Implementing Neural Style Transfer with Keras and TensorFlow
Overview
Designing images to produce contemporary and distinctive art has been a point of fascination for several centuries. The type of artwork one could produce with their abilities and blend of artistic styles piqued the interest of viewers, industry enthusiasts, and other business partners. Since the Renaissance, artistic creations like paintings, sculptures, models, architectural designs, and other works have been sold at auction for hefty profit margins. But recently, artificial intelligence has shown itself to be one of the original approaches to designing, decorating, and creating art. This article will discuss how we can generate art using Artificial Intelligence, known as Neural Style Transfer.
What are We Building?
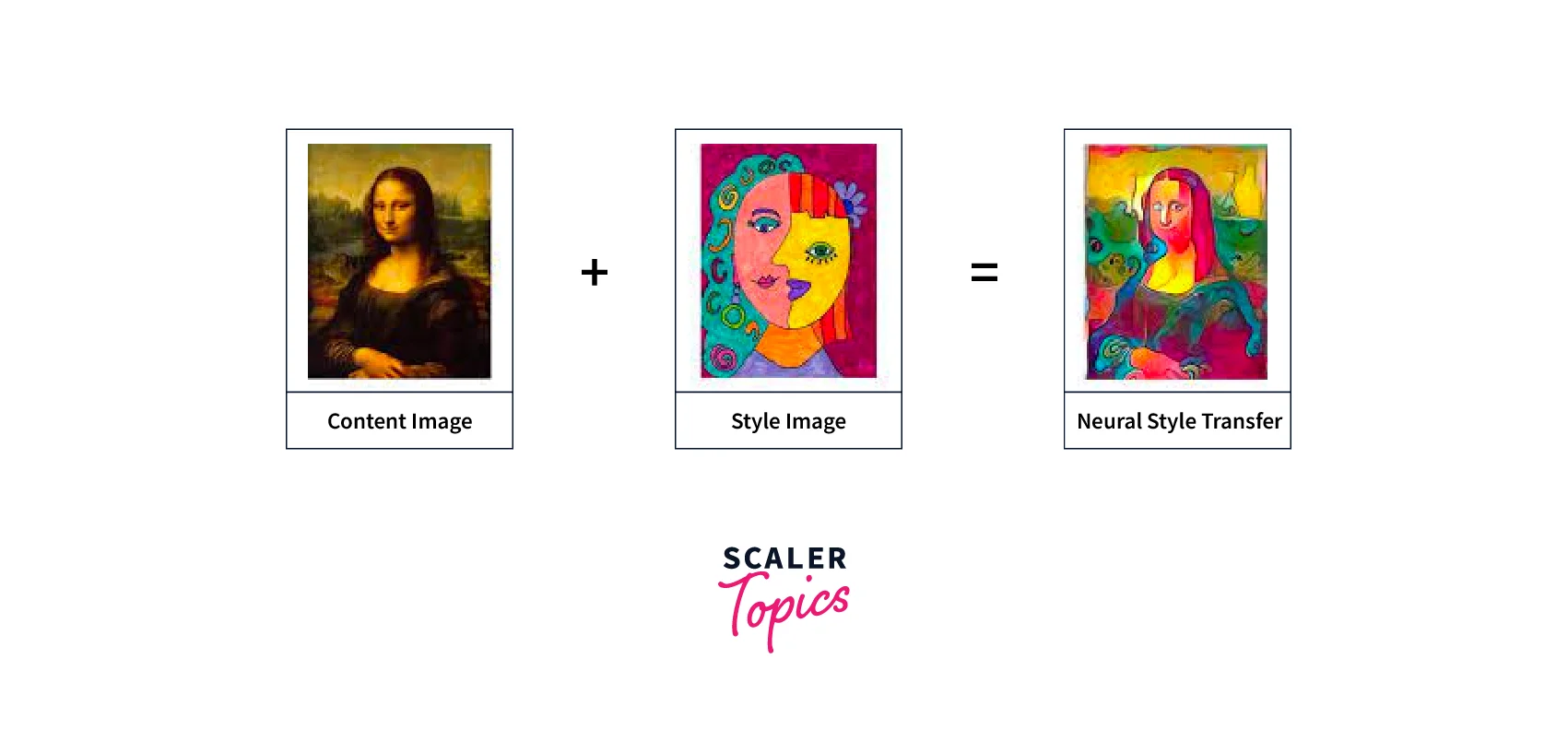
Neural Style Transfer is one of artificial intelligence's most entertaining contemporary uses. By combining two or more pictures, we can produce original artwork that is fresh and imaginative. There has been a great deal of advancement in face recognition and object identification, where one-shot learning approaches are used to achieve the best results quickly. However, the creative breakthroughs made possible by neural networks have been given little attention lately. With the publication of the research article A Neural Algorithm of Artistic Style in 2015, artificial intelligence and deep learning in art exploded.
We have learned about deep neural networks, which can perform most image-processing jobs as efficiently as convolutional neural networks. They comprise layers of small processing units that enable them to process visual data hierarchically and feed forwardly. A convolutional neural network has multiple of these computational units in each layer. Each of these computational units has a selection of image filters that extract a particular feature from the input image. In the following section of this article, we will explore more detail on Neural Style Transfer with Keras and TensorFlow.
In Neural Style Transfer (NST), we build a model to generate new images by combining one Image's Content with another's Style. Our model is typically based on a pre-trained convolutional neural network (CNN) such as VGG19, the base model for NST. The CNN is used to extract features from the input and generated images, which are then used to compute the content loss and style loss. Next, the model is trained by minimizing the total loss, which combines the content loss and the style loss, using backpropagation and optimization techniques such as stochastic gradient descent (SGD) or Adam. During the training process, the model generates a new image by starting with random noise or the content image and updating the pixels of the Image to minimize the total loss. After training, the model can generate new images by combining the Content of one Image with the Style of another image.
A common example could be using a photograph of a person as the content image and a portrait painting as the style image. It will generate a new image that combines the photograph's Content with the Style of the painting.
Pre-requisites
In this section, I will discuss the prerequisites, which is the building block for this article. With this, it will be easier to understand the Content of this article.
-
CNN:
A Convolutional Neural Network (CNN or convnet) is a subset of AI. A Convolutional Neural Network (CNN) is a type of network architecture for deep learning algorithms used for image recognition and other tasks requiring processing pixel data. In deep learning, there are other kinds of neural networks, but Convolutional Neural Networks are the preferred network architecture for identifying and recognizing objects. As a result, they are excellent candidates for applications requiring object recognition, such as self-driving cars and facial recognition, as well as computer vision (CV) tasks. For more details, you can refer here.
-
Transfer Learning:
Reusing a model that has already been trained on a different problem is known as transfer learning in machine learning. With transfer learning, a computer can use its understanding of one activity to better generalize about another. For instance, you may leverage the skills a classifier learned to identify drinks while training it to predict whether an image contains food. For more details, you can refer here.
-
TensorFlow and Keras
Keras is a compact, easy-to-learn, high-level Python library that runs on top of the TensorFlow framework. It focuses on understanding deep learning techniques, such as creating layers for neural networks, maintaining the concepts of shapes, and mathematical implementation.
-
What is Neural Style Transfer
Neural Style Transfer (NST) is a technique in deep learning that uses a pre-trained Convolutional Neural Network (CNN) to generate new images by combining the Content of one Image with the Style of another image. The process of NST involves training a model to transfer the style of a Style image to a Content image while preserving the overall structure and content of the Content image.
The model is trained by minimizing the total loss, which is a combination of the content loss and the style loss, which are defined as the difference between the feature maps of the generated Image and the content image, and the Gram matrices of the generated Image and the style image, respectively.
The final output is an image that is stylistically similar to the Style image but preserves the content of the Content image. NST can be applied to various images, including photographs, paintings, and illustrations, and can create unique and visually striking images.
How are We Going to Build this?
We typically need three key elements to generate an image via Neural Style Transfer. The main Image serves as the Content image to which we may apply some modifications. It serves as the framework for the desired artwork. The modification picture is the second element of the neural style transfer model, also known as the Style image. The Style is the flavor or variation that you can give to the Content to provide a fresh new image. Finally, the Generated image is the new Image created by the neural style transfer method using the Content and Style components. Building a Neural Style Transfer (NST) model typically involves the following steps:
- Choose a pre-trained convolutional neural network (CNN), such as VGG19 as the base model for NST. CNN is used to extract features from the input images and the generated Image.
- Load the content image and the style image. The images are preprocessed by resizing them to the same size and converting them to a format that can be fed into the CNN.
- Define the layers of the CNN that will be used for the content loss and the style loss. Typically, the lower layers are used for the content loss, while the higher layers are used for the style loss.
- Initialize the generated Image with random noise or with the content image.
- Define the content loss and style loss functions. The content loss measures the difference between the feature maps of the generated Image and the content image. In contrast, the style loss measures the difference between the Gram matrices of the generated Image and the style image.
- Define the total loss function, a combination of the content loss and the style loss, where the weights determine the relative importance of each loss.
- Use backpropagation to update the generated Image's pixels to minimize the total loss.
- Repeat step 7 for several iterations until the generated Image is close to the desired output.
- Post-process the generated Image by cropping or resizing it to the desired size, and adjusting the brightness, contrast, or other parameters.
- Save the generated Image.
It's worth noting that this is a general process with many variations in the implementation of NST, including using different loss functions, architectures, and optimization techniques.
The total loss function is applied to the dense convnet's output. This loss function is accurately depicted in the preceding Image. The loss of the Content and Style images, where alpha and beta represent the hyperparameters, adds together to form the total loss function. For more details, you can refer to the research paper here
The introduction to some of the guiding principles of the method will be covered in this article. Next, we'll dissect Neural Style Transfer and the fundamental conceptual underpinnings of this technique. Finally, we'll use this neural style transfer technique to create a straight forward project.
Final Output
Neural Style Transfer was a pioneering algorithm that motivated the researchers to experiment with the Deep Learning (DL) model architecture and DeepFakes. The below Image shows the Content Image, Style Image, and the image produced from the Neural Style Transfer Model.

Requirements
A low-level set of tools to create and train neural networks is offered by Google's TensorFlow2.x. with Keras, you can stack layers of neurons and work with various neural network topologies. We also use additional supporting packages like opencv2 and numpy for data preprocessing.
Implementing Neural Style Transfer
In this section, we will discuss one of the earliest approaches to building the neural style transfer project. We'll start from scratch with the tasks needed to make this project. We will import the necessary libraries, alter the images, design the Convolutional Neural Network, establish the total loss function, and finish the training loop.
The official websites of Keras and TensorFlow will serve as our primary sources of information as we create this project. We'll utilize the Van Gogh painting Starry Night as the style image for both portions of building this project. The Starry Night style is depicted in the Image below. You can choose any Content or Style Image to train the Neural Style Transfer Model.


Importing Libraries
We will import the TensorFlow and Keras deep learning frameworks to create the Neural Style Transfer model.
The VGG-19 transfer learning model will be imported for the feature extraction process. I suggest reading our earlier posts on Transfer Learning Dear SEO Team, Please add a link to Transfer Learning here if you want to learn more about transfer learning. To conduct the numerical operations, we will additionally import the Numpy library.
Data Preprocessing
Once the necessary libraries have been properly imported, we can define the necessary parameters. We will establish the routes for the three crucial elements: the path for the generated graphics, the Style, and the context image. All three of these parameters must be sent through our deep convolutional network to get the desired outcome. A few hyperparameters will also be set, including the content and style weight. Finally, we will specify some dimensions needed for the generated photos. The snippet of code for carrying out the following actions is shown below.
After importing the necessary libraries and image paths, the following step ensures that relevant functions are defined for appropriately preprocessing the photos. Two functions will be built. The VGG-19 transfer learning model is used to perform the first function: preprocess the images and load them appropriately. Next, we will transform the photos into a tensor format that can do the needed computations. Once all the necessary computations have been completed as desired, we will construct a function replicating the previously processed Image. The code snippet for carrying out both of these activities is shown below.
Loss Function
After preprocessing, we will create the loss function, which combines the content loss and the style loss, in the next stage. The previous section defined the relevance of the following loss function. The code snippet below defines four essential functions for calculating the overall loss. When calculating the style loss, the gram matrix function is employed.
Content Loss
When passing the created and original Images through the content layer, we use the mean square difference between the matrices produced to determine the content cost. For example, assume that p and x are the corresponding feature representations of the original picture ( p ) and the produced Image (x) in the layer. In contrast, P and F are their respective feature representation in layer l. The squared-error loss between the two feature representations is then defined by squared-error loss between the two feature representations.
Style Loss
We will first compute the gram matrix before calculating the style cost. Calculating the inner product of the vectorized feature maps of a specific layer is required to calculate gram matrices. The vectorized features of the layer's inner product, Gij (l), are shown below.
Gram Matrix: Gram matrix is a matrix of dot products between all possible pairs of feature maps in a given layer of a convolutional neural network (CNN). It is used to capture the correlation between different features in the layer and is often used as a loss function to compare the StyleStyle of two images. This loss function is used to guide the image generation process and ensure that the generated Image has a similar style as the style image.
Now that we have the feature vectors of the style image and the created Image, we can calculate the loss from a specific by finding the mean square difference of the gram matrices. This was then adjusted for layer weighting.
Assuming that a and x are the original and generated images, respectively, and Al and Gl are the corresponding style representations (gram matrices) in the layer. The layer's contribution to the overall loss is thus:
Hence Total style Loss will be:
Total Loss
Total loss is the linear sum of the above-described StyleStyle and Content losses, which is shown below:
Where α and β are the weighting variables for reconstructing the Content and Style, respectively.
When passing the created and original Images through the content layer, we use the mean square difference between the matrices produced to determine the content cost. For example, assume that P and F are the corresponding feature representations of the original picture ( p ) and the produced Image (x) in layer l. The squared-error loss between the two feature representations is then defined.
While the content loss function retains the top-level representation of the created Image similar to that of the base image, the style loss function keeps the generated Image close to the local textures of the style reference image. Therefore, we want to maintain the loss in a logically consistent manner and use the total loss function to keep the generated locally coherent.
Model Creation
Once we have defined our total loss function appropriately, we can move on to designing and developing the deep convolutional network's complete architecture to carry out the task of neural style transfer. The VGG-19 architecture includes the five crucial convolutional blocks, i.e., block1_conv, block2_conv1, block3_conv1, block4_conv1, and block5_conv1. The Image is shown below.
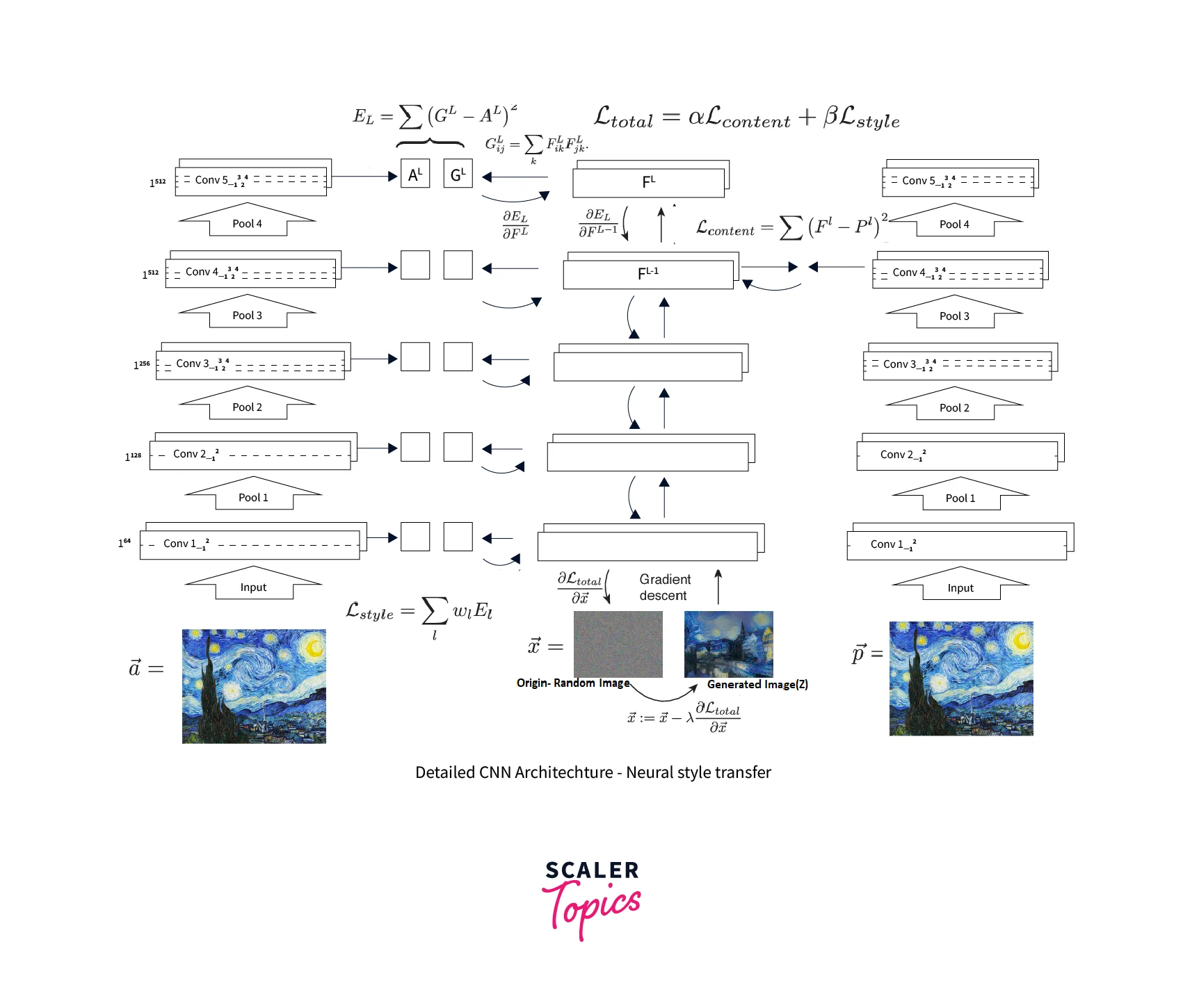
In this transfer learning architecture, the completely connected layers are disregarded. Instead, only convolutional and pooling layers of the deep convolutional network will be used. The output of this network will be passed with the proper loss function, which is a combination of the content loss and the style loss after the extracted features. The code snippets for model creation are shown below.
Creating Training Loops
Generating the training loop will be the last action in building neural-style transfer models from scratch. The decorator training loop is created as the first step in designing this portion. We will be responsible for defining the optimizer once we have created the decorator function. For this project, we'll employ the stochastic gradient descent optimizer with a learning rate and momentum.
The three necessary photos for the training procedure will then be loaded and preprocessed. After that, we'll start training the loop for about 400 iterations. You can train the subsequent neural style transfer for longer epochs and iterations. We'll also ensure that after the training, we'll rebuild the created Image using the previously defined de-process image function.
The output for training the model is shown below.
Testing
In this section, we will display the Image, the resultant Image of the Base image, and the style image from our Neural Style Transfer model. The code snippets are shown below:
The Image is shown below


What's Next?
In this article, we have trained the Neural Style Transfer Model with VGG-16. You can try with another pre-trained model, such as Inception and Mobilenet_V2, on different or the same images.
Conclusion
In this article, we learned how to train Neural Style Transfer Model using VGG-16. The following are the takeaways from this article:
- Pre-trained models can be used with various scenarios depending upon the use case.
- Neural Style Transfer can be used as a tool for Image and video editing.
- The difference between the higher-level intermediate layer feature maps is used to assess the content loss.
- The degree of correlation between the results from various filters at a level can be used to quantify style loss.
- Two loss terms are used during training by the model's architecture: Loss of both Content and Style.
- The Content Image and Style Image are the Neural Style Transfer network inputs. The only trainable variable in the neural network is the content image, replicated as a freshly generated image.