Building a Text Classifier with Pre-trained Embeddings Using Keras
Overview
In this article, we will learn to train a Deep Learning (DL) model, which will be able to classify the reviews into positive or negative classes. This type of problem statement comes under Natural Language Processing (NLP). A computer program's ability to comprehend human language as spoken and written is known as natural language processing or NLP. This article will implement the Sentiment Classification NLP model with Glove word embedding.
What are we Building?
Classifying text data into two or more groups is known as text classification. The most popular type of classification is binary classification, which categorizes each article in the corpus into one of two groups. The fundamental method for classifying texts is to create a set of features to characterize a text, then use an algorithm to process and use these features to choose the best category for a given text.
Text is among the most prevalent unstructured data types, making up 80% of all information. Unfortunately, due to its messy nature, most businesses do not fully utilize text data since it is difficult and time-consuming to analyze, organize, and filter through text data.
This is where machine learning for text classification comes in. Using text classifiers, companies can quickly and efficiently classify all kinds of relevant Text, including emails, legal documents, social media posts, chatbot messages, surveys, and more. As a result, businesses can analyze text data more quickly, automate business procedures, and decide based on data.
It makes extracting insights from data and automating business procedures simple, and text classification is becoming an increasingly important component of businesses. The following are some of the most typical uses and examples of automatic text classification:
-
Sentiment Analysis:
The technique of determining whether a text speaks favorably or adversely on a particular subject (e.g., for brand monitoring purposes). -
Topic Detection:
Finding the theme or topic of a text is known as topic detection (e.g., know if a product review is about Ease of Use, Customer Support, or Pricing when analyzing customer feedback). -
Language Detection:
Language detection determines a text's language (e.g., knowing if an incoming support ticket is written in English or Spanish for automatically routing tickets to the appropriate team).
In this article, we will build a text classification layer based on the Glove Word Embedding in Keras.
Pre-requisites
To excel in this article, we should have in-depth intuition about the Tensorflow dataset, the Tensorflow data pipeline, and Keras Model API.
-
Text-Classification:
Classifying Text into ordered groupings is called text classification, text tagging, or text categorization. Text classifiers can automatically assess Text using Natural Language Processing (NLP), and then based on its content, assign a set of predefined tags or categories. -
Tensorflow and Keras:
Keras is a compact, easy-to-learn, high-level Python library that runs on top of the TensorFlow framework. It focuses on understanding deep learning techniques, such as creating layers for neural networks, maintaining the concepts of shapes, and mathematical implementation. -
What are Word Embeddings?:
In essence, word embeddings are a type of word representation that connects a computer's language comprehension to a human's. They have mastered text representations in an n-dimensional space, where words with the same meaning are represented similarly. This means that closely spaced, practically identical vectors represent two related words. For the majority of problems involving natural language processing, these are crucial. In this article, we will use GLove word embedding. -
GLOVE:
Another approach to producing word embeddings is called GloVe (Global Vectors for Word Representation). It is based on word-context matrix factorization algorithms. We can build a big matrix of co-occurrence data and count the number of times each "word" (the rows) appears in a particular "context" (the columns) in the corpus. We typically scan our corpus as follows: for each term, we search for context terms within a region delineated by a window size before and after the term. Additionally, we assign words spoken further away less weight. There are many "contexts" because their magnitude is essentially combinatorial. Thus, a lower-dimensional matrix is created by factorizing this matrix, with each row now containing a vector representation of each word. Typically, this is accomplished by reducing a "reconstruction loss". To explain the majority of the variance in the high-dimensional data, this loss looks for lower-dimensional representations.In practice, we transform our Text into embeddings using GloVe and Word2Vec, showing equivalent performances. Since over 13 million words are in the corpus, creating these embeddings requires significant time and resources. However, we can utilize the already learned and simple to use pre-trained word vectors to avoid this. The download links for Word2Vec or GloVe are provided here.
-
Long Short-Term Memory (LSTM):
Long Short-Term Memory Networks (LSTM) are part of the Recurrent Neural Network (RNN) family of Deep Learning (DL) was introduced by Hochreiter & Schmidhuber (1997). The RNN architecture enables them to remember long-term data dependencies; hence, it is suitable for time series data and speech recognition, Image Video Captioning, forecasting, and many others. LSTM is the state-of-the-art architecture implemented to rectify the problem of vanishing gradient in the RNNs and the long-term dependency problem. The below diagram shows the structure of LSTM.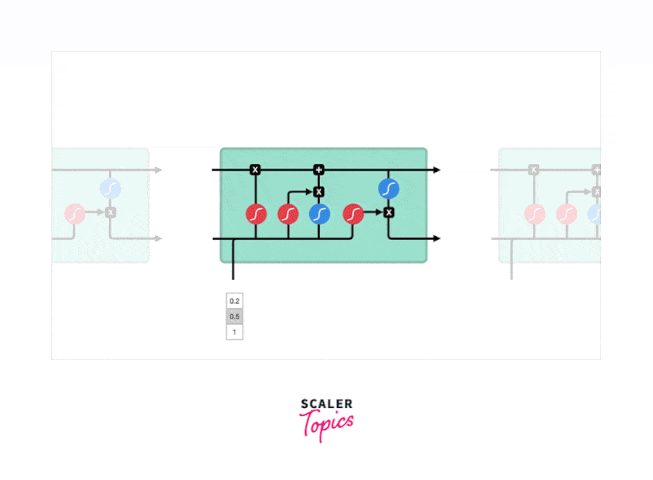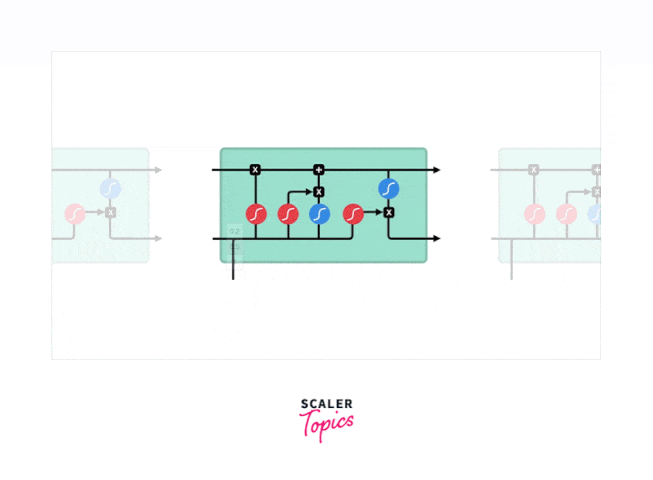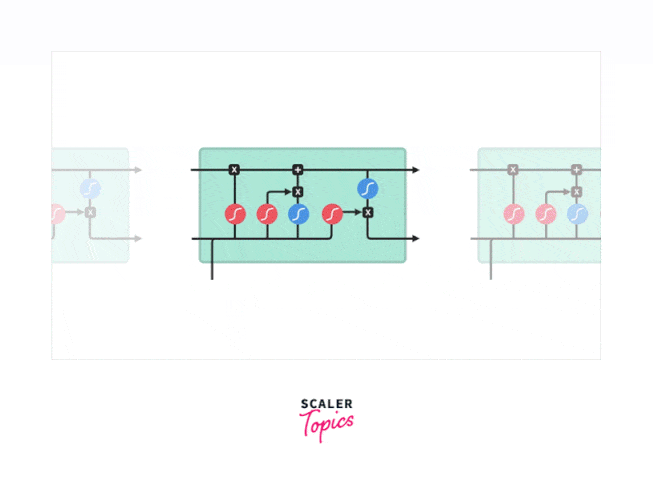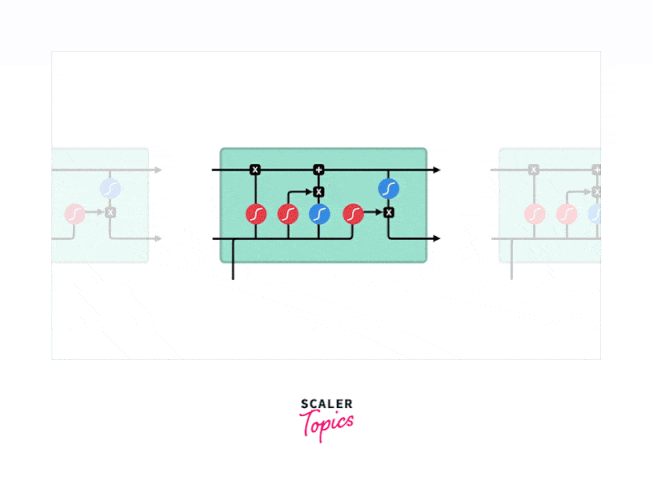
How are we Going to Build This?
To build the Text-Classification model with a Pre-Trained Embedding Layer, we will do the following process:
-
Data Loading:
We will use the Tensorflow data repository to load the Yelp dataset. -
Dataset Preprocessing:
In this section, we will preprocess the Dataset by removing URLs, stopwords, stemming, and punctuation and converting the word into numeric value by implementing GLOVE Pre-Trained Embedding. -
Model Training:
In this section, we will train our Text-Classifier Model composed of the Embedding Layer, LSTM, and Dense Layer. -
Prediction:
We will use the Trained Model to predict the Test Dataset. -
Export the Model:
Finally, we will save the Trained Model Weights.
Final Output
Two of the most promising recent developments in technology are natural language processing (NLP) and machine learning (ML), both of which are subsets of artificial intelligence (AI). These technologies can classify Text intelligently based on the sentiment it conveys.
Text classification is an important NLP activity that aids in resolving many business problems. Emails, messages, help tickets, and other types of data management are among the issues that many of these people have. The procedure is carried out automatically, saving time and increasing business productivity. At the same time, businesses can gain useful information that aids decision-making. Below I have displayed the Predicted Label and Actual from the trained Text-Classification Model using Pre-Trained Embedding.
Output:
Requirements
A low-level set of tools to create and train neural networks is offered by Google's TensorFlow2.x. With Keras, you can stack layers of neurons and work with various neural network topologies. We also use additional supporting packages like pandas and numpy for data preprocessing. For Dataset, we will be using Yelp Review Dataset, which is available on the Tensorflow dataset repository and can easily be accessed by tfds.loads.
Building a Text Classifier with Pre-trained Embedding Using Keras
Dataset Loading
TensorFlow Datasets is a set of dozens of machine learning datasets that can be used immediately. The tf.data file can load the data. Formatting datasets requires only a few lines of code for utilizing tf.data.Datasets. In this section, I will load the Dataset named yelp_polarity_reviews.
Importing Libraries:
In this section, I will import the libraries which will be used to download the Dataset from tensorflow Dataset and the supporting library for creating Text Classifier using Pre-trained embedding.
Downloading Dataset:
The tfds.load will download the Dataset from the Tensorflow dataset repository. It can split the Dataset, download the metadata about the Dataset, and specify the batch_size. For more detail, kindly refers to here
I have downloaded the yelp_polaity_reviews dataset from the tfds.load(). The shuffling_files is set to True as well I have specified to download the metadata about the Dataset by specifying with_info to True.
The Yelp reviews polarity dataset is constructed by taking into account stars 1, 2, and 3, which are negative, respectively. Two hundred eighty thousand training samples and 19,000 testing samples are randomly selected for each polarity. There are a total of 38,000 testing samples and 560,000 training samples. Class 1 is negative polarity, and class 2 is positive polarity. The training samples can be presented as comma-separated values in the files train.csv and test.csv. They have two columns, one for the class index and the other for the review text. Double quotes (") are used to escape the review texts, and two double quotes ("") are used to escape any internal double quotes. A backslash followed by an "n" character, which stands for "," is used to escape new lines.
This is a binary sentiment classification dataset. For training and testing, we provide a set of 38,000 highly polar Yelp reviews. ORIGIN The reviews from Yelp make up the Yelp reviews dataset. It is derived from the data for the 2015 Yelp Dataset Challenge. Please visit here for additional information. The Yelp reviews polarity dataset was created by Xiang Zhang (xiang.zhang@nyu.edu) using the preceding Dataset. The following paper is first utilized as a benchmark for text classification: Junbo Zhao, Xiang Zhang, and Yann LeCun Convolutional networks at the character level for text classification. NIPS 2015, Advances in Neural Information Processing Systems 28.
The below code snippets depict the code for downloading and loading the Dataset.
After downloading the Dataset, we will print the info variable. It will show the full description of the Dataset we have downloaded. The code snippets are shown below:
If you print the Dataset, you can see the description of the Dataset.
In the above section, i.e., tfds.load(), I have downloaded the Dataset. The ds will be composed of two dictionary keys, i.e., train and test, which can be used separately. That can be seen by executing the below code.
Output:
Since we know that Dataset is already separated into train and validation sets of tensor type. Therefore, by separating the test and train sets, I have created two pipelines, one for Test data and one for Train data. The code snippets are shown below:
Prepare the Dataset for Training
Text cleaning or preprocessing is mandatory when working with Text in Natural Language Processing (NLP). In real life, human writable text data contain different words with the wrong spelling, short words, special symbols, emojis, etc. We need to clean this kind of noisy text data before feeding it to the machine learning model. Moreover, any Deep Learning algorithm accepts a number, whether a floating point number or an integer. But our Dataset is in text form, so we need to preprocess the Dataset. This section will discuss the basic preprocessing steps implemented in the text data.
Seperating the Text, Label, and Dataset
The below function will separate the Text and label from the Dataset in the form of tf. records and store it in a separate list, making it easy for us to preprocess the Dataset. The code snippets are shown below:
Punctuation Removal
The process of getting rid of punctuation will help treat each Text similarly. Take, for instance, the terms data and data! are treated equally following the punctuation removal process. When removing punctuation, we need to pay attention to the Text because the contraction words will no longer have any meaning. For example, words like "don't" or "don t" will change depending on the parameter's setting. Additionally, depending on the use cases, we must exercise extra caution when selecting the list of punctuation marks from the data.
The below function will remove any punctuation from the Dataset.
Tokenization
The most important step in any NLP pipeline is tokenization. It has a significant impact on the remaining pipeline components. A tokenizer separates chunks of unstructured data and Text written in natural language into discrete elements.
The below function will tokenize the Dataset.
Stopwords Removal
A commonly used word like "the", "a", "an", or "in" is a stop word that a search engine is programmed to ignore when indexing or retrieving entries as a result of a search query. We don't want these words to take up valuable processing time or space.
The below function will remove any stopwords from the Dataset.
Stemming
The stemming process entails creating morphological variations of a root or base word. Stemming algorithms or stemmers are other names for stemming programs. For example, the terms "chocolates", "chocolatey", and "choco" are reduced by a stemming algorithm to the word "chocolate", and the words "retrieval", "retrieved", and "retrieves" are reduced to the word "retrieve". In the pipeline stage of natural language processing, stemming plays a significant role. Tokenized words are used as the stemmer's Input.
Preprocessing the Dataset
In this section, I will apply all individual functions and apply to the dataset pipeline using the .map function. The map function is called on the dataset input pipeline, which will invoke the preprocess function for all the samples present in the Dataset after preprocessing the Dataset. The map function will send one sample at a time to the preprocess function. I will implement the remove_punctuation, stemming , tokenise_data, and remove_stopwords. The snippets are shown below:
Word Embedding
This section will convert the preprocessed Dataset into a numerical value. We will download the GLOVE word embedding from here. The code snippets are shown below:
After downloading the folder, we need to extract the file. The code snippets are shown below.
After downloading and extracting the Glove embedding file it is time to convert our Dataset into numerical form for this I created a dictionary from the Glove pre-trained word embedding. For training, I will be using only 5 representations of words. If you want, you can choose according to your problem statement. The code snippets are shown below:
Finally, we must convert all the samples in the test train dataset into numeric vectors. The code snippets are shown below:
Creating Model
Now, after preprocessing the Dataset, it's time for the creation of the Model which we will train. For the sake of simplicity, I have constructed a simple Neural Network model with the following layers and activations:
-
Embedding Layer:
One of the layers in Keras is the embedding Layer. This is primarily utilized in NLP-related applications, such as language modeling, but it can also be applied to other neural network-based tasks. For example, we can use pre-trained word embeddings like GloVe to solve NLP issues. Alternatively, we can use Keras' embedding Layer to train our embeddings. -
Long Short Term Memory (LSTM) Neural Network:
The model architecture also constitutes two Long Short Term Memory (LSTM) with neurons of 128 and 64. The first Long Short Term Memory (LSTM) has a return sequence set to True. -
Dense Layer:
I have added one dense Layer with 25 neurons with a relu activation function in the model architecture. -
Classification Layer:
Since we have two classes (2 different objects to classify), we have added two neurons in the classification layer, which comprises one dense Layer with two neurons and the activation function of Sigmoid. Sigmoid is the activation function that outputs between 0 and 1.
The below code snippets depict code for creating the Model as discussed above.
Compile and Train the Segmentation Model
We built the Model in the parts above. In this stage, we will compile and train our Model. This component will be used to put our Model together. Before compiling the Model, we must specify the loss function, optimizer, and metrics. Our Dataset is a multi-label dataset. Hence I used sparse categorical cross-entropy as our loss function. Adam was chosen as the optimizer to propagate the error backward. Adam combines the Root Mean Square Propagation (RMSProp), Adaptive Gradient Algorithm, and Stochastic Gradient Descent (AdaGrad). We chose accuracy for simplicity, but you can choose any statistic that fits your issue statement. To save the Model and generate predictions, we also use a checkpoint. The below snippets depict the code for model compilation.
Our final step is to train the Model after a successful model compilation. The Dataset has previously been divided into training and testing sets.
Output:
Model Saving and Prediction
In this section, we will save the pre-trained Model, use the Model, and make predictions on the Test dataset unseen by the Model. We will select the test set as an input to the text classifier model, and we will predict and finally display the result as shown below:
Output:
What's Next?
In this article, we have created a Text Classification model based on a Pre-Trained Embedding Layer. You can also implement another word2vec algorithm with the same Model and try to create some applications using Flask, Django, and Streamlit by exporting the Model. Also, you can use 1D - Convolutional Neural Network (CNN) or Dense Neural Network (DNN) to create a Text Classification Model.
Conclusion
In this article, we learned how to create a text classifier model in Keras with Pre-Trained Word Embedding known as GLOVE. The following are the takeaways from this article:
- Natural Language Processing Model (NLP) model cannot accept Text or Letters as Input; they expect numerical Input.
- Glove is a work embedding that, as released by Google, is one of the most widely used pre-trained word embeddings.
- Text Classification can be used in many industries, such as customer services, banking, etc.
- Text Classification can also be implemented when we make chatbots.
- Social Media platforms heavily rely on the Text Classification algorithm to block or filter out inappropriate comments or posts