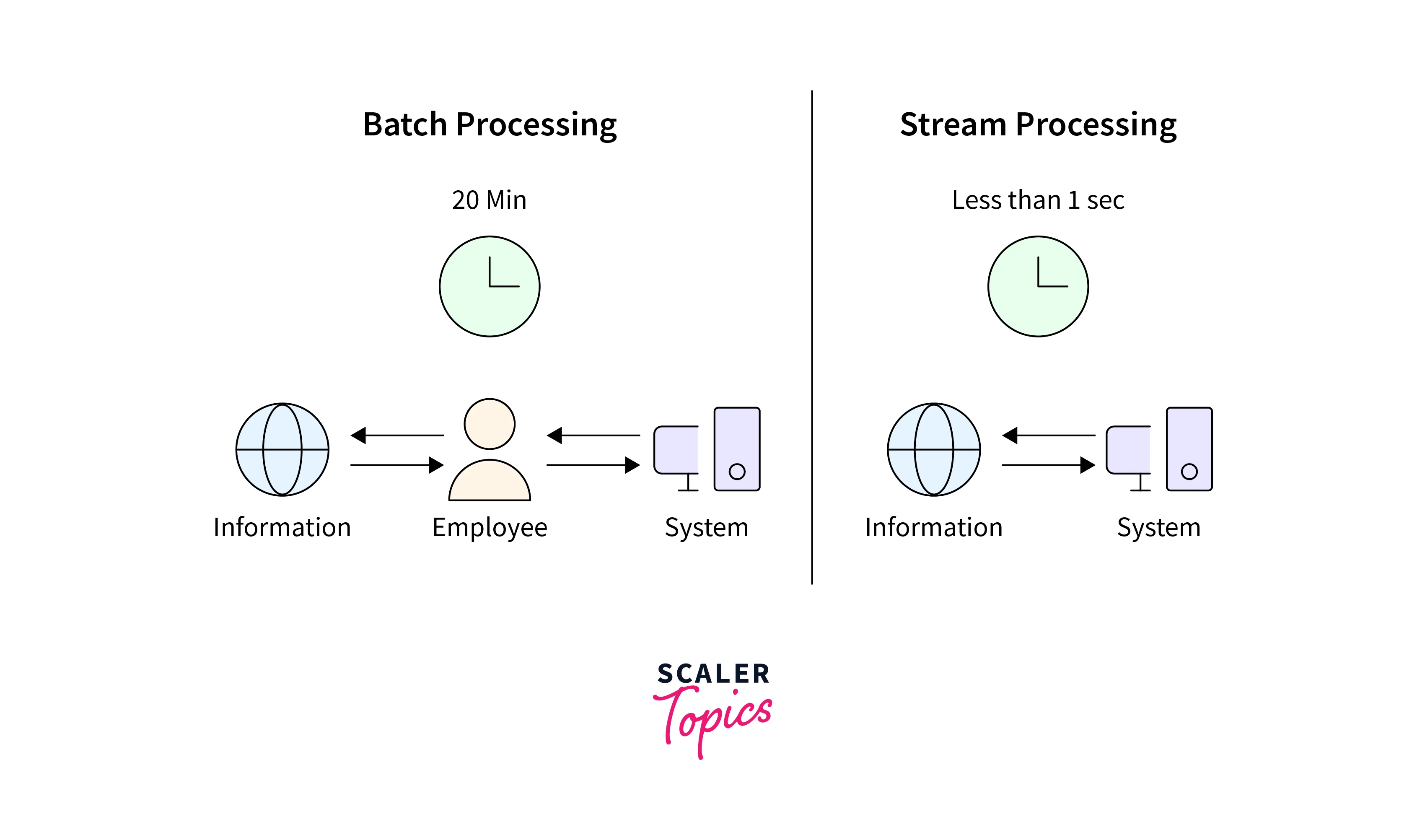
In this section of the article, we shall be discussing batch and stream ingestion.
We can define batch ingestion as the processing of data that has been acquired for the time period. At the same time, we define stream ingestion as the process where real-time data is being processed piece by piece.
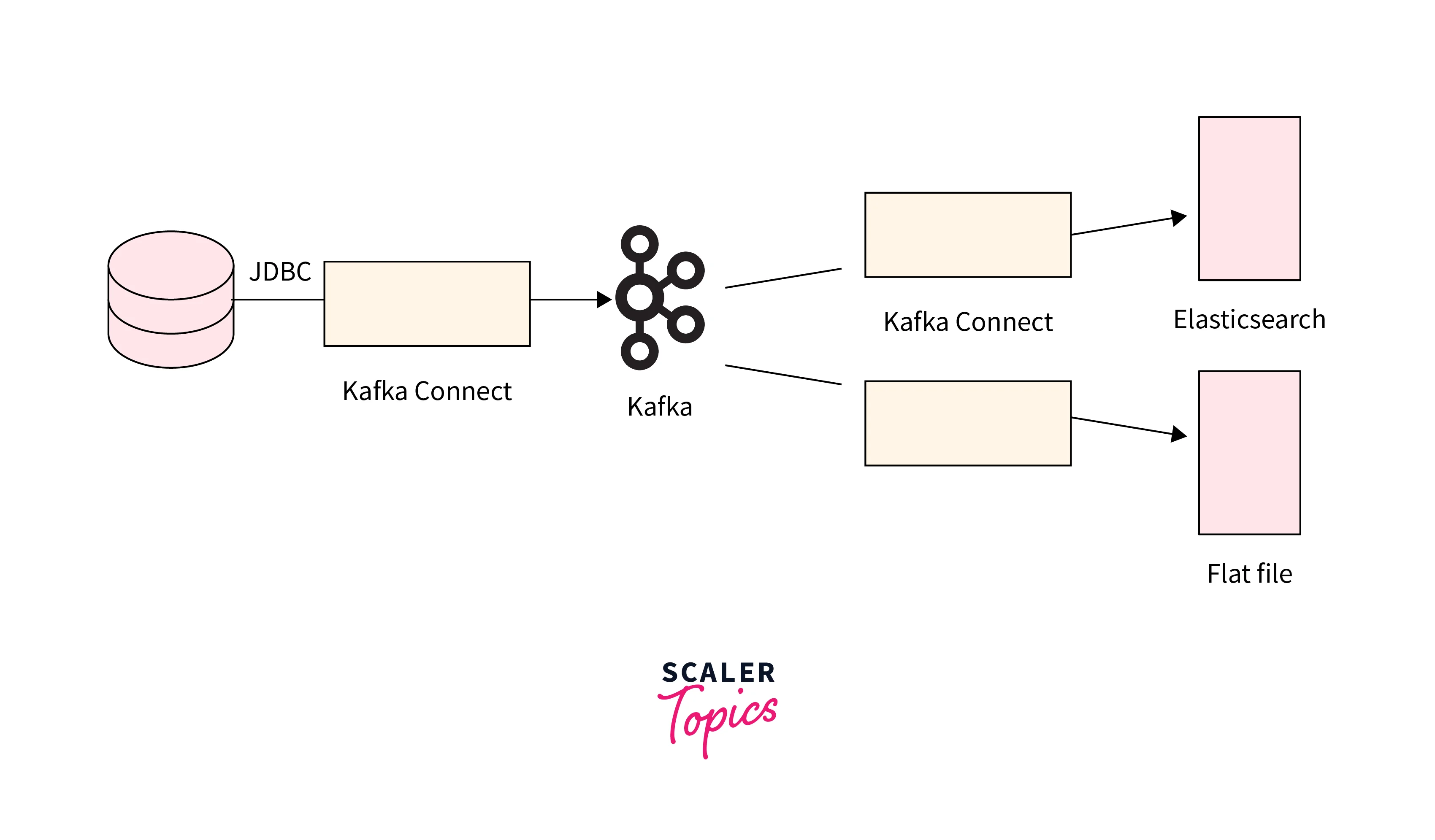
Below is the depiction of Batch and Stream Ingestion in the Kafka data pipeline and data flow:
Several components together make up the data pipeline. For instance, an Operational Data Store is a place where the batch data gets staged after the data processing has been completed. Stream data, that is, processed in real-time, is staged in a Message hub via Kafka.
Architecture of Kafka and how it facilitates data streaming and how Kafka enables data to flow between different data architecture components?
Now, in this section we shall be briefly discussing the Kafka's architecture. At the same time, Kafka utilizes the amalgamation of both the point-in-point and publish-subscribe messaging systems to publish the data records/messages across various topics and partitions. Every Topic is comprised of a partitioned as well as structured log commit model, which offers to keep a track of the data records as the new record is always appended at the end of this log in real-time, providing zero data loss feature. Fault tolerance, high scalability, as well as parallelism are effectively offered by the replicated partitions and distributed across various systems/servers.
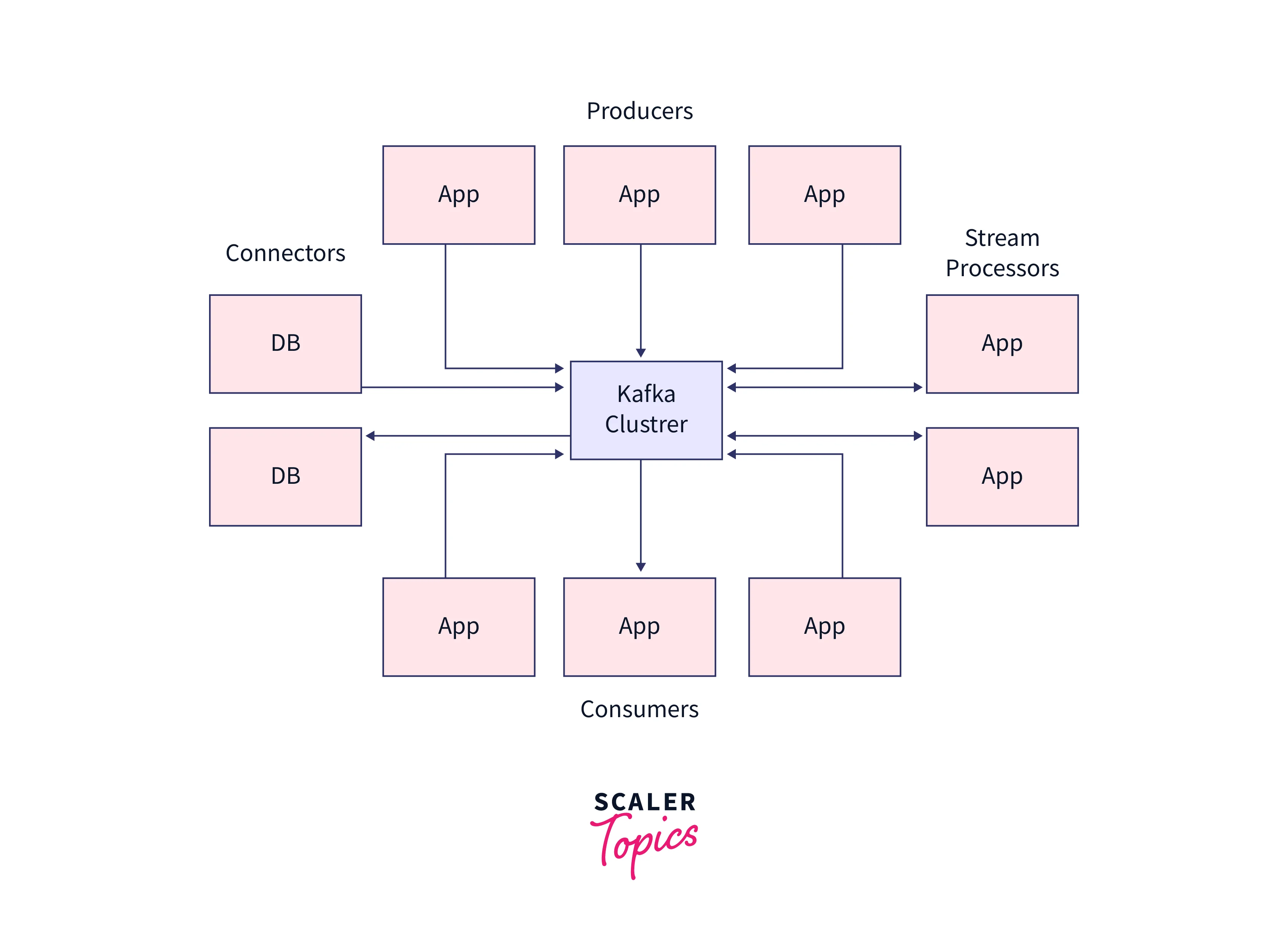
Every Consumer who wants to acess the data from the Kafka log has to be assigned a partition that allows the various consumers at the same time to access the data while the order of the data records or message are simultaneously maintained in the log. The data records are seamlessly written as well as replicated in the entire disk, making the Kafka a highly scalable and fault-tolerant storage system.
Four important APIs which is widely used in Kafka's architecture are described below:
Producer API: For publishing a stream of data records to a Kafka topic, Kafka uses the producer API. Consumer API: For subscribing to Kafka's topics and processing their streams of data records, Kafka uses the consumer API. Streams API: With the Streams API, Kafka authorizes the systems to work as stream processors. Here, the input stream is taken up from the Topic, which is then transformed into the output stream, transferring the data records across various output topics. Connector API: With the Connector API, any external system or application can be easily integrated with the Kafa architecture. The stems can be automated with the data system to any of their current Kafka topics.
Components of a typical Kafka data pipeline
A Kafka data pipeline consists of the following companies that enable efficient data transfer from source to destination. The key components that make up the Kafa data pipeline are:
- Producer
- Consumer
- Kafka Broker ( Consisting of Kafka Topic, Partitions and Offsets )
- ZooKeeper
While the Producer shall be pushing the message into the Kafka cluster, it is the Kafka broker that helps to transfer the message from the Producer to the Consumer. The Zookeeper works as the centralized controller, which manages the entire metadata information for the Kafka producers, brokers, and consumers. Finally, the message reaches the end of the Kafka cluster, where it can be easily read by the consumers. Hence, Kafka Broker, Consumer, Producer, and Zookeeper are the core components of the Kafka cluster architecture.
Below is the detailed illustration of Kafka data pipeline:
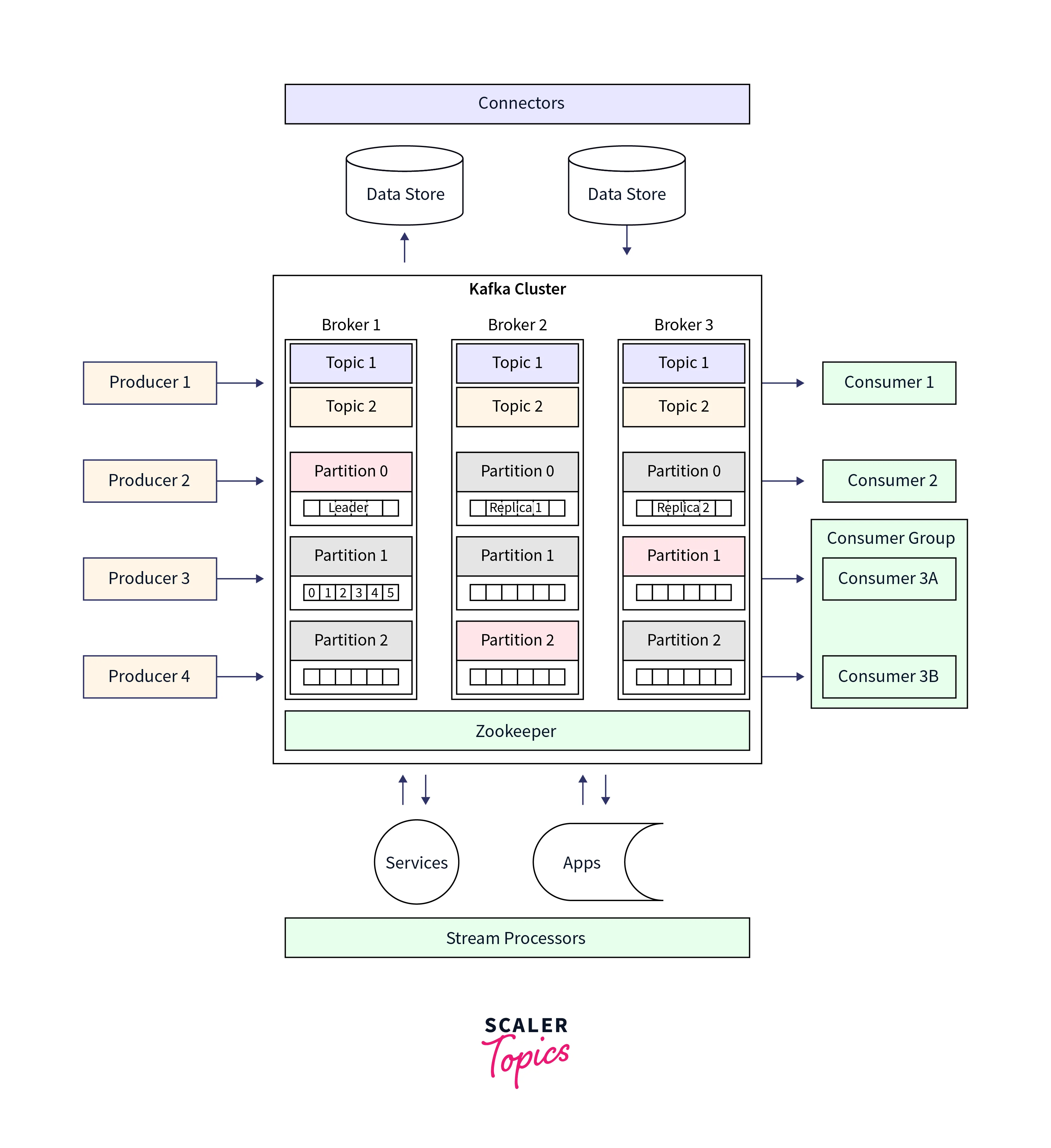
Kafka Topics, Kafka Partitions, and Kafka Offsets play a crucial role in Kafka architecture. Everything related to Kafka, be it scalability, durability, message movement, or high performance, is contributed by these three components of Kafka. In Apache Kafka, all the messages written in the partitioned log commit model reside inside the Topic, which can be further divided into partitions. In the partitions, each of the messages will have a specific ID attached to it called the Offsets.
We have discussed all the above-mentioned key components in detail in What is Kafka, Kafka Topics, Kafka Partitions, and Kafka Offsets, and Brokers, Producers, Consumers, and Zookeeper links. It's highly recommended to go through each and learn the basics of each of these components to understand the Kafka data pipeline and data flow definitely.
Steps to Build a Streaming Kafka Data Pipeline
Let us deep dive into the Kafka data pipeline and data flow, where we learn how one can easily and quickly build a Streaming Kafka Data Pipeline with the steps discussed below:
Setting Up the Environment
- For setting up the environment, one can use either a paid version or any open source system to get access to the managed Kafka services, stream processing, and connectors for streaming Kafka Data Pipeline.
- Start by setting up an account, where you can start creating a new cluster for Kafka Data Pipeline. You can start by naming the cluster, where you can also start with the Basic cluster type too.
- Once the cluster is successfully created, you must navigate your way to the Kafka Topics page and check if the "Create Topic" page is activated.
- Verify if your Schema Registry is for your Kafka Data Pipeline; if not, you can start by creating the Schema Registry too.
- One needs to select the required cloud platform as well as the region for setting the Schema Registry.
- For the application, navigate to the ksqlDB page where you can select the option like "Create application myself" and let all the details be as it is.
- Execute the below command in your MySQL CLI over your Amazon RDS-managed MySQL instance for creating the table and having the data in it.
Integrate Kafka with External Systems
For creating the streaming Kafka Data Pipeline integrations with other technologies like Data Warehouses, Document stores, Message Queues, Databases, etc., you can implement it with Kafka Connect. Confluent Cloud provides fully managed connectors that you only need to configure. If you have a UI option for your open-source system, use it to configure Kafka Connect. If not, then you can implement it via the Kafka Connect REST API to the JSON configuration.
Creating a Data Generator
- For Creating a Data Generator, start by navigating to the topics page, where you can add a topic to your streaming Kafka Data Pipeline.
- You can give any name of your choice to this Topic, along with assigning the number of partitions to it.
- Then, add this Topic to the Kafka Data Pipeline, which would enable the Data Generator connector for Kafka Connect.
- Then, navigate to the "Connector" page, where you can search for "datagen" and select the "Datagen Source" connector for streaming the Kafka Data Pipeline.
- You must also generate the Kafka API key & secret key where you can move ahead with giving a description and copy these credentials for safety and future purpose.
- The JSON that you might see would be something similar to what is shown below.
- You can then Launch to start the connector, where you can validate that the new connector is coming under the "Running "status.
- Then, from the "Topics" page, you could select your topic name and easily stream new messages through Kafka Data Pipeline.
Loading Data from MySQL into Kafka with Kafka Connect
- In this section, we shall be loading data from MySQL into Kafka with Kafka Connect. Start by connecting the MySQL Database and validate if the data is showing or not by running the query:
- User can create a topic that it wants to ingest via the MySQL connector for streaming Kafka Data Pipeline.
- You need to create the Topic and assign a name to it, and set the number of partitions.
- You can add the Connectors and search for "MySQL CDC Source," from where you can easily be able to add the connector for Kafka Data Pipeline.
- Once a successful connection is established, the JSON summary of the configuration is seen below.
- You can simply launch and select the Topic you want to explore from the list of Topics. One can also set the value of the offset to 0.
Filtering Streams of Data with ksqlDB
- Now, the message you shall be receiving is from the first channel device. You can also create a new stream for Kafka Data Pipeline having only live devices data via the ksqlDB.
- Validate if you have the ksqlDB application and check if its status is "Up" on the klsqlDB page.
- You can execute the below query to validate if the declaration of the ksqlDB stream has happened on the Topic containing the rating message.
- With the help of the below command, one can verify if the messages are successfully running through the Kafka Data pipeline:
- If you want to remove the fields containing the "test" word in the "CHANNEL" column, run the below given SQL query.
- One important point to note, users must set the "auto.offset.reset" parameter to the "earliest" for the ksqlDB to successfully process all the previous records as well as new records in the Topic.
- It's known that a ksqlDB stream is backed up via the Kafka topic, and one can simply start writing the data records matching the pattern or criteria into a new ksqlDB stream via the SQL query shown below:
- Now, you shall be able to see a new Kafka topic created having a prefix as "{topic-name}_LIVE ".
Joining Data Streams with ksqlDB
- In this section, we shall be learning how we can join data streams with the KsqlDB. Execute the below command:
- Create a ksqlDB table on the data, eventually build it over the Kafka stream that shall return value for a specific key. Execute the below:
- User can make use of the primary or foreign key for enriching the events with information about the data table.
- With the below command, one can join the table of data with the details stream of {topic-name}.
- You can re-validate the query for the newly created Kafka stream by executing the below command:
Streaming Data from Kafka to Elasticsearch with Kafka Connect
- In this step, we shall be streaming the data from Kafka to Elasticsearch with Kafka Connect. You can add the connector by navigating where your Connector show; there, you can easily find the "Elasticsearch Service Sink" connector.
- Configure the "Elasticsearch Service Sink" connector, and validate the connection of Kafka Data Pipeline with Elasticsearch, where you shall see the JSON output as shown below:
- Now, you can Launch the pipeline and validate if the status of the connector is shown as "Running. "You can also validate whether the data is properly streaming in Elasticsearch or not.
Hurray! This completes the process of successfully building a Streaming Kafka Data Pipeline.
Benefits of using Kafka for data flow
We understand in detail what it is Kafka; with this section of the article, we shall be learning about the benefits Kafka offers to its users.
With Apache Kafka, we can utilize its message broker system to create continuous data streams (in real time, too) by incrementally and sequentially processing the massive amount of data. This data inflow is real-time data that is simultaneously gathered from various data sources offering the below benefits to its users for their data integration process.
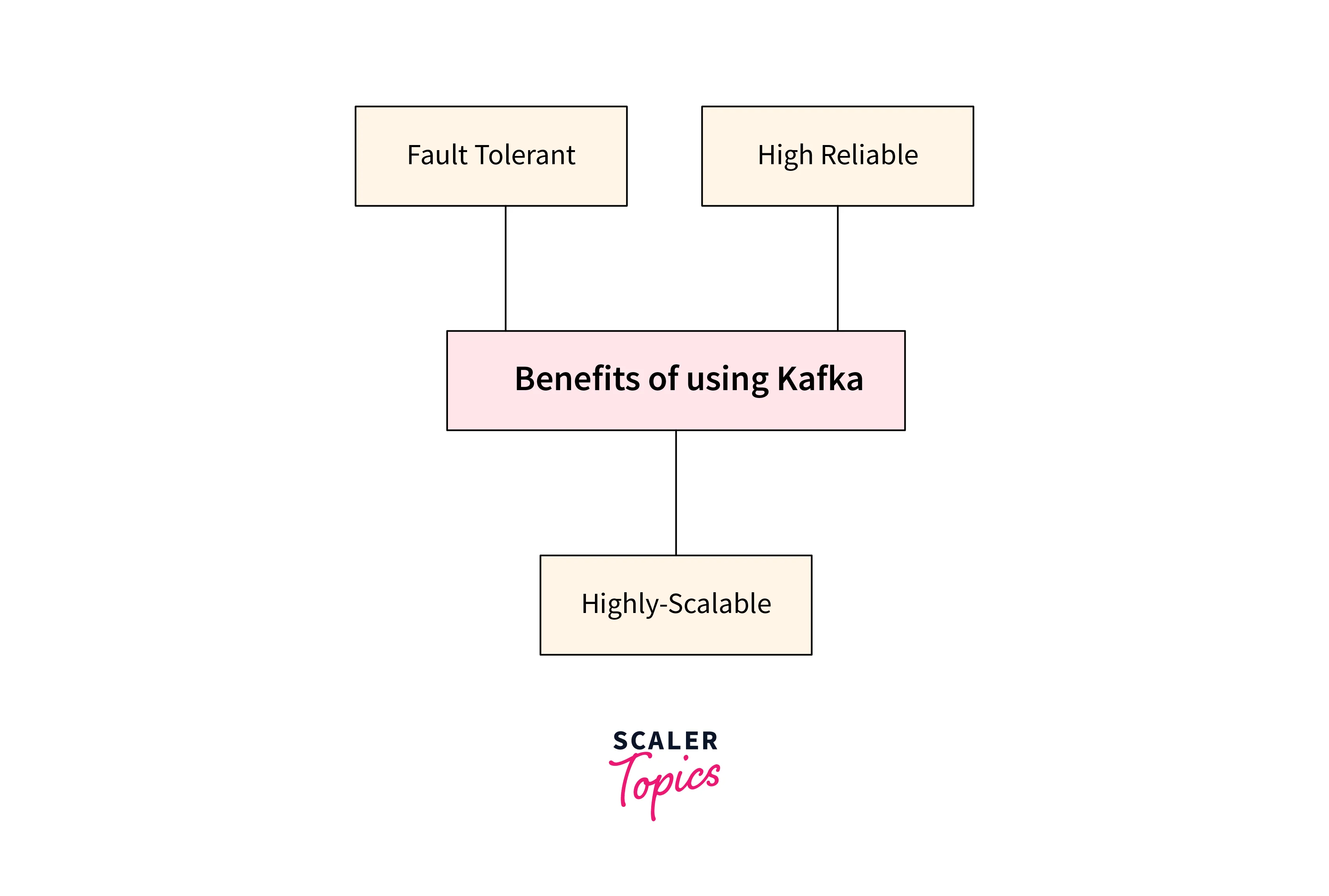
Scalability
With the Kafka messaging system, scalability could be easily achieved without any downtime. With its highly partitioned log commit model, the inflow of data is seamlessly distributed across its various servers. This gives Kafka meaning to offer scalability to its users beyond what could have been offered by a single server when it comes to handling huge amounts of streaming data.
Fault tolerance
As we studied in the What is Kafka section, Kafka utilizes the distributed log commit model, which makes the messages from various data sources persist on disk without any hassle. This makes Kafka durable enough to continue the data as fast as possible. The partitions in Kafka are highly distributed, as well as replicates across various servers before being all written to the disk. With this, the data is preserved from any server failure, making the data highly durable as well as fault-tolerant.
Real-time data processing
With the concept of decoupling, Kafka can offer low latency to its users for the various data streams, which makes it extremely fast. Users can extend the clusters efficiently across various availability zones. Users can also connect clusters over the globe contributes to Kafka being highly available as well as fault-tolerant without using a risk for data loss.
Best practices for designing and implementing Kafka data pipelines
Now we shall be talking about the best practices one must follow in the Kafka data pipeline and data flow for designing and implementing Kafka data pipelines.
Topic partitioning
To start with, the Kafka topic can be defined as a division implemented for classifying messages or data records. The topic name is unique across the entire Kafka cluster. This means that messages are read and sent from defined Kafka topics only. So consumers read data from topics, and producers write the data to topics.
Below is the depiction of how Topic partitioning plays an important role in the Kafka data pipeline and data flow:

This is analogous to the table we have inside the database in a traditional RDBMS system. So, as we have multiple tables inside a single database, similarly, we can have multiple topics inside Apache Kafka. The number of topics is not limited and can be easily identified by their unique name.
For in-depth understanding, one must also go through the article - Apache Kafka Topics, Partitions, and Offsets - Scaler Topics
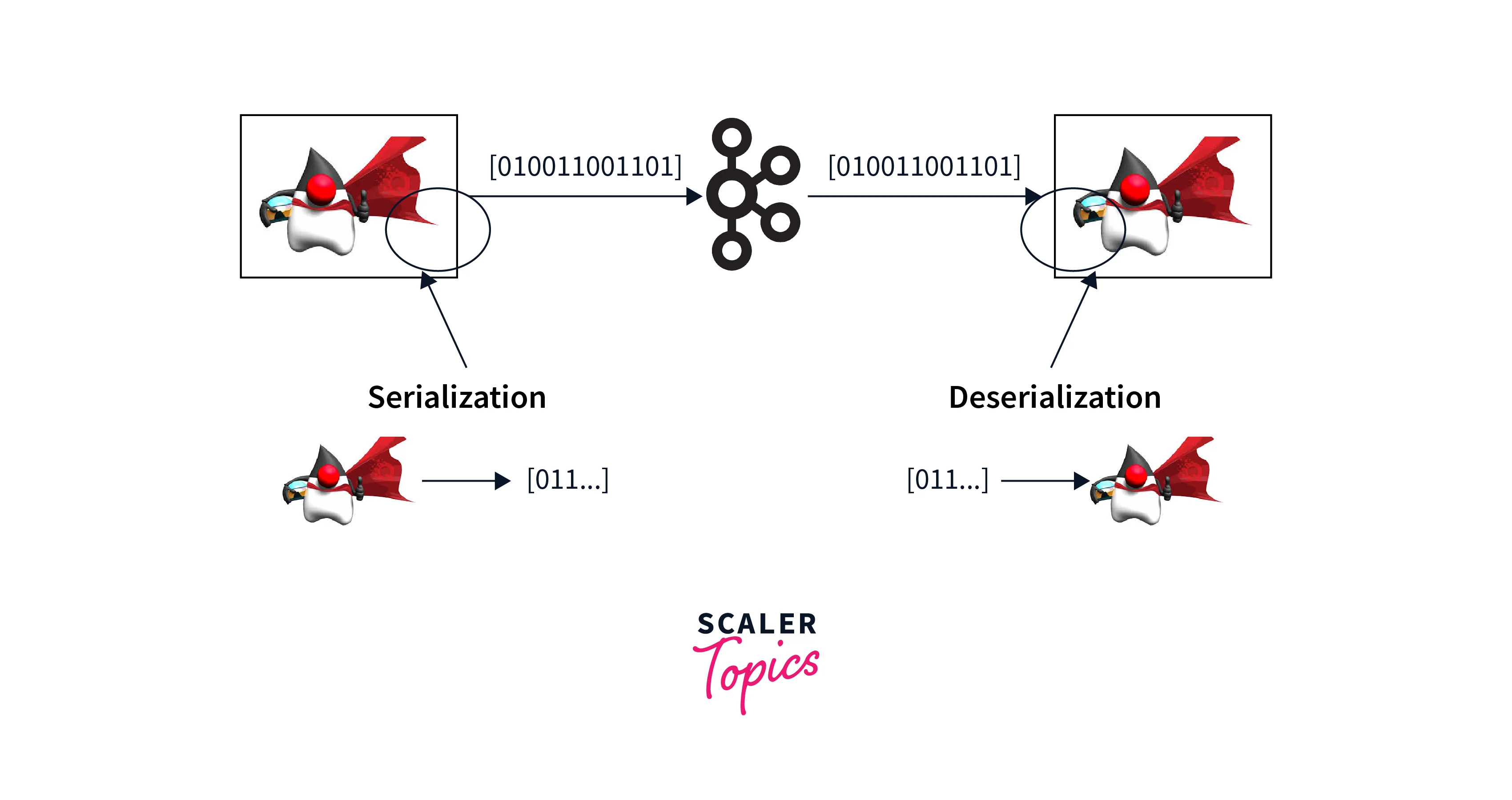
Message serialization
With message serialization, one can ensure compatibility and interoperability between different systems. It is a best practice for Kafka data pipelines to serialize messages into a standardized format like Avro or JSON. Data producers and consumers can exchange data seamlessly regardless of the programming language or platform.
Serialization also enables schema evolution, allowing for the addition, modification, or deletion of fields without breaking compatibility. This flexibility, along with the ability to validate and transform data during serialization, makes it an essential component for designing and implementing robust and adaptable Kafka data pipelines.
Below is the depiction of how Message serialization happens in the Kafka data pipeline and data flow:
Monitoring and alerting
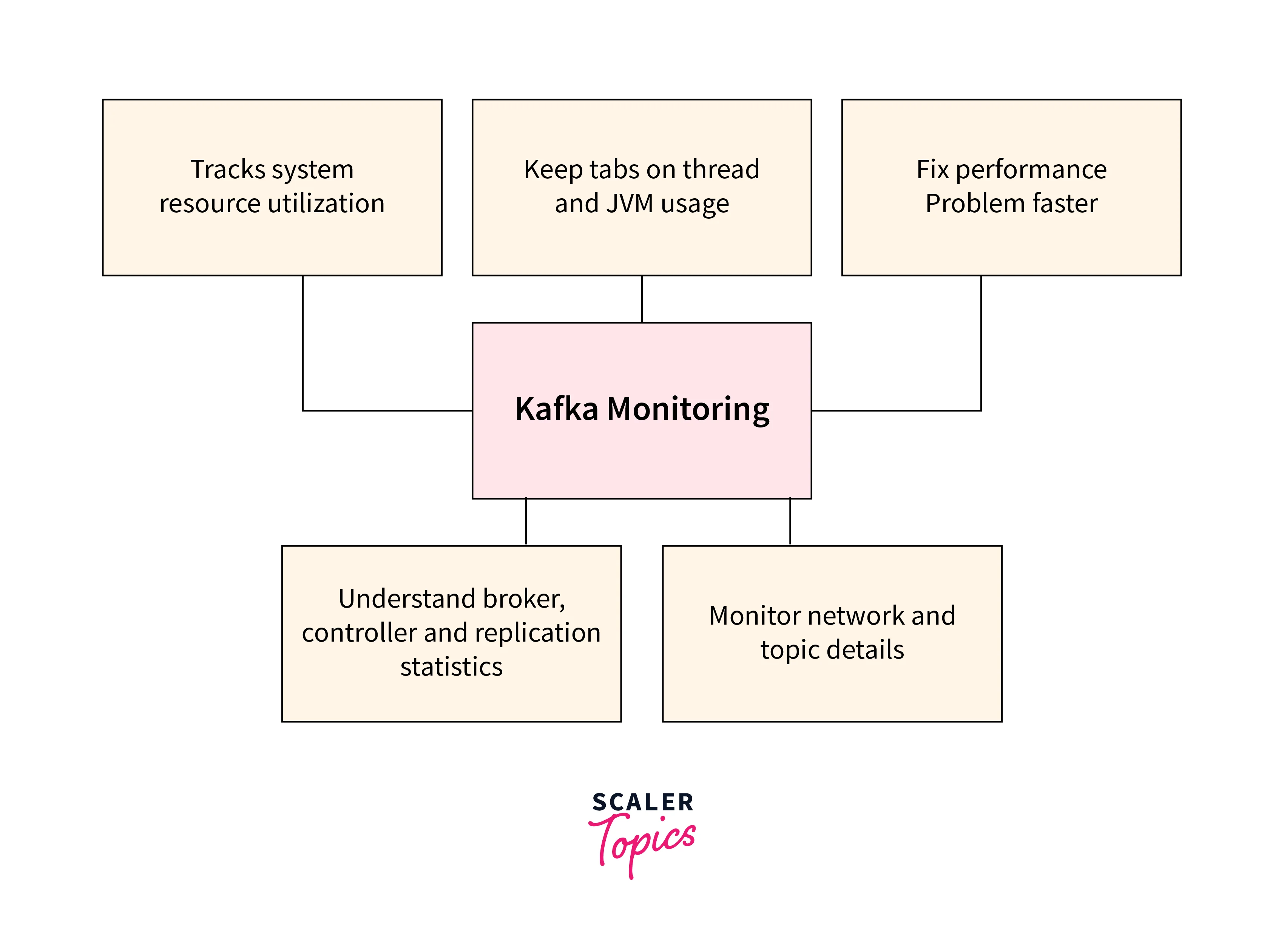
Above are some key benfits of monitoring in the Kafka data pipeline and data flow.
To be able to track the health, performance, and availability of your Kafka cluster, one must finetune the monitoring and alerting system for the Kafka data pipeline and data flow. Both of these practices are important best practices for designing and implementing Kafka data pipelines. Monitoring makes sure users are offered smooth operation and ease in identifying potential issues.
One must start by monitoring metrics such as latency, broker status, message throughput, and consumer lag, and this could help you proactively detect failures, bottlenecks, or anomalies. When the predefined conditions or threshold level are met, alerting complements monitoring by triggering notifications or automated desired actions. This prevents data loss or downtime by enabling prompt response in this kind of critical situation.