Optimizing Models for Mobile-based Deployments in Keras
Overview
Model Optimisation plays an important role in terms of deployment. Training machine learning or deep learning is much easier than deploying it in production. For deploying machine learning or deep learning models, we have many factors involved, where optimization comes into play. In this article, we will discuss how to optimize your machine-learning models for Mobile-based applications.
Introduction
Deployment in edge devices like mobile phones or Edge TPUs is slightly different from CPU-based or GPU-based deployment. For model deployment in edge devices, TensorFlow Lite APIs come into play. TensorFlow Lite models are so lightweight that they can easily fit in for deployment in edge devices. TensorFlow Lite models are small in model size, and the latency of the models is also low. TensorFlow Lite also supports Python, Java, C++ etc. In terms of optimization, we can also apply quantization in TensorFlow Lite models.
Different Quantization Recipes Offered by TensorFlow Lite
There are mainly two types of quantization.
-
Post-training quantization:
Post-training quantization is one type of quantization technique where the model size gets reduced, which helps to reduce the inference time in CPU and other edge devices. With post-training quantization, we need to bear a trade-off, i.e., it reduces the accuracy precision by a small factor. For performing quantization you need to have the TensorFlow version. 1.15 or higher. -
Quantization aware training:
Quantization-aware training is used to get better accuracy. Quantization-aware training uses lower precision, like 8-bit instead of 32-bit float, which helps deploy models.
How to Quantize a Model with TensorFlow Lite APIs with the Different Recipes?
Let's build a simple CNN model with the Fashion MNIST dataset and perform quantization strategies.
Import the packages:
Create a helper function to determine the file size:
Gather the dataset:
Classes of the dataset:
Normalize the images:
Build the model:
Model Summary:
Now let's compile and train the model,
Visualise the training curve:
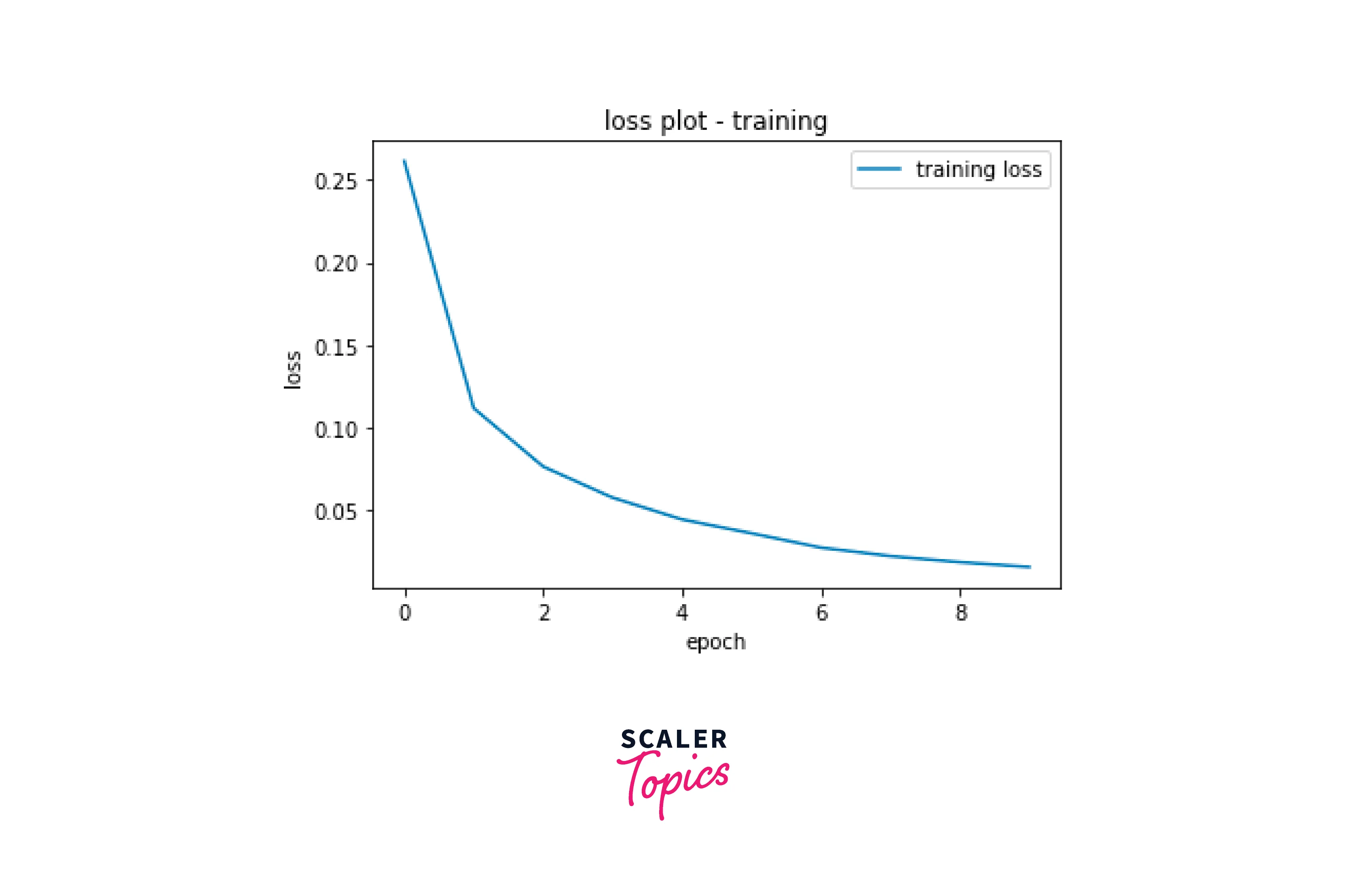
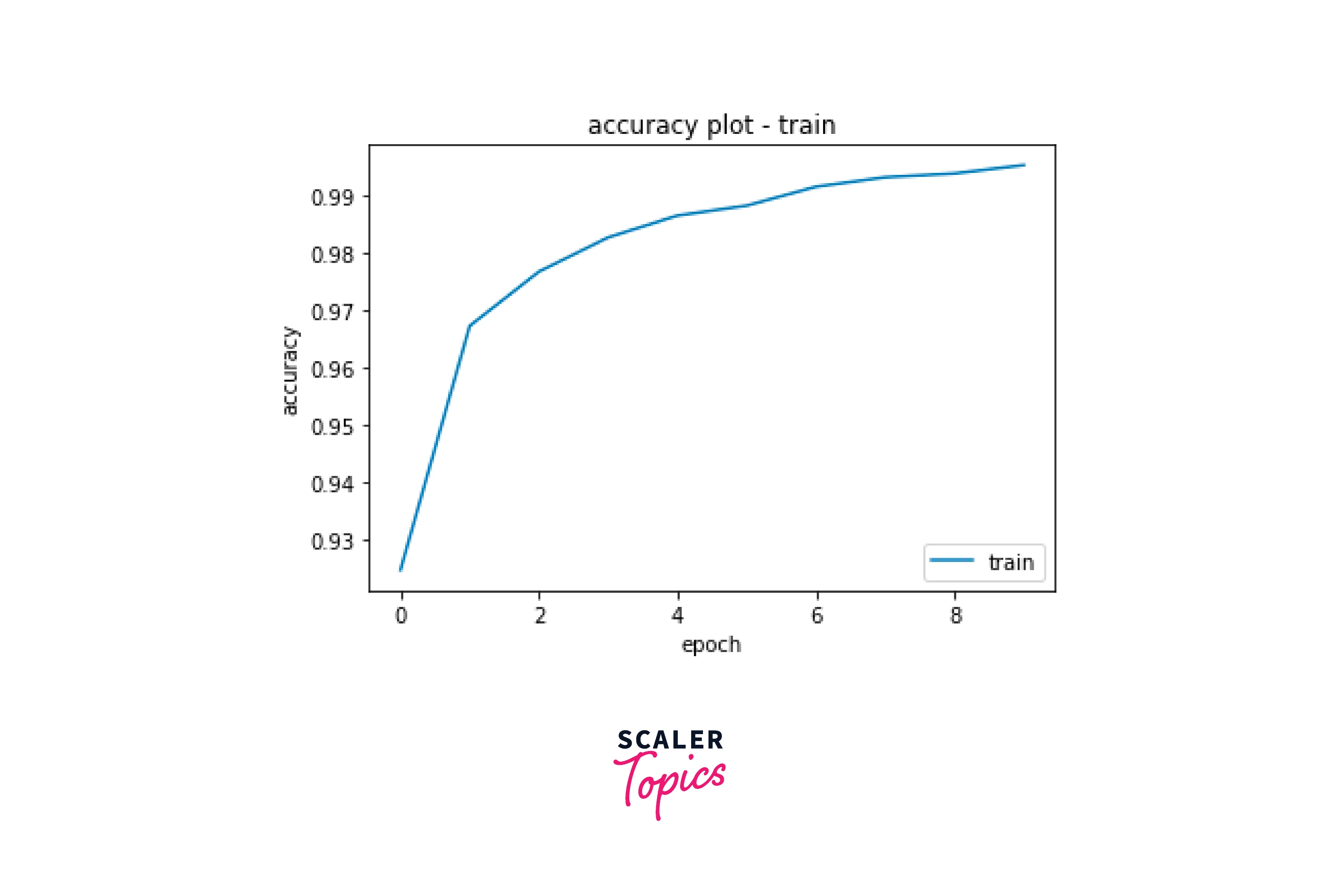
Evaluate the model using test data.
Results of evaluation:
Serialize the model and get the file size:
- File Size: 4.0 Kilobytes
Save the TF Lite Model:
- File Size: 399.227 Kilobytes
Evaluate the TF-Lite model:
Check tensor shape:
Resize tensor-shape for inference:
Test the TF-Lite model:
After evaluation, we can observe that the Keras model evaluation was 97.82% and the TF-Lite model was 97.82%. They are almost equal.
Now, we will apply different types of quantization to the TF-Lite models.
Dynamic Range Quantization:
- File Size: 101.602 Kilobytes
Float16 quantization:
- File Size: 201.047 Kilobytes
Full integer quantization:
- File Size: 101.602 Kilobytes
Further Reducing Model Size with Pruning
For using pruning, we need the package tensorflow-model-optimization, we can easily install it via pip.
Imports:
Define the model for pruning:
Model Summary:
Train the pruned model:
Serialize the pruned model:
Save the TensorFlow Lite model:
- File Size: 399.227 Kilobytes
Test the TF Lite file using test images:
Further Reading
Distillation
Knowledge Distillation is a process where the learning of a bigger model(teacher model) is transferred to a smaller model(student model). It is done to be used at its full utilization.

Source: Link
We know that neural network models are bigger, but we need to compress them to deploy them in mobile devices or edge devices. Unfortunately, in the compression process, we lose accuracy; that is where Knowledge Distillation comes into the picture.
To learn more about Knowledge Distillation recipes, you can head to the links below.
- Implementing Knowledge Distillation in TF and Keras
- Knowledge Distillation Recipes in TF and Keras
- Knowledge-Distillation-in-Keras-GitHub
Mobile-friendly Architectures
For deploying machine learning models or deep learning models in mobile-based applications, we need to consider using a good architecture suitable for mobile deployment models.
The mobile-friendly architectures are listed below:
- MobileNet, MobileNetV2, MobileNetV3Small, MobileNetV3Large
- MobileViT
- NASNetMobile
- EfficientNetB0, EfficientNetB1, EfficientNetB2
- EfficientNetV2B0, EfficientNetV2B1
Hardware-aware Architecture Search
Hardware-aware architectures for mobile deployment for deep learning are designed to take advantage of the exceptional characteristics of mobile devices, such as limited computational resources and power constraints, to enable efficient and effective deep learning on these devices. Some examples of hardware-aware architectures for mobile deployment include MobileNets, ShuffleNets, and SqueezeNets. These architectures are designed to be lightweight and efficient, making them well-suited for deployment on mobile devices. Additionally, they often incorporate techniques such as parameter pruning, quantization, and low-precision arithmetic to reduce the computational demands of the network further.
Conclusion
- In this article, we reviewed the quantization types available.
- We went through how you can perform different types of quantization, which can be done during mobile deployment.
- We also looked at how pruning can help in the model deployment.
- We also discussed distillation, mobile-friendly architecture, and hardware-aware architecture.