What is Kafka ?
Overview
With the amount of data growing every minute, challenges related to storing and processing this massive data are critical. To overcome this challenge, Apache Kafka was introduced. Kafka offers a highly distributed publish-subscribe messaging system that is fault-tolerant, scalable, and faster read the streaming data, storage, and analysis of it. Built on top of the ZooKeeper synchronization service, Kafka is easy to integrate with other `Apache technologies like Storm, Flink, and Spark.
What is Kafka?
To understand what is Kafka, we first need to understand the challenges that lead to its creation. With the huge amount of data generated every minute, it is quite difficult to understand how to collect a huge volume of data as well as how to analyze this collected data. To tackle these challenges, we need a messaging system. Now the messaging system we already had is a queue-based messaging system with its own set of limitations.
That is where Apache Kafka was introduced. To answer the question, of what is Kafka, we can define it as a highly distributed offering high throughput and great performance system. It is open-source software with a publish-subscribe messaging system and a robust queue that can efficiently manage the huge volume of streaming data from its source to destination. Kafka offers a great way to read the data, storage as well as analysis made with the streaming data. Built on top of the ZooKeeper synchronization service, Kafka is easy to integrate with other Apache technologies like Storm, Flink, Spark, etc. With its log commit partitioned architecture, Kafka holds the ability to process real-time data streams.
New developers and engineers contribute to the various new features of Apache Kafka to support new users as it is a free and open-source product from Apache Foundation. Originally it was created on Linkedin which was later passed to the Apache Foundation where it was declared as open-source software in 2011. The message in the Kafka is persisted in the disk along with replication within the cluster allowing zero data loss. As Kafka is highly distributed, contributes to the great processing power to handle large amounts of data that can be consumed either as online or offline messages.
Kafka has proven to be a great replacement for the traditional message queue system, as it offers better throughput, replication, built-in partitioning, as well as inherent fault tolerance. All these properties of Kafka make it a great fit for any type of large-scale message processing in the big data domain.
Benefits
We understood in detail what is Kafka, with this section of the article we shall be learning about the benefits Kafka offers to its users.
With Apache Kafka, we can utilize its message broker system to create continuous data streams (in real time too) by incrementally and sequentially processing the massive amount of data. This data inflow is real-time data that is simultaneously gathered from various data sources offering the below benefits to its users for their data integration process.
Reliability − Kafka is distributed, partitioned, replicated, and fault tolerant.
Scalabile − With the Kafka messaging system, scalability could be easily achieved without any downtime. With its highly partitioned log commit model, the inflow of data is seamlessly distributed across its various servers. This gives Kafka meaning to offer scalability to its users beyond what could have been offered by a single server when it comes to handling huge amounts of streaming data.
Fast - With the concept of decoupling, Kafka can offer low latency to its users for the various data streams which makes it extremely fast.
High Availability - Users can extend the clusters efficiently across various availability zones. Users can also connect clusters over the globe contributes to Kafka being highly available as well as fault-tolerant without using a risk for data loss.
Durable − As we studied in the what is Kafka section, Kafka utilizes the distributed log commit model which makes the messages from various data sources persist on disk without any hassle. This makes Kafka durable enough to continue the data as fast as possible. The partitions in Kafka are highly distributed as well as replicates across various servers before being all written to the disk. With this the data is preserved from any server failure, making the data highly durable as well as fault-tolerant.
High-Performance/High-throughout − Apache Kafka offers great performance or high throughput for not only the consumers subscribing messages but also for publishing messages in the queue. This helps to maintain a stable performance for huge volumes of data that is, TBs of messages.
Permanent Storage - The data streams gathered from various data sources can be securely and safely stored as streams of data in the fault-tolerant, replicated, and distributed cluster.
Need for Kafka
Till now, we know what is Kafka. What are the various benefits that Kafka offers? But is the need for Apache Kafka?
Let us answer this question in this section of the article. Apache Kafka is the data streaming system where your data from various sources can be easily handled for real-time data feeds as a unified platform. It is widely used for collecting metrics, messaging, logging events, activity tracking across websites, log committing, and real-time analytics. The number of different consumers can seamlessly be handled by Kafka, as it offers low low latency message delivery systems along with offering fault tolerance even when there is a failure in the machine.
Developers and Engineers from an organization like Uber, Shopify, Square, Spotify, Strave, etc, love working with Kafka as it is an open-source, distributed, flexible, and message stream processing framework.
Proving as a relief for large-scale message processing applications, Kafka is fast, reliable, scalable, and robust when compared with any traditional messaging queues. It can process 2 million writes/sec and then persist the data being written to the disk. This makes writes directly go to the page cache of the operating system or the RAM of the system. Efficient data transfer from a page cache to a network socket is easily possible with Kafka with its event-driven processing of data.
How Kafka Works?
Before we head towards understanding what is Kafka and how it works, it is crucial to understand the concept on which Kafka worked.
When we define a Messaging System, we need to highlight that, it is an end-to-end system that carries (or transfers) the data from one system to another to support the seamless data movement from source to target without worrying about the process of sharing the data. The method where the message is transferred in a distributed manner is positioned on the concept of reliable message queuing. The messaging pattern followed by Kafka is the combination of asynchronous point-to-point and publish-subscribe (pub-sub) messaging systems.
When the message persists in the queue, that messaging system is referred to as the point-to-point system. Here, one specific message can be consumed by one consumer while many consumers can be subscribed to consume the remaining messages in the queue. Also, once a message is read, it disappears from the queue. The publish-subscribe messaging system can be described as a process where the messages are persisted in a topic, which can be consumed only when the consumers subscribe to it. Though consumers can subscribe to more than one topic and consume all the messages. Here, the messages produced by the producers are called publishers while subscribers are the message which the consumers consume.
Below is the pictorial representation of both the messaging system on which Kafka works.


To provide all the key benefits to its users, Kafka pics the pros of both types of messaging systems. While the point-to-point queuing messaging systems offer distributed data processing across various consumer instances, the publish-subscribe messaging system does. help Kfaka become highly available so that the messages can be subscribed to by various subscribers. With the publish-subscribe messaging system, Kafka allows each message to reach each of its subscribers, while not allowing the work to be distributed across various workers. Hence, to combat this Kafka utilizes the partitioned log commit model which helps to bind the two messaging systems together.
As we know, a log captures the messages as an ordered sequence of data records which always append the data records at the end. These log commits can be broken up into multiple partitions, and correspond to various subscribers. This allows multiple subscribers to utilize the same topic at a time while offering high scalability as each is assigned a partition.
In short, Apache Kafka offers replayability, allowing various independent systems to seamlessly read and work as per their requirement from the data streaming in its queue without any hassle.
Kafka's Architecture
Let us briefly discuss Kafka's architecture. While Kafka utilizes both the point-in-point as well as publish-subscribe messaging systems for publishing data records across various topics. Every topic consists of a partitioned and structured log commit log, which helps to keep a track of the records. As the new record is always appended at the end of this log in real-time, offering zero data loss. High scalability, fault tolerance, as well as parallelism are offered by the distributed and replicated partitions across various servers.
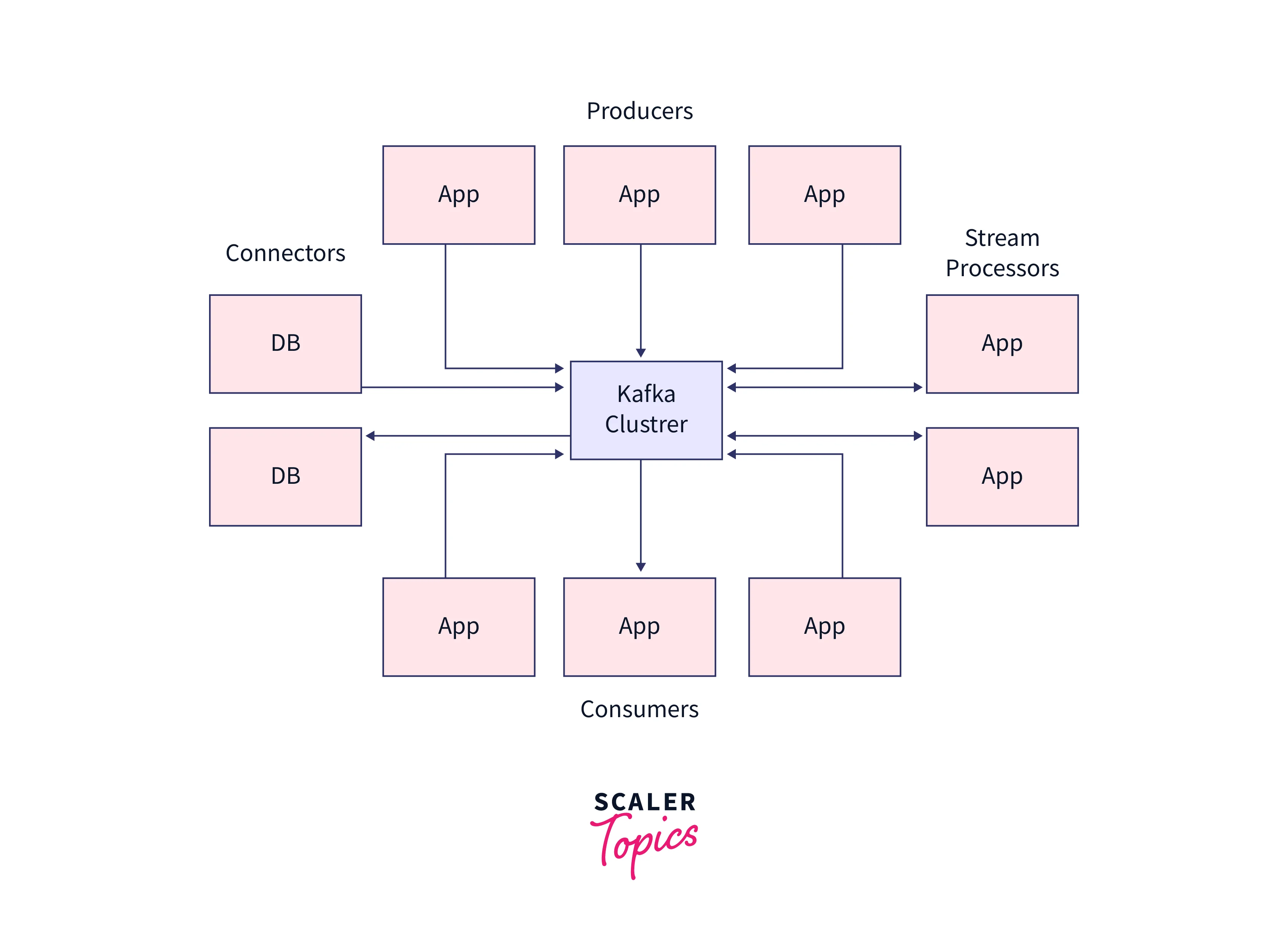
Every consumer who wants the data from the Kafka log is assigned a partition allowing various consumers at the same time to use the data while the order of the data in the log is maintained simultaneously. The data records are seamlessly written and replicated to the disk which makes Kafka a highly scalable and fault-tolerant storage system. Users can set a retention time limit for the data stored on disk until it runs out of space.
Four important APIs which is widely used in Kafka's architecture are described below:
Producer API: For publishing a stream of data records to a Kafka topic, Kafka uses the producer API.
Consumer API: For subscribing to Kafka's topics and processing their streams of data records, Kafka uses the consumer API.
Streams API: With the Streams API, Kafka authorizes the systems to work as stream processors. Here, the input stream is taken up from the topic which is then transformed into the output stream transferring the data records across various output topics.
Connector API: With the Connector API, any external system or application can be easily integrated with the Kafa architecture. The stems can be automated with the data system to any of their current Kafka topics.
For a more in-depth understanding of the topic of Kafka's Architecture, you can visit the article: [Kafka's Architecture]("{link=nofollow noopener}")
RabbitMQ vs Kafka
Given below is the detailed comparison between Rabbitmq vs Kafka based on various properties as listed.
| Properties | RABBITMQ | APACHE KAFKA |
|---|---|---|
| Architecture/Model | Structured on the concept of Messaging queue. | Structured on the concept of partitioned log commit architecture where both (messaging queue, as well as a publish-subscribe messaging system, are being utilized. |
| Retention period of the messages | Once the message in the queue has been read or consumed the message vanishes. The message retention is acknowledgment based. | The message retention is policy-based. Users get the flexibility to adjust the retention window for the message according to its needs. |
| Protocols utilized | Utilises the advanced messaging queue protocol (AMQP) along with the support from the MQTT, STOMP type of plugins. | Utilises the binary protocol over TCP. |
| Replication | Automatix replication is not possible, while the users get the flexibility to manually configure the replication of the messages. | Topics are automatically replicated, but the user can manually configure topics to not be replicated. |
| Scalability | For high scalability, the number of consumers must be increased in the queue as compared to the competing consumers. | As partitions are highly distributed across various servers, Kafka provides high scalability to its consumers. |
| Flexibility to serve the Consumers | As messages have vanished once it is consumed by any one of the consumers, multiple consumers will never be able to receive the same message. | As Kafka offers the same message to remain in the log until the retention window expiry, various consumers can subscribe to the same topic. |
| Ordering of the messages | Consumers receive the message concerning the order of the arrival of those messages to the queue. When the same message needs to be consumed by more than one consumer, only a subset of that message is available to be consumed by the consumers. | As the Kafka architecture is a partitioned log-based model, Kafka allows the consumer to receive the message in order. |
Apache Technologies Often Used with Kafka
Kafka is getting widely popular and its integration with other Apache technologies is on the rise. Be it large data processing streams, solutions for big data analytics, or event-driven architecture, everywhere Kafka is finding its place. Below are a few of the Apache technologies discussed often integrated and utilized with Apache Kafa.
Apache Hadoop: For storing huge amounts of data in a distributed manner, Apace Haddop is the choice. With the distributed software framework across the cluster of computers, Hadoop is widely used for big data analytics, data mining, machine learning, and various data-driven applications.
Apache Spark: When it comes to large-scale data processing, Apache Spark is the choice as the analytics engine. Apache Spark could be easily integrated with data transferred by Apache Kafka for performing analytics on data streams to produce a real-time data stream processing system.
Apache Flink: For tools that offer scalable computations on event-driven data streams along with consistently high speed at very low latency, Apache Flink is the right choice. You can easily ingest the data streams as a Kafka consumer, and in near real-time, you can perform operations as well as simply start to publish the outputs to Kafka.
Apache NiFi: We can define Apache NiFi as a data flow management application consisting of a drag-and-drop visual interface. Apache NiFi can run as a Kafka producer as well as a Kafka consumer to tackle this limitation.
Conclusion
-
Kafka is a highly distributed offering high throughput and great performance system. It is open-source software with a publish-subscribe messaging system and a robust queue that can efficiently manage the huge volume of streaming data from its source to destination. Kafka offers a great way to read the data, storage as well as analysis made with the streaming data.
-
The messaging pattern followed by Kafka is a combination of asynchronous point-to-point and publish-subscribe (pub-sub) messaging systems.
-
Apache Kafka offers benefits such as being Durable, and Scalable without any downtime and data loss, it's fast and offers high throughput which contributes to its great performance for streaming data.
-
Apache Kafka offers great performance or high throughput for not only the consumers subscribing to messages but also for publishing messages in the queue. This helps to maintain a stable performance for huge volumes of data that is, TBs of messages.
MCQs
-
MCQ 1 Which of the following messaging model does Kafka work on?
- Option 1 Publisher-Subscriber and push notification messaging system.
- Option 2 Messaging Queue and Publisher-Subscriber messaging system.
- Option 3 Messaging Queue and History log messaging queue messaging system.
- Option 4 All of the above.
Correct Answer: <2>
-
MCQ 2 Which of the following are the benefits offered by Kafka?
- Option 1 Durable and Fast
- Option 2 Scalability and reliability
- Option 3 High throughput/High performance
- Option 4 All of the above.
Correct Answer: <4>
- MCQ 3 Which of the following is False about Kafka?
- Option 1 Kafka is Open source.
- Option 2 Kafka has a distributed architecture.
- Option 3 Kafka opts for a Data-driven approche.
- Option 4 Kafka works on Point-in-point and Publisher-Subscriber models.
Correct Answer: <3>