Apache Kafka Use Cases
Overview
Kafka is a highly distributed offering high throughput and great performance system. It is open-source software with a publish-subscribe messaging system and a robust queue that can efficiently manage the huge volume of streaming data from its source to destination. Various use cases of what is Kafka used for can be found in the big data domain such as stream processing, Website Activity Tracking, Metrics, and Log Aggregation which shall be discussed in the article below. For data scenarios where organizations are dealing with little data say thousands of data messages per day, Kafka would not be a right fit, and such scenarios are also discussed.
What is Kafka?
To understand what is Kafka used for, we first need to understand the challenges that lead to its creation. With the huge amount of data generated every minute, it is quite difficult to understand how to collect a huge volume of data as well as how to analyze this collected data. To tackle these challenges, we need a messaging system. Now the messaging system we already had is a queue-based messaging system with its own set of limitations.
That is where Apache Kafka was introduced. To answer the question, of what is Kafka used for, we can define it as a highly distributed offering high throughput and great performance system. It is open-source software with a publish-subscribe messaging system and a robust queue that can efficiently manage the huge volume of streaming data from its source to destination. Kafka offers a great way to read the data, storage as well as analysis made with the streaming data. Built on top of the ZooKeeper synchronization service, Kafka is easy to integrate with other Apache technologies like Storm, Flink, Spark, etc. With its log commit partitioned architecture, Kafka holds the ability to process real-time data streams.
New developers and engineers contribute to the various new features of what is Kafka used for supporting new users as it is a free and open-source product from the Apache Foundation. Originally it was created on Linkedin which was later passed to the Apache Foundation where it was declared as open-source software in 2011. The message in the Kafka is persisted in the disk along with replication within the cluster allowing zero data loss. As Kafka is highly distributed, contributes to the great processing power to handle large amounts of data that can be consumed either as online or offline messages.
Kafka has proven to be a great replacement for the traditional message queue system, as it offers better throughput, replication, built-in partitioning, as well as inherent fault tolerance. All these properties of Kafka make it a great fit for any type of large-scale message processing in the big data domain.
Popular Use Cases for Apache Kafka
With Kafka capabilities such as fault tolerance and scalability, you shall find it often being implemented for big data domains. This way it is considered as a reliable way of ingesting as well as quickly moving large amounts of data streams. Let us briefly discuss some of the most popular use cases for Apache Kafka:
Messaging:
One of the most prominent use cases of what is Kafka used for is Messaging also widely popular as messaging. Apache Kafka works better as a replacement for traditional message brokers. Here it offers better throughput, replication, and in-built partitioning, along with its capability to offer fault-tolerance along with scaling attributes is huge. With Kafka streams, building a streaming platform is quick and easy. Users can transform the Kafka topics inputs into Kafka topics output quickly. This makes sure that the application or the systems where it has been implemented remains distributed as well as fault-tolerant.
Website Activity Tracking:
Kafka was originally invented by LinkedIn for this use case only. LinkedIn still utilizes Kafka for its Website Activity Tracking and captures data along with the operational metrics happening in real-time. Website activity such as real-time page views finds, or other insightful actions users are seamlessly published to the Kafka topics with one topic per activity type. Originally, Kafka was built to get the user activity tracking pipeline in a real-time publish-consumer manner. This data tracked from the Website Activity Tracking in the Kafka are available for subscription for various use cases such as real-time data processing, real-time data monitoring, or even loading this data into Hadoop along with offline processing and reporting from the data warehousing systems.
Metrics:
Another use case of Apache Kafka is Metrics collection and monitoring. Kafka is widely utilized for operational monitoring data. In this use case, the metrics are collected as statistics from various distributed applications for producing the aggregated feeds of centralized operational data. Ussr can easily combine Kafka with the real-time data monitoring application and systems from the Kfaka topics.
Log Aggregation:
In this use case, the messages logs can be pushed into Kafka topics and eventually store in a Kafka cluster. With Apache Kafka, logs can be processed or aggregated like many organizations. The process around log aggregation involves gathering the physical log files of the servers and conveniently placing them in a central repository like a data lake, HDFS, or file server for further data processing. In this scenario, Kafka filters the details of the file and abstracts the data from it. The data has abstracted the messages as stream enabling low-latency data processing which in turn offers support for various data sources as well as the distributed data consumption.
Stream Processing:
With Kafka data can be processed in multiple pipelines consisting of various stages, while the raw data is input and consumed from Kafka topics and eventually gathered, enriched, or transformed as new topics for further data consumption or processing. Currently, with Kafka streams, this process is made easier, lightweight, and powerful for processing the data Building a streaming platform that transformed the Kafka topic's input data into output Kafka topics can be easily done. This makes sure that the system is fault-tolerant and distributed.
Event Sourcing:
We can define event sourcing as the process where the design of the system or application could change the stated and can log the same as a time-ordered sequence of records. In this process of event sourcing, Kafka offers great support for huge log data stages making it an excellent backend for the system or application that is built for style.
Commit Log:
Kafka stores the message as a log commit and serves as an external commit log for distributed applications. The data could easily be replicated between the nodes via these logs which acts as a re-syncing mechanism for the destroyed or failed nodes for restoring the users' data. With the log compaction feature offered by Kafka, this can be easily done.
When Not to Use Kafka?
While Kafka is extremely useful for big data scenarios because of its fault-tolerant, scalable, and reliable features. But there is a certain limitation to it, which could increase the overall complexity, as it does not serve all the use cases. Let's find out which scenarios are not made for what Kafka is used for. Or for which scenario Kafak is not appropriate.
Small Data
Kafka was always designed keeping in mind the growing demand for data and fitting well for scenarios involving high volumes of data. But when used for small projects with fewer data Kafka might come out as overkill for you. In these scenarios, implementing traditional message queues like ActiveMQ or RabbitMQ is a better option for small data pipelines. To learn more about the difference between rabbitmq vs Kafka, deep dive into the link between rabbitmq vs Kafka and explore more. for relatively smaller data sets or as a dedicated task queue.
Streaming ETL
While Kafka has a streaming API, working in Kafka to perform the transformation of data on the fly is extremely painful. Building the pipeline with Kafka is quite complex with the setup, monitoring, and management of the data pipeline between producers and consumers. A substantial amount of work, time, and effort are required along with the added complexity that might not be well suited for streaming ETL. Hence, it is recommended to avoid Kafka as the processing engine for any Extract Transform and Load jobs. This is critically discouraged for pipelines involving real-time data processing.
Key Components of Kafka
Let us briefly discuss the key components of Kafka. While Kafka utilizes both the point-in-point as well as publish-subscribe messaging systems for publishing data records across various topics.
Every topic consists of a partitioned and structured log commit log, which helps to keep track of the records. As the new record is always appended at the end of this log in real-time, offering zero data loss. High scalability, fault tolerance, as well as parallelism are offered by the distributed and replicated partitions across various servers.
Every consumer who wants the data from the Kafka log is assigned a partition allowing various consumers at the same time to use the data while the order of the data in the log is maintained simultaneously. The data records are seamlessly written and replicated to the disk which makes Kafka a highly scalable and fault-tolerant storage system. Users can set a retention time limit for the data stored on disk until it runs out of space.
In the entire process, seven core components help in the entire working of Kafka streaming from publisher to subscriber. These are listed below:
- Broker
- Producers
- Consumers
- ZooKeeper
- Topic
- Partitions
- Offset
- Consumer Group
Kafka Broker:
The Kafka broker can be defined as one of the core components of the Kafka architecture. It is also widely known as the Kafka server and a Kafka node.
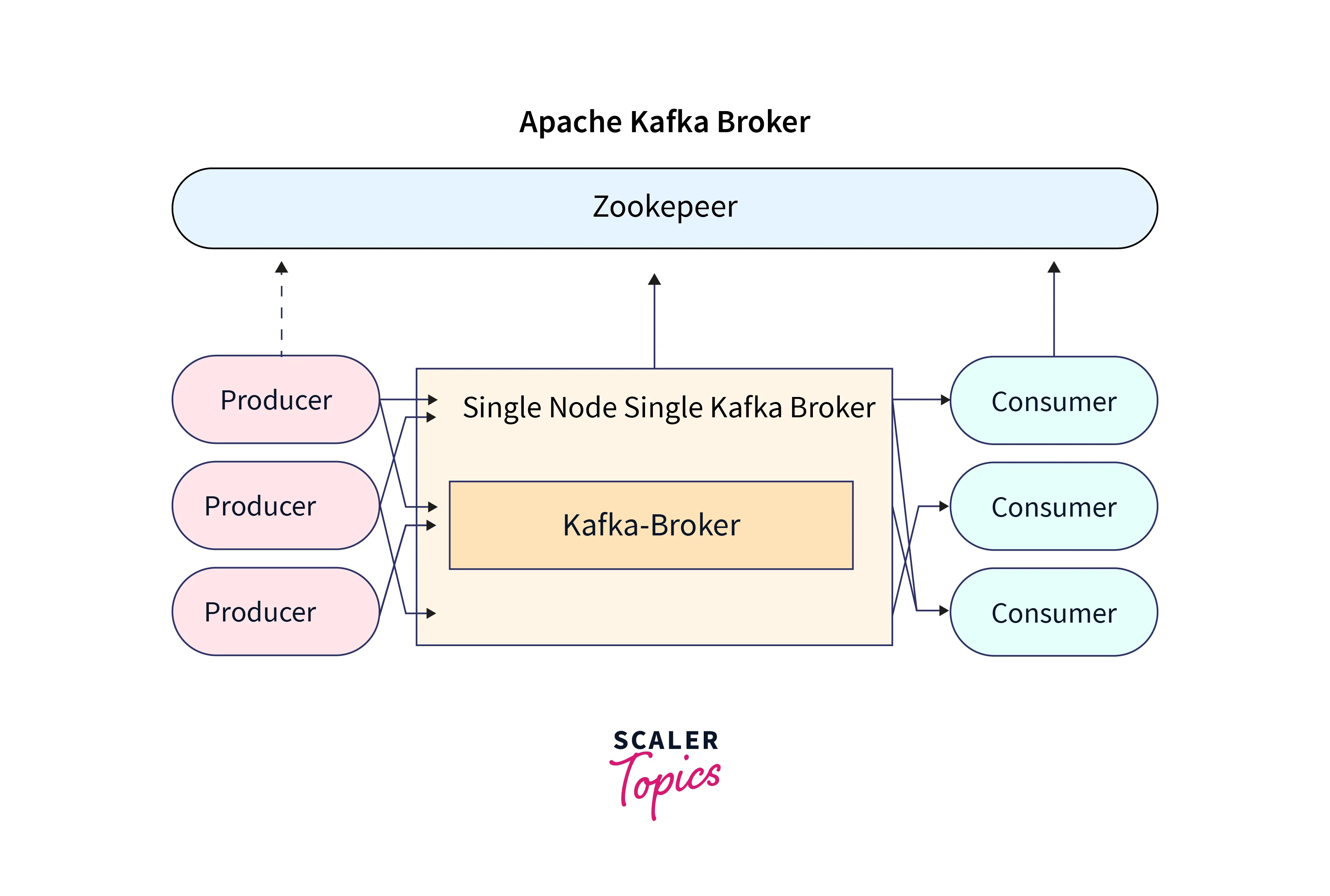
As seen in the illustration above, the Kafka broker is used for managing the storage of the data records/messages in the topic. It can be simply understood as the mediator between the two. We define a Kafka cluster when there is more than one broker present. The Kafka broker is responsible for transferring the conversation that the publisher is pushing in the Kafka log commit and the subscriber shall be consuming these messages. The conversation is mediated between the multiple systems, enabling the delivery of the data records/ message to process to the right consumer.
Kafka Producer:
The Kafka Producers as the one from where the users can publish, push messages, or writes the data records to the topics within various partitions. It is automatically detected by the producers about what data must be written at which of the partition and broker. The user doesn't need to define the broker and the partition.
Kafka Consumer:
We can describe a consumer as one who is subscribing to the records or messages that are being pushed into the Kafka cluster in a topic via the producer. The subscriber is well aware of the broker, from where it shall read the data. It reads the data within every partition as an ordered sequence. It can also read from various brokers at the same time like a subscriber will not read the data from offset 1 before it starts reading from offset 0.
ZooKeeper:
- We know that with ZooKeeper users get an in-sync view for their Kafka cluster while Kafka is primarily implemented for handling the real connections from the producers and subscribers. But if we want to understand how is Kafka managed between its brokers as well as clients and maintain the track of more than one broker at once. Well, it's entirely with the help of the Zookeeper.
- The metadata in Kafka is managed by the Zookeeper. Here, Zookeeper maintains track of all the brokers n the Kafka cluster. With the Zookeeper, it is easier to regulate which broker is taking the leader position for the specific partition and the topic along with performing the leadership elections.
- It helps to store the configurations for the permissions and topics. Every modification is tracked where the Zookeeper sends the notifications to Kafka as a broker dies, deletes topics, a new topic, a broker comes up, etc.
Kafka Topic:
- To start with, the Kafka topic can be defined as a division implemented for classifying messages or data records. The topic name is unique across the entire Kafka cluster. This means that messages are read and sent from defined Kafka topics only. So consumers read data from topics and producers are writing the data to topics.
- This is analogous to the table we have inside the database in a traditional RDBMS system. So, as we have multiple tables inside a single database, similarly we can have multiple topics inside Apache Kafka. The number of topics is not limited and can be easily identified by their unique name.
Kafka Offset:
- Once the topics are split into various Kafka partitions in Apache Kafka, each of the partitions needs to be assigned a defined ID to it, so that it is easier to recognize in a specific partition. As the Kafka partitions are containing the data records or messages, each of these messages within a partition needs to be assigned an incremental ID. This incremental ID is concerning the position, the message holds inside the Partition. This specific ID has defined an Offset.
Consumer Group
- We can describe a consumer group as a group of various consumers who are subscribing to the message as an application. Every consumer that is residing in any of these consumer groups shall be directly reading the message from the specific partitions that are defined for it.
- When a scenario arises where the number of consumers is comparatively more than the number of partitions, the remaining unassigned consumers stay in the inactive state. And during any disaster, if any, it is this inactive subscriber that takes up as the active subscriber within the group to read the message.
Kafka APIs
Four important APIs which is widely used in Kafka's architecture are described below:
- Producer API: For publishing a stream of data records to a Kafka topic, Kafka uses the producer API.
- Consumer API: For subscribing to Kafka's topics and processing their streams of data records, Kafka uses the consumer API.
- Streams API: With the Streams API, Kafka authorizes the systems to work as stream processors. Here, the input stream is taken up from the topic which is then transformed into the output stream transferring the data records across various output topics.
- Connector API: With the Connector API, any external system or application can be easily integrated with the Kafa architecture. The stems can be automated with the data system to any of their current Kafka topics.
For a more in-depth understanding of the topic of Kafka's Architecture, you can visit the article: Kafka's Architecture
How Kafka Works?
Before we head towards understanding what is Kafka used for and how it works, it is crucial to understand the concept on which Kafka worked.
When we define a Messaging System, we need to highlight that, it is an end-to-end system that carries (or transfers) the data from one system to another to support the seamless data movement from source to target without worrying about the process of sharing the data. The method where the message is transferred in a distributed manner is positioned on the concept of reliable message queuing. The messaging pattern followed by Kafka is the combination of asynchronous point-to-point and publish-subscribe (pub-sub) messaging systems.
When the message persists in the queue, that messaging system is referred to as the point-to-point system. Here, one specific message can be consumed by one consumer while many consumers can be subscribed to consume the remaining messages in the queue. Also, once a message is read, it disappears from the queue. The publish-subscribe messaging system can be described as a process where the messages are persisted in a topic, which can be consumed only when the consumers subscribe to it. Though consumers can subscribe to more than one topic and consume all the messages. Here, the messages produced by the producers are called publishers while subscribers are the message which the consumers consume.
Below is the pictorial representation of both the messaging system on which Kafka works.
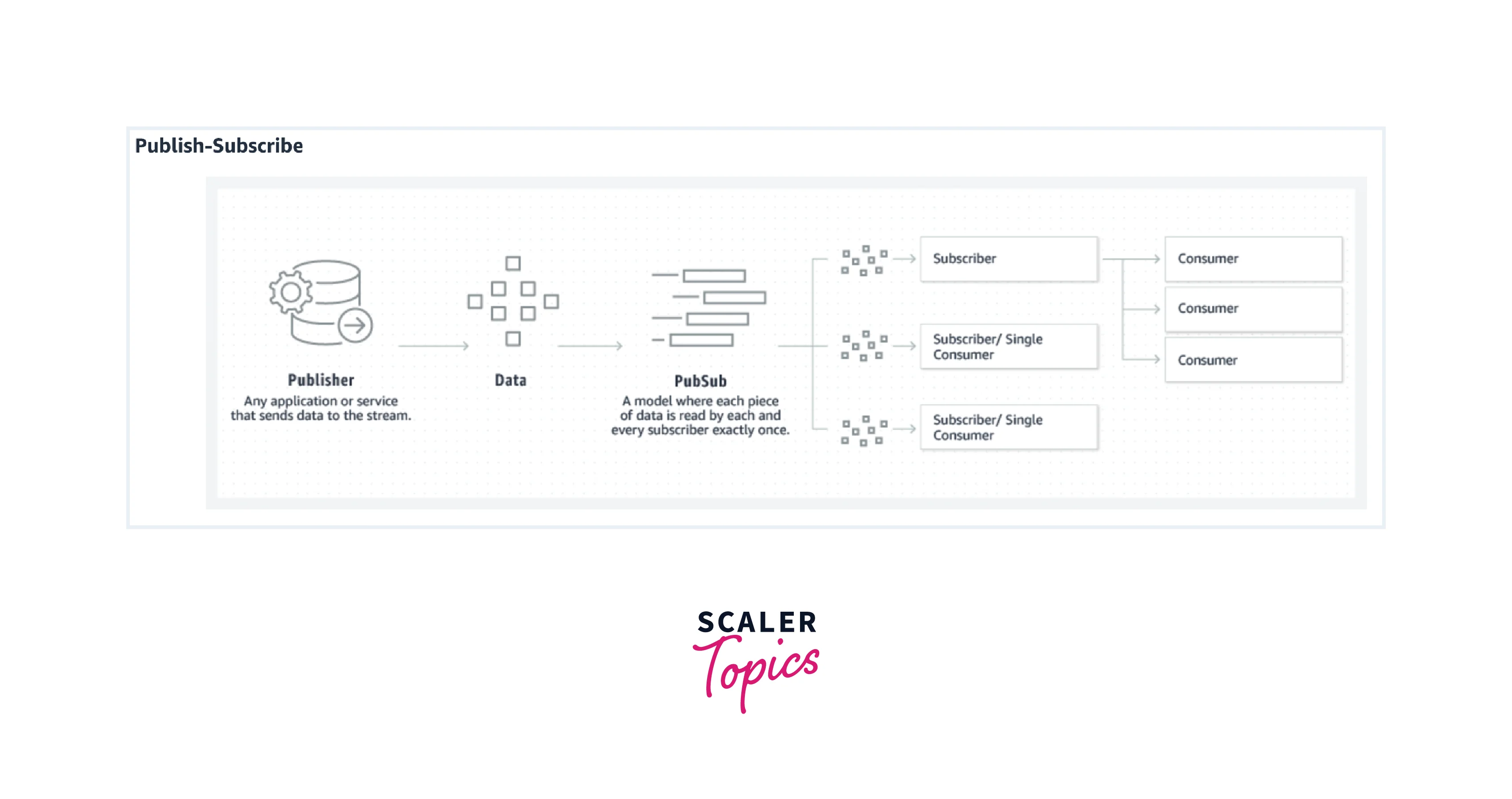
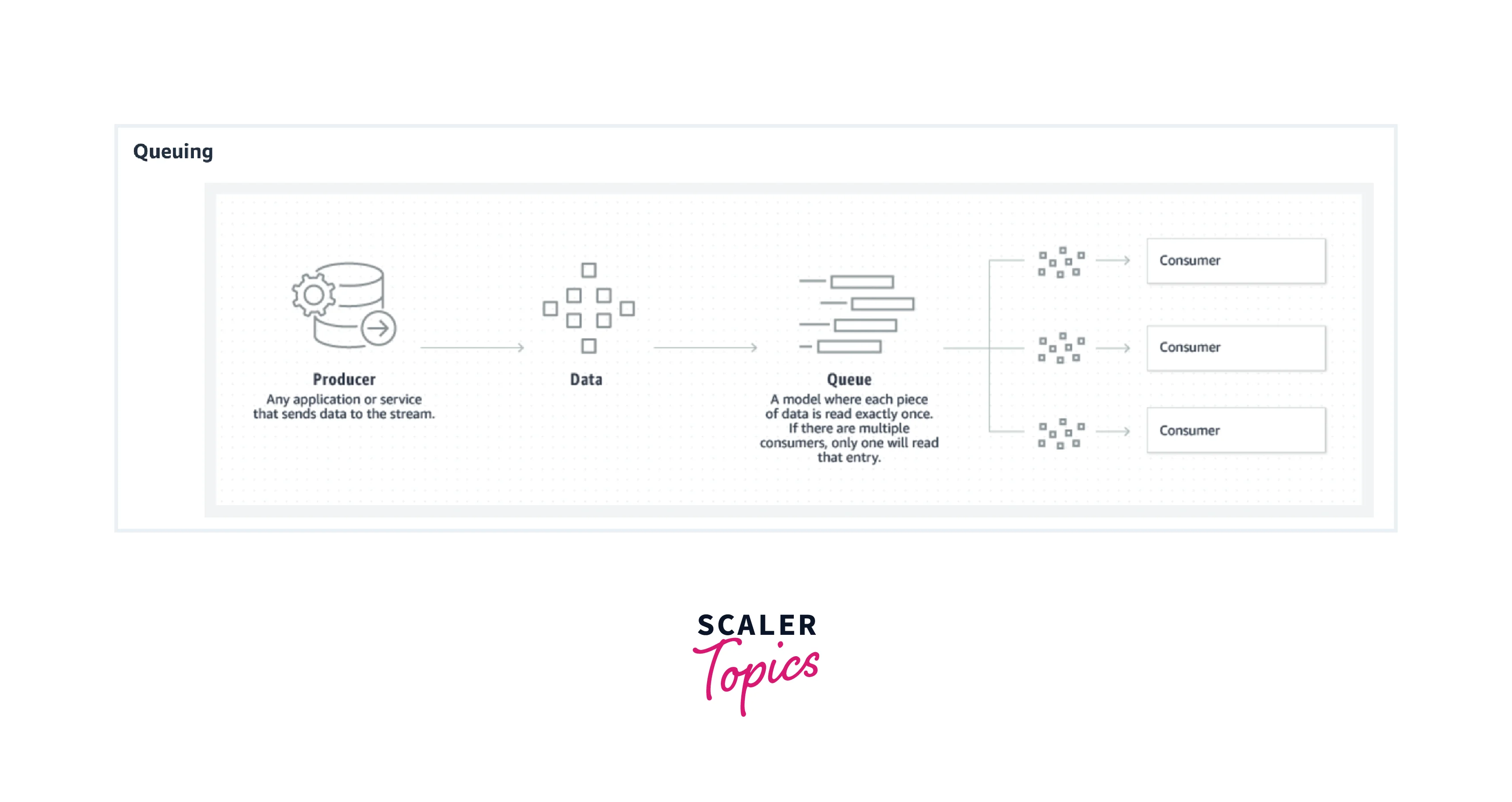
- To provide all the key benefits to its users, Kafka pics the pros of both types of messaging systems. While the point-to-point queuing messaging systems offer distributed data processing across various consumer instances, the publish-subscribe messaging system does help Kafka become highly available so that the messages can be subscribed to by various consumers.
- With the publish-subscribe messaging system, Kafka allows each message to reach each of its subscribers, while not allowing the work to be distributed across various workers. Hence, to combat this Kafka utilizes the partitioned log commit model which helps to bind the two messaging systems together.
- As we know, a log captures the messages as an ordered sequence of data records which always append the data records at the end. These log commits can be broken up into multiple partitions, and correspond to various subscribers. This allows multiple subscribers to utilize the same topic at a time while offering high scalability as each is assigned a partition.
- In short, Apache Kafka offers replayability, allowing various independent systems to seamlessly read and work as per their requirement from the data streaming in its queue without any hassle.
Conclusion
- With Kafka data can be processed in multiple pipelines consisting of various stages, while the raw data is input and consumed from Kafka topics and eventually gathered, enriched, or transformed as new topics for further data consumption or processing.
- A consumer group is a group of various consumers who are subscribing to the message as an application.
- Every consumer that is residing in any of these consumer groups shall be directly reading the message from the specific partitions that are defined for it.
- Kafka is a highly distributed offering high throughput and great performance system.
- The Kafka Producers as the one from where the users can publish, push messages, or writes the data records to the topics within various partitions. It is automatically detected by the producers about what data must be written at which of the partition and broker.
- Kafka is open-source software with a publish-subscribe messaging system and a robust queue that can efficiently manage the huge volume of streaming data from its source to destination.