What is the Difference Between Kafka and Spark?
What is the Difference Between Kafka and Spark?
While Spark is utilized for large-scale data processing, analytics, and machine learning, Kafka is primarily used for real-time data streaming and event processing.
There are primarily two categories of data processing use cases:
- When processing static data, it is either done all at once as a single task or in discrete batches. The fundamental data is processed here without any changes or additions.
- Where the data is generated as a stream, processing occurs as and when it is created. (This is known as stream processing)
As a result, Spark was designed to support both types of data processing, and Kafka is an integral part of Spark's streaming component. Compared to other distributed data processing engines, Apache Spark is quick and is built on the JVM. (Like Hadoop). According to Spark, it can "Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk," which is its strongest boast about performance. Due to in-memory processing, which reduces the amount of IO operations.
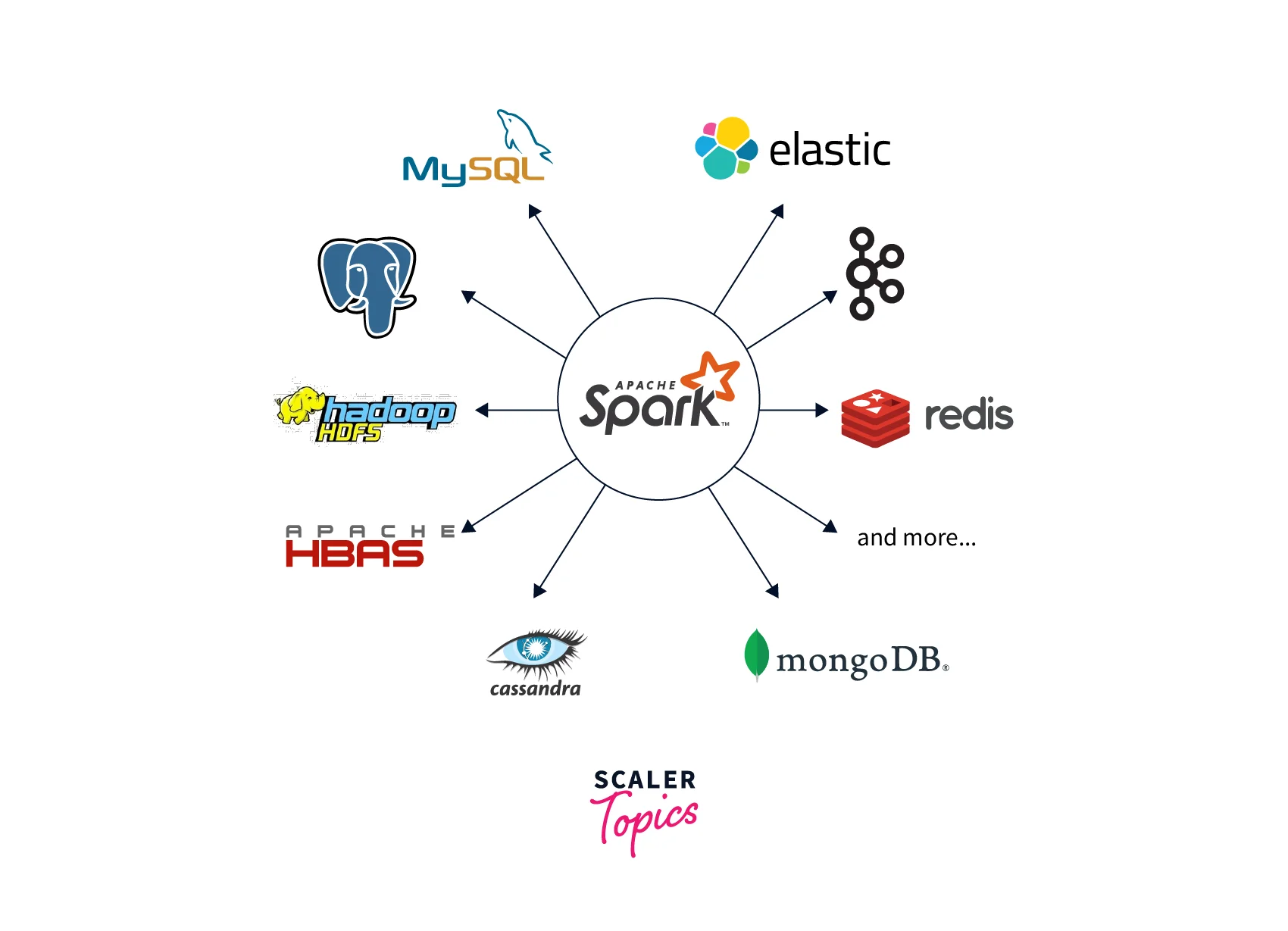
On top of Spark Core, which is the foundation of Spark, the following components are built, each for a particular data processing workload:
- Spark SQL is used for both interactive and batch data processing.
- Real-time stream data processing is done using Spark Streaming.
- For machine learning, use Mlib (Machine Learning Libraries).
- GraphX is for processing graphs.
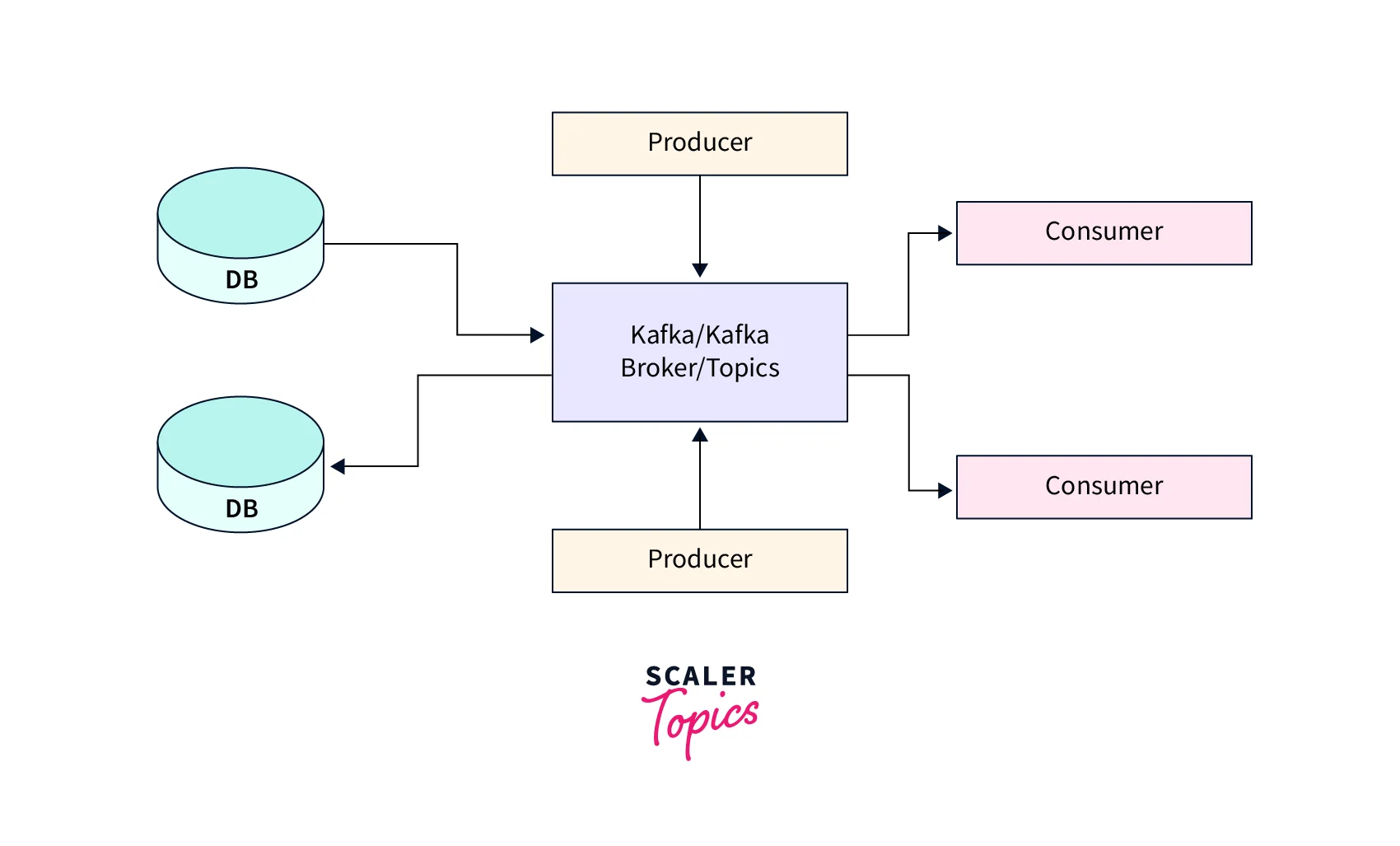
A stream processing engine called Kafka serves as one of the input sources for the Spark streaming component. (Others include Flume, Flink, Storm, Apex, etc.,). A distributed publish-subscribe messaging system called Apache Kafka has transformed into a distributed streaming platform.
For processing messages, publish-subscribe message queueing systems are typically utilized. Due to the enormous amount of messages that must be processed each second to meet the requirements of large-scale data processing applications, older message queueing systems were unable to perform. Large publish-subscribe data may be processed with Kafka.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
What is Apache Kafka?
Kafka is used for real-time analytics, huge data collecting, real-time streaming, or any combination of these. Kafka is further utilized with in-memory microservices to offer stability. Microservice architecture, or simply microservices, is a different approach to constructing software systems that focuses on creating single-function modules with well-defined interfaces and activities. Kafka is used for real-time data streams, massive data collection, or real-time analysis. (or both). Kafka may be used to feed events to CEP (complex event streaming systems) and IoT/IFTTT-style automation systems, as well as to offer durability for in-memory microservices.
The application also utilizes one or more servers to run. Each node in the Kafka cluster is hence referred to as a port. As demonstrated, Apache ZooKeeper is used by Kafka to maintain groups. specifically assists consumer applications in reading data from topics and producer applications in writing data to topics.
At the same time, themes are broken up into manageable pieces, and Kafka makes sure that each piece is consistently organized.
Apache Kafka is a robust and widespread distributed streaming technology that offers organizations several advantages and benefits.
- Kafka is built to be extremely scalable, allowing organizations to manage massive amounts of data and traffic without sacrificing speed. By adding more brokers to the Kafka cluster, it may grow horizontally.
- Kafka can handle millions of messages per second, making it ideal for real-time data streaming and analytics that demand high throughput and low latency.
- Kafka is extremely fault-tolerant, which means it can keep running even in the face of node failures or network difficulties without compromising data integrity.
- Kafka saves data in a distributed log, which assures persistence and that data is never lost, even if the system fails.
What is Apache Spark?
Large data loads are processed using Spark, an open-source processing technology. Therefore, the improvement of the in-memory cache and quick analytical searches for data of any size are advantages. It also makes use of Java, Python, and Scala APIs. It also offers code reuse for a variety of workloads, including batch processing, real-time analytics, machine learning, and graphics processing.
Spark is a general-purpose open-source processing solution for managing large data loads. Memory caching and query optimization for speedy analytic searches on data of any size, however, are additional benefits.
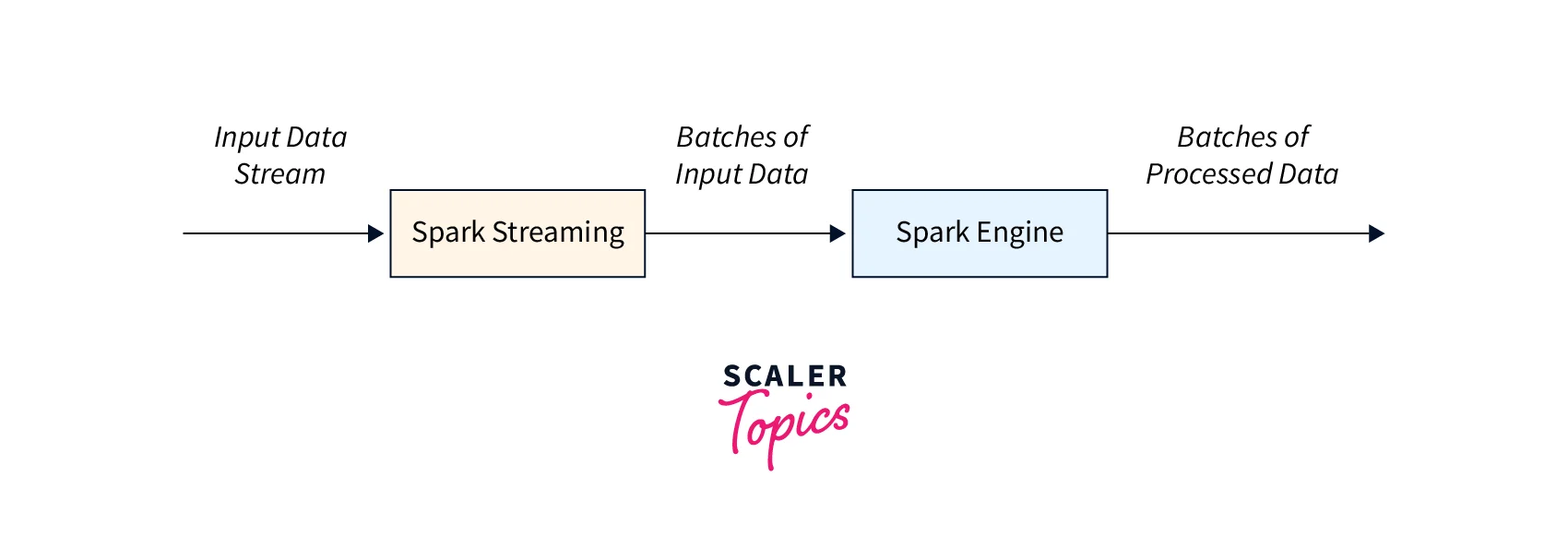
Apache Spark is a distributed computing platform that offers several advantages and benefits to organizations. Here are some of the benefits of using Apache Spark.
- Spark is extremely scalable and can extend horizontally by adding additional nodes to the cluster, making it suited for use cases requiring massive amounts of data to be handled.
- Spark offers a simple API that supports numerous programming languages, including Java, Python, and Scala, making it simple for developers to create and deploy applications.
- Spark provides a diversified set of use cases, including batch processing, real-time processing, machine learning, and graph processing, making it an adaptable framework for dealing with a variety of workloads.
- Spark is fault-tolerant, which means it can withstand node failures while maintaining data integrity, giving it a dependable framework for processing huge amounts of data.
Kafka Streams Vs. Spark Streaming: Key Difference
Apache Kafka vs Spark: ETL
- In the extract phase of ETL, data is collected from various sources, such as databases, log files, social media, or other mediums as well.
- Apache Kafka comes in the extract phase so that it can handle large sizes of data in real time. Kafka can collect data from several sources, it can store the data temporarily and then make it available for further processing.
- Apache Spark is used in the transform stage, as it provides a powerful interface for programming parallel data processing pipelines. It can handle both types of processing which is batch and streaming. It can be used for data transformations, such as filtering, joining, aggregating, or pivoting data.
- Apache Kafka can be used in the loading stage so that it can transmit data to multiple systems in real-time.
Apache Kafka vs Spark: Latency
- Latency is a measure of how long it takes for data to be transmitted from one system to another.
- The key difference between Apache Kafka and Apache Spark in terms of latency is that Kafka is optimized for low-latency data streaming and messaging, while Spark is optimized for in-memory processing.
- Kafka achieves low latency by using a distributed architecture and stores data in memory, which makes it fast and efficient for processing and transmitting data from the source to the target system.
- Spark also has the same feature as Kafka of low latency by using an in-memory computing engine that allows for fast processing of data. But the latency of Spark depends on the complexity of the data processing and the size of the data being processed.
Apache Kafka vs Spark: Recovery
- Kafka has a feature named replication which ensures that data is available in the event of a failure.
- When a message is published to a topic, it is replicated across multiple brokers in the Kafka cluster. If one broker fails, another broker can that place and continue serving data from the replicated data on other brokers.
- Spark is designed for fault tolerance and high availability, and it uses a feature called RDD (Resilient Distributed Datasets) to recover from failures.
- For example a Spark job is running and that is processing data from a large dataset. If one of the nodes in the Spark cluster fails during the processing, the RDD feature allows Spark to recover the lost data and continue processing from the last known good state.
- This ensures that the processing job can continue without data loss, even in the event of a failure.
Apache Kafka vs Spark: Processing Type
- Apache Kafka is a distributed streaming network that primarily serves as a platform for real-time data processing. It is built to handle high-throughput, low-latency data streams, making it perfect for data input, event processing, and real-time analytics.
- Producers post messages to topics, while consumers subscribe to those topics to consume the messages.
- In contrast, Apache Spark is a distributed computing platform that enables both batch and real-time processing. Its main applications include large-scale data processing, analytics, and machine learning.
- Spark employs the RDD (Resilient Distributed Datasets) processing model, which enables distributed data processing over several nodes. Spark has a robust API that supports a variety of programming languages, including Java, Python, and Scala.
Apache Kafka vs Spark: Programming Languages Supported
- Kafka does not support any programming language for data transformation, in contrast to Spark, which is recognized for supporting a broad variety of programming languages and frameworks.
- In other words, Apache Spark is capable of more than just understanding data since it processes graphs and makes use of current machine learning frameworks.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Kafka VS Spark Comparison Table
| Spark | Kafka |
|---|---|
| 1. For processing, live input data streams are divided into micro-batched data | 1. Real-time window processing is used in processing. |
| 2. There must be a unique processing cluster. | 2. There is no need for a separate processing cluster. |
| 3 Needs to be reconfigured for scaling. | 3. Simply adding more Java processes allows for easy scaling; no reconfiguration is necessary. |
| 4. Spark streaming processes groups of rows better. (group by, ml, window functions, etc.) | 4. True record-at-a-time processing capabilities are offered by Kafka streams. It works better for tasks like cleansing data and row parsing. |
| 5. Kafka keeps data in topics or a memory buffer. | 5. Resilient Distributed Datasets known as RDD is used by Spark to store data in a distributed fashion. (i.e., cache, local space) |
| 6. A separate framework is Spark streaming. | 6. Given that Kafka Stream is only a library, it may be included in microservices. |
Combining Kafka with Spark
The following are some of the advantages of combining Kafka with Spark:
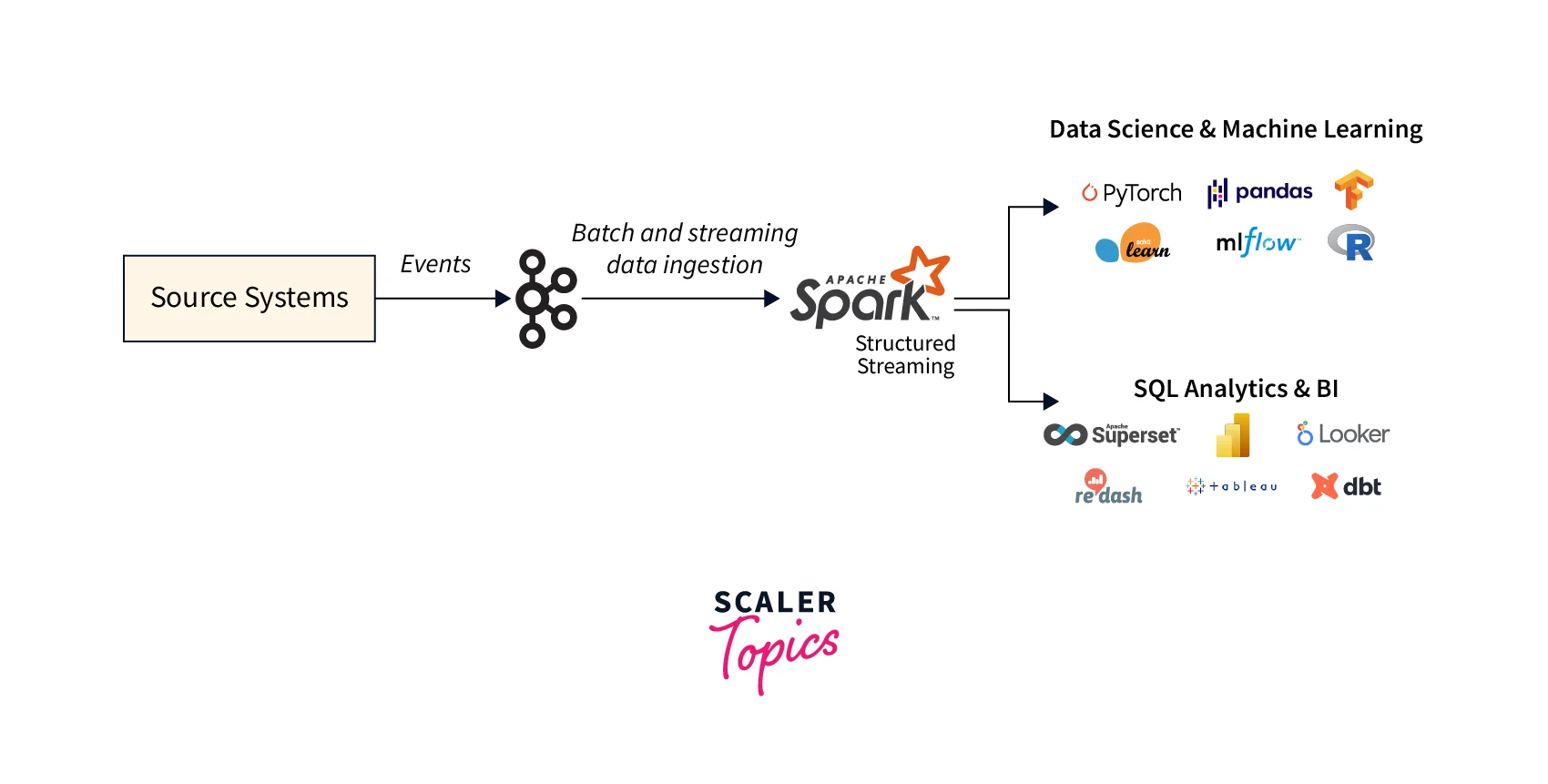
- Scalability: Kafka and Spark are both designed to be extremely scalable and capable of handling massive volumes of data without sacrificing speed.
- Real-time data processing: Kafka and Spark enable you to process and analyze data in real-time, allowing you to take rapid action based on data insights.
- Fault-tolerance: While Spark's RDD ( Resilient Distributed Datasets) lineage assures that processing may continue even if a node fails, Kafka's data replication makes sure that the data is not lost even if a broker fails. These two technologies work together to provide a highly fault-tolerant data processing pipeline that can manage errors and protect data integrity.
- Versatility: Because Kafka and Spark may be used with a broad variety of data sources and applications, they are flexible data processing and analytics tools.
Conclusion
- The two most well-liked data processing tools from the Apache Foundation are included in the article.
- Before deciding on Spark or Kafka, you will learn about their advantages and major differences that may help you make better choices and process information for a variety of requirements.
- As a message broker, Kafka may be used. It can keep the data for a set amount of time. We can conduct real-time window operations using Kafka.
- However, ETL transformations cannot be performed in Kafka. We can use Spark to persist data in data objects and execute end-to-end ETL operations.
- Kafka is a distributed streaming platform that handles massive volumes of data in real-time in a dependable, scalable, and fault-tolerant manner. In contrast, Spark is a distributed computing system that provides high-speed data processing and analysis.
- Kafka and Spark, when used together, may provide a full solution for real-time data processing, streaming analytics, and machine learning.
- Kafka serves as a message broker between many data sources, whereas Spark can ingest and analyze data in real-time.