Implementing SimCLR for Self-Supervised Learning from Images with Keras
Overview
SimCLR (Simplified Contrastive Learning) is a self-supervised learning method for images that use Contrastive Learning to learn representations of the data without relying on labeled data. It involves training a neural network to predict which two images, out of a pair of images, are more similar. The representations learned by the network can then be used as feature embeddings for downstream tasks such as image classification. This article will teach us how to build self-supervised learning in Keras.
What are We Building?
SimCLR (Simplified Contrastive Learning) is a self-supervised learning method for images that use contrastive Learning to learn representations of the data without relying on labeled data. It involves training a neural network to predict which two images, out of a pair of images, are more similar. Then, the network is trained using a contrastive loss function, which encourages the network to produce similar representations for similar images and different representations for dissimilar images. The representations learned by the network can then be used as feature embeddings for downstream tasks such as image classification. The whole process is known as self-supervised Learning, and we will build self-supervised learning in Keras.
Pre-requisites
This section will explain the basic building blocks to understanding self-supervised Learning Keras.
-
Convolutional Neural Network (CNN): CNN comprises convolutional layers that apply learnable filters to detect specific patterns or features in an image, pooling layers to reduce dimensionality, and make the features more robust and fully connected layers that classify the image into predefined classes.
-
Tensorflow & Keras TensorFlow and Keras are open-source libraries for machine learning and artificial intelligence that Google and MIT develop. It is used for building and deploying models for various tasks, including image and speech recognition, natural language processing, and reinforcement learning.
-
What are Self-Supervised Learning and Contrastive Learning?: Self-supervised Learning is a type of machine learning where the model learns from the data itself without needing explicit labels. In self-supervised Learning, the model is given unlabeled data and must learn to find patterns or features within the data that can be used to perform a specific task. For example, in image classification, a self-supervised model may be trained to identify certain features of images that are important for classifying them into different categories. In this article, we will be focusing on self-supervised learning in keras using SimCLR.
-
What is Contrastive Learning? Contrastive Learning is a specific self-supervised learning method where the model learns by comparing different examples within the dataset. In contrastive Learning, the model is trained to distinguish between similar but different examples. It is used in various tasks, such as image classification, natural language processing, and speech recognition. Contrastive learning models are based on the idea of understanding an image. We need to compare it with similar images. The model learns to find the difference between similar images and uses it to classify them.
How Are We Going to Build this?
SimCLR consists of two main components: a base encoder network, which extracts features from the input images, and a contrastive loss function, which trains the model. The base encoder network is typically a pre-trained convolutional neural network (CNN) such as ResNet. The contrastive loss function is used to maximize the similarity between the features of the augmented versions of the same image and minimize the similarity between the features of different images. Simple has achieved state-of-the-art performance on various computer vision tasks, such as image classification, object detection, and semantic segmentation, with a simple and efficient training procedure. For example, building a SimCLR model for self-supervised Learning in keras from images involves the following steps:
- Data Preprocessing: The first step is to preprocess the images in the dataset. This involves resizing the images to a fixed size and normalizing the pixel values.
- Data Augmentation: Next, we will apply data augmentation techniques to the images, such as random crop, flip, rotation, and color jitter. This helps increase the training data's diversity and makes the model more robust.
- Network Architecture: The next step is to define the network architecture. SimCLR's network consists of two towers - a base network and a projection head. The base network is typically a pre-trained convolutional neural network (CNN) such as ResNet50, which extracts image features. The projection head is a small feed-forward neural network that is added to the base network and is used to project the features into a compact representation.
- Loss Function: The loss function used in SimCLR is contrastive loss. The contrastive loss measures the similarity between two views of an image and tries to maximize the similarity between positive (i.e., two views of the same image) and minimize the similarity between negative (i.e., two views of different images).
- Training: Once the network architecture and loss function is defined, the model can be trained using stochastic gradient descent (SGD) or any other optimization algorithm. During training, a batch of positive and negative image pairs are fed into the network, and the weights are updated based on the computed contrastive loss.
- Fine-tuning: The base network and projection head can be fine-tuned using labeled data after training on a supervised task. This helps to transfer the learned representations to the specific task.
- Evaluation: The model's performance can be evaluated on a validation or test set. The evaluation metric typically used for self-supervised Learning is accuracy on a supervised task.
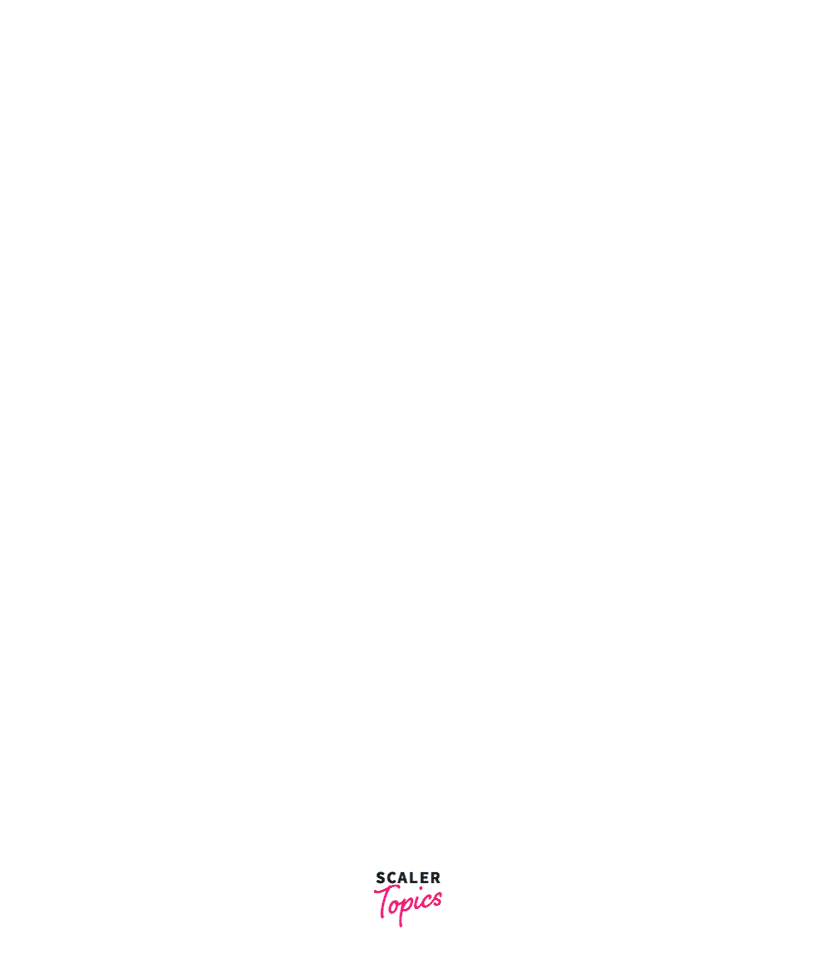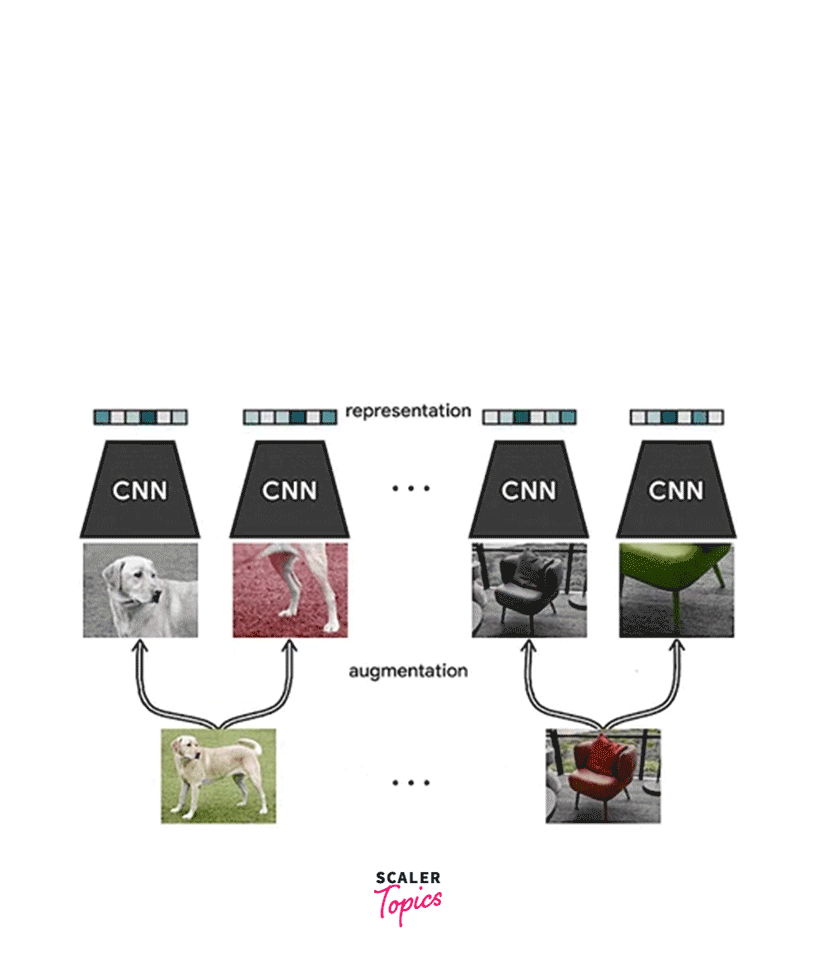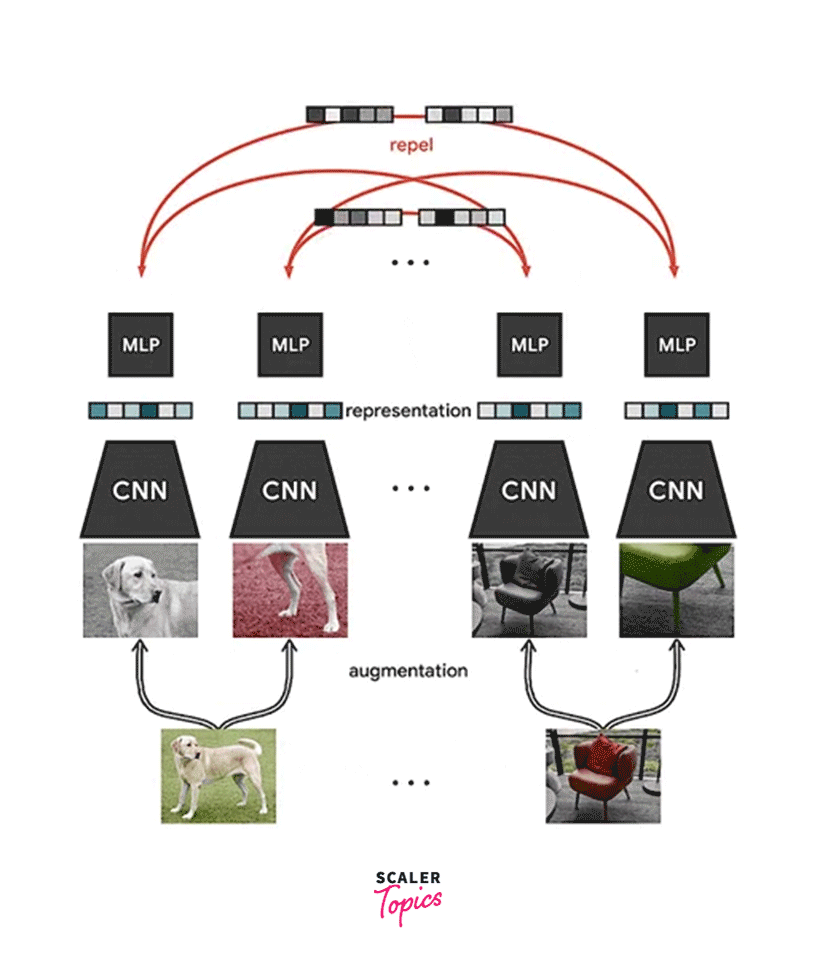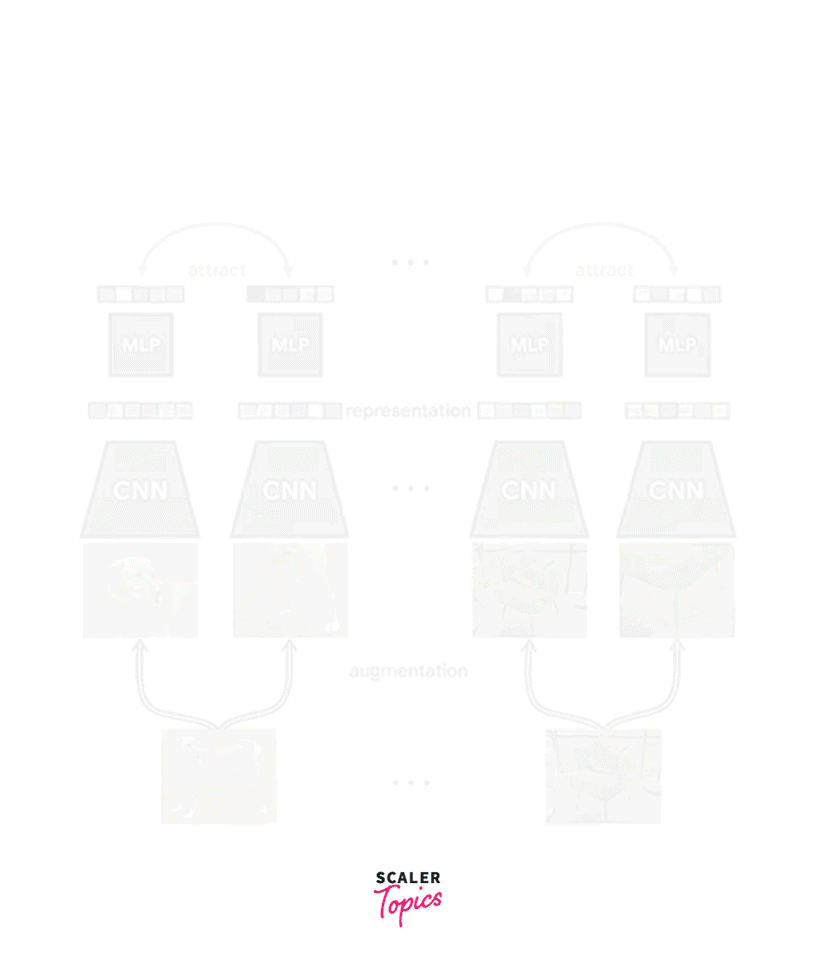
Final Output
SimCLR has shown its potential to be a powerful self-supervised learning technique that can be applied to various problem statements related to images and videos. Moreover, SimCLR can be combined with other self-supervised methods to improve its performance further. The below image shows the Validation Accuracy Graph of the SimCLR-trained model.

Requirements
For implementing the SimCLR in Keras, we must import some libraries from Keras, Tensorflow, and Tensorflow. The code below will import various libraries and modules commonly used in building a SimCLR model using TensorFlow and Keras.
- The TensorFlow library is imported as tf, which provides a comprehensive machine-learning platform for building and training models.
- The tensorflow_datasets library is imported as tfds, providing access to public datasets for training machine learning models.
- The keras module from the TensorFlow library is imported, which provides a high-level API for building and training neural networks.
- The layers module from the tensorflow.keras library is imported, providing a collection of pre-built layers for constructing neural networks, such as dense, convolutional, and recurrent layers.
Implementing SimCLR for Self-Supervised Learning from Keras.
In this self-supervised learning in Keras, we will learn how to train a SimCLR using images. This section is further divided into sub-sections that will help us gain in-depth knowledge of training SimCLR - Self-Supervised Learning in Keras.
Initializing Hyper-parameter
The code below defines various hyperparameters used to configure the SimCLR (self-supervised Learning using Keras) model and the dataset it will be trained on.
As we can see in the code the unlabeled_dataset_size and labeled_dataset_size specify the size of the dataset that will be used to train the network. The image_size and image_channels specify the size and number of channels of the images in the dataset.
The num_epochs hyperparameter specifies the number of times the model will iterate over the entire dataset during training. The batch_size specifies the number of images used in each iteration during training.
The width hyperparameter defines the number of neurons in the last fully connected layer, which will be used to produce the embeddings. Finally, the temperature hyperparameter scales the embeddings during training to improve the contrastive loss function.
The contrastive_augmentation and classification_augmentation hyperparameters specify the data augmentation techniques applied to the images during training. These augmentation techniques can include random cropping, flipping, and color jittering and are used to improve the robustness of the model.
Dataset Preparation
The code below defines a function prepare_dataset() used to load and prepare the STL10 dataset for training the SimCLR model.
The function first calculates the number of steps per epoch and the batch size for labeled and unlabeled samples based on the specified unlabeled_dataset_size and labeled_dataset_size hyperparameters.
Then it loads the dataset using the tfds.load() function. It loads the unlabeled split of the STL10 dataset for the unlabeled samples, the train split for the labeled samples, and the test split for the test dataset. The shuffle_files=True parameter is used to shuffle the dataset, and the as_supervised=True parameter returns the samples as a tuple of (image, label) instead of a dictionary.
The unlabeled train dataset is shuffled and batched, the labeled train dataset is shuffled and batched, and the test dataset is batched and prefetched.
Finally, the labeled and unlabeled datasets are combined using the tf.data.Dataset.zip() function, and the resulting combined dataset is prefetched. The function returns the combined train dataset, the labeled train dataset, and the test dataset as its output.
This code loads the STL10 dataset, shuffles, and splits it into three datasets: unlabeled samples, labeled samples, and test samples. These datasets will be used during the training process to learn the feature representations of the images in an unsupervised way and to evaluate the model's performance.
Data Augmentation and Visualization
The code below defines a custom layer called RandomColorAffine and a function get_augmenter() used to apply data augmentation to the images in the dataset.
The RandomColorAffine layer applies brightness and color jitter to images. Then, the __init__ method takes two hyperparameters, brightness and jitter, which configure the amount of brightness and color jitter to be applied to the images. Finally, the call method applies the data augmentation to the images using the following steps:
It generates a brightness scale and a jitter matrix for each image. Then, it uses matrix multiplication to apply the brightness scale and jitter matrix to the images. Finally, it clips the resulting images to 0 to 1. The get_augmenter() function creates a Keras Sequential model that applies data augmentation techniques to the images. It takes 3 parameters- min_area, brightness, and jitter, which are used to configure the amount of cropping, brightness, and color jitter to be applied to the images. Then, it applies the following steps to the images:
- Rescaling: it rescales the images from 0 to 1.
- RandomFlip: it randomly flips the images horizontally.
- RandomTranslation: it randomly translates the images.
- RandomZoom: randomly zooms the images.
- RandomColorAffine: it applies brightness and color jitter to the images.
The visualize_augmentations() function is used to visualize the effect of the data augmentation applied by the get_augmenter() function. First, it takes one parameter - num_images- to specify the number of images to be visualized. Then, it applies the data augmentation to a batch of images from the training dataset, using the classification_augmentation and contrastive_augmentation hyperparameters. It then displays the original and augmented images in a grid using Matplotlib.
The visualization helps to see how the data augmentation process affects the original images; it can be used to fine-tune the hyperparameters of the augmentation process.

Encoder Network
The code below defines a function get_encoder() that creates a Keras Sequential model that represents the encoder architecture of the SimCLR model.
The function creates a sequential model with the following layers:
- layers.Conv2D: a 2D convolutional layer that applies a kernel to the input images with a stride of 2. It has a wide number of filters and a ReLU activation function.
- layers.Flatten: a layer that flattens the 2D tensor output of the previous convolutional layers into a 1D tensor.
- layers.Dense: a fully connected layer with a wide number of neurons and a ReLU activation function.
This architecture is designed to extract features from the input images using a series of convolutional and pooling layers, then reduce the dimensionality of the feature maps using dense layers. The final output of this architecture is a high-dimensional feature embedding of the input image, which will be used to compute the contrastive loss.
Self-Supervise Baseline Model
The code below defines and trains a baseline model, which is a supervised model trained with random initialization, to classify images from the STL10 dataset.
It creates a Keras Sequential model, which is composed of the following layers:
- get_augmenter(): it applies data augmentation to the input images using the classification_augmentation hyperparameters.
- get_encoder(): it applies the encoder architecture to the augmented images to extract high-dimensional feature embeddings.
- layers.Dense: a fully connected layer with 10 neurons and no activation function. This layer is used to output the logits for the 10 classes of the STL10 dataset.
The model is then compiled by specifying an optimizer, a loss function, and a metric. The optimizer is the Adam optimizer, the loss function is the sparse categorical cross-entropy loss, and the metric used is the sparse categorical accuracy.
The model is then trained on the labeled train dataset for 20 epochs, and the performance is evaluated on the test dataset. The final output is the maximal validation accuracy reached during the training process.
This baseline model will be used to compare the performance of the SimCLR model that will be trained later. It represents the performance of a supervised model trained with random initialization, and it will be used as a comparison to show the improvement achieved by the unsupervised pretraining method.
Output
Self-Supervise Model for Contrastive Pretraining
The code below defines a Contrastive Model class, a Keras Model that implements the SimCLR algorithm for self-supervised Learning in Keras from images.
The SimCLR algorithm is based on the idea of Contrastive Learning, where the goal is to learn high-dimensional feature embeddings such that the representations of the same input image, obtained by applying different data augmentations, are similar to each other. In contrast, those of different images are dissimilar.
The ContrastiveModel class is composed of several components:
- temperature: a hyperparameter that controls the temperature scaling of the logits used in the contrastive loss.
- contrastive_augmenter: an image augmentation module that applies strong data augmentations to the input images using the contrastive_augmentation hyperparameters.
- classification_augmenter: an image augmentation module that applies weak data augmentations to the input images using the classification_augmentation hyperparameters.
- encoder: an encoder network that extracts high-dimensional feature embeddings from the augmented images.
- projection_head: a non-linear multi-layer perceptron that maps the feature embeddings to a lower-dimensional space.
- linear_probe: a single dense layer that maps the feature embeddings to the logits for the 10 classes of the STL10 dataset.
The ContrastiveModel class also defines the following methods:
- compile(): It specifies the optimizers, loss functions, and metrics used during training.
- contrastive_loss(): it is used to compute the contrastive loss, which is based on the InfoNCE loss (information noise-contrastive estimation) and the NT-Xent loss (normalized temperature-scaled cross-entropy).
- train_step(): It defines a custom training step that performs Contrastive Learning and linear probing.
The ContrastiveModel class is then trained using the train_dataset, unlabeled_train_dataset, and test_dataset to learn high-dimensional feature embeddings that can be used for various downstream tasks, such as image classification.
Output
Supervised fine-tuning of the pretrained Encoder
Supervised fine-tuning in SimCLR refers to taking the pre-trained encoder of a contrastive model and fine-tuning it on a supervised task using labeled data. This is done by replacing the contrastive model's projection head and linear probe with a new head tailored to the supervised task, such as a dense layer with several outputs corresponding to the number of classes in the labeled dataset. The new model is then trained on the labeled data using a supervised loss function, such as categorical cross-entropy, and regularization techniques, such as weight decay and early stopping. This fine-tuning process allows the model to leverage the representations learned during pre-training to improve performance on the supervised task.
The code below defines a new model, finetuning_model which uses the pre-trained contrastive model pretraining_model encoder and replaces the projection head and linear probe with a single dense layer with 10 outputs. The new model is then compiled with an Adam optimizer, SparseCategoricalCrossentropy loss, and SparseCategoricalAccuracy metric. It is then trained on the labeled dataset for the specified number of epochs (num_epochs). The results are printed with a message indicating the maximal validation accuracy achieved during the training.
Output
Comparision Against the Baseline Model
The fine-tuned SimCLR model should perform better than the baseline model as it starts with pre-trained representations that have already learned useful features from many unlabeled data. This can lead to faster convergence and higher accuracy on the supervised task. Therefore, a comparison of the performance of the fine-tuned SimCLR model against a baseline model trained from scratch on the labeled dataset can be used to evaluate the effectiveness of the self-supervised SimCLR model.
One way to compare the two models is to plot the training and validation accuracy/loss of both models and compare them. Another way is to compute the final accuracy of the models on the test set after training and compare them, shown below in image format. The below code plots the training curves for accuracy and loss for the baseline, pre-trained, and fine-tuned model.
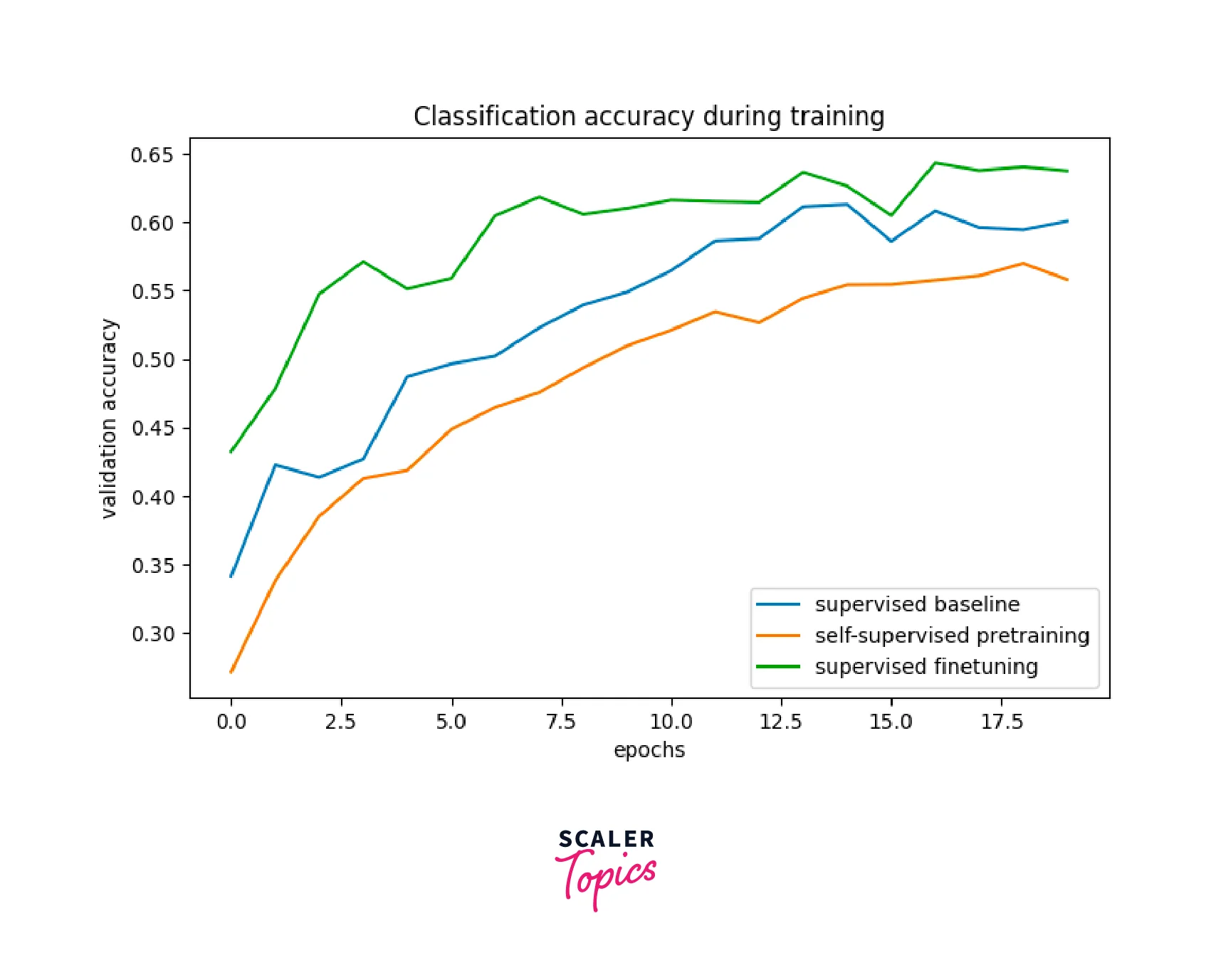
Conclusion
In this article, we have studied self-supervised learning in Keras. The following are the key takeaways from this article:
- SimCLR is based on the contrastive learning principle, where the model learns to distinguish between different views of the same image.
- SimCLR combines data augmentation and a contrastive loss function to achieve the goal.
- The representations learned by SimCLR can be used as initialization for a supervised task such as image classification.
- SimCLR shows that the self-supervised pretraining followed by supervised fine-tuning leads to better results than the supervised baseline.