The Role of the Zookeeper in the Kafka Cluster
Overview
ZooKeeper is a critical role in a Kafka cluster by providing distributed coordination and synchronization services. It maintains the cluster's metadata, manages leader elections, and enables consumers to track their consumption progress. It also stores offsets, ensures fault tolerance, and assists in broker discovery and dynamic configuration updates. ZooKeeper serves as the backbone of the Kafka ZooKeeper cluster, facilitating essential coordination and management tasks that enable Kafka to function as a distributed, scalable, and fault-tolerant messaging system.
Introduction
In a Kafka ZooKeeper cluster, ZooKeeper plays a crucial role in coordinating and managing the distributed environment.
It serves as a centralized spot for maintaining and storing the metadata for Kafka, which includes details on topics, partitions, consumer offsets, and cluster setup. ZooKeeper maintains a consistent picture of the cluster across all participating Kafka brokers, ensuring data consistency and fault tolerance. In a Kafka cluster, ZooKeeper ensures fault tolerance by keeping consistent metadata across brokers.
Important functions in the Kafka ZooKeeper cluster include leader election, broker discovery, and distributed operation coordination are handled by ZooKeeper. It makes it possible for Kafka producers and consumers to monitor their progress and keep the cluster's communication dependable.
What is ZooKeeper?
In a Kafka ZooKeeper cluster, ZooKeeper is a centralized service that provides distributed coordination, names, and configuration information maintenance for applications that are executing in a distributed environment.
Apache Kafka makes use of Zookeeper to manage the following:
- In a Kafka ZooKeeper cluster, ZooKeeper tracks broker membership, topic configuration, leader selection, and metadata related to Kafka topics, brokers, and consumers.
- It stores the configuration of Kafka topics, stores the configuration of topics, and chooses leaders for each partition.
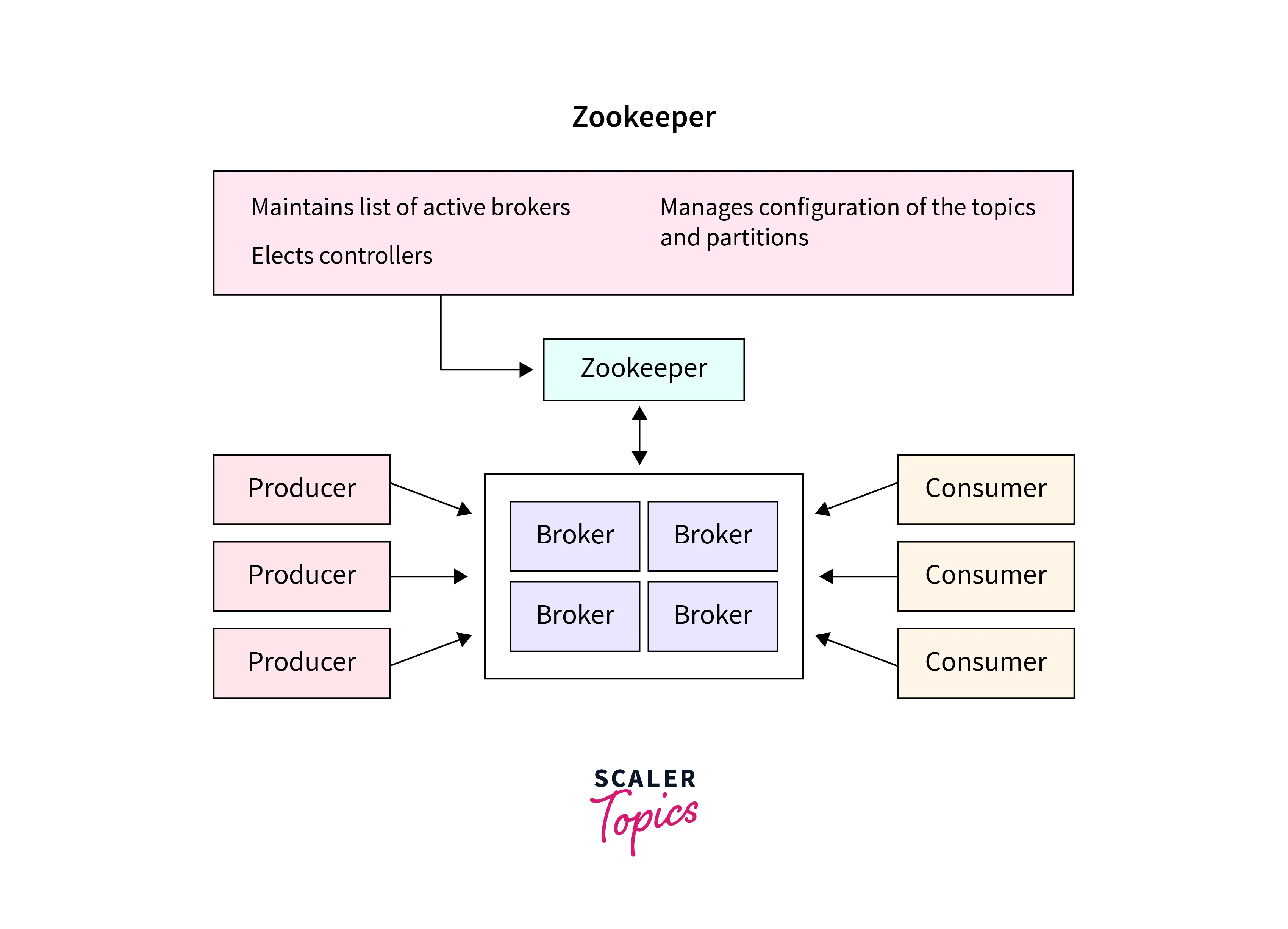
ZooKeeper is an essential Kafka component that is highly available and dependable, essential for Kafka to function properly.
Roles of ZooKeeper in Kafka
In a Kafka ZooKeeper cluster,Kafka and ZooKeeper collaborate to build a Kafka Cluster, with ZooKeeper providing distributed clustering and Kafka managing data streams and client communication.
a. In Kafka Brokers
Kafka brokers are essential components of Apache Kafka, responsible for partition management, message replication, fault tolerance, and collaborating with ZooKeeper for cluster coordination and metadata management.
The following are ZooKeeper's primary functions within Kafka brokers:
- Registration of Broker:
Kafka brokers register with ZooKeeper to enable other brokers and clients to find and contact them, and ZooKeeper keeps track of active brokers and their connection information. - Membership of Cluster:
ZooKeeper keeps track of the Kafka cluster's active brokers and stores membership information, allowing for dynamic cluster membership changes and a current view. - Controller Election:
ZooKeeper makes the controller election process easier by ensuring that only one broker is the controller at any given time. - Cluster Events and Alerts:
ZooKeeper sends alerts to Kafka brokers about cluster events and changes. For example, if a broker fails or quits the cluster, ZooKeeper can alert the other brokers.
b. In Kafka Consumers
Kafka consumers use ZooKeeper to coordinate, monitor, record offsets, and perform partition rebalancing within a consumer group. ZooKeeper is used to read data from Kafka topics.
The following are ZooKeeper's primary functions within Kafka Consumers:
- Cluster Coordination:
ZooKeeper is responsible for arranging consumer groups in Kafka and keeping track of active groups and their members, as well as group membership information such as customers and partitions. - Group Membership and Rebalancing:
ZooKeeper simplifies group membership management by assigning partitions fairly among active consumers and coordinating the partition reassignment process when group membership changes. - Offset Commitment:
Kafka consumers store their current offset, which can be managed by ZooKeeper, which maintains committed offset information for each consumer group. - Consumer Metadata:
ZooKeeper saves consumer-related metadata, which other components or monitoring systems can utilize to track the progress and status of individual consumers or consumer groups.
How Kafka and ZooKeeper Work Together?
ZooKeeper is used by Kafka to coordinate clusters, maintain metadata, track broker availability, facilitate leader election, and manage consumer groups, as well as handle dynamic configuration changes.
Controller Election
- To choose the Controller, each broker attempts to create an "ephemeral node" (a znode that will exist until the session that created it ends) called controller.
- The controller will be the first broker to create this ephemeral node, and future broker requests will receive the "node already exists" message.
- When a controller fails, brokers initiate a new round of controller elections to take over the failed controller's tasks.
Cluster Membership
- A group of brokers identified by a special numeric ID form a Kafka cluster.
- A group znode is generated when the brokers connect to the respective ZooKeeper instances, and each broker then constructs an ephemeral znode inside of this group znode.
Topic Configuration
- Each Kafka topic has its topic configuration, which may be applied at both the per-topic and global levels.
- Each topic's option has a default value that may be changed on a global or per-topic basis.
- The replication factor, limit message size, flush rate, unclean leader election, and message retention are all topic settings.
- The minimum number of replicants, maximum message size, flush rate, unclean leader election, and message retention are all determined by these settings.
Access Control Lists
- Apache Kafka includes an authorizer that supports access control lists (ACLs) via ZooKeeper.
- If an authorizer is defined in the Kafka server.properties file, access to resources is restricted to super users.
- When an authorizer is enabled, only super users have access to resources that do not have an associated ACL.
Quotas
- Quotas can be used by Kafka brokers to limit the number of broker resources that consumers can utilize.
- Client quotas are classified into two types: network bandwidth restrictions established by a byte-rate threshold and request rate constraints defined by a CPU utilization threshold.
- Quotas can be applied to user+client-id groups as well as user or client-id groups, with the most specific quota matching a particular connection being utilized.
- Overriding default quotas at any of the quota levels that must be smaller or larger than the default.
The Hardware of the ZooKeeper Server
- Memory:
ZooKeeper is not a memory-intensive application when dealing with simply Kafka-stored data. In a typical production use case, a minimum of 8 GB of RAM should be available for ZooKeeper. - CPU:
ZooKeeper is a Kafka metadata store that does not require a lot of CPU resources and has a latency-sensitive feature, so it should be given a dedicated CPU core. - Disk:
Disk performance is critical for maintaining a healthy ZooKeeper cluster. We advocate utilizing SSDs for best performance because ZooKeeper requires low-latency disk writes. - Java Virtual Machine (JVM):
ZooKeeper is often used as a JVM but should have a 1 GB heap size and monitor heap utilization to avoid garbage collection delays.
How to Connect to Zookeeper?
ZooKeeper has several configuration settings that may be modified to enhance its functionality, dependability, and behavior.
Configuration Options for ZooKeeper
The following are some essential setup parameters for ZooKeeper:
-
dataDir:
The data directory (dataDir) specifies the location of the directory in which transaction logs and snapshots are kept by ZooKeeper.Example:
dataDir=/var/lib/zookeeper -
clientPort:
Determines the port number on which ZooKeeper looks for client connections (clientPort). This port is used by clients to connect to ZooKeeper.Example:
clientPort=2181 -
Tick Time (tickTime):
ZooKeeper's tick setting controls how long a tick lasts, which affects time-related parameters such as synchronization and session timeout.Example:
tickTime=2000 -
Init Limit (initLimit) and Sync Limit (syncLimit):
ZooKeeper settings determine the number of ticks required for initial sync and synchronization, affecting how long it takes for a ZooKeeper server to join or recover from a failure.Example:
initLimit=10, syncLimit=5 -
Maximum Client Connections (maxClientCnxns):
ZooKeeper server load is controlled by setting the maximum number of concurrent client connections per IP address, preventing excessive connections.Example:
maxClientCnxns=100
Advantages of ZooKeeper
ZooKeeper has many advantages that make it a popular choice in distributed systems for distributed coordination and synchronization.
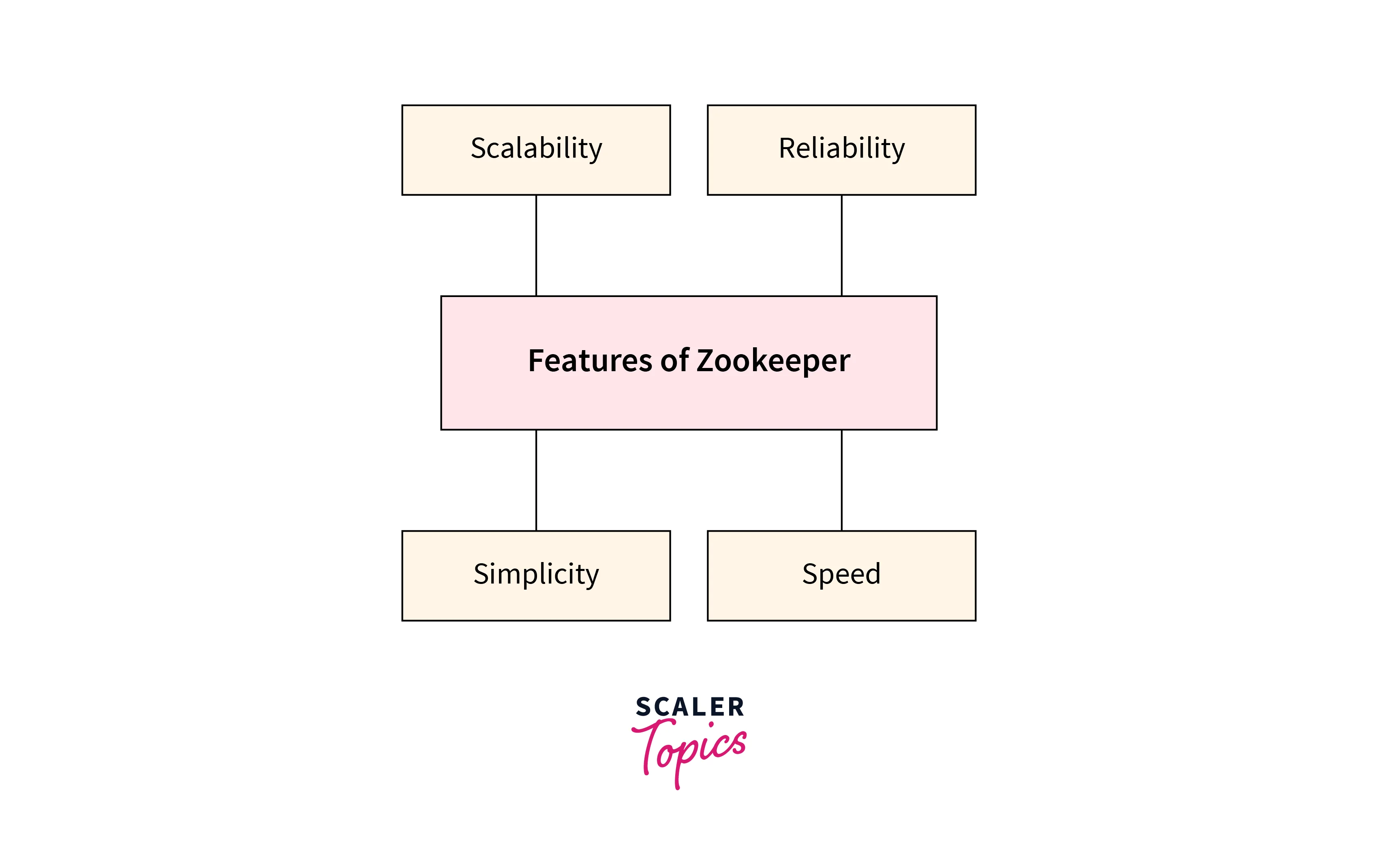
- Reliability:
ZooKeeper is a highly dependable service that is built to resist downtime. - Simplicity:
With the use of a common hierarchical namespace, coordination is accomplished. - Speed:
In circumstances when 'Reads' are more numerous, it operates with a 10:1 ratio, which is extremely fast. - Scalability:
We can efficiently improve performance without any downtime by adding extra machines and making little changes to the application settings as necessary.
Optimizing ZooKeeper
Consider the following strategies to improve ZooKeeper's performance and scalability:
- Hardware Configuration:
ZooKeeper servers should be equipped with adequate hardware to manage the workload and deliver top-notch performance. - Ensemble Size:
ZooKeeper ensemble size affects performance and fault tolerance, with bigger ensembles providing better fault tolerance, but resulting in higher coordination costs. - Network Latency:
ZooKeeper servers can be placed in the same data area to reduce network latency, resulting in better performance and faster response. - JVM Tuning:
The Java Virtual Machine (JVM) parameters for ZooKeeper may be adjusted to increase memory efficiency, garbage collection behavior, server reliability, and performance. - Batch operations:
Batching actions together reduces round trips between clients and ZooKeeper servers, increasing throughput and reducing network overhead.
Monitoring ZooKeeper with Elasticsearch and Kibana
Elasticsearch and Kibana are the perfect tools for this type of monitoring, which is essential for determining the health of the Kafka cluster and identifying system problems.
Elasticsearch is recommended for monitoring Kafka for the following reasons:
- Elasticsearch is open source.
- Elasticsearch may serve as an organization's central source of truth in a variety of ways.
- Elasticsearch and Kibana collaborate to deliver specialized visualizations for monitoring Kafka health.
- Elasticsearch and several other tools are used to offer threshold- and machine-learning-based alerts.
Running Kafka without ZooKeeper
Can Kafka be Run without ZooKeeper?
- Before Apache Kafka 2.8.0 (which was made available in June 2021), ZooKeeper was a requirement and an essential component of the Kafka ecosystem.
- Kafka 2.8.0 brought about a new feature known as Kafka Raft Metadata Mode, which does away with the need for ZooKeeper to store Kafka's metadata.
- The Kafka Raft Metadata Mode allows the cluster to elect an internal controller to manage metadata, maintain the state, handle leader elections, and coordinate distributed operations.
Why Remove ZooKeeper from Kafka Implementations?
- By removing the requirement for a separate ZooKeeper ensemble, removing ZooKeeper simplifies the design and lowers operating costs.
- It is simpler to install and operate Kafka clusters when ZooKeeper is removed since there is less reliance on external services.
- Kafka now uses the Raft consensus protocol to improve performance and scalability for large-scale installations.
How does Kafka Work without ZooKeeper?
- Kafka versions 2.8.0 and later can operate without an external ZooKeeper dependency by using the Kafka Raft Metadata Mode.
- This eliminates the need for a separate ZooKeeper ensemble, simplifying the architecture, enhancing scalability, improving reliability, and streamlining operations.
- The removal of ZooKeeper reduces complexity, dependencies, and single points of failure, offering a more streamlined and self-contained Kafka ecosystem.
KIP-500
- Apache Kafka's "KRaft" mode is a new functionality introduced by Kafka Improvement Proposal 500 (KIP-500).
- An alternative metadata mode called KRaft mode breaks Kafka's dependency on ZooKeeper for metadata storage and synchronization.
- It describes the KRaft mode's architecture and implementation in detail, including the Kafka broker changes that must be made and the procedure for switching from the current ZooKeeper-based metadata mode.
Kafka Raft Metadata Mode
- The Kafka Raft Metadata Mode in version 2.8.0 allows Kafka to function independently of ZooKeeper's storage and coordination of metadata.
- It uses the Raft consensus mechanism to choose an internal controller who is responsible for managing leader elections, keeping track of the metadata state, and coordinating distributed activities throughout the Kafka cluster.
- The controller ensures that brokers update their information consistently and simultaneously.
Conclusion
- In summary, ZooKeeper is essential for a Kafka cluster as it provides distributed coordination and synchronization services, managing metadata and facilitating coordination among components.
- ZooKeeper is a centralized repository for essential information such as topic metadata, broker settings, consumer offsets, and cluster configuration.
- ZooKeeper guarantees that one broker is the partition leader, allowing for high availability and fault tolerance. It also organizes dispersed processes, allowing Kafka producers and consumers to find each other and have a consistent picture of the cluster.
- In the above also covers Optimizing ZooKeeper, Monitoring ZooKeeper with Elasticsearch and Kibana and also Running Kafka Without ZooKeeper.
- To operate Kafka without ZooKeeper, you must use Kafka version 2.8.0 or later and configure Kafka to utilize the Raft Metadata Mode. To correctly configure and move your Kafka deployment to run without ZooKeeper, check the Kafka documentation and migration instructions offered by Apache Kafka.