Distributed Training for Standard Training Loops in Keras
Overview
Distributed Training in Keras allows for training a model on multiple devices, such as multiple GPUs or multiple machines. TensorFlow's distribution strategies can be used to handle the distribution of training data and computation. The tf.distribute.Strategy API provides an abstraction for distributing training across multiple devices. Standard training loops can be used with minimal changes to the code. It helps to improve the performance of training large models and can also help to reduce the training time.
Introduction
Distributed training is a method of training machine learning models on multiple devices, such as multiple GPUs or multiple machines. This can be done to improve the performance of training large models and can also help to reduce the training time. Keras, a high-level neural networks API, has built-in support for distributed training through TensorFlow's distribution strategies. The tf.distribute.Strategy API provides an abstraction for distributing training across multiple devices, allowing standard training loops to be used with minimal changes to the code. This allows developers to easily leverage the power of multiple devices to train their models without manually handling the distribution of data and computation.
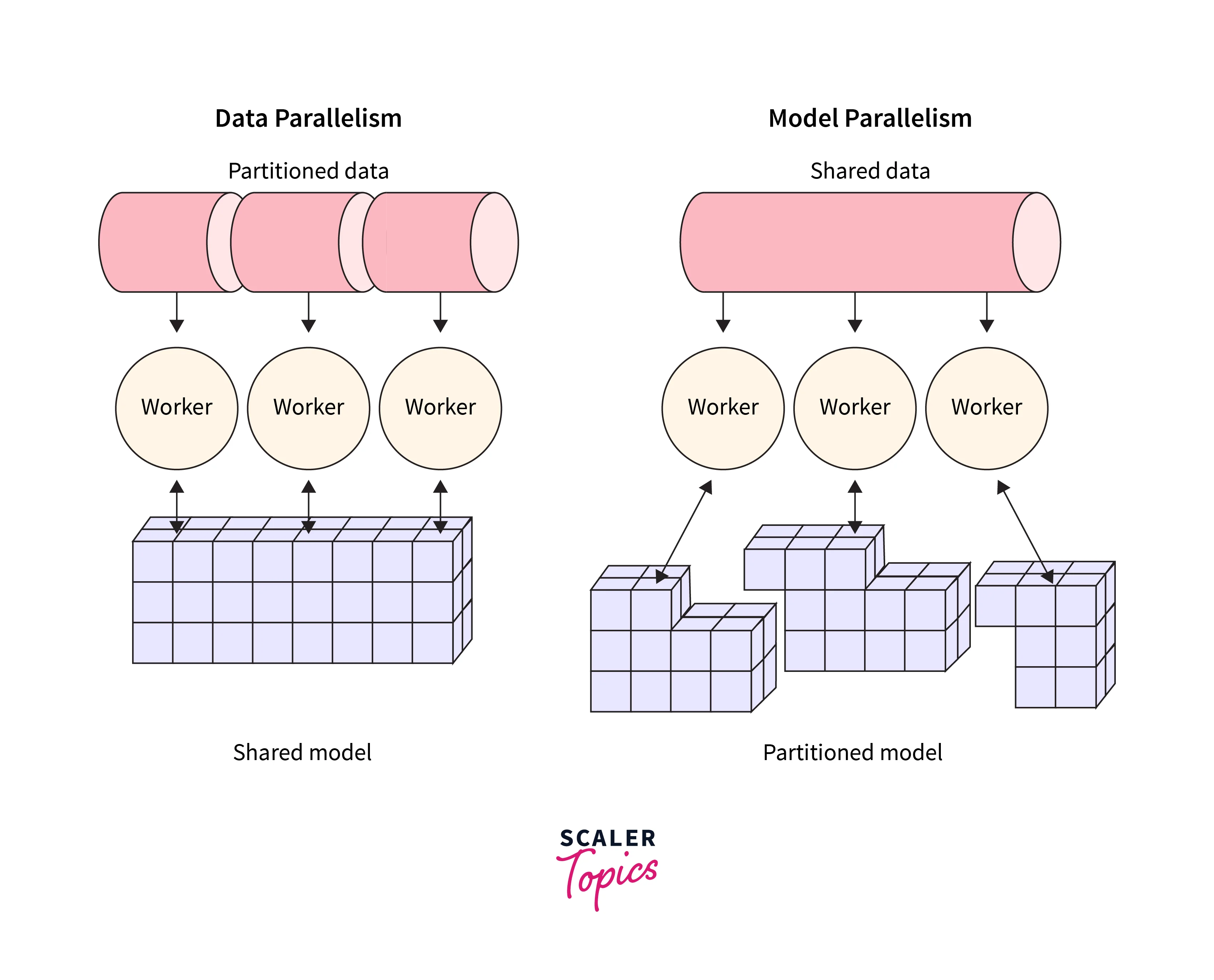
What is MirroredStrategy?
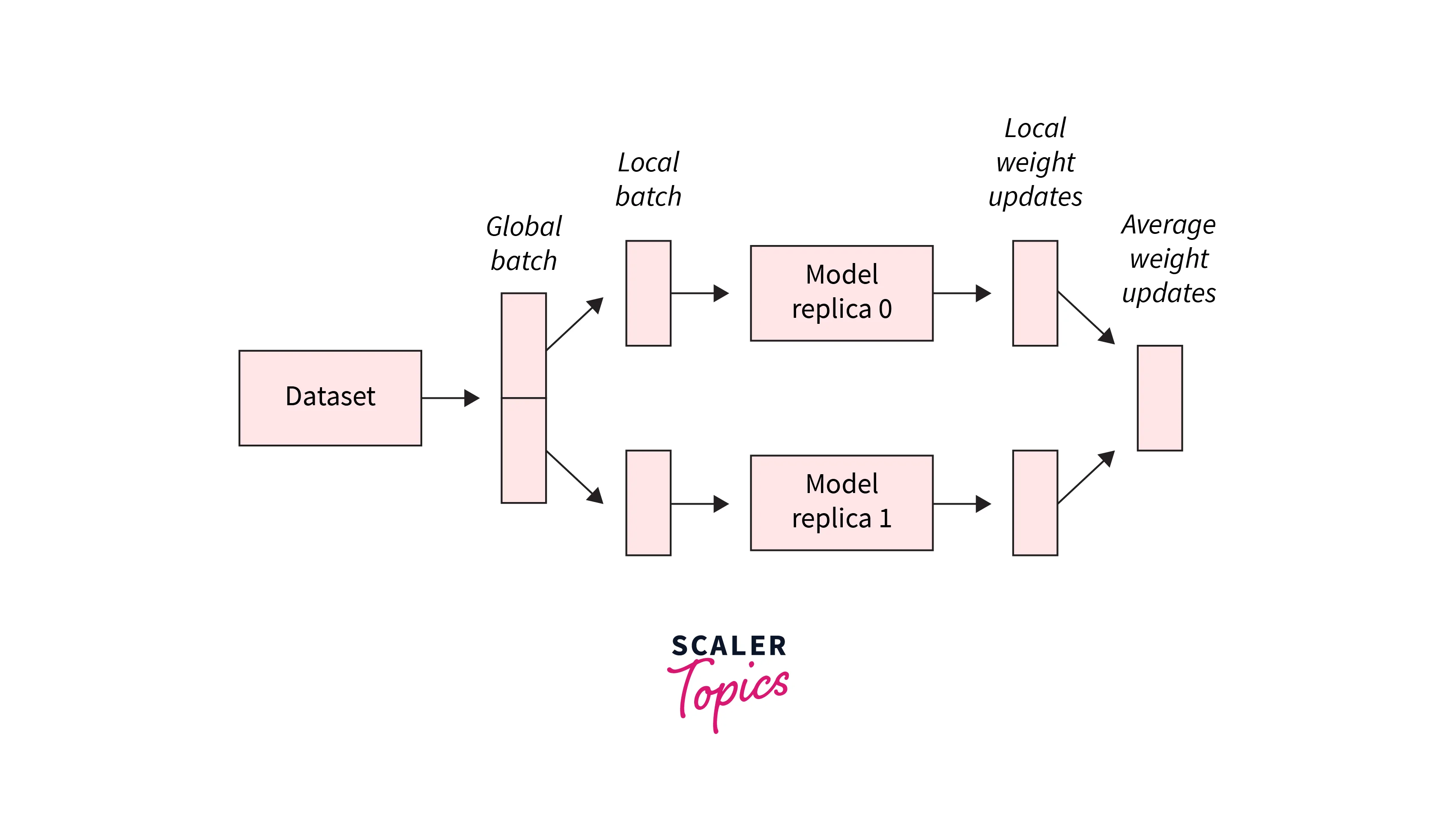
MirroredStrategy is a TensorFlow distribution strategy for distributed training on multiple GPUs on one machine. It supports training on multiple GPUs with minimal code changes by creating mirrored copies of the model on each device. This allows for parallel and efficient training on multiple GPUs by synchronizing gradients and updating model parameters across all copies of the model. It is particularly useful for training large models on high-performance GPU clusters.
A Simple Training Loop for Image Classification
We will train a simple image classifier model using the tf_flower dataset. Our main focus is demonstrating the distributed training in standard loops in Keras. We are using a simple CNN model to demonstrate this distributed training experiment in Keras's standard loops.
Train on a Single GPU
Here is a simple training loop for image classification using TensorFlow and Keras:
Imports
Load the "tf_flowers" dataset
Normalize the pixel values
Define the model
Compile the model
Train the model
Evaluate the model
Note: This is just an example, you can use different architectures, hyperparameters, and other options depending on the problem and data.
Train on Multiple GPUs
Here's a simple training loop for image classification that demonstrates the impact of distributed training using TensorFlow and Keras:
Imports
Load the "tf_flowers" dataset
Normalize the pixel values
Define the model
Compile the model
Initialize a MirroredStrategy
Train the model with the MirroredStrategy
Evaluate the model
This code trains the model using a MirroredStrategy, which supports synchronous training on multiple GPUs with one replica per GPU. Using a MirroredStrategy, you can use multiple GPUs to speed up the training process.
Note: This is just an example. You can use different architectures, hyperparameters, and other options depending on the problem and data.
Mixed Precision
Mixed precision is a technique in TensorFlow and Keras that involves using single precision (32-bit) and half-precision (16-bit) floating-point data types in the same model. The idea behind mixed precision is to use the more memory-efficient half-precision data type for certain computations while retaining the higher precision of single precision for other computations where accuracy is critical.
To use mixed precision in TensorFlow and Keras, you can specify the data type for each layer in the model. For example, you can use the dtype argument in keras.layers.Dense to specify the data type for the weights and biases of the layer. For example, to perform operations in half-precision, you can use the tf.float16 data type; to perform operations in single precision, you can use the tf.float32 data type.
The advantages of mixed precision include faster training times, reduced memory usage, and improved training stability. By using half-precision, you can fit larger models into GPU memory, allowing you to use more parameters and layers in your models. Additionally, half precision can be faster to compute than single precision, leading to faster training times.
When to use mixed precision depends on the problem and data. Mixed precision is generally suitable for most deep-learning tasks and can be used in most cases without sacrificing accuracy. However, in some cases, it may be necessary to use single precision for certain computations to ensure high accuracy. Therefore, before using mixed precision, it is important to evaluate the impact of reducing precision on the accuracy of your model.
Usage:
Conclusion
To conclude this article, we looked at how to train image data in a distributed training environment with TensorFlow and Keras.
- We understood the concept of MirroredStrategy and built API in TensorFlow.
- We implemented a simple training loop to train the model on single GPU and multiple GPUs.
- We also discussed how to train the model faster using Mixed Precision.