Exploring Kafka and Zookeeper: The Symbiotic Relationship in Distributed Systems
Overview
Exploring Kafka and ZooKeeper reveals how well they work together to build stable and scalable distributed systems. While Apache ZooKeeper serves as a central coordination service for controlling group membership and synchronisation, Apache Kafka is a distributed event streaming platform for real-time data integration. Together, they make fault-tolerance, fault-tolerant distributed systems, and high-throughput communications possible.
What is Apache Kafka?
Apache Kafka is a free-source distributed event streaming platform ideal for real-time data handling in pipelines, messaging systems, and streaming applications.
Producers post messages to topics, while consumers subscribe to those topics to receive and process the messages. It offers a long-lasting, fault-tolerant, and high-throughput architecture that enables real-time data processing and integration across multiple systems and applications.
Organizations utilize various tools like CRM, websites, accounting, and billing to gather information, requiring engineers to create custom connectors for a unified business perspective.
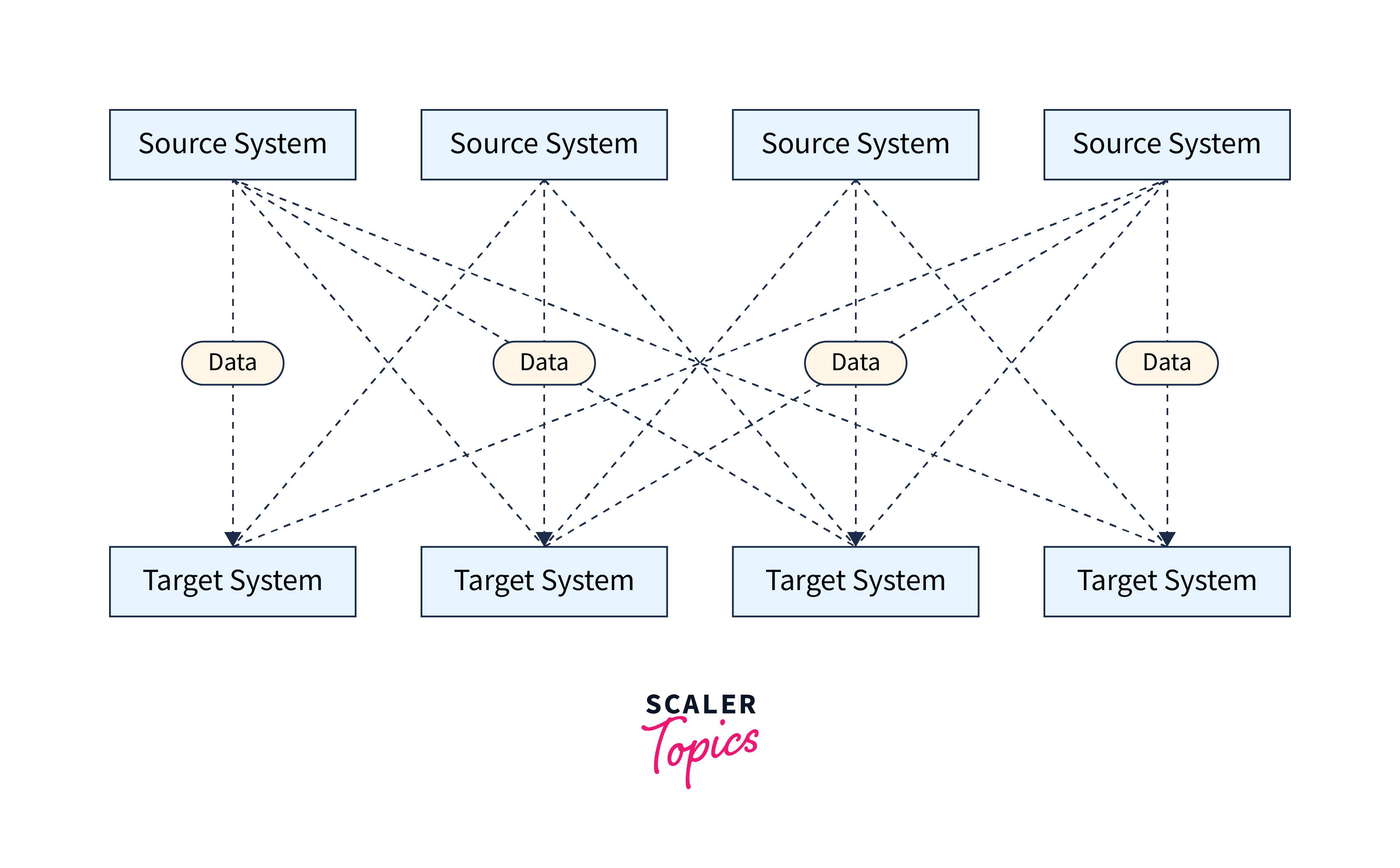
Each integration has specific challenges.
- The data transfer methods include TCP, HTTP, REST, FTP, and JDBC.
- Data format: The method used to parse the data (Binary, CSV, JSON, Avro)
- Evolution of the data's schema and how it is shaped
Data sources will publish their data to Apache Kafka using Apache Kafka as a data integration layer, and target systems will source their data from Apache Kafka. As seen in the image below, this separates source data streams and destination systems, enabling a more straightforward data integration solution.
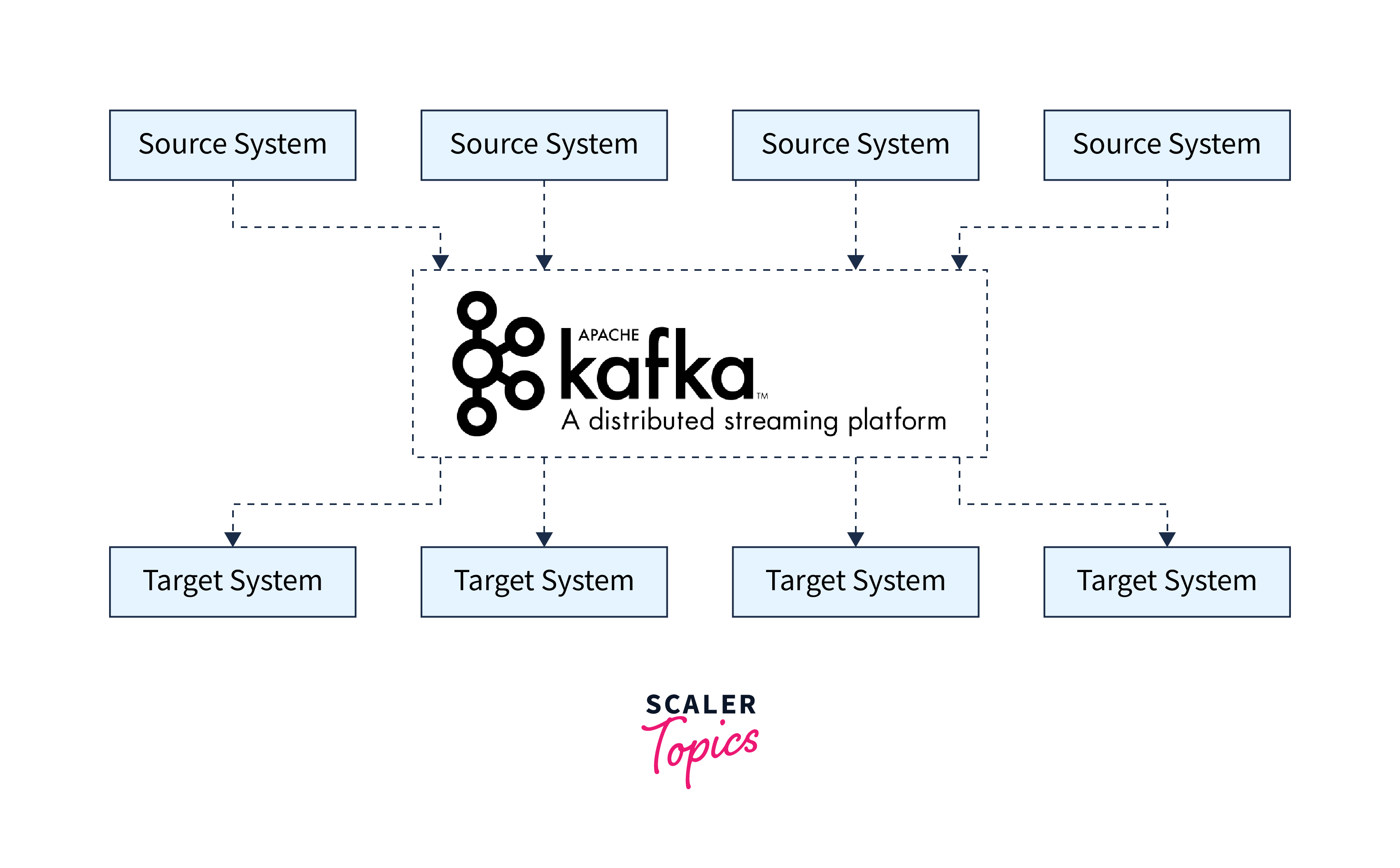
What does Apache Kafka Define as a Data Stream?
Typically, a data stream is viewed as a possibly infinite stream of data. The term "streaming" is given that we want the data to be available as soon as it is created.
Every application that generates data inside a company can produce data streams. Data streams often produce small amounts of data. Data streams' throughput varies greatly; some receive tens of thousands of records per second, while others only get one or two records per hour.
These data streams, also known as topics, are stored using Apache Kafka, allowing computers to execute stream processing—the act of executing continuous computations on a theoretically infinite and continuously changing source of data. The stream may be moved to another system, such as a database, once it has been processed and stored in Apache Kafka.
What Applications that Make Use of Apache Kafka Are There?
Some of the well-known stream processing frameworks, such as Apache Flink and Samza, use Apache Kafka as their storage system.
- Communication systems
- Activity Monitoring
- Collect metrics from a variety of sources, such as IoT devices.
- Examination of Application Logs
- Splitting apart System Dependencies
- Integration of Hadoop, Spark, Flink, and other big data technologies.
- Shop for Event Sourcing
Definition of Core Apache Kafka Concepts
- Topics: Groups or feeds from which consumers can access and consume messages.
- Producers: Software applications that post messages to Kafka topics.
- Applications that subscribe to (read from) and process messages from Kafka topics are called consumers.
- Brokers: Kafka servers that handle message management, data replication, and dissemination.
- Partitions: Areas inside a topic that divide and process messages concurrently.
- Consumer Groups: A logical arrangement of consumers who cooperate to read messages from a topic concurrently.
- Replication: Data duplication across many brokers for fault tolerance and high availability is known as replication.
What is Apache Zookeeper?
A distributed coordination service called Apache ZooKeeper offers a centralized infrastructure for managing group membership in distributed systems, providing distributed synchronization, and keeping configuration information.
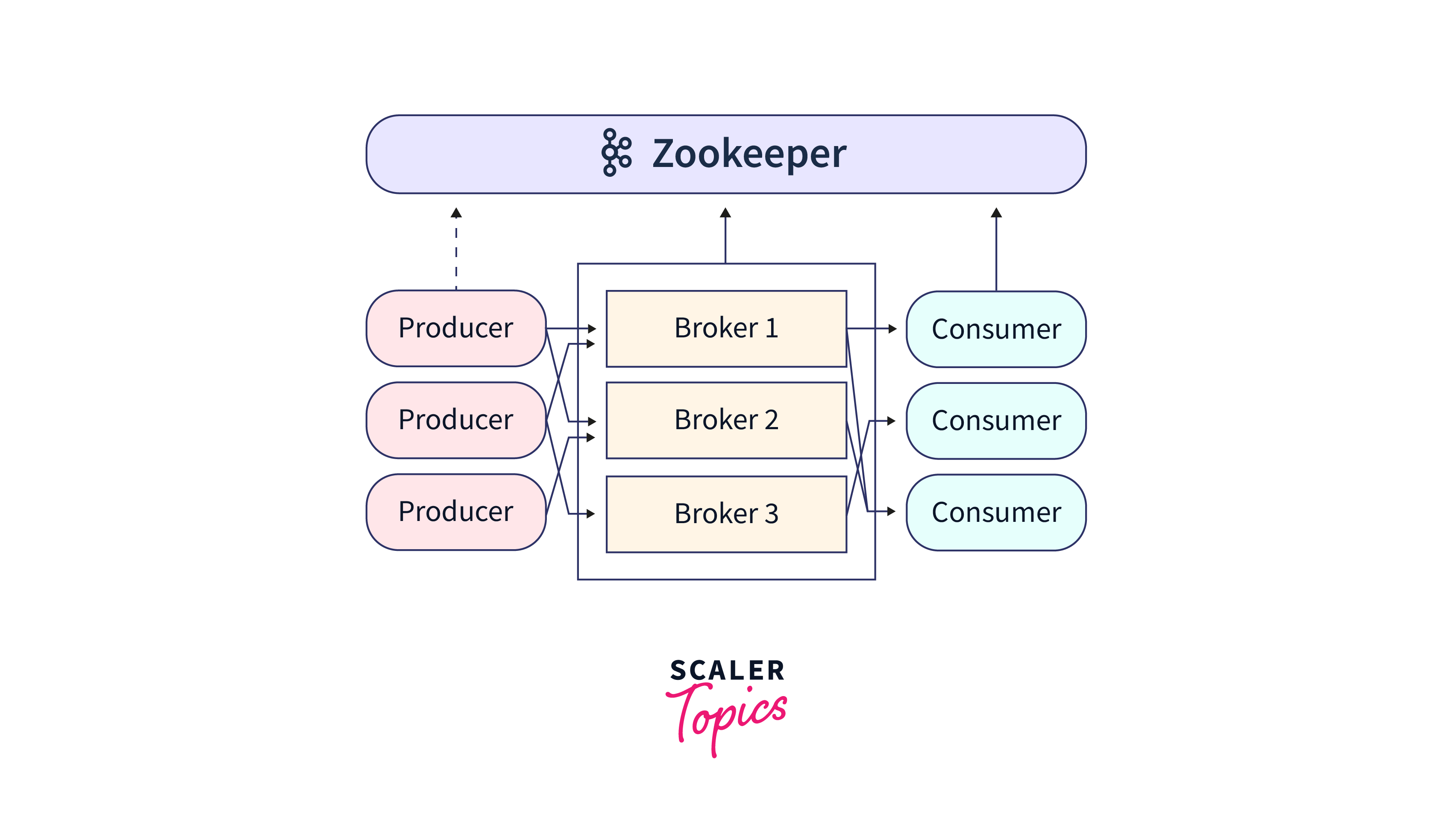
To coordinate and synchronize dispersed applications, ZooKeeper essentially serves as a centralized control system. In a distributed system, it enables several nodes to concur on a common state and coordinate their actions.
Components of Zookeeper Architecture That are Commonly Used
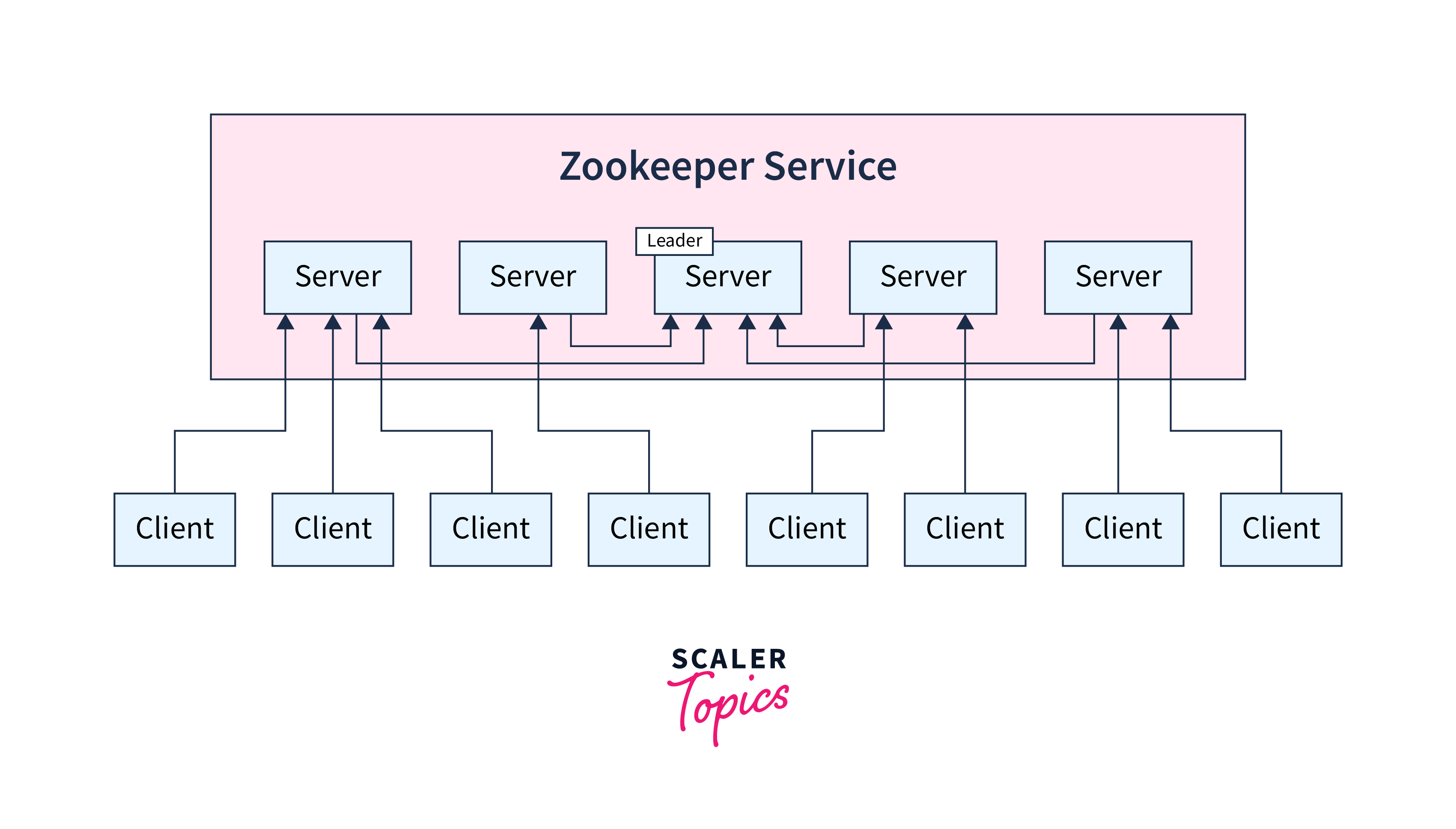
- Node: The cluster's systems that are installed
- ZNode: The nodes in a cluster for which other nodes update their state.
- Application by clients: Systems that connect to distributed applications
- Applications for servers: It enables communication across client apps utilizing a standard interface.
The Role of Zookeeper in Kafka
- State: The status is decided by the zookeeper. That means when it consistently makes heartbeat queries, it always detects if the Kafka Broker is alive. The Broker must be able to obey replication requirements even though it is the constraint for handling replication.
- Cluster Management: ZooKeeper keeps track of the Kafka cluster's metadata, such as the list of available brokers and the details of their connection. When a Kafka broker launches, it registers with ZooKeeper, and ZooKeeper manages the cluster's active brokers.
- Election of Leader: ZooKeeper manages Kafka's leader election process, selecting a replacement leader from available brokers when a partition leader becomes unavailable, ensuring one broker remains the leader.
- Broker Registration: Kafka brokers sign up with ZooKeeper and build ephemeral znodes to signal cluster existence. Broker failures or disconnections erase these znodes, allowing other brokers and clients to notice unavailability.
- Synchronizing of Metadata about Kafka Topics, Partitions, and Replicas: ZooKeeper stores and synchronizes metadata for objects, enabling brokers and clients to query for the latest information on partition leaders and available partitions.
Setting Up Kafka with Zookeeper
The cluster's Kafka components are managed by Apache Kafka using Zookeeper. ZooKeeper is a centralized service that offers group services, distributed synchronization, configuration information maintenance, and naming. Distributed applications make use of all of these services in some capacity. A reliable file system for configuration data is called ZooKeeper.
- Download and extract Kafka.
Download the Kafka distribution package for your operating system from the Apache Kafka website https://kafka.apache.org/downloads.
Extract the downloaded file to your preferred location.
- Start ZooKeeper
ZooKeeper is used by Kafka for coordination. Go to the Kafka directory in a terminal when it is opened.
- Setup Kafka
- Navigate to the Kafka directory in a new terminal.
- Modify the server.properties file in the Kafka server setup to meet your needs.
- Make sure that you set up the zookeeper. To make a connection to a ZooKeeper instance, use the connect attribute. It has been set to localhost:2181 by default.
- Make Topics
Navigate to the Kafka directory in a new terminal. To create a topic, use the following command:
List the topics
As needed, change the --topic name, --partitions, and --replication-factor values.
- Produce and Consume Messages
The messages for the topic are written by the producer. The consumer consumes the topic's messages.Apache Kafka has a client for accessing the producer and consumer APIs.
produce the message
consume the messages
Performance Considerations with Kafka and Zookeeper
Kafka Performance Considerations:
- Select high-performance servers with appropriate CPU, RAM, and disc I/O capacity for Kafka implementation. SSDs are suggested for improved I/O performance.
- When configuring partition and replication factors in Kafka, keep the trade-off between throughput and fault tolerance in mind.
- Optimise producer setup by altering the batch size, linger duration, and compression parameters based on workload variables.
- Tune consumer setup to limit message consumption rate and guarantee efficient processing.
- Instead of JSON or XML, use efficient serialization formats such as Avro or Protobuf to improve speed and eliminate network overhead.
- Reduce network latency by placing Kafka brokers and consumers close to one another.
- Monitor Kafka metrics (throughput, latency, disk utilization) regularly and optimize with tools like Kafka Streams or Confluent Control Centre.
ZooKeeper Performance Considerations:
- Choose high-performance servers with sufficient resources for ZooKeeper deployment, including consideration for SSDs.
- Maintain a small ensemble size (typically three or five) for fault tolerance without impacting performance.
- Adjust tickTime and syncLimit based on workload and ensemble size to balance responsiveness and overhead.
- Optimize the data model to minimize znodes and data stored in each znode, avoiding frequent updates.
- Configure the network to minimize latency and avoid congestion for ZooKeeper communication.
- Monitor metrics like request latency, follower lag, and ensemble size, and adjust configuration parameters accordingly.
Future of Kafka and Zookeeper
The migration of Kafka from ZooKeeper to KRaft has various advantages, including architectural simplicity, greater scalability, and speedier failover capabilities.
Architectural Simplification:
- Kafka used ZooKeeper as an external coordination service for distributed consensus and metadata management. By embedding the coordination protocol directly into Kafka, KRaft eliminates this reliance.
- The elimination of ZooKeeper simplifies Kafka cluster setup and operation. Administrators no longer need to manage and maintain a separate ZooKeeper ensemble, which reduces the system's total complexity.
Increased Scalability:
- KRaft outperforms ZooKeeper in terms of scalability, especially in bigger Kafka installations.
- KRaft distributes metadata over several Raft groups, enabling simultaneous processing of metadata changes and decreasing the impact of metadata operations on overall cluster performance.
- Because of this segmentation, Kafka can manage much greater metadata update rates, resulting in enhanced scalability as the cluster expands in size.
Capabilities for Faster Failover:
- When compared to ZooKeeper, KRaft delivers quicker and more efficient failover capabilities.
- When a Kafka controller dies, the KRaft protocol provides for speedier leader election and transition, minimising downtime and impacting cluster performance overall.
- The shorter failover time improves Kafka cluster robustness by assuring little disturbance to data intake and consumption activities during controller failures.
Kraft:
- KRaft is based on the Raft consensus algorithm and is designed specifically for managing Kafka's metadata.
- Raft is a distributed consensus protocol that ensures consistency and fault tolerance among a group of nodes working together as a replicated state machine.
- Kafka's metadata, such as topics, partitions, and leaders, is stored and managed using the Raft protocol in KRaft.
- The metadata is divided into multiple Raft groups, with each group comprising a set of nodes responsible for replicating and coordinating metadata updates.
- The partitioning of metadata enables parallel processing of operations, leading to improved scalability in KRaft.
The following are the essential aspects of the KRaft protocol:
- Leader Election: KRaft guarantees that each Raft group elects a leader. The leader handles metadata update requests and organises replication with followers.
- Replication and Consistency: KRaft guarantees that metadata updates are copied consistently among the followers. In the event of a node failure, this replication offers fault tolerance and prevents data loss.
- KRaft conducts log compaction, which removes outdated and superfluous metadata items from duplicated logs. This procedure reduces storage needs while improving performance.
- KRaft regularly takes snapshots of the metadata state, enabling speedier recovery in the event of failures or cluster restarts.
Conclusion
- Apache Kafka is a distributed event streaming platform used for integrating various systems and applications while processing data in real time.
- Providing distributed synchronisation and configuration management for distributed systems, Apache ZooKeeper is a centralised coordination service.
- ZooKeeper is a key component of the Kafka ecosystem, managing the Kafka cluster, keeping track of information, performing leader elections, and providing fault tolerance.
- Starting ZooKeeper and configuring Kafka to connect to it are required steps in setting up Kafka with ZooKeeper. ZooKeeper, which supervises active brokers and tracks the cluster's information, registers Kafka.
- Kafka performance concerns include adjusting variables like the replication factor, number of partitions, and the number of replica fetchers to maximise throughput and replication efficiency.
- By limiting the number of nodes, practising isolation for security, and adjusting ZooKeeper for lower latency using suitable hardware and monitoring, the performance of ZooKeeper may be improved.
- Kafka's future entails moving away from ZooKeeper dependence and towards the use of KRaft, a new consensus mechanism that increases stability, streamlines Kafka's architecture, and allows for solo deployment of Kafka with increased scalability and resilience.