Introduction to Distributed Training in Deep Learning
Overview
Distributed training refers to training a machine-learning model on multiple machines or with various GPUs. This can be useful when the data is too large to fit on a single device or when the model is too large to serve on a single machine. In addition, distributed training can speed up the training process by allowing multiple machines or GPUs to work on the training process simultaneously.
Introduction to Distributed Training
In Keras, distributed training is typically achieved using the TensorFlow backend. The TensorFlow backend for Keras allows you to specify which devices you want to use for training, and it will automatically distribute the training process across those devices. This can be done by setting the tf.device context when creating your Keras model. Once you have specified which devices to use, you can compile and train your model.
Keras automatically distributes the training process across the specified devices. Overall, distributed training is a powerful technique for training large, complex machine learning models. It can help you train your models faster and more efficiently, but it can also be more complicated to set up and require more computational resources. Therefore, it's essential to carefully consider whether distributed training is appropriate for your particular use case.
Why is Distributed Training Important in Deep Learning?
Distributed training is essential in deep learning because it allows for training huge models on a much more significant amount of data than would be possible on a single machine. This can lead to more accurate models and faster training times. Additionally, distributed training allows for the training of models on multiple devices, further speeding up training times and making it more practical to train extensive models.
Types of Distributed Training Workloads in Deep Learning
Pipeline Parallelism
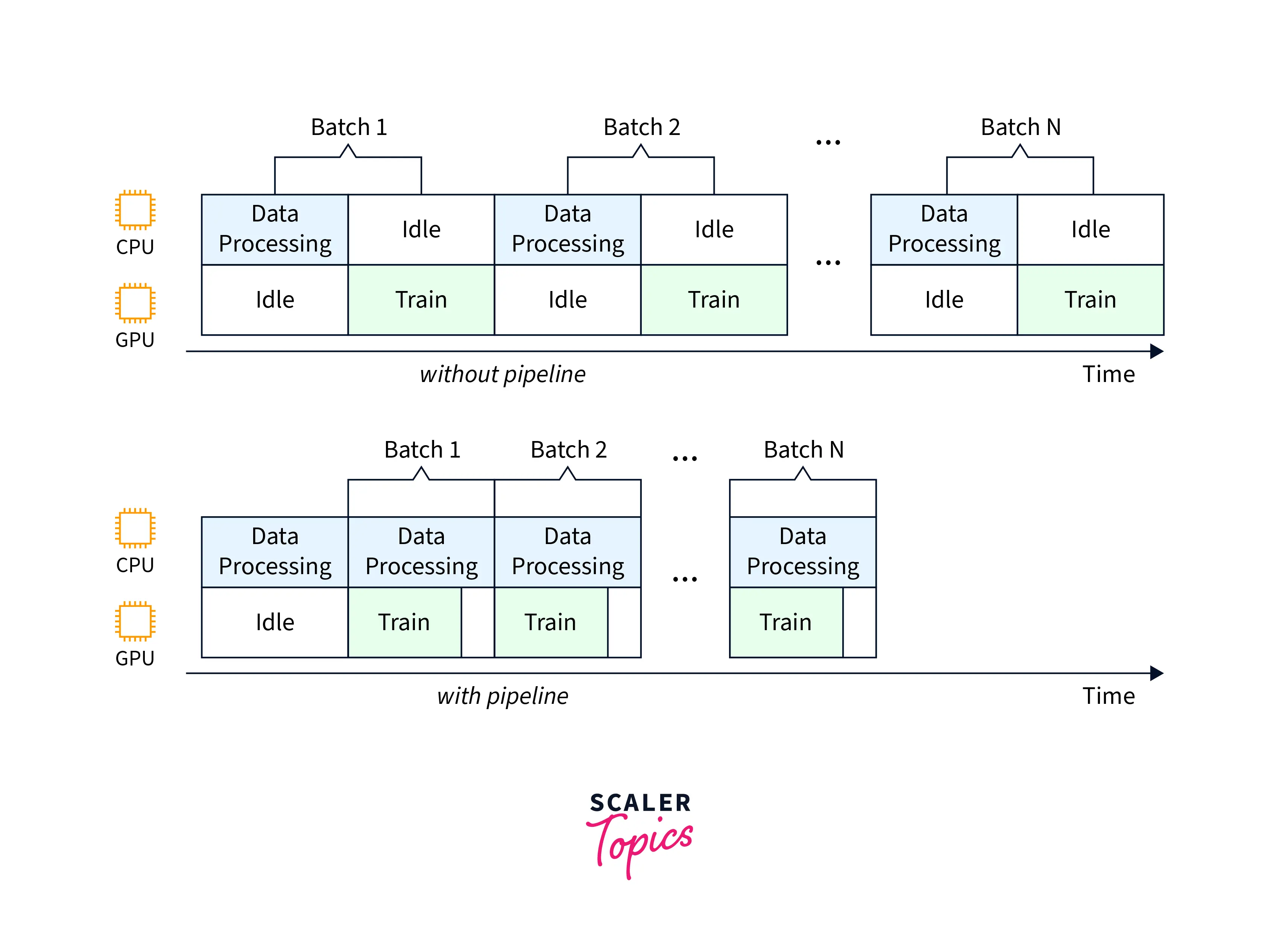
Pipeline parallelism is a machine-learning technique to speed up a model's training by dividing the data into multiple smaller batches and processing each batch in parallel. This differs from model parallelism, which involves dividing the model across various devices. In pipeline parallelism, the entire model is run on a single device, but the data is divided into smaller batches that can be processed simultaneously. This allows for faster training times, but it also requires careful planning to ensure that the pipeline's different stages can communicate with each other efficiently.
Model Parallelism
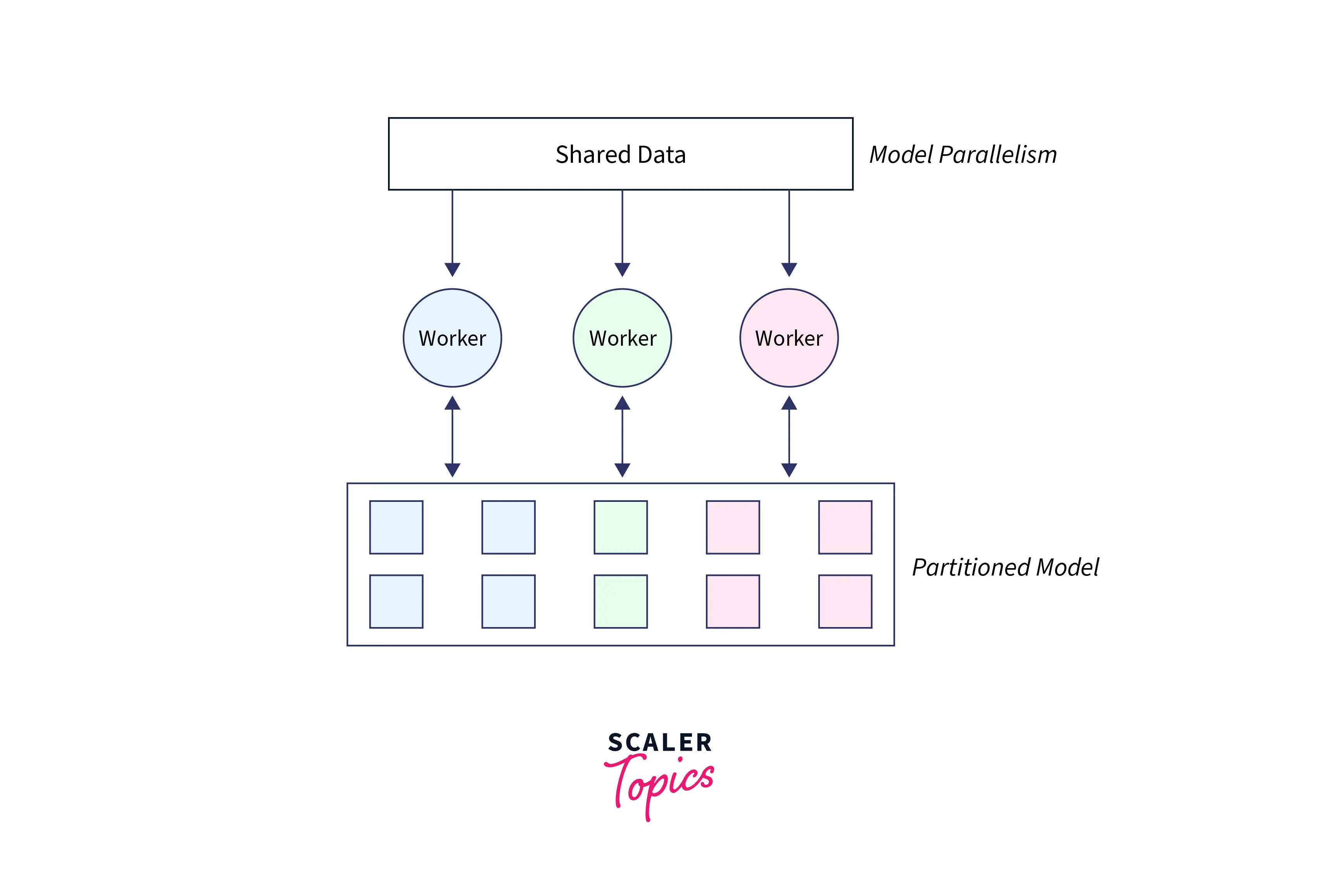
Model parallelism is a machine learning technique to distribute a model's workload across multiple devices, such as GPUs or machines. This allows for faster training times and the ability to train more extensive and complex models. It works by dividing the model into different "parts" or "blocks", and each part is run on a separate device. The results are then combined to produce the final output. This can be an effective way to train large models. Still, it can also be challenging to implement and requires careful planning to ensure that the additional parts of the model can communicate efficiently.
Data Parallelism

Data parallelism is a way of parallelizing a program by dividing the data it operates on across multiple computational units, such as multiple CPUs or GPUs. This allows the program to run faster by distributing the workload across multiple processors. To achieve data parallelism, the program must be designed to enable the data to be easily divided and distributed to the different computational units. In addition, the results must be appropriately combined at the end of the computation.
One of the main advantages of data parallelism is that it can be applied to a wide variety of problems, including highly parallelizable issues, such as matrix multiplication and image convolution, and less parallelizable problems, such as natural language processing and computer vision. Additionally, data parallelism can be easily implemented using parallel computing frameworks, such as TensorFlow and PyTorch, which make it easy to distribute the data and combine the results.
Overall, data parallelism is a powerful tool for speeding up computation by taking advantage of multiple processors, and it has become an essential part of many modern parallel computing systems.
Conclusion
In this article, we understood the following:
- What is Distributed learning and its importance?
- We also understood the importance of distributed learning.
- We also understood the concepts like Pipeline parallelism, Model parallelism, and Data parallelism.