APIs for Distributed Training in TensorFlow and Keras
Overview
Have you pondered how terabytes of data are utilized for training sophisticated models with millions to billions of parameters? The size of such models can increase to the amount where they may not even fit in the processor's memory. So it becomes hard to train such models using conventional methods, and we need an alternative method that can handle such a memory-intensive task. In this article, we will have in-depth knowledge about the API of Distributive Training in Keras.
Introduction
Distributed Training is a technique for training machine learning models on multiple machines, either by splitting the data across multiple devices or by splitting the computational workload across multiple devices. This can be useful for training large models that would not fit on a single device or for training models more quickly by utilizing the computational resources of multiple devices.
TensorFlow and Keras are both deep learning frameworks that support Distributed Training. TensorFlow provides a low-level API for Distributed Training and a higher-level tf.distribute.Strategy API is built on top of the low-level API, making it easier to perform distributed Training.
Additionally, as mentioned before, Horovod can be used for distributed model training for TensorFlow and Keras. Therefore, it is a more efficient library for distributed Training that utilizes the distributed training capability of TensorFlow and Keras.
What is Distributive Training?
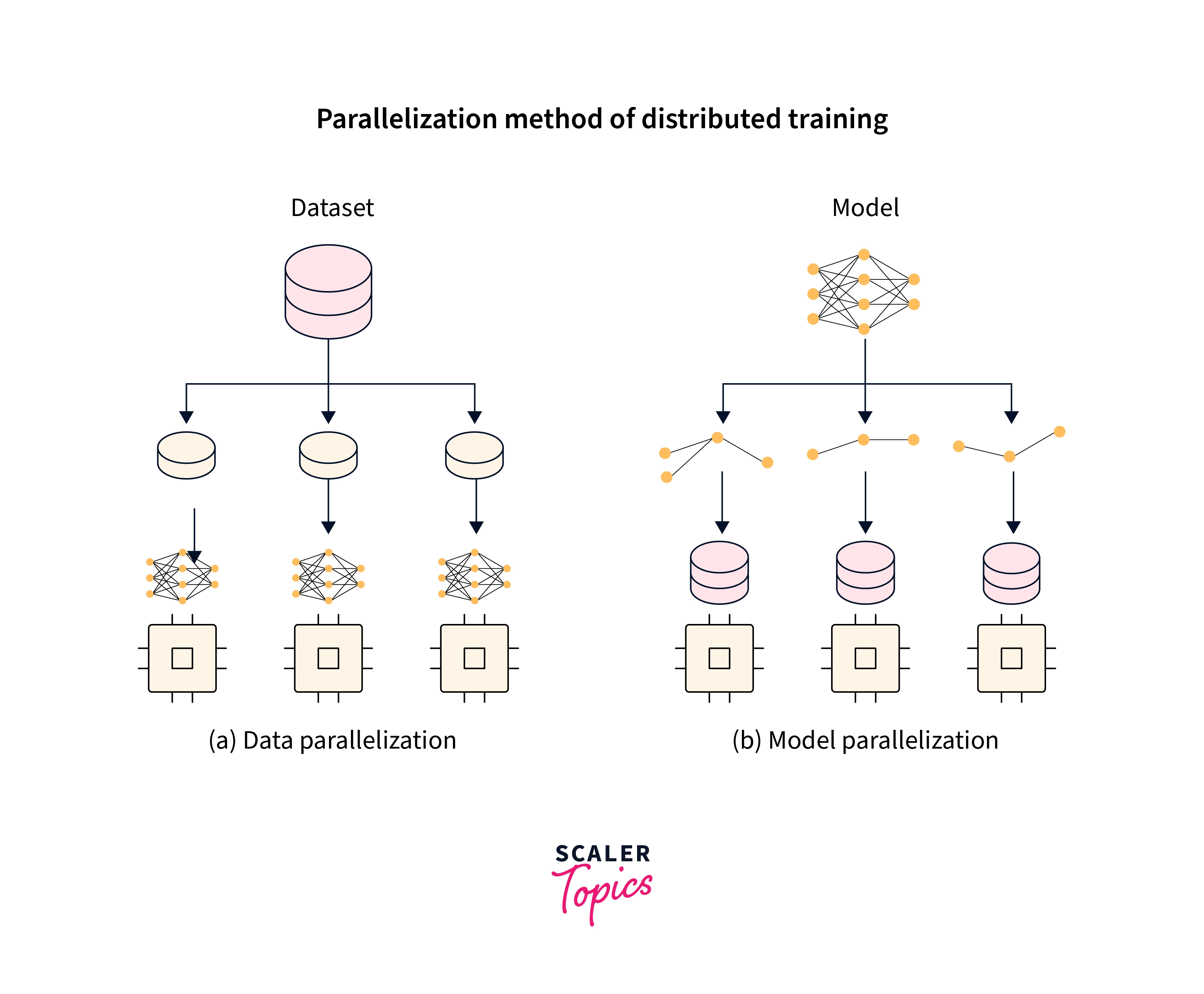
In any field, when confronted with a massive amount of work, we divide it into smaller tasks and complete them simultaneously. This allows us to save time and makes a challenging problem manageable. Distributed Training is the same process by which we train the Deep Learning model in more instances by Data or Model parallelism.
To be even more specific, Distributed Training means dividing the workload of training a massive deep learning model across several processors. Worker nodes, or simply workers, are the term given to these processors. To expedite the training process, these workers are trained concurrently. Data parallelism and model parallelism are the two main types of parallelism.
Data Parallelism: Models are duplicated across many data sets in data parallelism. Data parallelism: Models are copied onto various hardware (GPU) and trained on data sets in data parallelism.
Model Parallelism: When a model is too big to fit on a single system, it can be divided and spread across several.
What are the Different APIs for Distributed Training in TensorFlow and Keras?
There are several APIs available for distributed Training in TensorFlow and Keras:
- TensorFlow's native distributed training API: This API allows for distributed Training using data parallelism, model parallelism, and hybrid parallelism. It includes functionality for parallelizing computations, managing variables, and handling communication between devices.
- Keras's multi-worker training API: This API is built on top of TensorFlow's native distributed training API and provides a higher-level interface for training models using multiple workers.
- TensorFlow's Estimator API: This API provides a high-level interface for training models and includes built-in support for distributed Training.
- TensorFlow's DistributedStrategy API: This API allows users to specify the distribution strategy for their model and provides a high-level interface for training models using multiple devices and machines.
- Horovod: This open-source library allows for distributed Training using data parallelism and is compatible with TensorFlow and Keras.
- TensorFlow On-Premises: This allows for distributed Training on multiple machines within a single data center or on-premises cluster.
TensorFlow and Keras are updated frequently, so new options and features may be available. Therefore, checking the latest documentation for the most updated information is always good.
Multiple GPUs
Distributed Training with multiple GPUs in Keras and TensorFlow can be achieved using the MultiWorker MirroredStrategy or the ParameterServerStrategy.
-
MultiWorker MirroredStrategy: This strategy uses data parallelism. The same model is replicated on each GPU, and the weights are kept in sync through all-reduce communication during the forward and backward pass. This is useful when all the GPUs are located on a single machine.
-
ParameterServerStrategy: This strategy uses model parallelism, where different parts of the model are on different GPUs, and the parameter updates are communicated between the GPUs and a parameter server. This is useful when the GPUs are located on multiple machines.
You can use the tf.distribute to use these strategies with Keras.Strategy API. First, you must choose a strategy and create a tf.distribute.Strategy instance. Next, you can use the strategy.scope context to create your Keras model and call the compile() and fit() methods within the scope.
It's worth mentioning that TensorFlow also provides other strategies, such as TPUStrategy, MirroredStrategy, and CentralStorageStrategy, which have their use cases depending on the hardware and training requirements.
-
Multiworker Mirrored Strategy
The MultiWorker MirroredStrategy is a TensorFlow training strategy for synchronous Training on multiple workers, with each worker having a copy of the model.
This strategy uses data parallelism, where the same model is replicated on each worker, and the weights are kept in sync through all-reduce communication during the forward and backward pass. This is useful when training on multiple GPUs or using multiple machines with one or more GPUs each. In addition, Keras, a high-level neural networks API, can be used with TensorFlow to simplify the process of building and training models.
-
ParameterServerStrategy
The ParameterServerStrategy is a TensorFlow training strategy for asynchronous Training on multiple workers, with parameter updates being handled by a separate parameter server.
ParameterServerStrategy uses model parallelism, where different parts of the model are on different devices (typically one worker per device). The parameter updates are communicated between the workers and the parameter server. This is useful when training large models that do not fit on a single device and when using multiple machines with one or more devices each.
Like the MultiWorker MirroredStrategy, Keras, a high-level neural networks API, can be used with TensorFlow to simplify the building and Training models using the ParameterServerStrategy.
-
CentralStorageStrategy
CentralStorageStrategy is a TensorFlow training strategy designed for use with model parallelism. Unlike the MultiWorker MirroredStrategy and the ParameterServerStrategy, which are designed for data parallelism and use multiple GPUs or devices, CentralStorageStrategy is used to split a model across multiple devices while keeping the model parameters on a single device. The split model is then trained on multiple devices in parallel, and the gradients are accumulated on the device holding the model's parameters.
In this strategy, the model is split into multiple sub-models, each running on a different device, and each device has its forward pass. Still, the gradients are accumulated on a central device (parameter server) and then applied to the model. To use CentralStorageStrategy with Keras, you can use the tf.distribute.Strategy API. First, you need to create a tf.distribute.experimental.CentralStorageStrategy instance and then use the strategy.scope context to create your Keras model and call the compile() and fit() methods within the scope.
Organization of Distributive Training APIs in TensorFlow
In TensorFlow, distributed Training is organized using the tf.distribute API. This API provides several strategies for Distributed Training across multiple devices and machines. Some of the strategies include:
- tf.distribute.MirroredStrategy: It is used for Training on one machine with multiple GPUs. The strategy creates one replica of the model on each device, and the gradients are synchronized across all replicas using the all-reduce algorithm.
- tf.distribute.MultiWorkerMirroredStrategy: used for Training on multiple machines, each with one or more GPUs. The strategy creates one replica of the model on each device, and the gradients are synchronized across all replicas using collective communications.
- tf.distribute.experimental.MultiDeviceStrategy: This strategy allows Training on multiple devices within a single machine, each with a single GPU, or on multiple machines, each with one or more GPUs.
- tf.distribute.experimental.ParameterServerStrategy: used for Training on multiple machines, each with one or more GPUs. The strategy creates separate parameter servers for holding variables and worker nodes for computing gradients.
To use the tf.distribute API. It would help if you created an instance of the strategy you want to use and then used it to wrap your model and optimizer. Once you have wrapped your model and optimizer, you can use them as you would normally, and TensorFlow will handle the distribution of the training process for you.
Single-host, Multi-device Synchronous Training
Single-host, multi-device synchronous Training trains a model on multiple devices, such as GPUs, within a single machine. This method works by creating multiple copies of the model, known as replicas, and running them on different devices. Each replica processes a portion of the input data and calculates its gradients. These gradients are then synchronized across all replicas using an algorithm such as all-reduce. Once the gradients are synchronized, they update the model's parameters.
In TensorFlow 2.x and Keras, the tf.distribute.MirroredStrategy API can be used to perform single-host, multi-device synchronous Training. To use the API, you must create an instance of the tf.distribute.MirroredStrategy class. You can then use the strategy.scope context manager to create your model and optimizer inside the scope.
Here is an example of how to use tf.distribute.MirroredStrategy in Keras:
It is important to note that when using tf.distribute.MirroredStrategy The batch size should be divisible by the number of devices. Also, the data should be loaded on the device where the replica is located.
You can also use tf.distribute.MirroredStrategy with the tf.keras.fit() method, which will handle the distribution of the training process for you.
Multi-worker Distributed Synchronous Training
Multi-worker distributed synchronous Training is a distributed training method used to train a model on multiple machines, each with one or more GPUs. It works by creating multiple copies of the model, known as replicas, and running them on different machines. Each replica processes a portion of the input data and calculates its gradients. These gradients are then synchronized across all replicas using collective communications such as ring reduction. Once the gradients are synchronized, they update the model's parameters.
In TensorFlow 2.x and Keras, the tf.distribute.MultiWorkerMirroredStrategy API can be used to perform multi-worker distributed synchronous Training. To use the API, you must first create an instance of the tf.distribute.MultiWorkerMirroredStrategy class. You can then use the strategy.scope context manager to create your model and optimizer inside the scope.
Here is an example of how to use tf.distribute.MultiWorkerMirroredStrategy in Keras:
It is important to note that when using tf.distribute.MultiWorkerMirroredStrategy The batch size should be divisible by the number of workers. Also, the data should be loaded on the device where the replica is located.
You can also use tf.distribute.MultiWorkerMirroredStrategy with the tf.keras.fit() method, which will handle the distribution of the training process for you. The tf.distribute.MultiWorkerMirroredStrategy API requires cluster management tools, like Kubernetes or Docker Swarm, to coordinate Training across multiple machines.
Performance Tips
Here are a few performance tips for using the tf.data data pipeline with TensorFlow:
- Use the tf.data.Dataset.prefetch() method overlaps the preprocessing and model execution. This allows the model to start using the next batch of data while the current batch is still being preprocessed.
- Use the tf.data.Dataset.cache() method to cache the data in memory. This can reduce the overhead of reading and preprocessing the data on each iteration.
- Use the tf.data.Dataset.map() method with the num_parallel_calls argument to parallelize the preprocessing. This can help speed up the preprocessing step, especially when using expensive operations such as image decoding or data augmentation.
- Use the tf.data.Dataset.shuffle() method with a large buffer size to shuffle the data randomly. This can help prevent overfitting and improve the generalization of the model.
- Use the tf.data.Dataset.batch() method to batch the data. This can help improve the model's performance by reducing the overhead of the GPU memory transfer.
- Use the tf.data.Dataset.interleave() method to interleave multiple files. This method can be useful to read multiple files in parallel and improve the data's performance.
- Use the tf.data.Dataset.filter() method to filter out unwanted examples. This can reduce the amount of data that needs to be processed and improve performance.
It's also important to note that with tf.data API, you can build a pipeline that can handle multi-threading and multi-processing, which can be useful for large datasets and complex preprocessing.
Advantages and Disadvantages of Using APIs for Distributing Training
There are several advantages and disadvantages to using APIs for distributing Training in TensorFlow:
Advantages
Advantages of using APIs for distributing Training:
- Flexibility: APIs allow for flexible integration with various platforms and devices, making it easy to distribute Training to different systems and environments.
- Scalability: APIs can easily handle large amounts of data and requests, making them suitable for distributed training tasks.
- Easy access to powerful resources: APIs can provide access to powerful resources such as cloud computing and GPUs, greatly improving training efficiency.
- Reusability: Once an API is developed, it can be reused for different training tasks, reducing the development time required for each new task.
- Easy to monitor and control: APIs provide a way to monitor and control the training process, making it easy to track progress and adjust as needed.
Disadvantages
Disadvantages of using APIs for distributing Training:
- Security concerns: Because APIs expose training data and models to the internet, there is a risk of data breaches and unauthorized access.
- Latency: APIs can add latency to the training process, as data must be transmitted over the internet.
- Dependency: If the API provider goes out of service or changes its terms of service, it can disrupt the training process and make it easier to continue or reproduce the results.
- Cost: Additional costs may be associated with using APIs, such as user fees or accessing powerful resources.
- Complexity: APIs can add complexity to the training process, requiring additional development and maintenance.
- Limited control: Depending on the API, the user may have limited control over the configuration and settings of the training process.
- Limited customization: Using an API may limit the ability to customize the training process to specific needs and requirements.
- Limited transparency: The internal workings of the API may be opaque, making it difficult to understand or debug any issues that arise during Training.
- Limited ownership: Depending on the terms of service, the user may not have ownership over the data or models generated through the API.
The strategy choice and the training pipeline's architecture should be well thought out. Otherwise, it may result in suboptimal performance or even errors. It is also important to consider the costs of the additional infrastructure required for distributed Training.
Conclusion
This article has studied the APIs for Distributed Training in TensorFlow and Keras. The following are the key takeaways:
- The MultiWorker MirroredStrategy is useful when training on multiple GPUs or using multiple machines with one or more GPUs each.
- The ParameterServerStrategy is useful when training large models that do not fit on a single device and when using multiple machines with one or more devices each.
- The CentralStorageStrategy is designed for use with model parallelism, and it is useful when the model is too large to fit on a single device. However, it still needs to be more experimental and adopted.
- TensorFlow also provides other strategies, such as TPUStrategy, and MirroredStrategy, which have their use cases depending on the hardware and training requirements.