Model Optimization Recipes with Keras and TensorFlow
Overview
It has been easy to train a neural network on famous frameworks like Keras, TensorFlow, and PyTorchrecently. However, in most cases, we need to pay more attention to the model optimization recipes of neural networks, which prevents a high latency model in production. So in this article, we will discuss several model optimization recipes.
Introduction
Model Optimisation is an essential tool in terms of deployment. Model Optimisation helps to reduce model size in edge devices like Mobile, Edge TPUs, etc. In addition, it helps to reduce the latency of the model (latency is the amount of time taken by the model to infer results). Lower latency results in less power consumption in edge devices. Not only it performs better for edge devices, but it also plays an upper hand while deploying models in GPUs. However, quantization helps to solve these problems.
Quantization
Quantization is a process where the model's parameter's precision is reduced from float32 to float 16 or int8.
Now let's easily understand this thing.
While training the model, the weights are adjusted so that the precision is float32. After applying quantization, the weights of the model's precision were reduced to float16 or int8. This results in model size reduction and increases the latency of the model.
For more details, you can refer to this link.
Post-training Quantization
Post-training quantisation is one type of quantisation technique where the model size gets reduced, which helps to reduce the inference time in CPU and other edge devices. With post-training quantisation, we need to bear a trade-off, i.e. it reduces the accuracy precision by a small factor. You need to have TensorFlow version 1.15 to perform quantization.
There are many types of post-quantization methods. The table shows the summary of all the methods.
| Quantization Technique | Advantages | Hardware |
|---|---|---|
| Float16 quantization | Size: 2x smaller & Speedup in GPU | CPU & GPU |
| Full integer quantization | Size: 4x smaller & 3x Speedup | CPU, Microcontrollers & Edge TPU |
| Dynamic range quantization | Size: 4x smaller & 2x-3x Speedup | CPU |
These numbers may confuse beginners; for that reason, I am attaching a decision tree so that anyone can choose what type of quantization they want.
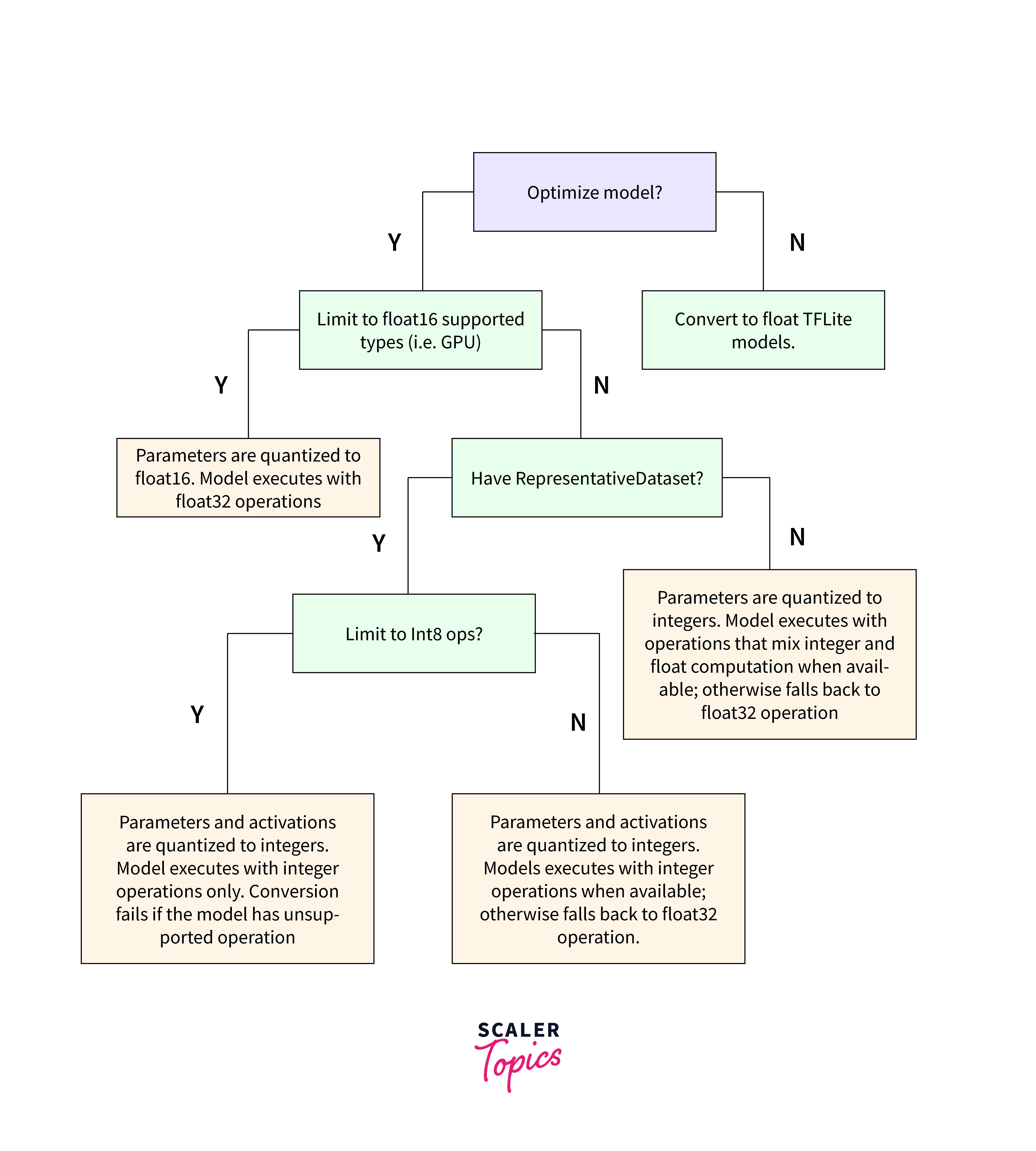
Source: TensorFlow Optimisation Methods
Dynamic Range Quantization
I assume you have trained a simple neural network with TensorFlow and Keras. After training the model, the next step is to serialize the model using model.save() function. After serializing the model, the model is converted to TensorFlow Lite format. For simple conversion of a serialized model to TensorFlow Lite is as follows.
For quantization (dynamic range), we can do it like this.
Dynamic Range Quantization is recommended as it provides less memory space and rapid computation without using the representative dataset.
Float16 Quantization
There are many advantages of using Float16 quantization. Firstly it reduces the model size by half. It results in a minimum loss in accuracy. It also supports GPU delegates to operate on float16 data, resulting in faster inferencing than float32. But the main drawback is that it does not reduce the latency of the model compared to the other quantization methods.
Full Integer Quantization
The main advantage of this quantization method is that it can improve the model's accuracy significantly, but it also increases the model size slightly. But the disadvantages are more in this case, such as the inferencing is slower than an 8-bit full integer. It is also not compatible with the existing TPU Delegates.
If you want a tutorial, you can visit this link.
Quantization-aware training
Above, we discussed Post-training quantisation, which is easier to perform. Quantization-aware training is used to get better accuracy. Quantization-aware training uses lower precision like 8-bit instead of 32-bit float, which helps deploy models.
Quantization-aware training is limited to Conv2D layers, BatchNormalization Layer, DepthwiseConv2D Layer, and in Concat but in limited cases. The API is compatible with EdgeTPU, FLite backends, and NNAPI.
To use Quantization-aware training, we need tensorflow-model-optimization in our pockets. We can install it easily via pip
The first and foremost step is to train. The model in TensorFlow and Keras. After training the model, create an object with tensorflow-model-optimization like,
After recompiling the model, we can train the model. This is how Quantization-aware training takes place. If you want to know more about it., head over to this link.
Pruning
Weight Pruning achieves model sparsity by zeroing out model weights during training. It is because they are easier to compress the model, and we can skip the zeroes during the inference process. It is observed that the model size is compressed 6x times with a gradual loss in accuracy.
To use Pruning, we need tensorflow-model-optimization in our pockets. We can install it easily via pip
The first and foremost step is to train the model in TensorFlow and Keras. After training the model, create an object with tensorflow-model-optimization like,
After recompiling the model, you can train the model. This is how Pruning takes place in Keras. If you want to know more about it., head over to this link.
Layer Fusion
Layer Fusion is a very interesting technique for optimizing deep learning models. It discovers which weights to combine and then fuse weights of similar fully connected, convolutional, and attention layers, etc. It significantly reduces the number of layers of the original neural network which was created.
To learn more about Layer fusion recipes, you can head to the links below.
Knowledge Distillation
Knowledge Distillation is a process where the learning of a bigger model(teacher model) is transferred to a smaller model(student model). It is done to be used at its full utilization.
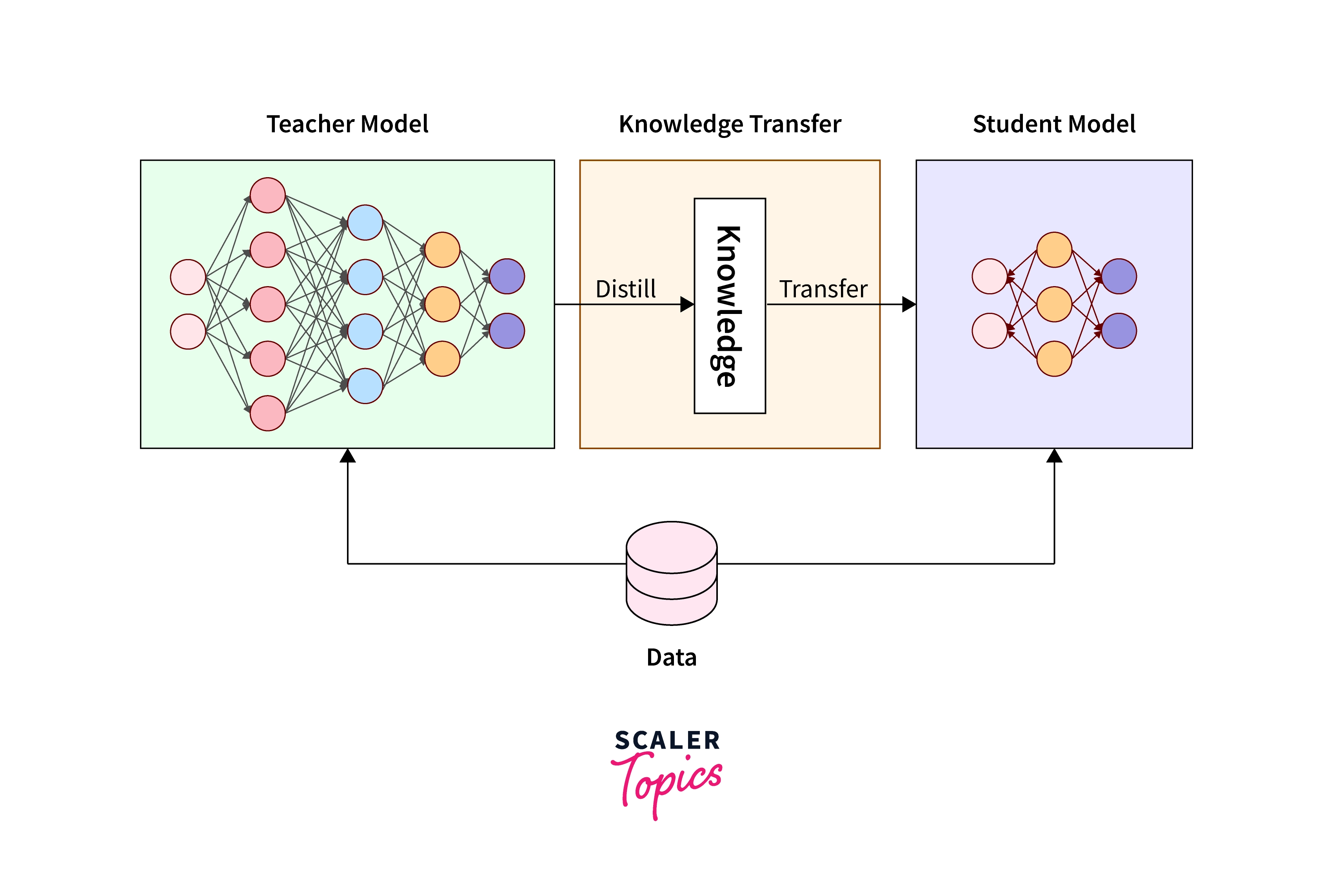
Source: Link
We know that neural network models are bigger, but we need to compress them to deploy them in mobile devices or edge devices. Unfortunately, in the compression process, we lose accuracy; that is where Knowledge Distillation comes into the picture.
To learn more about Knowledge Distillation recipes, you can head to the links below.
TensorFlow Model Optimization Toolkit
TensorFlow Model Optimization Toolkit is a collection of the toolkit for optimizing ML models for deployment and execution. The advantages TensorFlow Model Optimization Toolkit are:
- Reduces latency.
- Easily deployable models in edge devices.
- Enable execution on accelerated hardware.
The TensorFlow Model Optimization Toolkit is easily accessible via pip. You can easily use this tool to perform many optimization methods in TensorFlow and Keras.
TensorFlow Lite
TensorFlow Lite, or TFLite`, is a library useful for mobile and edge device deployments. For the deployment of ML models in edge devices, TensorFlow Lite is your go-to tool. The steps are very simple. These are the steps:
- Train a deep learning model.
- Convert a TensorFlow model to TensorFlow Lite via TensorFlow Lite converter.
- Deploy the .tflite model via the existing API.
- Furthermore, you can optimize the model using quantization methods.
For more information, visit here.
Conclusion
- In this article, we went through quantization and the available types of quantization.
- We went through model optimization recipes like pruning, layer fusion, and knowledge distillation.
- We also looked at what we are offered in the TensorFlow Optimization Toolkit and TensorFlow Lite.