Kubernetes Autoscaling
Overview
Kubernetes is an open-source container orchestration platform that allows you to deploy, manage, and scale containerized applications. Autoscaling in Kubernetes refers to the ability of the platform to automatically adjust the number of instances (pods) of an application based on workload demand or we can say traffic. This ensures that your applications can handle varying levels of traffic efficiently without manual intervention. Kubernetes provides both horizontal and vertical autoscaling mechanisms.
Understanding Kubernetes Scaling
Horizontal Scaling (Scaling Out)
Horizontal scaling, also known as horizontal application scaling or scaling out, is a method used to handle increased demand and traffic for an application by adding more instances or replicas of the application.
Here's a more detailed explanation of horizontal scaling:
- Adding Identical Instances: When an application experiences increased demand or traffic instead of making individual instances work harder, horizontal scaling involves adding more instances of the application. These new instances are essentially clones of the existing ones and can handle incoming requests independently.
- Load Distribution: Horizontal scaling distributes incoming requests or tasks among the available instances. Load balancers are often used to evenly distribute the workload across these instances. This prevents any single instance from becoming overwhelmed while ensuring efficient utilization of resources.
- Improved Performance and Availability: With more instances available to process requests, the application's performance can improve as each instance handles a smaller portion of the overall load. Additionally, if one instance fails, the remaining instances can continue to serve traffic, enhancing the application's availability and resilience.
- Scalability on Demand: Horizontal scaling allows you to scale your application up or down based on demand. During traffic spikes, you can add more instances to accommodate the increased load. Conversely, during periods of lower demand, you can reduce the number of instances to save resources and cost.
- Statelessness and Data Handling: For effective horizontal scaling, applications are often designed to be stateless. This means that the application's state or data is not stored on individual instances but rather in shared databases, caches, or storage systems.
- Cloud and Container Orchestration: Cloud platforms and container orchestration tools like Kubernetes provide the infrastructure that supports easy horizontal scaling. These platforms allow you to define how many instances of your application you want to run and automatically manage their deployment, distribution, and load balancing.
- Cost Efficiency: Horizontal scaling can be more cost-effective than vertical scaling (scaling up), as it involves adding smaller instances rather than upgrading to more powerful and often more expensive hardware.
Vertical Scaling (Scaling Up)
Vertical scaling, also referred to as vertical application scaling or scaling up, is a method used to handle increased demand or resource requirements for an application by upgrading the existing hardware or resources of a single instance.
Here's a more detailed explanation of vertical scaling:
- Upgrading Hardware Resources: Vertical scaling involves upgrading the resources of an existing instance. This can include adding more CPU cores, increasing the amount of RAM, expanding storage capacity, or improving other components of the instance, such as the GPU.
- Enhanced Performance: By increasing the resources of a single instance, the application's performance can improve. This is especially beneficial for applications that have resource-intensive tasks or require a significant amount of memory or processing power.
- Single Instance Management: Unlike horizontal scaling, which involves managing multiple instances, vertical scaling requires managing a single instance. This can simplify deployment, monitoring, and maintenance tasks compared to dealing with a larger number of instances.
- Vertical Scaling Limits: While vertical scaling can improve performance, there are limitations to how much an instance can be upgraded. Eventually, the hardware's physical limitations, such as the maximum number of CPU cores or the maximum amount of RAM, may be reached. This can make it challenging to handle extremely high levels of traffic or resource demands solely through vertical scaling.
- Downtime Considerations: Vertical scaling may require downtime or service disruption as the instance is upgraded. This can impact the application's availability during the scaling process.
- Cost Implications: Upgrading hardware resources can be costly, especially for high-performance instances with significant resources. Additionally, upgrading to more powerful hardware may not always result in a linear increase in performance, making cost-effectiveness an important consideration.
- Cloud and Virtualization: Cloud platforms and virtualization technologies have made vertical scaling more flexible by allowing you to adjust the resources of virtual machines on the fly. However, there are still practical limits to how much a single virtual machine can be scaled vertically.
- Application Compatibility: Some applications might not be designed to take full advantage of vertical scaling. They might not be able to fully utilize the increased resources, which could result in suboptimal scaling outcomes.
Manual Scaling in Kubernetes
Manual scaling in Kubernetes refers to the process of manually adjusting the number of replicas (pods) for a specific deployment or application. Unlike autoscaling, where Kubernetes adjusts the number of replicas automatically based on defined criteria, manual scaling requires human intervention.
To manually scale an application in Kubernetes:
a. Kubectl Command: You can use the Kubectl scale command to manually change the number of replicas for a deployment or replicaset.
-
the Use kubectl scale command:
b. Edit the YAML File: You can also manually edit the YAML file for the desired deployment or replicaset and change the replicas field to the desired number.
It's important to note that manual scaling requires continuous monitoring and adjustment as the workload changes. Autoscaling is often preferred for maintaining a balance between resource utilization and application performance, as it can respond dynamically to changes in demand without manual intervention.
Kubernetes autoscaling encompasses both horizontal scaling (adding more instances) and vertical scaling (increasing instance resources), while manual scaling involves adjusting the number of replicas manually through commands or YAML file edits.
Horizontal Pod Autoscaler (HPA)
Horizontal Pod Autoscaler is a feature in Kubernetes, an open-source container orchestration platform, that helps automatically adjust the number of pod replicas within a deployment or replica set based on the observed CPU utilization or other custom metrics.
The primary goal of HPA is to ensure that your application's resource utilization remains balanced and efficient. When the demand for processing power increases, the HPA will scale up the number of pod replicas, and when the demand decreases, it will scale down the replicas. This dynamic scaling helps maintain optimal performance and resource allocation without manual intervention.
In essence, HPA monitors the resource metrics of the pods it's managing and makes scaling decisions according to pre-configured thresholds. This allows applications to adapt to varying workloads and traffic patterns, ensuring efficient resource utilization and an improved user experience.
Cluster Autoscaler
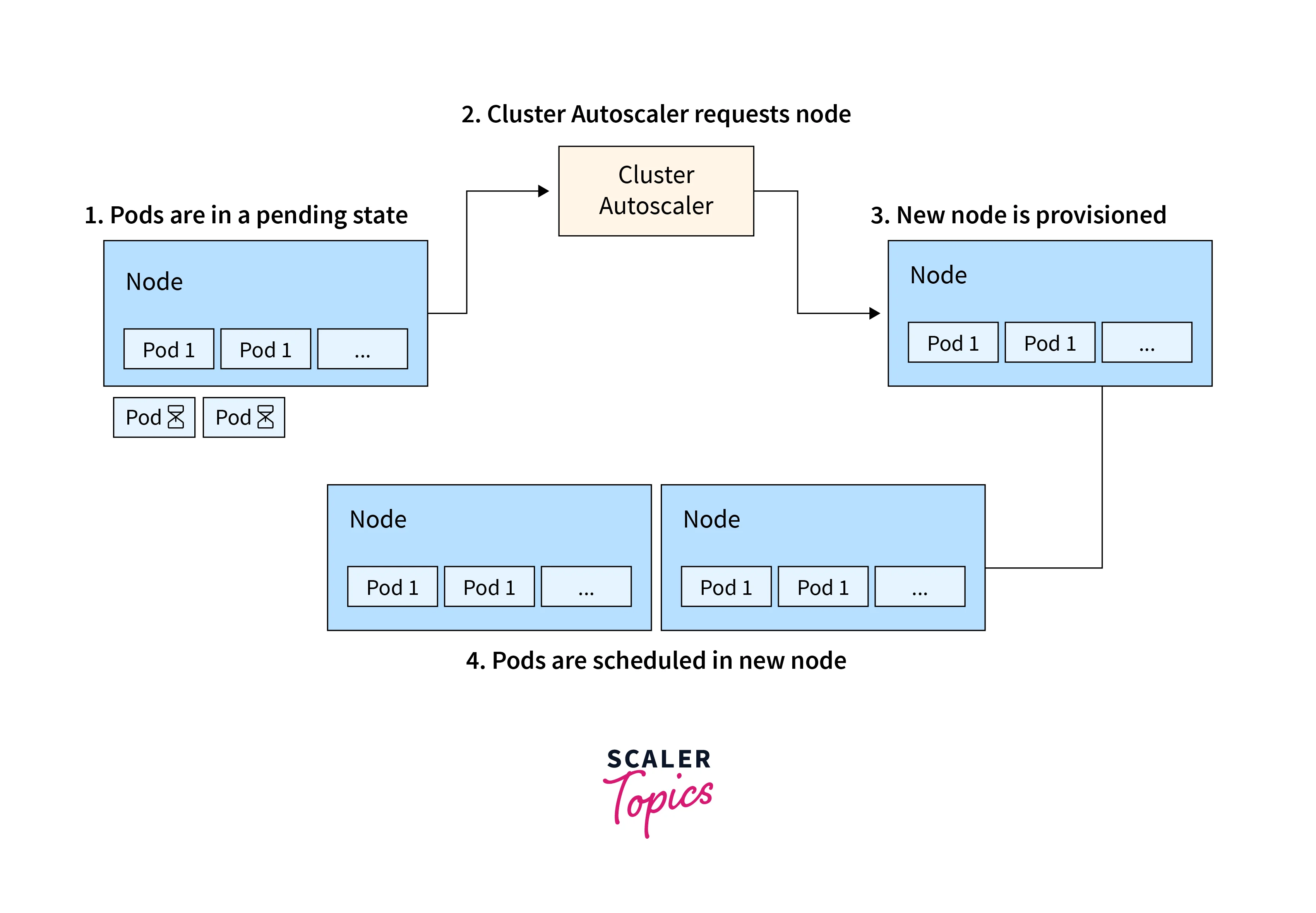
Cluster Autoscaler is another feature in Kubernetes that focuses on the overall capacity of the entire cluster rather than individual pods. It ensures that the Kubernetes cluster has the appropriate amount of compute resources (nodes) to run all the desired workloads while optimizing resource allocation and cost.
As workloads increase or decrease, the Cluster Autoscaler monitors the utilization of nodes in the cluster and decides when to add or remove nodes. If the resource demand is high and existing nodes are running at high utilization, the cluster autoscaler will provision additional nodes to accommodate the load. Conversely, if there are idle nodes with low utilization, the cluster autoscaler will downscale the cluster by removing unnecessary nodes, which helps save costs.
In summary, while Horizontal Pod Autoscaler focuses on adjusting the number of pod replicas to match demand within a deployment, Cluster Autoscaler ensures the entire cluster's capacity matches the workload demand, ultimately optimizing resource usage and maintaining a responsive and efficient application environment.
Custom Metrics and Metrics Server
Explain How to Use Custom Metrics for Advanced Scaling Scenarios, beyond CPU Utilization
Custom metrics allow you to use application-specific or business-related metrics for autoscaling decisions, going beyond the standard CPU and memory utilization.
To use custom metrics, you need a metrics server (or a more advanced monitoring solution like Prometheus) to collect and expose these metrics to Kubernetes.
- Collect Metrics: Your application needs to expose the custom metrics. This could be done using the Kubernetes API or an external monitoring tool.
- Configure Metrics Server: Ensure Metrics Server or another compatible monitoring tool is deployed in your cluster.
- Create a Custom Metrics API: Define and deploy a Custom Metrics API, which exposes your custom metrics to the Horizontal Pod Autoscaler.
- Create an HPA with Custom Metrics: Create an HPA similar to the one shown earlier, but with custom metric types and thresholds.
Pod Disruption Budgets (PDB)
Introduce Pod Disruption Budgets as a Mechanism to Ensure High Availability during Scaling Events.
Pod Disruption Budgets (PDBs) play a crucial role in maintaining high availability for applications during scaling events within a Kubernetes cluster. Scaling events can include activities like rolling updates, scaling up/down, or node maintenance. PDBs act as a safeguard to ensure that these events do not lead to excessive downtime or service disruptions for critical applications.
By setting up a PDB, you provide explicit guidelines to Kubernetes on how many pods can be simultaneously unavailable during these events. This ensures that there is always a minimum number of healthy pods available to handle incoming requests. For instance, if you specify a PDB that allows only a certain percentage of pods to be unavailable, Kubernetes will orchestrate the scaling event in a way that adheres to this constraint.
PDBs provide a balance between maintaining application availability and the need for updates or scaling adjustments. Instead of all pods of an application being taken down simultaneously, PDBs enforce controlled, staggered disruptions, ensuring that the application can continue to serve traffic while the cluster undergoes changes.
Best Practices For Scaling in Kubernetes:
- Resource Requests and Limits: Set appropriate resource requests and limits for containers to prevent resource contention and ensure fair allocation within pods.
- Cluster Autoscaling: Use Cluster Autoscaler to dynamically adjust the number of nodes in the cluster based on resource demand, optimizing resource utilization and cost-efficiency.
- Pod Design: Design applications with statelessness in mind, enabling pods to be easily scaled horizontally. Consider using microservices architecture for better scalability.
- Efficient Use of Storage: Optimize storage usage by using dynamic provisioning, resizing volumes as needed, and regularly cleaning up unused resources.
- Caching and State Management: Utilize caching mechanisms and state management strategies to offload data-intensive operations from pods, improving scalability and responsiveness.
Monitoring and Alerting:
Monitoring and alerting are critical for maintaining the health and performance of your Kubernetes environment.
a) Metrics Collection: Set up monitoring to gather metrics on resource usage, pod health, and application performance.
b) Centralized Logging: Implement centralized logging to aggregate logs from all pods and containers, making troubleshooting and performance analysis easier.
c) Alerting Policies: Define alerting thresholds based on predefined metrics. Set up alerts to notify you when resources are nearing capacity, pods are failing, or other critical events occur.
d) Anomaly Detection: Implement anomaly detection mechanisms to identify unusual patterns in metrics that might indicate performance or availability issues.
e)Integration with External Monitoring Tools: Integrate Kubernetes monitoring with external monitoring tools for more comprehensive insights into application performance and infrastructure health.
Conclusion
- Scaling in Kubernetes is crucial for maintaining application performance and responsiveness.
- Horizontal Pod Autoscaling (HPA) and Cluster Autoscaler are key tools for dynamic scaling.
- Properly set resource requests and limits to prevent resource contention.
- Design pods and applications with statelessness and microservices architecture to facilitate horizontal scaling.
- Use Pod Disruption Budgets (PDBs) to ensure high availability during scaling and maintenance events.